
深度学习之PyTorch实战(4)——迁移学习
(这篇博客其实很早之前就写过了,就是自己对当前学习pytorch的一个教程学习做了一个学习笔记,一直未发现,今天整理一下,发出来与前面基础形成连载,方便初学者看,但是可能部分pytorch和torchvision的API接口已经更新了,导致部分代码会产生报错,但是其思想还是可以借鉴的。
因为其中内容相对比较简单,而且目前其实torchvision中已经存在现成的VGG模型及其预训练模型,所以不建议看到这篇博客的盆友花费过多时间敲写学习)
========下面是5年前的正文:
我们在前三篇博客学会了使用自己搭建的卷积神经网络模型解决手写图片识别的问题,因为卷积神经网络在解决计算机视觉问题上有着独特的优势,所以采用简单的神经网络模型就能使手写图片识别的准确率达到很高的水平。不过,用来训练和测试模型的手写图片数据的特征非常明显,所以也很容易被卷积神经网络模型捕获到。
本次将搭建卷积神经网络模型对生活中普通图片进行分类,并进入迁移学习(Transfer Learning)方法。为了验证迁移学习方法的方便性和高效性,我们先使用自定义结构的卷积神经网络模型解决图片的分类问题,然后通过使用迁移学习方法得到的模型来解决同样的问题,以此来看看在效果上是传统的方法更出色还是迁移学习方法更出色。
一:迁移学习入门
在开始之前,我们先来了解一下什么是迁移学习。在深度神经网络算法的应用过程中,如果我们面对的是数据规模较大的问题,那么在搭建好深度神经网络模型后,我们势必要花费大量的算力和时间去训练模型和优化参数,最后耗费了这么多资源得到的模型只能解决这一个问题,性价比非常低。如果我们用这么多资源训练的模型能够解决同一类问题,那么模型的性价比会提高很多,这就促使使用迁移模型解决同一类问题的方法出现。因为该方法的出现,我们通过对一个训练好的模型进行细微调整,就能将其应用到相似的问题中,最后还能取得很好的效果;另外,对于原始数据较少的问题,我们也能够通过采用迁移模型进行有效解决,所以,如果能够选取合适的迁移学习方法,则会对解决我们所面临的问题有很大的帮助。
假如我们现在需要解决一个计算机视觉的图片分类问题,需要通过搭建一个模型对猫和狗的图片进行分类,并且提供了大量的猫和狗的图片数据集。假如我们选择使用卷积神经网络模型来解决这个图片分类问题,则首先要搭建模型,然后不断对模型进行训练,使其预测猫和狗的图片的准确性达到要求的阈值,在这个过程中会消耗大量的时间在参数优化和模型训练上。不久之后我们又面临另一个图片分类问题,这次需要搭建模型对猫和狗的图片进行分类,同样提供了大量的图片数据集,如果已经掌握了迁移学习方法,就不必再重新搭建一套全新的模型,然后耗费大量的时间进行训练了,可以直接使用之前已经得到的模型和模型的参数并稍加改动来满足新的需求。不过,对迁移的模型需要进行重新训练,这是因为最后分类的对象发生了变化,但是重新训练的时间和搭建全新的模型进行训练的时间相对很少,如果调整的仅仅是迁移模型的一小部分,那么重新训练所耗费的时间会更少。通过迁移学习可以节省大量的时间和精力,而且最终得到的结果不会太差,这就是迁移学习的优势和特点。
需要注意的是,在使用迁移学习的过程中有时会导致迁移模型出现负迁移,我们可以将其理解为模型的泛化能力恶化。假如我们将迁移学习用于解决两个毫不相关的问题,则极有可能使最后迁移得到的模型出现负迁移。
(下面迁移学习内容参考:https://my.oschina.net/u/876354/blog/1614883)
1.1,什么是迁移学习?
迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。
通过,源领域数据量充足,而目标领域数据量较小,这种场景就很适合做迁移学习,例如我们要对一个任务进行分类,但是此任务中数据不重复(目标域),然而却又大量的相关的训练数据(源域),但是此训练数据与所需进行的分类任务中的测试数据特征分布不同(例如语音情感识别中,一种语言的语音数据充足,然而所需进行分类任务的情况数据却极度缺乏),在这种情况下如果可以采用合适的迁移学习方法则可以大大提高样本不充足任务的分类识别结果。
1.2,为什么现在需要迁移学习?
前百度首席科学家,斯坦福的教授吴恩达(Andrew Ng)在曾经说过:“迁移学习将会是继监督学习之后的下一个机器学习商业成功的驱动力”。
在2016年的NIPS会议上,吴恩达给出了一个未来AI方向的技术发展图,还是很客观的:
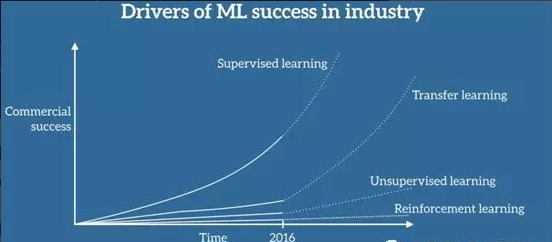
毋庸置疑,监督学习是目前成熟度最高的,可以说已经成功商用,而下一个商用的技术将会是迁移学习(Transfer Learning),这也是Andrew 预测未来五年最有可能走向商用的 AI 技术。
吴恩达在一次采访中,也提到迁移学习会是一个很有活力的领域,我们之所以对迁移学习感到兴奋,其原因在于现代深度学习的巨大价值是针对我们拥有海量数据的问题。但是,也有很多问题领域,我们没有足够数据。比如语音识别。在一些语言中,比如普通话,我们有很多数据,但是那些只有少数人说的语言,我们的数据就不够庞大。所以,为了针对数据量不那么多的中国少数人所说的方言进行语音识别,能将从学习普通话中得到的东西进行迁移吗?我们的技术确实可以做到这一点,我们也正在做,但是,这一领域的进步能让人工智能有能力解决广泛得多的问题。
1.3,传统机器学习和迁移学习有什么不同呢?
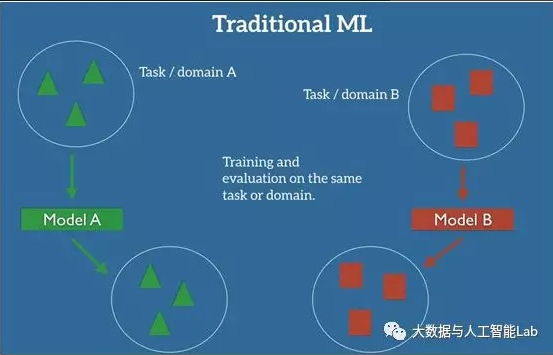
在机器学习的经典监督学习场景中,如果我们要针对一些任务和域A训练一个模型,我们会假设被提供了针对同一个域和任务的标签数据。如下图所示,其中我们的模型A在训练数据和测试数据中的域和任务都是一样的。
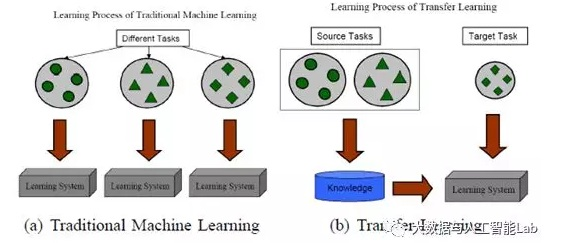
即使是跟迁移学习比较相似的多任务学习,多任务学习是对目标域和源域进行共同学习,而迁移学习主要是对通过对源域的学习解决目标域的识别任务。下图就展示了传统的机器学习和迁移学习的区别:
1.4,什么适合迁移?
在一些学习任务中有一些特征是个体所特有的,这些特征不可以迁移。而有些特征是所有的个体中具有贡献的,这些可以进行迁移。
有些时候如果迁移的不合适则导致负迁移,例如当源域和目标域的任务毫不相关时有可能会导致负迁移。
1.5,迁移学习的分类
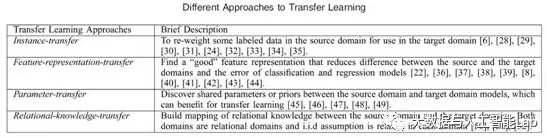
根据 Sinno Jialin Pan 和 Qiang Yang 在TKDE 2010上的文章,可将迁移学习算法,根据所需要的迁移知识表示形式(即 what to transfer ),分为四类:
- 1,基于实例的迁移学习(instance-based transfer learning):源领域(source domain)中的数据(data)的某一部分可以通过 reweighting 的方法重用,用于 target domain 的学习。
- 2,基于特征表示的迁移学习(feature-representation transfer learning):通过 source domain 学习一个好的(good)的特征表示,把知识通过特征的形式进行编码,并从 source domain 传递到 target domain ,提升 target domain 任务效果。
- 3,基于参数的迁移学习(parameter-transfer learning):target domain和source domain的任务之间共享相同的模型参数(model parameters)或者是服从相同的先验分布(prior distribution)。
- 4,基于关系知识迁移学习(relational-knowledge transfer learning):相关领域之间的知识迁移,假设 source demain 和 target domain中,数据(data)之间联系关系是相同的。
前三类迁移学习方式都要求数据(data)独立同分布假设。同时,四类迁移学习方式都要求选择 source domain和 target domain 相关。
下表给出了迁移内容的迁移学习分类:
1.6,迁移学习的应用与价值
1.6.1 迁移学习的应用
用于情感分类,图像分类,命名实体识别,WiFi信号定位,自动化设计,中文到英文翻译等问题。
1.6.2 迁移学习的价值
- 1,复用现有知识域数据,已有的大量的工作不至于完全丢弃
- 2,不需要再去花费巨大代价去重新采集和标定庞大的新数据局,也有可能数据根本无法获取
- 3,对于快速出现的新领域,能够快速迁移和应用,体现时效性优势
总之,迁移学习将会成为接下来令人兴奋的研究方向,特别是许多应用需要能够将知识迁移到新的任务和域中的模型,将会成为人工智能的又一个重要助推力。
二:数据集处理
本文使用的数据集来自Kaggle网站上的“Dogs vs.Cats”竞赛项目,可以通过网络免费下载这些数据集。在这个数据集的训练数据集中一共有25000张猫和狗的图片,其中包含12500张猫的图片和12500张狗的图片。在测试数据集中有12500张图片,不过其中的猫狗图片是无序混杂的,而且没有对应的标签。这些数据集将被用于对模型进行训练和对参数进行优化,以及在最后对模型的泛化能力进行验证。
官方下载地地址 https://www.kaggle.com/c/dogs-vs-cats/data
2.1 验证数据集和测试数据集
在实践中,我们不会直接使用测试数据集对搭建的模型进行训练和优化,而是在训练数据集中划出一部分作为验证集,来评估在每个批次的训练后模型的泛化能力。这样做的原因是如果我们使用测试数据集进行模型训练和优化,那么模型最终会对测试数据集产生拟合倾向,换而言之,我们的模型只有在对测试数据集中图片的类别进行预测时才有极强的准确率,而在对测试数据集以外的图片类别进行预测时会出现非常多的错误,这样的模型缺少泛化能力。所以,为了防止这种情况的出
现,我们会把测试数据集从模型的训练和优化过程中隔离出来,只在每轮训练结束后使用。如果模型对验证数据集和测试数据集的预测同时具备高准确率和低损失值,就基本说明模型的参数优化是成功的,模型将具备极强的泛化能力。在本章的实践中我们分别从训练数据集的猫和狗的图片中各抽出 2500 张图片组成一个具有5000张图片的验证数据集。
我们也可以将验证数据集看作考试中的模拟训练测试,将测试数据集看作考试中的最终测试,通过两个结果看测试的整体能力,但是测试数据集最后会有绝对的主导作用。不过本章使用的测试数据集是没有标签的,而且本章旨在证明迁移学习比传统的训练高效,所以暂时不使用在数据集中提供的测试数据集,我们进行的只是模型对验证数据集的准确性的横向比较。
2.2 数据预览
在划分好数据集之后,就可以进行数据预览了,我们通过数据预览可以掌握数据的基本信息,从而更好地决定如何使用这些数据。
开始的部分代码如下:
import torch import torchvision from torchvision import datasets from torchvision import transforms import os import matplotlib.pyplot as plt import time
在以上的代码中先导入了必要的包,之之前不同的是新增加了os包和time包,os包集成了一些对文件路径和目录进行操作的类,time包主要是一些和时间相关的方法。
在获取全部的数据集之后,我们就可以对这些数据进行简单分类了。新建一个名为DogsVSCats的文件夹,在该文件夹下面新建一个名为train和一个名为valid的子文件夹,在子文件夹下面再分别新建一个名为cat的文件夹和一个名为dog的文件夹,最后将数据集中对应部分的数据放到对应名字的文件夹中,之后就可以进行数据的载入了。对数据进行载入的代码如下:
data_dir = "DogsVSCats"
data_transform = {x:transforms.Compose([transforms.Scale([64,64]),
transforms.ToTensor()])
for x in ["train","valid "]}
image_datasets = {x:datasets.ImageFolder(root=os.path.join(data_dir,x),
transform=data_transform[x])
for x in ["train","valid"]}
dataloader = {x:torch.utils.data.DataLoader(dataset = image_datasets[x],
batch_size = 16,
shuffle = True)
for x in ["train","valid"]}
在进行数据的载入时我们使用torch.transforms中的Scale类将原始图片的大小统一缩放至64×64。在以上代码中对数据的变换和导入都使用了字典的形式,因为我们需要分别对训练数据集和验证数据集的数据载入方法进行简单定义,所以使用字典可以简化代码,也方便之后进行相应的调用和操作。
os.path.join就是来自之前提到的 os包的方法,它的作用是将输入参数中的两个名字拼接成一个完整的文件路径。其他常用的os.path类方法如下:
(1)os.path.dirname :用于返回一个目录的目录名,输入参数为文件的目录。
(2)os.path.exists :用于测试输入参数指定的文件是否存在。
(3)os.path.isdir :用于测试输入参数是否是目录名。
(4)os.path.isfile :用于测试输入参数是否是一个文件。
(5)os.path.samefile :用于测试两个输入的路径参数是否指向同一个文件。
(6)os.path.split :用于对输入参数中的目录名进行分割,返回一个元组,该元组由目录名和文件名组成
下面获取一个批次的数据并进行数据预览和分析,代码如下:
X_example,y_example = next(iter(dataloader['train']))
以上代码通过next和iter迭代操作获取一个批次的装载数据,不过因为受到我们之前定义的batch_size值的影响,这一批次的数据只有16张图片,所以X_example和y_example的长度也全部是16,可以通过打印这两个变量来确认。打印输出的代码如下:
print(u"X_example 个数{}".format(len(X_example)))
print(u"y_example 个数{}".format(len(y_example)))
输出结果如下:
X_example 个数16 y_example 个数16
其中,X_example是Tensor数据类型的变量,因为做了图片大小的缩放变换,所以现在图片的大小全部是64×64了,那么X_example的维度就是(16, 3, 64, 64),16代表在这个批次中有16张图片;3代表色彩通道数,因为原始图片是彩色的,所以使用了R、G、B这三个通道;64代表图片的宽度值和高度值。
y_example也是Tensor数据类型的变量,不过其中的元素全部是0和1。为什么会出现0和1?这是因为在进行数据装载时已经对dog文件夹和cat文件夹下的内容进行了独热编码(One-Hot Encoding),所以这时的0和1不仅是每张图片的标签,还分别对应猫的图片和狗的图片。我们可以做一个简单的打印输出,来验证这个独热编码的对应关系,代码如下:
index_classes = image_datasets["train"].class_to_idx print(index_classes)
输出的结果如下:
{'cat': 0, 'dog': 1}
这样就很明显了,猫的图片标签和狗的图片标签被独热编码后分别被数字化了,相较于使用文字作为图片的标签而言,使用0和1也可以让之后的计算方便很多。不过,为了增加之后绘制的图像标签的可识别性,我们还需要通过image_datasets["train"].classes将原始标签的结果存储在名为example_clasees的变量中。代码如下:
['cat', 'dog']
example_clasees变量其实是一个列表,而且在这个列表中只有两个元素,分别是dog和cat。
打印输出的该批次的所有图片的标签结果如下:
['dog', 'dog', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'dog', 'dog']
标签对应的图片如图所示

三:模型搭建和参数优化
本节会先基于一个简化的VGGNet架构搭建卷积神经网络模型并进行模型训练和参数优化,然后迁移一个完整的VGG16架构的卷积神经网络模型,最后迁移一个ResNet50架构的卷积神经网络模型,并对比这三个模型在预测结果上的准确性和在泛化能力上的差异。
3.1 自定义VGGNet
我们首先需要搭建一个卷积神经网络模型,考虑到训练时间的成本,我们基于VGG16架构来搭建一个简化版的VGGNet模型,这个简化版模型要求输入的图片大小全部缩放到64×64,而在标准的VGG16架构
模型中输入的图片大小应当是224×224的;同时简化版模型删除了VGG16最后的三个卷积层和池化层,也改变了全连接层中的连接参数,这一系列的改变都是为了减少整个模型参与训练的参数数量。简化版模型的搭建代码如下:
# 自定义VGGNet
# 基于VGG16架构一个简化版的VGGNet模型 简化吧的VGG16图片全部缩放到64*64
# 而标准的VGG模型输入的图片应该是224*224
class Modles(torch.nn.Module):
def __init__(self):
super(Modles,self).__init__()
self.Conv = torch.nn.Sequential(
torch.nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64,64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2,stride=2),
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(128,128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(128,256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(256,256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(256,512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512,512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512,512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
)
self.Classes = torch.nn.Sequential(
torch.nn.Linear(4*4*512,1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024,1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024,2)
)
def forward(self, input):
x = self.Conv(input)
x = x.view(-1,4*4,512)
x = self.Classes(x)
return x
在搭建好模型后,通过 print 对搭建的模型进行打印输出来显示模型中的细节,打印输出的代码如下:
model = Models() print(model)
输出的内容如下:
Modles(
(Conv): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU()
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU()
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU()
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU()
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU()
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU()
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU()
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(Classes): Sequential(
(0): Linear(in_features=8192, out_features=1024, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=1024, out_features=1024, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=1024, out_features=2, bias=True)
)
)
然后,定义好模型的损失函数和对参数进行优化的优化函数,代码如下;
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr = 0.00001)
epoch_n = 10
time_open = time.time()
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch,epoch_n-1))
print("-"*10)
for phase in ["train","valid"]:
if phase == "train":
print("Training...")
model.train(True)
else:
print("Validing...")
model.train(False)
running_loss = 0.0
running_corrscts = 0
for batch,data in enumerate(dataloader[phase],1):
X,y = data
X,y = Variable(X),Variable(y)
y_pred = model(X)
_,pred = torch.max(y_pred.data,1)
optimizer.zero_grad()
loss = loss_f(y_pred,y)
if phase == "train":
loss.backward()
optimizer.step()
running_loss += loss.data[0]
running_corrects += torch.sum(pred == y.data)
if batch%500 == 0 and phase == 'train':
print("Batch{},Train Loss:{:.4f},Train ACC:{:.4f}".format(
batch,running_loss/batch,100*running_corrects/(16*batch)
))
epoch_loss = running_loss*16/len(image_datasets[phase])
epoch_acc = 100*running_corrects/len(image_datasets[phase])
print("{} Loss:{:.4f} Acc:{:.4f}%".format(phase,epoch_loss,epoch_acc))
time_end = time.time() - time_open
print(time_end)
在代码中优化函数使用的是Adam,损失函数使用的是交叉熵,训练次数总共是10 次,最后的输出结果如下(这是书原文的结果,这里直接复制粘贴过来)



虽然准确率不错,但因为全程使用了计算机的 CPU进行计算,所以整个过程非常耗时,约为492分钟(492=29520/60)。下面我们对原始代码进行适当调整,将在模型训练的过程中需要计算的参数全部迁移至GPUs上,这个过程非常简单和方便,只需重新对这部分参数进行类型转换就可以了,当然,在此之前,我们需要先确认GPUs硬件是否可用,具体的代码如下:
# print(torch.cuda.is_available()) # Use_gpu = torch.cuda.is_available()
打印输出的结果如下:
True
返回的值是True,这说明我们的GPUs已经具备了被使用的全部条件,如果遇到False,则说明显卡暂时不支持,如果是驱动存在问题,则最简单的办法是将显卡驱动升级到最新版本。
在完成对模型训练过程中参数的迁移之后,新的训练代码如下:
print(torch.cuda.is_available())
Use_gpu = torch.cuda.is_available()
if Use_gpu:
model = model.cuda()
epoch_n = 10
time_open = time.time()
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch,epoch_n-1))
print("-"*10)
for phase in ["train","valid"]:
if phase == "train":
print("Training...")
model.train(True)
else:
print("Validing...")
model.train(False)
running_loss = 0.0
running_corrscts = 0
for batch,data in enumerate(dataloader[phase],1):
X,y = data
if Use_gpu:
X, y = Variable(X.cuda()), Variable(y.cuda())
else:
X,y = Variable(X),Variable(y)
y_pred = model(X)
_,pred = torch.max(y_pred.data,1)
optimizer.zero_grad()
loss = loss_f(y_pred,y)
if phase == "train":
loss.backward()
optimizer.step()
running_loss += loss.item()
running_corrscts += torch.sum(pred == y.data)
if batch%500 == 0 and phase == 'train':
print("Batch{},Train Loss:{:.4f},Train ACC:{:.4f}".format(
batch,running_loss/batch,100*running_corrscts/(16*batch)
))
epoch_loss = running_loss*16/len(image_datasets[phase])
epoch_acc = 100*running_corrscts/len(image_datasets[phase])
print("{} Loss:{:.4f} Acc:{:.4f}%".format(phase,epoch_loss,epoch_acc))
time_end = time.time() - time_open
print(time_end)
在以上代码中,model = model.cuda()和X, y = Variable(X.cuda()),Variable(y.cuda())就是参与迁移至GPUs的具体代码,在进行10次训练后,输出的结果如下



从结果可以看出,不仅验证测试集的准确率提升了近10%,而且最后输出的训练耗时缩短到了大约14分钟(14=855/60),与之前的训练相比,耗时大幅下降,明显比使用CPU进行参数计算在效率上高出不少。
到目前为止,我们构建的卷积神经网络模型已经具备了较高的预测准确率了,下面引入迁移学习来看看预测的准确性还能提升多少,看看计算耗时能否进一步缩短。在使用迁移学习时,我们只需对原模型的结构进行很小一部分重新调整和训练,所以预计最后的结果能够有所突破。
3.2 迁移VGG16
下面看看迁移学习的具体实施过程,首先需要下载已经具备最优参数的模型,这需要对我们之前使用的 model = Models() 代码部分进行替换,因为我们不需要再自己搭建和定义训练的模型了,而是通过代码自动下载模型并直接调用,具体代码如下:
model = models.vgg16(prepare = True)
在以上代码中,我们指定进行下载的模型是VGG16,并通过设置prepare = True 中的值为True,来实现下载的模型附带了已经优化好的模型参数。这样,迁移的第一步就完成了,如果想要看迁移的细节,就可以通过print 将其打印输出,输出的结果如下:



下面开始进行迁移学习的第二步,对当前迁移过来的模型进行调整,尽管迁移学习要求我们需要解决的问题之间最好具有很强的相似性,但是每个问题对最后输出的结果会有不一样的要求,而承担整个模型输出分类工作的是卷积神经网络模型中的全连接层,所以在迁移学习的过程中调整最多的也是全连接层部分。其基本思想是冻结卷积神经网络中全连接层之前的全部网络层次,让这些被冻结的网络层次中的参数在模型的训练过程中不进行梯度更新,能够被优化的参数仅仅是没有被冻结的全连接层的全部参数。
下面看看具体的代码。首先,迁移过来的VGG16架构模型在最后输出的结果是1000个,在我们的问题中只需要两个输出结果,所以全连接层必须进行调整。模型调整的具体代码如下:
for parma in model.parameters():
parma.requires_grad = False
model.classifier = torch.nn.Sequential(torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 2))
if Use_gpu:
model = model.cuda()
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.00001)
首先,对原模型中的参数进行遍历操作,将参数中的parma.requires_grad全部设置为False,这样对应的参数将不计算梯度,当然也不会进行梯度更新了,这就是之前说到的冻结操作;然后,定义新的全连接层结构并重新赋值给model.classifier。在完成了新的全连接层定义后,全连接层中的parma.requires_grad参数会被默认重置为True,所以不需要再次遍历参数来进行解冻操作。损失函数的loss值依然使用交叉熵进行计算,但是在优化函数中负责优化的参数变成了全连接层中的所有参数,即对 model.classifier.parameters这部分参数进行优化。在调整完模型的结构之后,我们通过打印输出对比其与模型没有进行调整前有什么不同,结果如下:
