
装箱算法的性能测试
笔者第一次对算法做性能测试,记录本次测试的过程,方便以后复盘。
项目的背景是新提交了一个需求,在每个b2c出库订单入库时,给订单一个合适的推荐箱型。订单的sku属性中有长宽高,包材管理的表中也有各包材的长宽高。需要推荐一个能装下的最小包材,并且体积占比低于90%,剩余大于等于10%空间留给冷媒和充气柱。以下是产品提出的初步流程图:
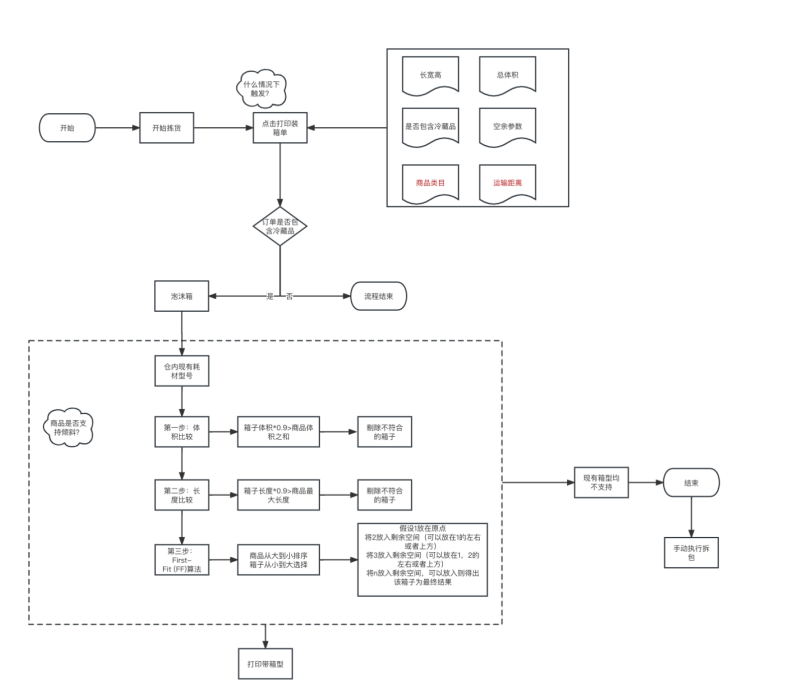
在需求评审阶段,我提出了以下问题:
1、在订单入库的阶段就给了推荐箱型,那如果修改了商品或包材的长宽高,可能会导致推荐的包材过大(不是最优解)或者放不下,怎么处理?
2、实际的sku很多是不规则的,怎么去计算?
3、如果所有单个包材都装不下,应该怎么推荐?
4、包材推荐的优先级怎么设置?比如计算得出的最优的包材是包材管理中仓库所属的包材,属于通用包材,而货主指定了自己的专属包材,那优先选用哪一个?
5、商品和包材的长宽高不是必填字段,为空怎么处理?
在设计评审阶段,开发同事去了解了相关的算法之后,向产品同事提出过一些问题。
6、使用该算法的前提是商品视做长*宽*高规则的长方体。
7、商品sku过多,计算超时怎么处理?
8、实际装箱商品可以斜放,但是选用的算法是一种正交摆放的方式,不考虑商品翻转,只能在一个类似坐标轴中正正方方的摆放(从包材的一个角斜插到另一个角不被允许)。
在产品同事一一解答并三方确认后,对以上问题做出解答并记录。
1、实际业务中sku和包材的基础资料几乎不会修改,因此不考虑后续修改商品或包材参数;
2、因为开发的问题6,所以商品视作规则长方体;
3、单个包材如果装不下推荐一栏置空;
4、实际业务中,商家有提供包材则仓内通常只提供打包服务,优先考虑所有专属包材,都不满足再考虑通用包材;
5、长宽高任意为空则跳过,置空;
6、使用该算法的前提是商品视做长*宽*高规则的长方体;
7、sku数量参数这一块根据具体性能测试结果定;
8、只支持正交摆放。
有了以上的需求评审和问题评审对一系列问题在开会过程中统一意见后,开发同事开始了编码,我则开始进行测试用例的设计,依旧是按照等价类、边界值、场景法和错误推定法设计了一些功能的测试用例。在进行用例评审过后,执行功能测试,发现bug提交,验证功能bug修复后,开始了性能测试。
分析整个场景,在高并发场景下,多个b2c订单同时下发到我们wms系统中,需要能够快速的给出推荐箱型,并在接下来的出库流程中的总拣过程中在打印的拣货单上给到各订单的推荐箱型。在之前的压测过程中,已得出系统支持200qps程度的并发。因此本次压测的期望就是在200qps的情况下,能够给出推荐箱型,不影响后续出库流程。
与此同时,我去简单了解了下装箱算法。装箱算法是典型的世界难题,属于算法中的NP一HARD问题,从数学家高斯时期开始研究开始到现在已有百余年的历史。虽然经过几代人的努力,但迄今尚无成熟的理论和有效的数值计算方法,由于目前NP完全问题不存在有效时间内求得精确解的算法,装箱问题的求解极为困难,因此,从70~80年代开始,陆续提出的装箱算法都是各种近似算法。同事使用的算法基本思想是一种将商品视作在坐标轴中,以包材的长宽高作为坐标轴,以商品(规则长方体)在坐标轴中的位置,将装箱问题转化为一元三次不等式方程组的求解。
在功能测试阶段,已经发现有性能问题,在单个订单的数量超过50个sku后,获取面单的速度明显变慢。和开发同事沟通,他为了开发进度考虑,没有走集团内部资源申请流程,没申请新的redis资源,而是将装箱计算的方法写在了获取面单号的模块中。为了具体得出每次装箱推荐的时间,让开发同事加了打印日志,观察到后台在50个sku以上,推荐箱型的消耗时间会超过3s,对比20个sku只需要0.2s左右(这里就是算法的弱点,每多1个sku,排列组合的方式是呈指数方式增长的,因此计算耗时也大大增加,20到50个sku,增长了1.5倍,但是耗时增长了约15倍),则200个订单需要多出600s(约10min)的计算时间,而此前200个订单获取面单号的时间仅需要耗时30-40s。这种设计方案是严重阻碍实际业务场景中,b2c订单出库的,因此需要改动。而且测试中发现,单个订单在300个sku以后,会导致系统崩溃。结合rancher中top命令下服务器的CPU占用,发现此时CPU占用达到207%,推断是有指数增长情况下,300个sku的计算难度和时间以目前的服务器cpu性能都不足以完成。再次分析实际业务中,50个以上的sku很大可能单个包材是装不下的,这部分可以由仓库人员灵活处理,因此增加判断条件,sku>50则跳过箱型推荐。为了安全起见,加上了判断条件,单个订单的箱型推荐,如果计算超过15s,则终止计算。
第一次改动,拆分了两个队列,加上了计算上限是sku=50。
在申请了单独的kafka资源作为队列后,获取面单号成为了单独的流程,恢复到了每分钟350个单号左右的效率。使用jmeter同时推送200个订单,发现系统再次崩溃,此时观察到rancher中top命令下服务器的内存,发现此时内存占用达到102%,但是有少量订单完成了箱型推荐,分析推断是存在内存泄露。在和开发同事沟通后,得知他参照获取面单接口的操作流程,同样是每个线程每次获取50个b2c订单作为一组去执行,但是执行完成后没有释放内存,仍然进行下一个线程的调用,存在内存泄露,因此要求他修改,于是改为了进程每次调用一组订单前,需要申请服务器内存,完成一组订单的装箱推荐计算后,需要释放服务器内存。这样的设计在1个订单1个sku的时候,发现耗时需要0.14s,即每次申请资源和释放资源需要固定的0.14s时间作为额外的性能开销,经过和开发同事的讨论,这个时间是完全可以接受的。
第二次改动,将每个进程调取一组订单前后,分别申请服务器内存和释放服务器内存。
在经过2次设计的修改后,终于程序支持200qps情况下装箱推荐了,极限情况下是200单,每单50个sku需要600s获取箱型推荐,但是并不会影响正常的出库流程。以当前生产环境wms的日单量判断和80%的爆品单集中在10个sku以内,可以得出结论,性能满足当前的业务需求,测试通过,允许发布。