
ByteHouse MaterializedMySQL 增强优化
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
前言
社区版 ClickHouse 推出了MaterializedMySQL数据库引擎,用于将 MySQL 中的表映射到 ClickHouse 中。ClickHouse 服务作为 MySQL 副本,读取 Binlog 并执行 DDL 和 DML 请求,实现了基于 MySQL Binlog 机制的业务数据库实时同步功能。
这样不依赖其他数据同步工具,就能将 MySQL 整库数据实时同步到 ClickHouse,从而能基于 ClickHouse 构建实时数据仓库。
ByteHouse 是基于 ClickHouse 增强自研的云原生数据仓库,在社区版 ClickHouse 的 MaterializedMySQL 之上进行了功能增强,让数据同步更稳定,支持便捷地处理同步异常问题。
社区版 MaterializedMySQL 简介
ClickHouse 社区版通过 DDL 语句在 ClickHouse 上创建一个 database,并将 MySQL 中的指定的一个 database 的全量数据迁移至 ClickHouse,并实时读取 MySQL 的 binlog 日志,将 MySQL 中的增量数据实时同步至 ClickHouse 中。
详细介绍:[experimental] MaterializedMySQL | ClickHouse Docs
同步示例
同步一个 MySQL 库至 ClickHouse 的示例创建语句如下:
功能优势
MaterializedMySQL 数据同步方案的优势有:
-
简单易用:使用一个 DDL 语句就能创建整库同步任务,能将数百数千张表一键同步至 ClickHouse,操作简单。
-
架构简单:使用 ClickHouse 本身的计算资源进行数据增量同步,无需搭建其他的数据同步工具,数据架构简单。
-
时效性好:支持实时同步源端数据,ClickHouse 端几乎是毫秒和秒级延迟,时效体验非常好。
ByteHouse 功能增强
社区版 MaterializedMySQL 很大程度了解决了 MySQL 库到 ClickHouse 之间的数据实时同步问题,但也存在不少问题导致其很难应用到生产应用中,主要问题如下:
-
配置选项少
社区版 MaterializedMySQL 不支持同步到分布式表,不支持跳过不兼容 DDL 等功能,缺乏这些功能很难将 MaterializedMySQL 用于实际应用中。
-
运维困难
社区版 MaterializedMySQL 不支持同步异常重新同步命令,没有同步状态和日志信息,同步任务失败后很难短时间定位问题和恢复同步。
ByteHouse 的 MaterializedMySQL 功能针对使用过程中的问题和困难,做了多处增强,提高了易用性,降低了运维成本。
数据去重
通过 MaterializedMySQL 同步到 ByteHouse 的表默认采用 HaUniqueMergeTree 表引擎,该表引擎支持配置 UNIQUE KEY 唯一键,提供 upsert 更新写语义,源端数据的更新操作在目标端可以实时去重更新。不需要依赖_version、_sign 虚拟列来标记删除更新,简化了业务逻辑,提高了易用性。
同步范围
通过 SETTINGS 参数中配置 include_tables 和 exclude_tables 列表,指定该数据库下需要同步的表清单或者不需要同步的表清单,否则同步该库所有的表。
在实际应用中,一个数据库通常有数百乃至数千张表,其中有些表无需同步、或者数据可能存在异常,可以将这些表加入 exclude_tables 清单,不影响其他表的数据同步。
异常处理
数据同步链路无法避免发生异常情况导致同步中断,ByteHouse 提高了多个功能来简化异常问题处理。
跳过不支持的语句
MySQL 支持的 DDL 语句非常丰富,有很多语法与 clickhouse 不兼容,在 ClickHouse 端执行会报错中断同步任务。
可以通过设置 skip_ddl_patterns 参数,用 1 个或多个正则表达式将匹配的 DDL 语句过滤掉,从而避免了报错和中断同步任务。
系统日志表
ByteHouse 提供两个系统表:system.materialize_mysql_status,system.materialize_mysql_log,分别记录了每个同步任务的状态,参数设置和运行日志。便于实时查看同步状态和排查异常问题。
出错后运维
当同步任务出现了同步异常后,通过查看运行日志系统表定为问题。
针对性处理了异常问题后,通过 resync 命令重启同步任务。
分布式模式
社区版 MaterializedMySQL 的每个同步任务会将源端的一个库同步至 ClickHouse 的某个节点,不支持按分片逻辑将数据分布到所有节点,无法利用 ClickHouse 集群的分布式计算存储能力;如果在集群中每个节点都建一个同步库,则源端一份数据会被同步一份全量至每个 ClickHouse 节点,既浪费了存储空间,降低了查询性能,又会对源端产生巨大的压力。
ByteHouse 支持构建分布式模式的 MaterializedMySQL 库,将每个表都对应同步至 ByteHouse 的一个分布式表,数据不重复存储,能充分利用分布式集群的计算能力,又降低了对源端的同步压力。
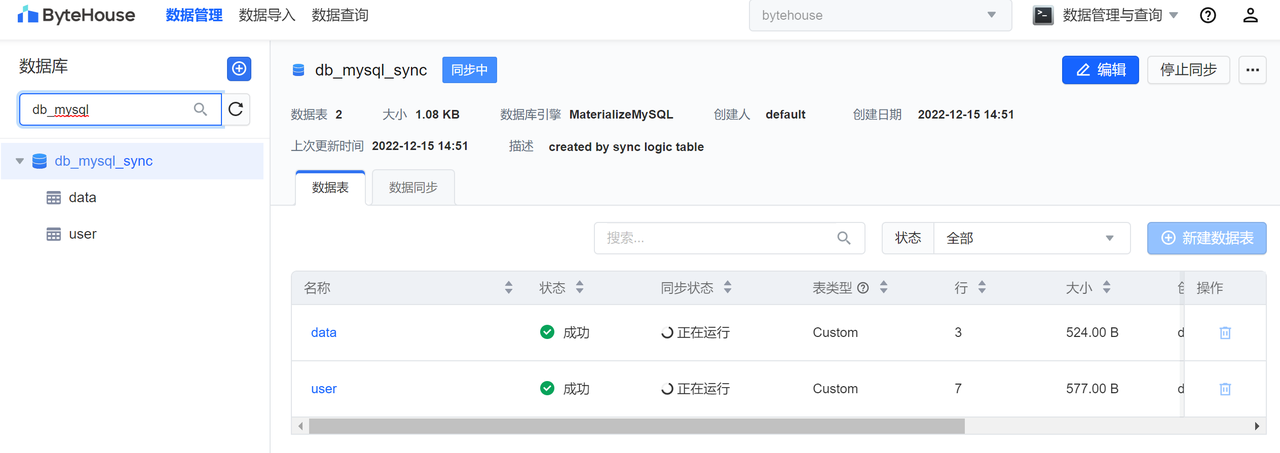
可视化运维
ByteHouse 同时提供了可视化运维模块,能实时查看同步状态,暴露同步异常,支持在线修复同步异常问题和重启同步任务。
最佳实践
下午将演示将 MySQL 库中的若干张表同步至 ByteHouse 的全过程。
源端配置
在 MySQL 数据库端需要配置的参数如下。
开启 Binlog

设置默认的认证插件

开启 GTID 模式

-
用户权限 MaterializeMySQL 表引擎用户必须具备 MySQL 库的 RELOAD、REPLICATION SLAVE、REPLICATION CLIENT 以及 SELECT PRIVILEGE 权限 支持的 MySQL 版本 5.65.78.0
源端数据准备
在 MySQL 数据库里面创建一个 database,创建两张表,并插入若干数据。
创建 MaterializeMySQL
在 ByteHouse 的控制台数据查询窗口,创建 MaterializeMySQL 库。
参数解释:
-
shard_mode:true 表示是同步至分布式表。
-
allows_query_when_mysql_lost:1 表示同步中断的时候也允许查询数据。
-
include_tables:同步源端 db 库中 user 和 data 两张表,其他表跳过不同步。
-
OVERRIDE :ByteHouse 中的 data 表按照 date_time 字段分区。
查看同步状态
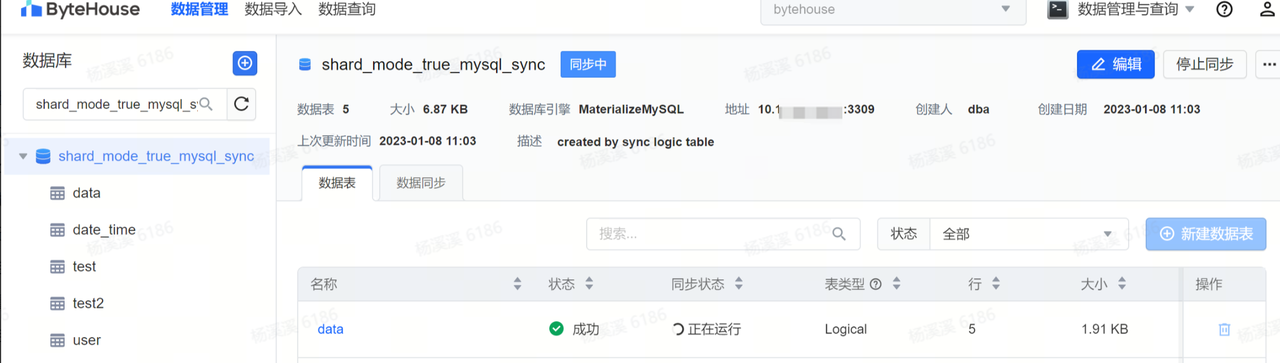
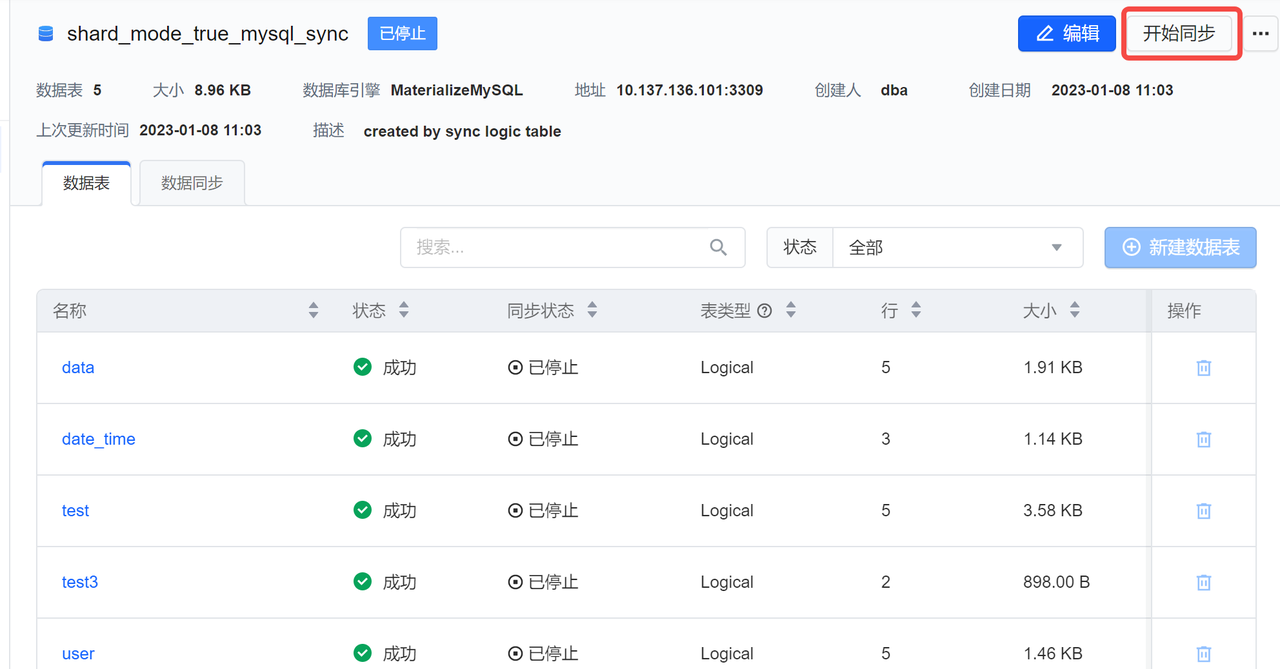
切换到 ByteHouse 数据管理模块,搜索 shard_mode_true_mysql_sync 库,并查看库同步状态
同步任务管理
库-停止同步/开始同步
-
创建库后默认是同步状态
-
可以手动停止同步
-
停止中的库可以手动开始同步
库-重置同步
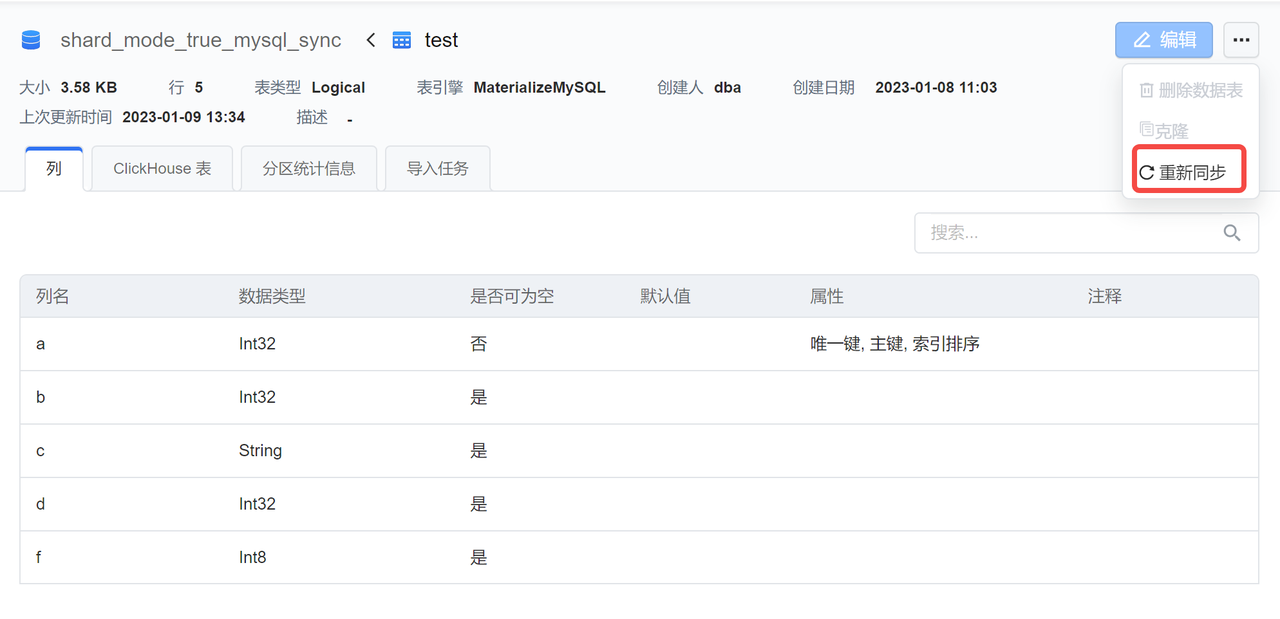
选择一个同步库,点击“重置同步”可以从头开始重新同步整库
表-重置同步
选择一个同步中的表 A,点击“重置同步”按钮,系统将执行以下行为:
-
关闭同步任务
-
从源端全量拉取该表的数据至临时表(A_CHTMP,表名后缀会加上_CHTMP)
-
删除目标端原有表 A(如果存在)
-
将临时表 A_CHTMP RENAME 为 A
-
开始增量同步
删除库
删除 ByteHouse 中的库以及同步关系。
异常处理
系统运维表
在 ByteHouse 管理控制台,通过下列语句查看任务同步状态和错误信息。
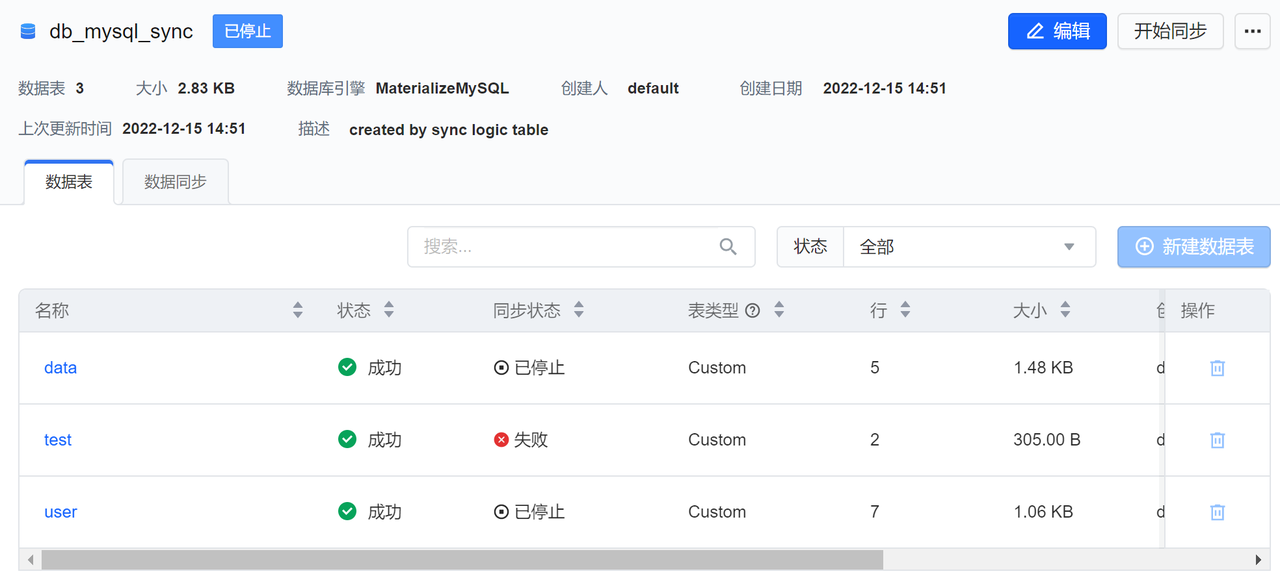
单表异常恢复
在源端执行下列 Alter table 语句以后,库同步会失败
恢复办法:
在 ByteHouse 界面上进入表详情,点击重新同步按钮。
进入库详情页面,点击开始同步按钮,即可恢复同步。
在 ByteHouse 中执行下列语句,也可以恢复数据同步
其他操作
设置跳过 DDL
修改 include 和 exclude
通过下列语句修改 include 和 exclude 参数,来修改同步表范围。
异常报警
ByteHouse 提供监控报警功能,在库同步异常停止或单表同步失败的时候,可以向管理员发送报警信息。
点击跳转 ByteHouse云原生数据仓库 了解更多