
三分钟速览GPT系列原理
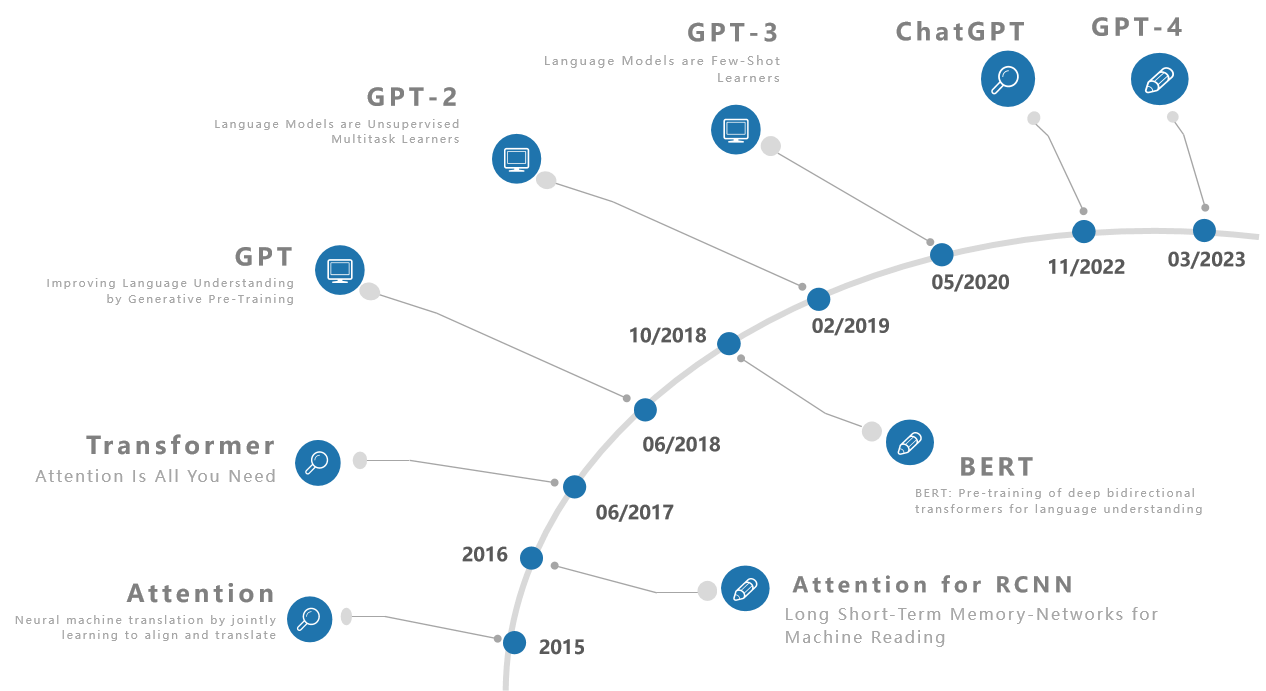
GPT
Paper名为Improving Language Understanding by Generative Pre-Training,通过生成式预训练模型来提高语言理解。
- GPT,将Transformer的Decoder拿出来,在大量没有标注的文本数据上进行训练,得到一个大的预训练的语言模型。然后再用它在不同子任务上进行微调,最后得到每一个任务所要的分类器。
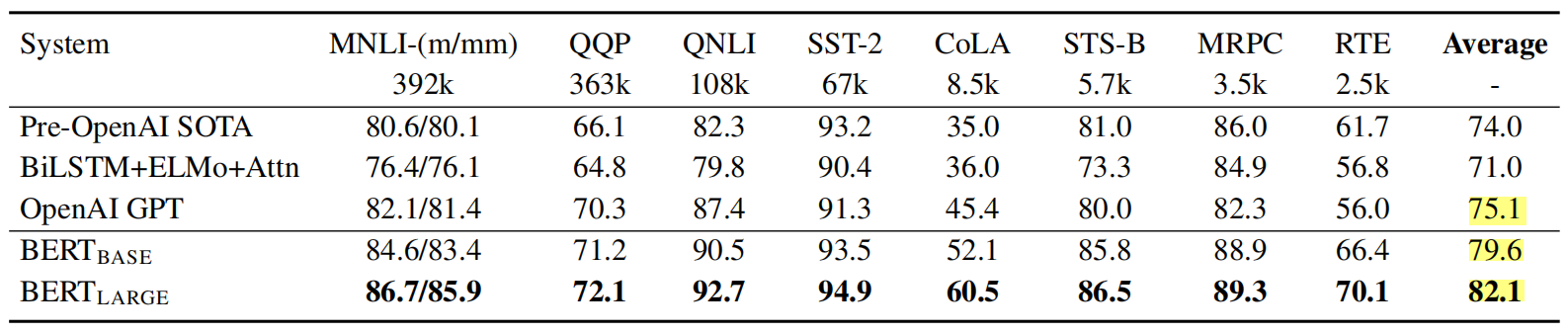
- BERT虽然大家更为熟知,但其实发布晚于GPT,是将Transformer的Encoder拿出来,收集了一个更大的数据集做训练,取得了比GPT好很多的效果。BERT给了BERT-Base和BERT-Large两个模型,BERT-Base的模型大小与GPT相当,效果更好,BERT-large模型更大数据效果也更好,下图是BERT论文[1]中给出的一组对比数据。
我们知道,BERT中使用(1)扣取某个单词,学习完形填空(2)判断是否为下一句来学习句子的相关性,两个任务来使用海量数据进行训练。
在GPT中,训练分为无监督的预训练和有监督的微调,无监督的预训练使用标准语言模型,给定前i-1个单词,预测第i个单词;有监督的微调使用标准交叉熵损失函数。
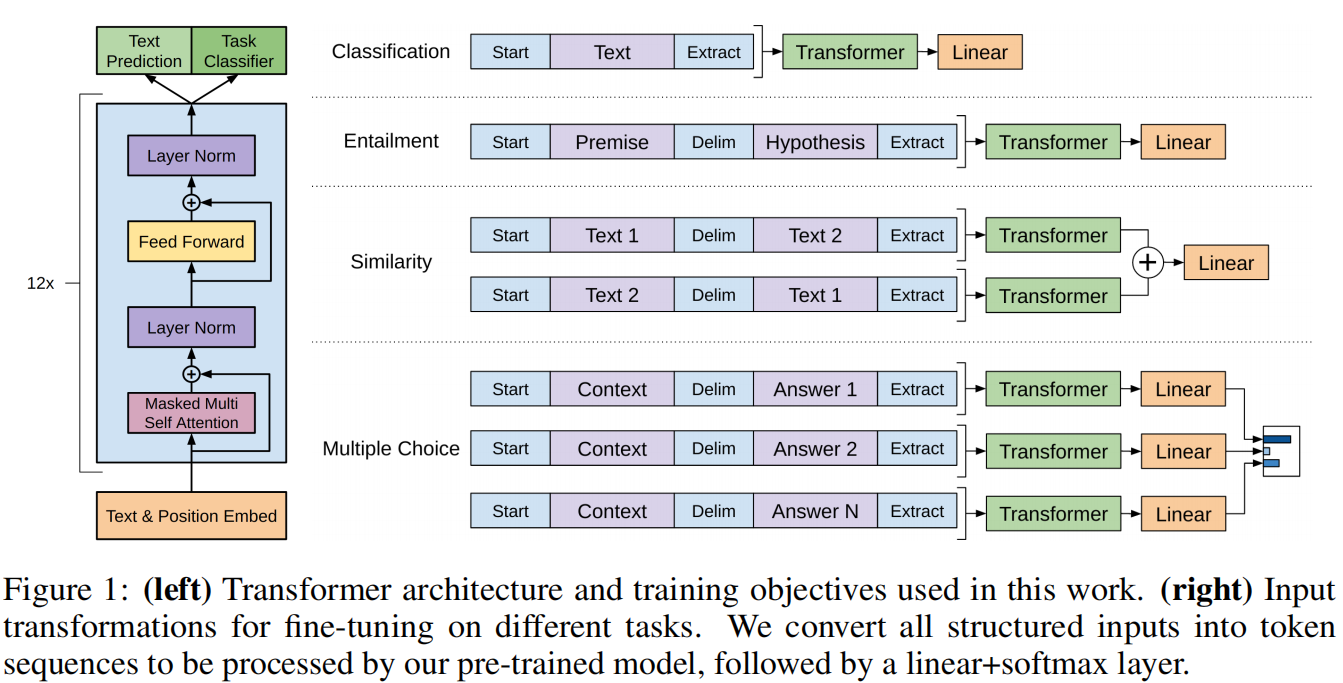
针对不同的任务,只需要按照下列方式将其输入格式进行转换,转换为一个或多个token序列,然后送入Transformer模型,后接一个任务相关的线性层即可。
GPT-2
之前,大家倾向于为每个任务收集单独的数据集(single task training on single domain datasets),OpenAI在这篇文章中使用了zero-shot的设定来解决下游任务。
We demonstrate language models can perform down-stream tasks in a zero-shot setting -- without any parameters or architecture modification.
GPT的时候,针对不同的任务构造不同的输入序列进行微调,这里直接使用自然语言的方式训练网络并可以使用到不同的任务上去。
例如,对于一个机器翻译任务的训练样本【translation training example】为:
translate to french, english text, french text
对于阅读理解训练样本【reading comprehension training example】:
answer the question, document, question, answer
这种方法并不是作者首提的,但是作者将其用到了GPT的模型上,并取得了一个相对的效果【如果没有GPT-3的惊艳效果,估计它也就是一个不怎么被人所知的工作了】。
从GPT-2开始不再在子任务上做微调,直接使用预训练模型进行预测,这个是很牛掰的。
GPT-3
GPT-3基于GPT-2继续做,GPT-2有1.5Billion【15亿】的参数量,GPT-3做到了175Billion【1750亿】的参数量。
Specififically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specifified purely via text interaction with the model.
摘要中这里详述了,GPT-3参数量翻了10倍,同时推理的时候使用了few-shot。对于所有的子任务,都不进行梯度更新,而是纯使用few-shot的形式改变输入。
Finally, we find that GPT-3 can generate samples of news articles which human evaluators have diffificulty distinguishing from articles written by humans.
GPT-3取得了非常经验的效果,已经能够写出人类无法分辨真假的假新闻。
这里详述一下zero-shot、one-shot、few-shot:
- zero-shot:推理时,输入包含:任务描述 + 英文单词 + prompt[=>]
- one-shot:推理时,输入包含:任务描述 + 一个例子 + 英文单词 + prompt[=>]
- few-shot:推理时,输入包含:任务描述 + 多个例子 + 英文单词 + prompt[=>]

Reference
[1] Devlin, Chang, Lee, and Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In ACL, 2019.
[2] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under standing with unsupervised learning. Technical report, OpenAI. [GPT]
[3] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019. [GPT-2]
[4] Brown, Tom B. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020): n. pag. [GPT-3]
[5] 沐神 GPT,GPT-2,GPT-3 论文精读【论文精读】
