
selenium模块
一、selenium模块介绍
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题。selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。但是它的使用必须配合浏览器驱动而且浏览器版本也要一样才可以。正式使用之前需要做一些准备工作。浏览器和浏览器驱动的话推荐使用谷歌浏览器(因为这个浏览器支持selenium的最好)
怎么查看谷歌浏览器的版本
浏览器右上角》点三个点点》往下找帮助并点击》之后再点关于Google Chrome就可以查看版本
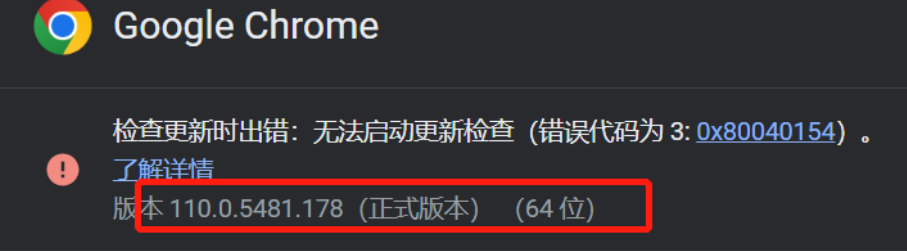
确定自己浏览器版本之后下载对应的驱动
点击这里下载
谷歌浏览器驱动
准备下载驱动的时候发现驱动和浏览器版本无法完全一致,我这里有两个不用纠结二选一即可。
再根据自己的电脑的操作系统选择即可
所有的准备工作已完成接下来咱学习如何使用selenium模块吧
二、selenium基本使用
- 下载selenium模块
pip install selenium
-
下载好了的驱动拖到项目路径下
-
写代码控制谷歌浏览器
from selenium import webdriver
# 第一步:打开谷歌浏览器
my_browser = webdriver.Chrome(executable_path='chromedriver.exe')
# 第二步:在地址栏中输入网址
page_source = my_browser.get('https://www.cnblogs.com/almira998/p/17226553.html')
# 第三步:完成任务就关闭浏览器
my_browser.close()
三、无界面浏览器
无界面浏览器指的就是隐藏浏览器图形化界面但是数据照样能拿到,有这个模块我就不需要费心费力的用requests模块了。那么怎么操作呢?请继续看下面代码框
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--hide-scrollbars') # 隐藏滚动条
chrome_options.add_argument('blink-settings=imagesEnabled=false') # 不加载图图片
chrome_options.add_argument('--headless') # 不提供可视化界面
my_browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
my_browser.get('https://www.cnblogs.com/')
print(my_browser.page_source)
my_browser.close()
四、selenium用法
1. 查找标签
可以按id,标签名,name属性名,类名,a标签的文字,a标签的文字模糊匹配,css选择器,如果有id那就优选选择id,因为id具有唯一性,查找标签最准确
# 两个方法
bro.find_element 找一个
bro.find_elements 找所有
input_1=bro.find_element(by=By.ID,value='wd')
input_1 = bro.find_element(by=By.NAME, value='wd')
input_1=bro.find_element(by=By.TAG_NAME,value='input')
input_1=bro.find_element(by=By.CLASS_NAME,value='s_ipt')
input_1=bro.find_element(by=By.LINK_TEXT,value='登录')
input_1=bro.find_element(by=By.PARTIAL_LINK_TEXT,value='录')
input_1 = bro.find_element(by=By.CSS_SELECTOR, value='#su')
2. 获取标签
通过tag.的方式获取标签的属性、id、文本、位置、大小、标签名
print(tag.get_attribute('src')) # 用的最多
print(tag.id)
print(tag.text)
print(tag.location)
print(tag.size)
print(tag.tag_name)
3. 元素操作
可以操作点击、输入内容、清空内容、浏览器对象最大化、截全屏幕、还可以控制代码运行(代码执行很快,有的标签没来的及加载,直接查找就会报错,设置等待)
# 点击
tag.click()
# 输入内容
tag.send_keys()
# 清空内容
tag.clear()
# 浏览器对象 最大化
bro.maximize_window()
#浏览器对象 截全屏
bro.save_screenshot('main.png')
# 设置等待:所有标签,只要去找,找不到就遵循 等10s的规则
bro.implicitly_wait(10)
4. 执行JS代码
可以干的事情:获取当前访问的地址、打开新的标签、滑动屏幕、获取cookie,获取定义的全局变量(如果获取到cookie那么爬虫一个大难点就解决了,具体如何获取后面继续学)
bro.execute_script('alert("美女")') # 引号内部的相当于 用script标签包裹了
5. 切换选项卡
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) #获取所有的选项卡
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(2)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close()
6. 控制前进后退
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/')
browser.back()
time.sleep(2)
browser.forward()
browser.close()
7. 异常处理
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
try:
except Exception as e:
print(e)
finally:
browser.close()
五、xpath的使用
关于xpath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言,具体会一下几个就够了,实在不行咱有终极大法:那就是右键检查>copy>copy xpath来复制用即可
/ 从当前路径下开始找
/div 从当前路径下开始找div
// 递归查找,子子孙孙
//div 递归查找div
@ 取属性
. 当成
.. 上一层
六、selenium动作链
Selenium的动作链是一种在网页上执行多个动作的技术,它可以模拟人类在网页上的交互行为,例如鼠标移动、点击、拖拽等操作。动作链中的每个动作都可以设置等待时间、偏移量、速度等参数,以便更加精确地模拟用户的操作。使用动作链可以实现复杂的交互操作,提高自动化测试的效率和准确性。
actions=ActionChains(bro) #拿到动作链对象
actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
actions.perform()
ActionChains(bro).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
track=0
while track < distance:
ActionChains(bro).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2
ActionChains:这是Selenium原生的动作链类,它可以在浏览器中执行鼠标和键盘的交互操作,例如点击、拖拽、悬停等。ActionChains类可以通过链式调用来组合多个操作,以实现复杂的操作流程。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://www.baidu.com')
# 找到搜索框元素
search_box = driver.find_element_by_css_selector('#kw')
# 创建ActionChains对象
actions = ActionChains(driver)
# 在搜索框中输入关键词
actions.move_to_element(search_box).send_keys('Selenium').perform()
# 找到搜索按钮元素
search_button = driver.find_element_by_css_selector('#su')
# 悬停在搜索按钮上
actions.move_to_element(search_button).perform()
# 点击搜索按钮
actions.click(search_button).perform()
# 关闭浏览器
driver.quit()
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
try:
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult') # 切换到id为iframeResult的frame
target = browser.find_element(By.ID, 'droppable') # 目标
source = browser.find_element(By.ID, 'draggable') # 源
# 方案1
# actions = ActionChains(browser) # 拿到动作链对象
# actions.drag_and_drop(source, target) # 把动作放到动作链中,准备串行执行
# actions.perform()
# 方案2
# ActionChains(browser).click_and_hold(source).perform()
# distance = target.location['x'] - source.location['x']
# track = 0
# while track < distance:
# ActionChains(browser).move_by_offset(xoffset=2, yoffset=0).perform()
# track += 2
time.sleep(2)
finally:
browser.close()
七、selenium模块相关的案例练习
1. 模拟登录百度
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 1.打开浏览器
browser = webdriver.Chrome(executable_path='chromedriver.exe')
# 2.打开百度官网
browser.get('https://www.baidu.com')
browser.implicitly_wait(10)
# 3.找到登录按钮并点击
login_btn = browser.find_element(by=By.LINK_TEXT, value='登录')
login_btn.click()
time.sleep(2)
# 4.选择账号登录方式并点击
login_by_pwd = browser.find_element(by=By.CSS_SELECTOR, value='#TANGRAM__PSP_11__changePwdCodeItem')
login_by_pwd.click()
time.sleep(2)
# 5.输入用户名和密码
username = browser.find_element(by=By.ID, value='TANGRAM__PSP_11__userName')
password = browser.find_element(by=By.ID, value='TANGRAM__PSP_11__password')
username.send_keys('18963884980')
password.send_keys('almira10054X')
time.sleep(2)
# 6.最后点击登录
commit_btn = browser.find_element(by=By.ID, value='TANGRAM__PSP_11__submit')
commit_btn.click()
time.sleep(10)
# 关闭浏览器
browser.close()
2. 自动登录12306
3. 爬取商品信息