?原创作者 | 杨健
论文标题:
KEPLER: A unified model for knowledge embedding and pre-trained language representation
收录期刊:
TACL
论文链接:
https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00360/98089/
项目地址:
https://github.com/THU-KEG/KEPLE

01、问题
上一次我们介绍了ERNIE,其实类似的工作还有KnowBERT,它们的思路都是对知识图谱中的三元组表示学习,在编码实体间的关联信息后,通过对齐文本指称项将其注入到预训练语言模型之中。所不同的是KnowBERT不使用TransE,而是使用Tucker进行表示学习。
此外,KnowBERT设计了一个基于神经网络的实体链接器,该链接器能够获得和某个指称项关联的多个实体,从而为一个指称项注入多个实体的信息。
对这两个模型而言,知识的丰富程度都取决于知识表示的方法。然而传统的基于平移的表示学习方法没有考虑图谱的拓扑结构,也无法利用实体相关的文本信息编码实体。在这篇文章中,笔者将介绍该论文如何使用文本辅助图谱的表示学习,从而让实体向量蕴含更多的信息。
此外,在上次介绍ERNIE的文章中,笔者提到ERNIE使用基于自注意力机制来克服异构向量的融合。那么有没有可能在一开始就产生同构的表示向量,降低知识和文本向量融合的难度呢?
02、解决方案
为了避免异构向量的产生,作者使用同一个预训练语言模型编码实体和文本,从而生成处于同一语义空间的向量,并使用知识表示学习和掩码语言模型(MLM)作为预训练任务联合训练,共同更新模型参数。
具体而言,作者沿用RoBERTa作为基础模型,拼接实体的描述文本和特殊符号<s>作为模型的输入,从而为实体引入了更多的上下文信息。
考虑到RoBERTa采用双向关注的Transformer作为编码层,特殊符号<s>所对应的表示向量将包含整个序列的语义,因此作者将这一向量视为实体的初始化向量,该向量将用于TransE的损失函数计算,为预训练模型注入实体关联信息。模型的结构如下图所示:
为了比较不同的实体描述文本所产生的效果,作者设计了三种不同的描述文本组合来进行对比实验。第一种是使用实体的描述文本编码实体向量并随机初始化关系向量。给定三元组(h,r,t),向量编码过程如下:
其中E表示编码器,表示起始位置的特殊符号,T表示关系向量矩阵。
第二种是分别使用实体和关系的描述文本编码实体和关系的向量,其中头尾实体编码方式同上,关系向量的编码方式如下:
最后一种则是拼接实体和关系的描述文本编码实体向量,随机初始化关系向量,实体的编码方式如下:
在获得实体和关系的表示向量后,模型使用TransE中的损失函数计算损失值,更新模型参数。计算公式如下:
其中
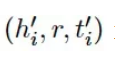
为负样本,
gamma为边缘值,
dr则采用P=1的评分函数:
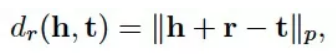
除了知识表示的预训练任务,模型仍然针对描述文本进行掩码,并预测掩码词,以避免模型出现参数遗忘的问题。模型总的损失函数为:
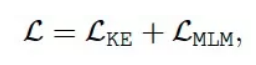
通过这种方式生成的向量既能够同时利用三元组结构信息和文本语义,又避免了引入外部实体链接器或者融合两类向量的编码层,保持了模型结构在预训练阶段和推理应用阶段的一致性。
传统的知识表示学习方法仅能够应用于转导式(transductive)链接预测任务,即只能判断训练阶段出现过的实体间的关系。
对于训练阶段未出现过的实体,由于无法获得对应的表示向量,也就无法判断彼此是否存在关联。使用预训练模型生成的实体向量则能够克服这一问题,应用到推导式(inductive)链接预测任务,关系分类任务甚至是信息检索任务[1]。
03、实验分析
实验主要包括针对下游任务测试实验和消融(ablation)实验。
3.1 下游任务测试实验
针对下游任务,作者使用关系分类和实体分类这两个知识驱动型任务检验知识注入的有效性。此外,该方法也为实体向量注入了文本信息,为了检验文本信息对实体向量的性能提高,作者还使用推导式和转导式链接预测任务进行实验对比。
除了上述提到的三种不同的描述文本,作者还考虑了不同知识图谱对模型性能的影响,并根据这两个变量设计了以下的模型变种(Variant)。
其中KEPLER-Wiki仅使用作者自己构建的Wikidata5M图谱,KEPLER-WordNet仅使用WordNet图谱,而KEPLER-W+W则使用两类图谱。
以上三个模型都使用实体描述文本编码实体,KEPLER-Rel同样使用两类图谱进行训练,但分别使用实体和关系的描述文本编码二者。KEPLER-Cond也使用两类图谱进行训练,使用包含实体和关系的描述文本编码实体。
关系分类任务的实验结果如图1所示,结果表明,相比ERNIE、KnowBERT和RoBERTa等基准模型以及其他变种模型,KEPLER-Wiki取得了最高的F1值和召回率,对比不同描述文本产生的性能差异,可以发现使用包含实体和关系的描述文本编码实体并没有提高模型在该任务上的性能,但在链接预测任务上有很大的性能提升,笔者认为这可能是因为关系分类任务更倾向于获取实体信息,含有别的关系描述文本反而干扰了实体的准确性。
相比另外两类变种模型,KEPLER-Rel的F1值最低,这是由于Wikidata中关系的描述内容很短并且和普通文本异构,使用关系描述对关系编码反而恶化了模型的性能。
图1 基于TACRED数据集的关系分类任务
对比不同知识图谱产生的性能差异,可以发现同时使用Wikidata5M和WordNet训练反而不如仅仅使用Wikidata5M,笔者认为WordNet是以词义作为关联信息的知识图谱,会连接存在近义或者反义的实体,与Wikidata关联方式不一致, 这也说明了不同组织方式的图谱可能会存在冲突。
实体分类任务的实验结果同样显示KEPLER-Wiki取得了比基准模型更好的结果,其中F1值比ERNIE高出1.3%,比KnowBERT高出0.6%。
此外,在GLUE数据集上KEPLER-Wiki取得了和RoBERTa相近的结果,表明模型在注入知识后保持了预训练语言模型原有的语言理解能力。
链接预测任务的实验结果显示KEPLER-Cond取得了最好的效果,表明实体和关系的描述文本在该任务中能帮助模型更准确的预测出尾实体。
3.2 消融实验
为了检测模型所具有的知识含量,作者使用LAMA数据进行实验,考虑到数据可能包含字面上的线索提示模型生成正确答案,作者还使用了LAMA-UHN测试模型。
结果发现KEPLER-W+W虽然在关系分类任务上不如KEPLER-Wiki,但在LAMA-UHN上却取得了最高的正确率。这表明不同的下游任务需要不同类型的知识图谱。
在计算效率方面,由于模型并没有引入额外的参数或者架构,因此对比ERNIE和KnowBERT,模型在训练和推理阶段所需的时间都更短。
在低频词语义学习方面,作者按照单词在训练语料中出现的频率从高往低分成了五组,并使用RoBERTa和KEPLER对这些词进行实体对齐实验,结果发现当对于低频词,KEPLER比RoBERTa的实体预测准确率更高。
由于训练语料存在长尾分布的特征,低频词无法从上下文文中充分学习语义,而KEPLER通过外部描述文本弥补了这一缺陷。
04、点滴思考
模型通过引入描述文本带来了以下几个好处,一是解决了分别对文本和知识编码造成的异构向量问题,二是保持了和原有模型相同的结构,减少了训练时长和额外的工程实现。三是弥补了预训练语言模型低频词无法充分学习语义的缺陷。
然而这种方法也依赖于具有充分准确的实体和关系描述文本,适用于具有实体简介语料如医疗领域的术语词条的领域知识增强。
在不具备实体描述文本的情况下,我们也可以考虑使用实体所在图谱的上下文,也即实体在图谱的路径帮助实体表示向量的学习,通过采样局部的结构图并构造实体的上下文,也能帮助模型获取更多的信息[2][3]。
此外,我们在这篇论文中看到了借用预训练语言模型,可以用实体的介绍文本初始化实体向量,从而解决文本和知识向量存在于异构向量空间的问题。问题的关键在于使用同一个编码器对两种不同结构的对象表示学习。
除了本文这种方法,通过将三元组结构的知识图谱转换为文本序列也能够解决这一问题[2][4],笔者将在后续详细介绍这些方法。
参考文献
[1] Inductive Entity Representations from Text via Link Prediction
https://arxiv.org/abs/2010.03496
[2] CoLAKE- Contextualized Language and Knowledge Embedding
https://arxiv.org/abs/2010.00309
[3] Integrating Graph Contextualized Knowledge into Pre-trained Language Models
https://arxiv.org/abs/1912.00147
[4] K-BERT: Enabling Language Representation with Knowledge Graph
https://ojs.aaai.org/index.php/AAAI/article/view/5681
