
图论算法
图论算法
第一节 基本概念
一、什么是图?
很简单,点用边连起来就叫做图,严格意义上讲,图是一种数据结构,定义为:graph=(V,E)。V是一个非空有限集合,代表顶点(结点),E代表边的集合。
二、图的一些定义和概念
(a)有向图:图的边有方向,只能按箭头方向从一点到另一点。(a)就是一个有向图。 (b)无向图:图的边没有方向,可以双向。(b)就是一个无向图。
结点的度:无向图中与结点相连的边的数目,称为结点的度。 结点的入度:在有向图中,以这个结点为终点的有向边的数目。
结点的出度:在有向图中,以这个结点为起点的有向边的数目。
权值:边的“费用”,可以形象地理解为边的长度。
连通:如果图中结点U,V之间存在一条从U通过若干条边、点到达V的通路,则称U、V 是连通的。
回路:起点和终点相同的路径,称为回路,或“环”。
完全图:一个n 阶的完全无向图含有n*(n-1)/2 条边;一个n 阶的完全有向图含有n*(n-1)条边;
稠密图:一个边数接近完全图的图。
稀疏图:一个边数远远少于完全图的图。
强连通分量:有向图中任意两点都连通的最大子图。右图中,1-2-5构成一个强连通分量。特殊地,单个点也算一个强连通分量,所以右图有三个强连通分量:1-2-5,4,3。
三、图的存储结构
1.二维数组邻接矩阵存储
定义int G[101][101]; G[i][j]的值,表示从点i到点j的边的权值,定义如下:


建立邻接矩阵时,有两个小技巧:
初始化数组大可不必使用两重for循环。
1) 如果是int数组,采用memset(g, 0x7f, sizeof(g))可全部初始化为一个很大的数(略小于0x7fffffff),使用memset(g, 0, sizeof(g)),全部清为0,使用memset(g, 0xaf, sizeof(g)),全部初始化为一个很小的数。
2)如果是double数组,采用memset(g,127,sizeof(g));可全部初始化为一个很大的数1.38*10306,使用memset(g, 0, sizeof(g))全部清为0.
下面是建立图的邻接矩阵的参考程序段:
#include<iostream> using namespace std; int i,j,k,e,n; double g[101][101]; double w; int main() { int i,j; for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) g[i][j] = 0x7fffffff(赋一个超大值); //初始化,对于不带权的图g[i][j]=0,表示没有边连通。这里用0x7fffffff代替无穷大。 cin >> e; for (k = 1; k <= e; k++) { cin >> i >> j >> w; //读入两个顶点序号及权值 g[i][j] = w; //对于不带权的图g[i][j]=1 g[j][i] = w; //无向图的对称性,如果是有向图则不要有这句! } ………… return 0; }
2.数组模拟邻接表存储
图的邻接表存储法,又叫链式存储法。本来是要采用链表实现的,但大多数情况下只要用数组模拟即可。
以下是用数组模拟邻接表存储的参考程序段:
#include <iostream> using namespace std; const int maxn=1001,maxm=100001; struct Edge { int next; //下一条边的编号 int to; //这条边到达的点 int dis; //这条边的长度 }edge[maxm]; int head[maxn],num_edge,n,m,u,v,d; void add_edge(int from,int to,int dis) //加入一条从from到to距离为dis的单向边 { edge[++num_edge].next=head[from]; edge[num_edge].to=to; edge[num_edge].dis=dis; head[from]=num_edge; } int main() { num_edge=0; scanf("%d %d",&n,&m); //读入点数和边数 for(int i=1;i<=m;i++) { scanf("%d %d %d",&u,&v,&d); //u、v之间有一条长度为d的边 add_edge(u,v,d); } for(int i=head[1];i!=0;i=edge[i].next) //遍历从点1开始的所有边 { //... } //... return 0; }
两种方法各有用武之地,需按具体情况,具体选用。
第二节 图的遍历
一、深度优先与广度优先遍历
从图中某一顶点出发系统地访问图中所有顶点,使每个顶点恰好被访问一次,这种运算操作被称为图的遍历。
为了避免重复访问某个顶点,可以设一个标志数组visited[i],未访问时值为false,访问一次后就改为true。
图的遍历分为深度优先遍历和广度优先遍历两种方法,两者的时间效率都是O(n*n)。
1.深度优先遍历
深度优先遍历与深搜DFS相似,从一个点A出发,将这个点标为已访问visited[i]:=true;,然后再访问所有与之相连,且未被访问过的点。
当A的所有邻接点都被访问过后,再退回到A的上一个点(假设是B),再从B的另一个未被访问的邻接点出发,继续遍历。
例如对右边的这个无向图深度优先遍历,假定先从1出发 程序以如下顺序遍历: 1→2→5,然后退回到2,退回到1。
从1开始再访问未被访问过的点3 ,3没有未访问的邻接点,退回1。
再从1开始访问未被访问过的点4,再退回1 。
起点1的所有邻接点都已访问,遍历结束。
2.广度优先遍历
广度优先遍历并不常用,从编程复杂度的角度考虑,通常采用的是深度优先遍历。
广度优先遍历和广搜BFS相似,因此使用广度优先遍历一张图并不需要掌握什么新的知识,在原有的广度优先搜索的基础上,做一点小小的修改,就成了广度优先遍历算法。
二、一笔画问题
如果一个图存在一笔画,则一笔画的路径叫做欧拉路,如果最后又回到起点,那这个路径叫做欧拉回路。
我们定义奇点是指跟这个点相连的边数目有奇数个的点。对于能够一笔画的图,我们有以下两个定理。
定理1:存在欧拉路的条件:图是连通的,有且只有2个奇点。
定理2:存在欧拉回路的条件:图是连通的,有0个奇点。
两个定理的正确性是显而易见的,既然每条边都要经过一次,那么对于欧拉路,除了起点和终点外,每个点如果进入了一次,显然一定要出去一次,显然是偶点。对于欧拉回路,每个点进入和出去次数一定都是相等的,显然没有奇点。
求欧拉路的算法很简单,使用深度优先遍历即可。
根据一笔画的两个定理,如果寻找欧拉回路,对任意一个点执行深度优先遍历;找欧拉路,则对一个奇点执行DFS,时间复杂度为O(m+n),m为边数,n是点数。
以下是寻找一个图的欧拉路的算法实现:
样例输入:第一行n,m,有n个点,m条边,以下m行描述每条边连接的两点。
5 5
1 2
2 3
3 4
4 5
5 1
样例输出:欧拉路或欧拉回路
1 5 4 3 2 1
#include<iostream> #include<cstring> using namespace std; #define maxn 101 int g[maxn][maxn]; //此图用邻接矩阵存储 int du[maxn]; //记录每个点的度,就是相连的边的数目 int circuit[maxn]; //用来记录找到的欧拉路的路径 int n,e,circuitpos,i,j,x,y,start; void find_circuit(int i){ //这个点深度优先遍历过程寻找欧拉路 int j; for (j = 1; j <= n; j++) if (g[i][j] == 1) //从任意一个与它相连的点出发 { g[j][i] = g[i][j] = 0; find_circuit(j); } circuit[++circuitpos] = i; //记录下路径 } int main() { memset(g,0,sizeof(g)); cin >> n >> e; for (i = 1; i <= e; i++) { cin >> x >> y; g[y][x] = g[x][y] = 1; du[x]++; //统计每个点的度 du[y]++; } start = 1; //如果有奇点,就从奇点开始寻找,这样找到的就是 for (i = 1; i <= n; i++) //欧拉路。没有奇点就从任意点开始, if (du[i]%2 == 1) //这样找到的就是欧拉回路。(因为每一个点都是偶点) start = i; circuitpos = 0; find_circuit(start); for (i = 1; i <= circuitpos; i++) cout << circuit[i] << ' '; cout << endl; return 0; }
注意以上程序具有一定的局限性,对于下面这种情况它不能很好地处理:
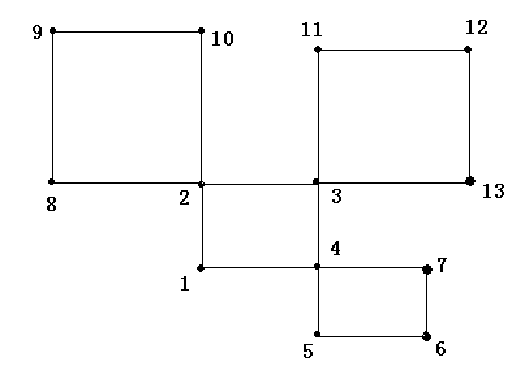
上图具有多个欧拉回路,而本程序只能找到一个回路。读者在遇到具体问题时,还应对程序作出相应的修改。
第三节 最短路径算法
如下图所示,我们把边带有权值的图称为带权图。边的权值可以理解为两点之间的距离。一张图中任意两点间会有不同的路径相连。最短路径就是指连接两点的这些路径中最短的一条。
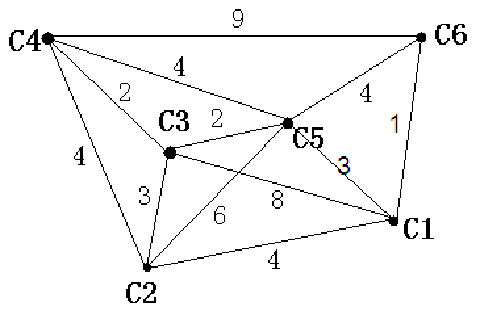
我们有四种算法可以有效地解决最短路径问题。有一点需要读者特别注意:边的权值可以为负。当出现负边权时,有些算法不适用。
一、求出最短路径的长度
以下没有特别说明的话,dis[u][v]表示从u到v最短路径长度,w[u][v]表示连接u,v的边的长度。 1.Floyed-Warshall算法 O(N3)
简称Floyed(弗洛伊德)算法,是最简单的最短路径算法,可以计算图中任意两点间的最短路径。Floyed的时间复杂度是O (N3),适用于出现负边权的情况。 算法描述: 初始化:点u、v如果有边相连,则dis[u][v]=w[u][v]。
如果不相连则dis[u][v]=0x7fffffff For (k = 1; k <= n; k++) For (i = 1; i <= n; i++) For (j = 1; j <= n; j++) If (dis[i][j] >dis[i][k] + dis[k][j]) dis[i][j] = dis[i][k] + dis[k][j]; 算法结束:dis[i][j]得出的就是从i到j的最短路径。
算法分析&思想讲解: 三层循环,第一层循环中间点k,第二第三层循环起点终点i、j,算法的思想很容易理解:如果点i到点k的距离加上点k到点j的距离小于原先点i到点j的距离,那么就用这个更短的路径长度来更新原先点i到点j的距离。 在上图中,因为dis[1][3]+dis[3][2]<dis[1][2],所以就用dis[1][3]+dis[3][2]来更新原先1到2的距离。 我们在初始化时,把不相连的点之间的距离设为一个很大的数,不妨可以看作这两点相隔很远很远,如果两者之间有最短路径的话,就会更新成最短路径的长度。Floyed算法的时间复杂度是O(N3)。
第四节 图的连通性问题
一、判断图中的两点是否连通
1、Floyed算法
时间复杂度:O(N3 )
算法实现: 把相连的两点间的距离设为dis[i][j]=true,不相连的两点设为dis[i][j]=false,用Floyed算法的变形:
for (k = 1; k <= n; k++)
for (i = 1; i <= n; i++)
for (j = 1; j <= n; j++)
dis[i][j] = dis[i][j] || (dis[i][k] && dis[k][j]);
最后如果dis[i][j]=true的话,那么就说明两点之间有路径连通。
2、遍历算法
时间复杂度:O(N2 )
算法实现: 从任意一个顶点出发,进行一次遍历,能够从这个点出发到达的点就与起点是联通的。
这样就可以求出此顶点和其它各个顶点的连通情况。
所以只要把每个顶点作为出发点都进行一次遍历,就能知道任意两个顶点之间是否有路存在。
可以使用DFS实现。
有向图与无向图都适用。
二、求有向图的强连通分量
Kosaraju算法可以求出有向图中的强连通分量个数,并且对分属于不同强连通分量的点进行标记。
它的算法描述较为简单: (1) 第一次对图G进行DFS遍历,并在遍历过程中,记录每一个点的退出顺序。以下图为例:
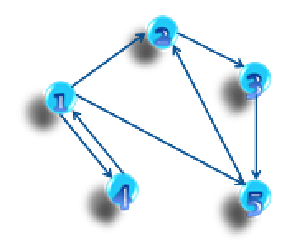

如果以1为起点遍历,访问结点的顺序如下:

结点第二次被访问即为退出之时,那么我们可以得到结点的退出顺序:

(2)倒转每一条边的方向,构造出一个反图G’。
然后按照退出顺序的逆序对反图进行第二次DFS遍历。我们按1、4、2、3、5的逆序第二次DFS遍历:
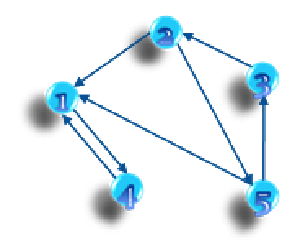

访问过程如下:

每次遍历得到的那些点即属于同一个强连通分量。
1、4属于同一个强连通分量,2、3、5属于另一个强连通分量。
本文来自博客园,作者:张其勋,转载请注明原文链接:https://www.cnblogs.com/zhangqixun/p/17206839.html