Hadoop节点的分类与作用
文件的数据类型
文件有一个stat命令
- 元数据信息-->描述文件的属性
文件有一个vim命令
- 查看文件的数据信息
分类
- 元数据
File 文件名
Size 文件大小(字节)
Blocks 文件使用的数据块总数
IO Block 数据块的大小
regular file:文件类型(常规文件)
Device 设备编号
Inode 文件所在的Inode
Links 硬链接次数
Access 权限
Uid 属主id/用户
Gid 属组id/组名
Access Time:简写为atime,表示文件的访问时间。当文件内容被访问时,更新这个时间
Modify Time:简写为mtime,表示文件内容的修改时间,当文件的数据内容被修改时,更新这个时间。
Change Time:简写为ctime,表示文件的状态时间,当文件的状态被修改时,更新这个时间,例如文件的链接数,大小,权限,Blocks数。

文件数据
- 真实存在于文件中的数据
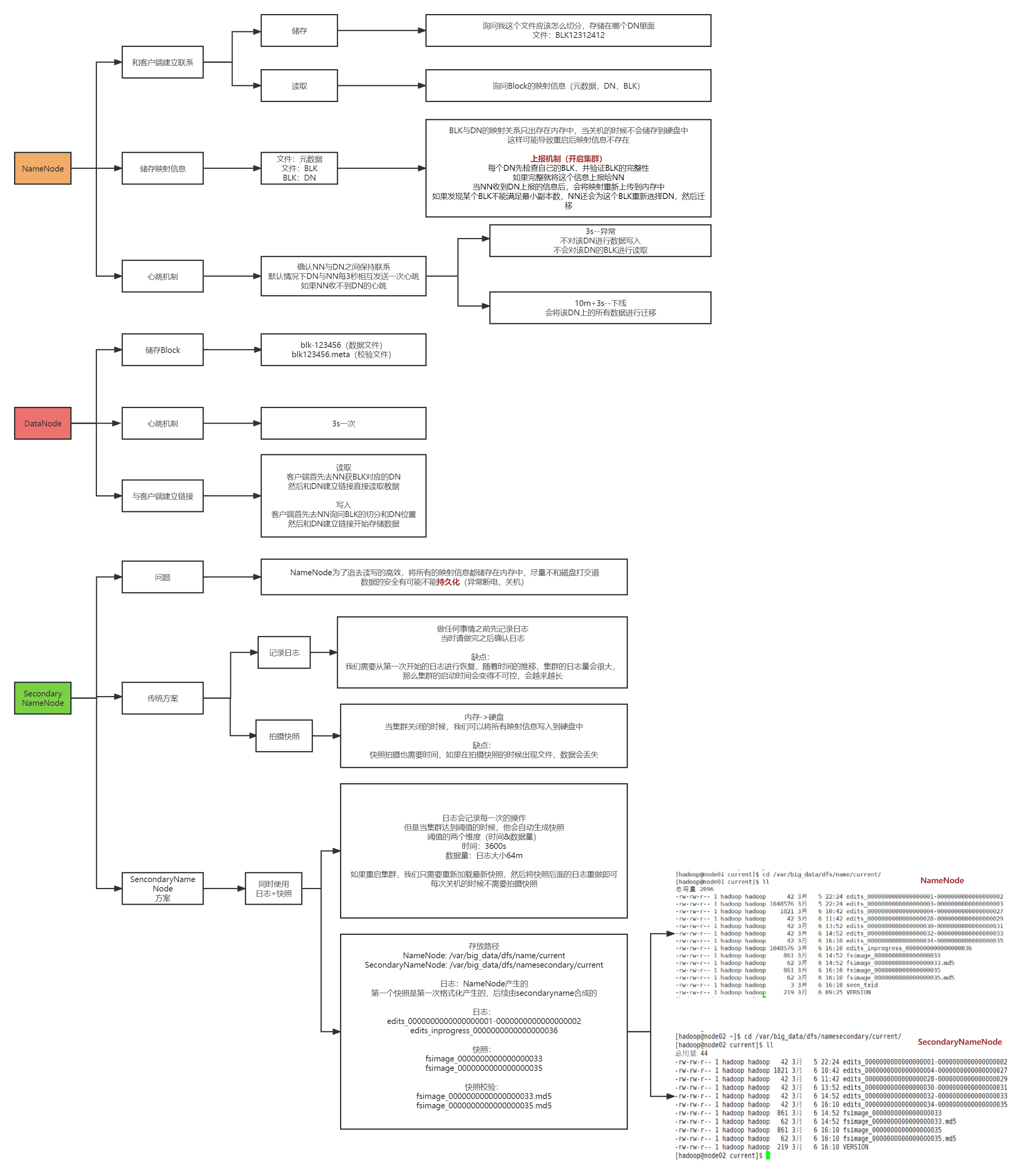
NameNode(NN)

功能
接受客户端的读写服务
-
NameNode存放文件与Block的映射关系
-
DataNode存放Block与DataNode的映射关系

保存文件的元数据信息
-
文件的归属
-
文件的权限
-
文件的大小时间
-
lock信息,但是block的位置信息不会持久化,需要每次开启集群的时候DN上报

收集Block的信息
-
系统启动时
- NN关机的时候是不会存储任意的Block与DN的映射信息
- DN启动的时候,会将自己节点上存储的Block信息汇报给NN
- NN接受请求之后重新生成映射关系
- Block--DN3
- 如果某个数据块的副本数小于设置数,那么NN会将这个副本拷贝到其他节点
-
集群运行中
- NN与DN保持心跳机制,三秒钟发送一次
<property> <description>Determines datanode heartbeat interval in seconds.</description> <name>dfs.heartbeat.interval</name> <value>3</value> </property> <property> <name>heartbeat.recheck.interval</name> <value>300000</value> </property>- 如果客户端需要读取或者上传数据的时候,NN可以知道DN的健康情况
- 可以让客户端读取存活的DN节点
-
如果DN超过三秒没有心跳,就认为DN出现异常
- 不会让新的数据读写到DataNode - 客户访问的时候不提供异常结点的地址-
如果DN超过10分钟+30秒没有心跳,那么NN会将当前DN存储的数据转存到其他节点
-
超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
-
-
性能
NameNode为了效率,将所有的操作都在内存中完成
-
NameNode不会和磁盘进行任何的数据交换
-
问题:
- 数据的持久化
- 数据保存在内存中,掉电易失
DataNode(DN)
功能
存放的是文件的数据信息和验证文件完整性的校验信息
-
数据会存放在硬盘上
-
1m=1条元数据 1G=1条元数据
-
NameNode非常排斥存储小文件,一般小文件在存储之前需要进行压缩
汇报
-
启动时
- 汇报之前先验证Block文件是否被损坏
- 向NN汇报当前DN上block的信息
-
运行中
- 向NN保持心跳机制
- 客户可以向DN读写数据
-
当客户端读写数据的时候,首先去NN查询file与block与dn的映射
- 然后客户端直接与dn建立连接,然后读写数据
SecondaryNameNode
传统解决方案
日志机制
-
做任何操作之前先记录日志
-
当NN下次启动的时候,只需要重新按照以前的日志“重做”一遍即可缺点
-
缺点
- edits文件大小不可控,随着时间的发展,集群启动的时间会越来越长
- 有可能日志中存在大量的无效日志
-
优点
- 绝对不会丢失数据
拍摄快照
我们可以将内存中的数据写出到硬盘上
- 序列化
启动时还可以将硬盘上的数据写回到内存中
- 反序列化
缺点
-
关机时间过长
-
如果是异常关机,数据还在内存中,没法写入到硬盘
-
如果写出频率过高,导致内存使用效率低(stop the world) JVM
优点
- 启动时间较短
SNN解决方案
解决思路(日志edits+快照fsimage)
让日志大小可控
- 定时快照保存
NameNode文件目录
- 查看目录

解决方案
当我们启动一个集群的时候,会产生四个文件
-
edits_0000000000000000001
-
fsimage_00000000000000000
-
seen_txid
-
VERSION
我们每次操作都会记录日志 -->edits_inprogress-000000001
随和时间的推移,日志文件会越来越大,当达到阈值的时候(64M 或 3600秒)
dfs.namenode.checkpoint.period 每隔多久做一次checkpoint ,默认3600s
dfs.namenode.checkpoint.txns 每隔多少操作次数做一次checkpoint,默认1000000次
fs.namenode.checkpoint.check.period 每个多久检查一次操作次数,默认60s
会生成新的日志文件
-
edits_inprogress-000000001 -->edits_0000001
-
创建新的日志文件edits_inprogress-0000000016

节点的分类与作用汇总图