
SqlServer 高并发的情况下,如何利用锁保证数据的稳定性
sql的锁机制,是时刻贯彻在每一次的sql事务中的,为了理解更透彻,介绍锁之前,我们得先了解,锁是为了干什么!!
1、数据库异常情况
1.1 先来聊聊数据可能发生个异常状况
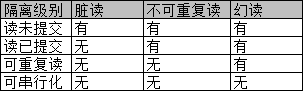
1)脏读:读未提交,顾名思义,读到了不该读的东西,如:

事务B读到了事务A回滚的数据,就是脏读
2)不可重复读:读已提交,同个事务内,多次读取同个数据,却返回不同结果,偏向数据更新

事务B发生了不可重复读
3) 幻读:同个事务内,因其他事务插入或删除数据,导致读取到不同的数据量(本质和不可重复读相似)

事务B发生了幻读
1.2 数据库用什么机制来处理这些异常情况的发生,四种隔离级别
1)读未提交(Read Uncommitted):发生脏读,基本没有数据库使用这个级别了
2)读已提交(Read Committed):大多数数据库系统的默认隔离级别,解决了脏读问题
3)可重复读(Repeatable Read):同一事务的多个实例在并发读取数据时,会看到同样的数据,解决了不可重复读问题
4)可串行化(Serializable):这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。但可能导致大量的超时现象和锁竞争
总结:四种级别越往后越影响性能,但数据越稳定,实现机制就是"锁";
2、都有什么锁
2.1锁的种类:
1)共享锁:其他事务可select,无法被update、delete、insert
2)排他锁:其他事务不可任何操作
2.2粒度提示:
1)rowlock:行锁,指定到行,select * from dual where id=1会默认行锁
2)paglock:页锁,select * from dual会默认页锁,select的时候先锁定第一页,读取后释放,再锁定第二页,直到读完
3)tablock:表锁,语句结束解锁
4)tabockx:表锁,排他锁。
5)nolock:取消默认锁,涉及大量删除数据的时候可能会堵塞进程,如果需要select,可以加上nolock来过滤掉需要删除的数据
6)holdlock:保持共享锁,数据库会根据sql操作加默认锁
7)serializable:同holdlock
8)readcommited:遵循读已提交隔离级别
9)updlock:更新锁,排他锁
3、举例子
3.1 模拟场景,多个客户在抢一个优惠券
客户:kxy
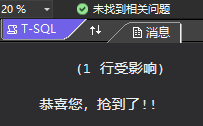
begin tran declare @_owner varchar(100); set @_owner = (select owner from Coupons with(updlock) where id=2); if(@_owner is null or @_owner='') begin update Coupons set owner='kxy' where id=2 waitfor delay '00:00:10' print '恭喜您,抢到了!!' end; else print '该券已经被抢了!!' commit tran
客户:keys
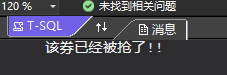
begin tran declare @_owner varchar(100); set @_owner = (select owner from Coupons with(updlock) where id=2); if(@_owner is null or @_owner='') begin update Coupons set owner='keys' where id=2 waitfor delay '00:00:10' print '恭喜您,抢到了!!' end; else print '该券已经被抢了!!' commit tran
用代码进行抢券,同个时间先后执行kxy和keys抢券
结果:
kxy
keys
持续更新,感谢关注!!!