
Study for Go ! Chapter three - Function
-
Initialization
-
函数是结构化编程的最小模块单元
-
函数是代码复用和测试的基本单元
-
关键字 func
-
无需前置声明
-
不支持命名嵌套定义 (nested)
-
不支持同名函数重载 (overload)
-
不支持默认参数
-
支持不定长变参
-
支持多返回值
-
支持命名返回值
-
-
花括号不能另起一行
-
函数属于第一类对象,具备相同签名(参数和返回值列表)的视作同一类型
First-class object:指可在运行期创建,可用作函数参数或返回值,可存入变量的实体。最常见的用法是匿名函数
-
从阅读和代码的维护角度来说,使用命名类型更加方便
-
函数只能判断其是否为nil,不支持其他比较操作
-
从函数返回局部变量指针是安全的,编译器会通过逃逸分析( escape analysis ) 来决定是否在堆上分配内存
-
函数内联(inline)对内存分配有一定的影响。
-
编译器可能未实现尾递归优化 (tail-call optimization)尽管 golang 执行栈的上线是 GB 规模,轻易不会出现堆栈溢出 (stack overflow)错误,但是依然余姚注意拷贝栈的复制成本
Notice:(name rule)
-
在避免冲突的情况下,函数命名要本着精简短小,望文知意的原则
-
通常是动词和介词加上名词,例如:scanWords
-
避免不必要的缩写,printError 比 printErr 更好
-
避免使用类型关键字,比如 buildUserStruct 就会看起来别扭
-
避免歧义,不能有多种用途的解释造成误解
-
避免只能通过大小写区分的同名函数
-
避免与内置函数同名,这会导致误用
-
避免使用数字,除非是特定专有名词 如 UTF8
-
避免添加作用域提示前缀
-
同一使用 camel / pascal case 拼写风格
-
使用相同术语,保持一致性
-
使用习惯用语,比如 init 表示初始化, is / has 返回布尔值结果
-
使用反义词组命名行为相反的函数,比如: get / set, min / max 等
Attention:
-
函数和方法的命名规则有些不同,方法通过选择符调用,且具备状态上下文,可使用更简短的动词命名
-
-
argument
-
Go 对参数的处理偏向保守,不支持有默认值的可选参数
-
不支持命名实参
-
调用时必须按签名顺序传递指定类型和数量的实参,就算以 “ _ ” 命名的参数也不能忽略
-
在参数列表中,相邻的同类型参数可以合并
-
参数可以被视作函数局部变量,因此不能再相同层次定义同名变量
-
形参是指函数定义中的参数,实参则是函数调用时所传递的参数。形参类似函数局部变量,而实参则是函数外部对象,可以是常量、变量、表达式或者函数等
-
不管是指针,引用类型,还是其他类型参数,都是值拷贝传递 (pass-by-value)区别无非是拷贝目标对象,还是拷贝指针而已。
-
在函数调用前,会为形参和返回值分配内存空间,并将实参拷贝到形参内存
-
尽管实参和形参都指向同一目标,但传递指针时依然被复制
Attention:
-
表面上看,指针参数的性能可能更好一些,但是实际上需要具体分析,被复制的指针会延长目标对象生命周期,还可能会导致它被分配到堆上,那么其性能消耗就得加上堆内存分配和垃圾回收的成本
-
其实在栈上复制小对象只需很少的指令就可完成,远比运行时进行堆的内存分配要快得多,另外并发编程也提倡尽可能使用不可变对象 (只读或复制),这可以消除数据同步等麻烦。当然如果复制成本很高,或者需要修改原对象状态,自然使用指针更好
-
要使用传出参数( out ) 通常建议使用返回值,当然也可以使用二级指针
-
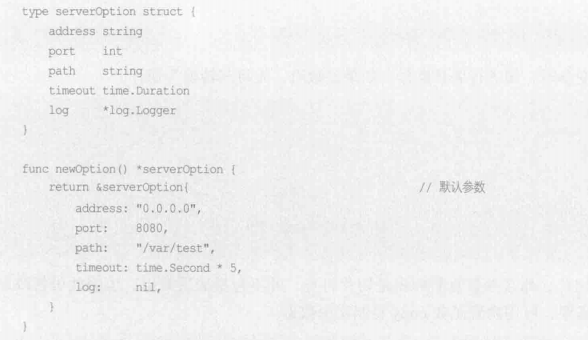
如果函数参数过多,建议将其重构为一个符合结构类型,也算是变相实现可选参数和命名实参等功能,例如:将过多的参数独立成 option struct , 既便于扩展参数集,也方便通过 newOption 函数设置默认配置,这也是代码复用的一种方式,避免多处调用时的繁琐的参数配置


变参:
-
变参实际上本质是一个切片,只能接受一到多个同类型参数,且必须放在列表尾部
-
将切片作为变参时,须进行展开操作,如果是数组,先将其转换为切片
-
参数复制的仅是切片自身,并不包括底层数组,也因此可修改原数据,如果需要,可用内置函数copy 复制底层数据
-
return
-
有返回值的函数,必须有明确的 return 终止语句
-
除非有 panic,或者无 break 的死循环,则无须 return 终止语句
-
借鉴自动态语言的多返回值模式,函数得以返回更多状态,尤其是 error 模式
-
golang 中稍有不便的是没有元组(tuple)类型,也不能用数组、切片接受,但可用 “ _ ” 忽略掉不想要的返回值
-
多返回值可以用作其他函数调用实参,或当作结果直接返回
-
在 golang 中命名返回值和简短变量定义 一样,既有优点也有缺点
-
命名返回值让函数声明更加清晰,同时也会改善帮助文档和代码编辑器提示
-
命名返回值和参数一样,可当作函数局部变量使用,最后由 return 隐式返回
-
这种特殊的 “ 局部变量 ” 会被不同层级的同名变量遮蔽。 但编译器能检查到此类情况,只要改为显式 return 返回即可
-
除遮蔽外,我们还需要对全部返回值命名,否则编译器会搞不清状况
-
如果返回值能明确表明其含义,就尽量不要对其命名
-
匿名函数 anonymous function
-
匿名函数 是指没有定义名字符号的函数
-
除了没有名字以外,匿名函数和普通函数完全相同。最大的区别是,我们可以在函数内部定义匿名函数,形成类似 嵌套效果。匿名函数可以直接调用,保存到变脸,作为参数或返回值
-
将匿名函数赋值给变量,与为普通函数提供名字标识符有着根本的区别。当然,编译器会为匿名函数生成一个 “ 随机 ” 符号名
-
普通函数 与 匿名函数都可以作为结构体字段,或经过通道传递
-
不曾使用的匿名函数会被编译器当作错误
-
除闭包因素外,匿名函数也是一种常见的重构手段,可以将大函数分解成多个相对独立的匿名函数块,然后用相对简洁的调用完成逻辑流程,以实现框架和细节
-
相比语句块,匿名函数的作用域被隔离(不使用闭包),不会引发外部污染,更加灵活。没有定义顺序限制,必要时可抽离,便于实现干净、清晰的代码层次
closure 闭包
-
closure 是在其词法上下文中引用了自由变量的函数,或者说是函数及其引用的环境的组合体
-
正因为闭包通过指针引用环境变量,那么可能会导致其生命周期延长,甚至被分配到堆内存。另外。还有所谓的 “ 延迟求值 ” 的特性
-
多个匿名函数引用同一环境变量,也会让事情变得复杂,任何修改行为都会影响其他函数取值,在并发模式下可能需要做同步处理
-
闭包让我们不用传递参数就可以读取或修改环境状态,当然也要为此付出格外代价,对于性能要求较高的场合,须谨慎使用
-
延迟调用 delayed call
-
语句 defer 向当前函数注册稍后执行的函数调用。这些调用就被称作延迟调用,因为它们直到当前函数执行结束前才被执行
-
常用于资源释放接触锁定,以及错误处理 等操作
Attention:
-
延迟调用注册的是调用,必须提供执行所需参数(即使是空),参数在注册时被复制并缓存起来,如果对状态敏感,可改用指针或闭包
-
延迟调用可修改当前函数命名返回值,但自身返回值被抛弃
-
多个延迟注册按FLFO次序执行
-
延迟调用要在函数结束时才被执行,不合理的使用方式会浪费更多资源,甚至造成逻辑错误
-
相比直接用 CALL 汇编指令调用函数,延迟调用需要花费更大的代价,这其中包括 注册、调用等操作,还有格外的缓存开销,所以追求性能的算法应避免使用延迟调用
-
错误处理
-
golang 的错误处理与目前流行的趋势背道而驰
-
官方推荐的标准是 返回 error 状态
-
标准库将 error 定义为接口类型, 以便实现自定义错误类型
-
按照惯例, error 总是最后一个返回参数,标准库提供看相关创建函数,可以方便地创建包含简单错误文本的 error 对象
-
应从错误变量 而不是文本内容来判定错误类别
-
错误变量通常 以 err 作为前缀、且自负床内容全部小写,没有结束标点。以便于嵌入到其他格式化字符串中输出
-
全局错误变量并非没有问题,因为它们可以被用户重新赋值,这就可能导致结果不匹配,不知道以后是否会出现 只读变量功能,否则就只能靠自觉 了
-
与error.New 类似的还有 fmt.Errorf ,它返回一个格式化无内容的错误对象
-
某些时候,我们需要自定义错误类型,以容纳更多上下文状态信息。
-
在正式代码中,我们不能忽略 error 返回值,应严格检查,否则可能导致错误的逻辑状态。调用多返回值函数时,除了 error 外,其他返回值同样需要关注
Notice:如何解决大量函数和方法返回 error 使得调用代码变得很难看的问题
-
使用专门的检查函数处理错误逻辑(比如记录日志), 简化检查代码
-
在不影响逻辑的情况下,使用 defer 延后处理错误状态(err 退化赋值)
-
在不中断逻辑的情况下,将错误作为内部状态报错,等最终 “ 提交 ” 时再处理
-
panic,recover
-
与 error 相比,panic/recover 再使用方法上更接近 try/catch 结构化异常
-
它们都是内部函数而非语句
-
panic 会立即中断当前函数流程,执行延迟调用
-
而 recove r 在延迟调用函数中 可捕获并返回 panic 提交的错误对象
-
因为 panic 参数时空接口类型, 因此可使用任何对象作为错误标志。而 recover 返回结果同样需要转型才能获得具体信息
-
无论是否执行 recover,所有延迟调用都会被执行,但中断性错误会沿调用堆栈向外传递,要么被外场捕获,要么导致进程崩溃
-
recover 必须在延迟调用函数中执行才能正常工作
-
除非是不可恢复性、导致系统无法正常工作
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/17180826.html