
torch.nn.Embedding使用详解
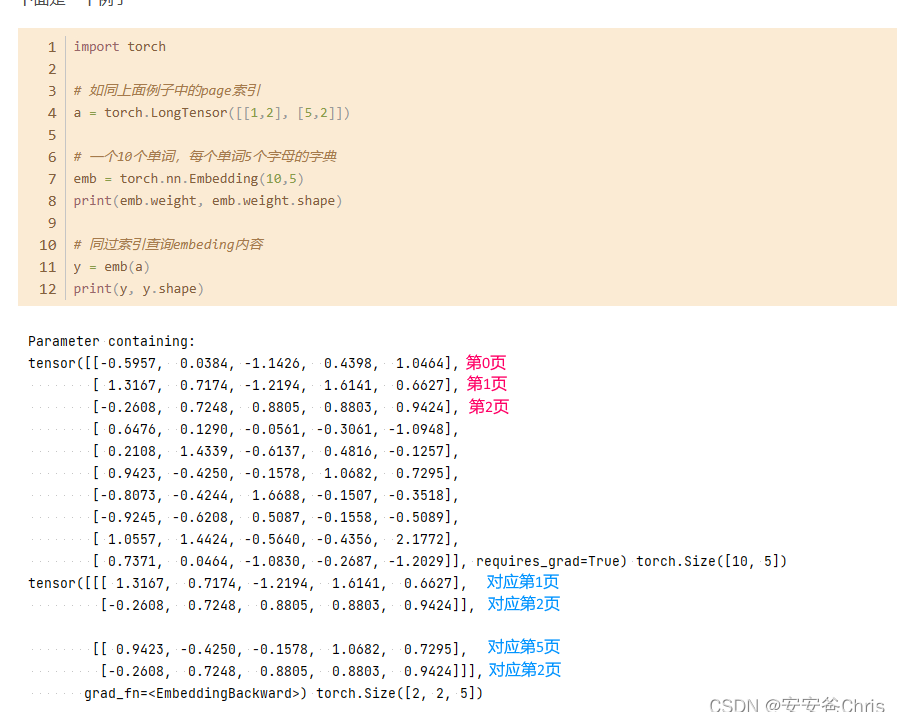
torch.nn.Embedding: 随机初始化词向量,词向量值在正态分布N(0,1)中随机取值。
输入:
torch.nn.Embedding(
num_embeddings, – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim,– 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx=None,– 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm=None, – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type=2.0, – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq=False, 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse=False, – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。
_weight=None)
输出:
[规整后的句子长度,样本个数(batch_size),词向量维度]
举例:
博客推荐:
https://www.cnblogs.com/duye/p/10590146.html