
一文快速入门任务调度框架-Quartz
前言
还不会 Quartz?如果你还没有接触过Quartz,那么你可能错过了一个很棒的任务调度框架!Quartz 提供了一种灵活、可靠的方式来管理和执行定时任务,让咱们的定时任务更加优雅。本篇文章将为你介绍 Quartz 框架的核心概念、API 和实战技巧,让你轻松上手。也不用担心,作为过来人,我会把难懂的概念和术语解释清楚,让你看完本篇文章后,就知道该如何操作 Quartz。当然,本篇文章难免有不足之处,在此欢迎大家指出。那废话少说,下面我们开始吧!
什么是 Quartz?
Quartz 是一个功能丰富的开源任务调度框架(job scheduling library)。从最小的独立的 Java 应用程序到最大的电子商务系统,它几乎都可以集成。Quartz 可用于创建简单或复杂的调度,以执行数十、数百个甚至数万个任务;这些任务被定义为标准 Java 组件,这些组件可以执行你想让他做的任何事情。Quartz 调度程序包括许多企业级特性,例如支持 JTA 事务(Java Transaction API,简写 JTA)和集群。
注意:Job == 任务
JTA,即 Java Transaction API,JTA 允许应用程序执行分布式事务处理——在两个或多个网络计算机资源上访问并且更新数据。
为什么学习 Quartz?
定时任务直接用 Spring 提供的 @Schedule 不行吗?为什么还要学习 Quartz?有什么好处?
是的,一开始我也是这么想的,但是某些场景,单靠 @Schedule 你就实现不了了。
比如我们需要对定时任务进行增删改查,是吧,@Schedule 就实现不了,你不可能每次新增一个定时任务都去手动改代码来添加吧。而 Quartz 就能够实现对任务的增删改查。当然,这只是 Quartz 的好处之一。
Quartz 的特性
运行时环境
- Quartz 可以嵌入另一个独立的应用程序中运行
- Quartz 可以在应用程序服务器(比如 Tomcat)中实例化,并参与 XA 事务(XA 是一个分布式事务协议)
- Quartz 可以作为一个独立程序运行(在其自己的Java虚拟机中),我们通过 RMI(Remote Method Invocation,远程方法调用)使用它
- Quartz 可以实例化为一个独立程序集群(具有负载平衡和故障转移功能),用于执行任务
任务的调度(Job Scheduling)
当一个触发器(Trigger)触发时,Job 就会被调度执行,触发器就是用来定义何时触发的(也可以说是一个执行计划),可以有以下任意的组合:
- 在一天中的某个时间(毫秒)
- 在一周中的某些日子
- 在一个月的某些日子
- 在一年中的某些日子
- 重复特定次数
- 重复直到特定的时间/日期
- 无限期重复
- 以延迟间隔重复
Job 由我们自己去命名,也可以组织到命名组(named groups)中。Trigger 也可以被命名并分组,以便在调度器(Scheduler)中更容易地组织它们。
Job 只需在 Scheduler 中添加一次,就可以有多个 Trigger 进行注册。
任务的执行(Job Execution)
- 实现了 Job 接口的 Java 类就是 Job,习惯称为任务类(Job class)。
- 当 Trigger 触发时,Scheduler 就会通知 0 个或多个实现了 JobListener 和 TriggerListener 接口的 Java 对象。当然,这些 Java 对象在 Job 执行后也会被通知到。
- 当 Job 执行完毕时,会返回一个码——
JobCompletionCode,这个 JobCompletionCode 能够表示 Job 执行成功还是失败,我们就能通过这个 Code 来判断后续该做什么操作,比如重新执行这个 Job。
任务的持久化(Job Persistence)
- Quartz 的设计包括了一个 JobStore 接口,该接口可以为存储 Job 提供各种机制。
- 通过 JDBCJobStore,可以将 Job 和 Trigger 持久化到关系型数据库中。
- 通过 RAMJobStore,可以将 Job 和 Trigger 存储到内存中(优点就是无须数据库,缺点就是这不是持久化的)。
事务
- Quartz 可以通过使用 JobStoreCMT(JDBCJobStore的一个子类)参与 JTA 事务。
- Quartz 可以围绕任务的执行来管理 JTA 事务(开始并且提交它们),以便任务执行的工作自动发生在 JTA 事务中。
集群
- 故障转移
- 负载均衡
- Quartz 的内置集群功能依赖于 JDBCJobStore 实现的数据库持久性。
- Quartz 的 Terracotta 扩展提供了集群功能,而无需备份数据库。
监听器和插件
- 应用程序可以通过实现一个或多个监听器接口来捕获调度事件以监听或控制 Job / Trigger 的行为。
- 插件机制,我们可向 Quartz 添加功能,例如保存 Job 执行的历史记录,或从文件加载 Job 和 Trigger 的定义。
- Quartz 提供了许多插件和监听器。
初体验
引入 Quartz 依赖项
创建一个 Spring Boot 项目,然后引入如下依赖,就可以体验 Quartz 了。
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
示例
现在知道 Quartz 有这么几个概念,分别是 Job、Trigger、Scheduler。在它的设计实现上,分别是 Job 接口、JobDetail 接口、Trigger 接口、Scheduler 接口。除了 Job 接口的实现类需要我们自己去实现,剩下的都由 Quartz 实现了。
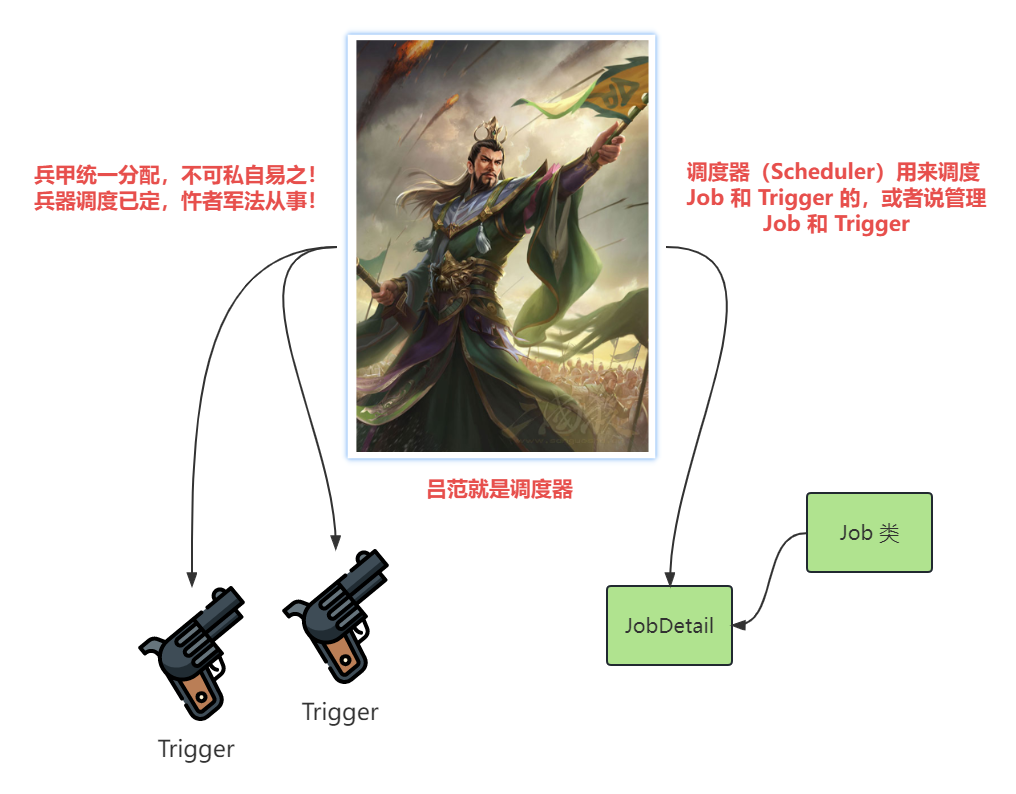
Quartz中的调度器(Scheduler)的主要作用就是调度 Job 和 Trigger 的执行。在Quartz中,Job代表需要执行的任务,Trigger代表触发Job执行的条件和规则。调度器会根据Trigger的配置来确定Job的执行时机。
下面的代码包含了一个 Scheduler 的实例对象,接着是调用 start 方法,最后调用 shutdown 方法。
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class QuartzTest {
public static void main(String[] args) {
try {
// 从 Factory 中获取 Scheduler 实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 开始并关闭
scheduler.start();
scheduler.shutdown();
} catch (SchedulerException se) {
se.printStackTrace();
}
}
}
一旦我们使用 StdSchedulerFactory.getDefaultScheduler() 获取 Scheduler 对象后,那么程序就会一直运行下去,不会终止,直到我们调用了 scheduler.shutdown() 方法才会停止运行。这是因为获取 Scheduler 对象后,就有许多线程在运行着,所以程序会一直运行下去。
与此同时,控制台会输出相应的日志:
10:14:02.442 [main] INFO org.quartz.impl.StdSchedulerFactory - Using default implementation for ThreadExecutor
10:14:02.445 [main] INFO org.quartz.simpl.SimpleThreadPool - Job execution threads will use class loader of thread: main
10:14:02.452 [main] INFO org.quartz.core.SchedulerSignalerImpl - Initialized Scheduler Signaller of type: class org.quartz.core.SchedulerSignalerImpl
10:14:02.452 [main] INFO org.quartz.core.QuartzScheduler - Quartz Scheduler v.2.3.2 created.
10:14:02.453 [main] INFO org.quartz.simpl.RAMJobStore - RAMJobStore initialized.
10:14:02.453 [main] INFO org.quartz.core.QuartzScheduler - Scheduler meta-data: Quartz Scheduler (v2.3.2) 'DefaultQuartzScheduler' with instanceId 'NON_CLUSTERED'
Scheduler class: 'org.quartz.core.QuartzScheduler' - running locally.
NOT STARTED.
Currently in standby mode.
Number of jobs executed: 0
Using thread pool 'org.quartz.simpl.SimpleThreadPool' - with 10 threads.
Using job-store 'org.quartz.simpl.RAMJobStore' - which does not support persistence. and is not clustered.
10:14:02.453 [main] INFO org.quartz.impl.StdSchedulerFactory - Quartz scheduler 'DefaultQuartzScheduler' initialized from default resource file in Quartz package: 'quartz.properties'
10:14:02.453 [main] INFO org.quartz.impl.StdSchedulerFactory - Quartz scheduler version: 2.3.2
从日志中也能看出 Quartz 的一些信息,比如版本、使用的线程池、使用的任务存储机制(这里默认是 RAMJobStore)等等信息。
我们想要执行任务的话,就需要把任务的代码放在 scheduler.start() 和 scheduler.shutdown() 之间。
QuartzTest:
import cn.god23bin.demo.quartz.job.HelloJob;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
// 这里导入了 static,下面才能直接 newJob, newTrigger
import static org.quartz.JobBuilder.newJob;
import static org.quartz.SimpleScheduleBuilder.simpleSchedule;
import static org.quartz.TriggerBuilder.newTrigger;
public class QuartzTest {
public static void main(String[] args) {
try {
// 从 Factory 中获取 Scheduler 实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 开始并关闭
scheduler.start();
// 定义一个 Job(用JobDetail描述的Job),并将这个 Job 绑定到我们写的 HelloJob 这个任务类上
JobDetail job = newJob(HelloJob.class)
.withIdentity("job1", "group1") // 名字为 job1,组为 group1
.build();
// 现在触发任务,让任务执行,然后每5秒重复执行一次
Trigger trigger = newTrigger()
.withIdentity("trigger1", "group1")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(5)
.repeatForever())
.build();
// 告知 Quartz 使用我们的 Trigger 去调度这个 Job
scheduler.scheduleJob(job, trigger);
// 为了在 shutdown 之前让 Job 有足够的时间被调度执行,所以这里当前线程睡眠30秒
Thread.sleep(30000);
scheduler.shutdown();
} catch (SchedulerException | InterruptedException se) {
se.printStackTrace();
}
}
}
HelloJob:实现 Job 接口,重写 execute 方法,实现我们自己的任务逻辑。
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import java.text.SimpleDateFormat;
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("Hello Job!!! 时间:" + sdf.format(jobExecutionContext.getFireTime()));
}
}
运行程序,输出如下信息:
10:25:40.069 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.simpl.PropertySettingJobFactory - Producing instance of Job 'group1.job1', class=cn.god23bin.demo.quartz.job.HelloJob
10:25:40.071 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 1 triggers
10:25:40.071 [DefaultQuartzScheduler_Worker-1] DEBUG org.quartz.core.JobRunShell - Calling execute on job group1.job1
Hello Job!!! 时间:2023-03-28 10:25:40
10:25:45.066 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.simpl.PropertySettingJobFactory - Producing instance of Job 'group1.job1', class=cn.god23bin.demo.quartz.job.HelloJob
10:25:45.066 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 1 triggers
10:25:45.066 [DefaultQuartzScheduler_Worker-2] DEBUG org.quartz.core.JobRunShell - Calling execute on job group1.job1
Hello Job!!! 时间:2023-03-28 10:25:45
# 省略后面输出的信息,都是一样的
API 有哪些?
Quartz API 的关键接口如下:
Scheduler:最主要的 API,可以使我们与调度器进行交互,简单说就是让调度器做事。Job:一个 Job 组件,你自定义的一个要执行的任务类就可以实现这个接口,实现这个接口的类的对象就可以被调度器进行调度执行。JobDetail:Job的详情,或者说是定义了一个 Job。JobBuilder: 用来构建JobDetail实例的,然后这些实例又定义了 Job 实例。Trigger: 触发器,定义Job的执行计划的组件。TriggerBuilder: 用来构建Trigger实例。
Quartz 涉及到的设计模式:
-
Factory Pattern:
// 从 Factory 中获取 Scheduler 实例 Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); -
Builder Pattern:
JobDetail job = newJob(HelloJob.class) .withIdentity("job1", "group1") // 名字为 job1,组为 group1 .build();这里的
newJob方法是 JobBuilder 类中的一个静态方法,就是通过这个来构建 JobDetail 的。/** * Create a JobBuilder with which to define a <code>JobDetail</code>, * and set the class name of the <code>Job</code> to be executed. * * @return a new JobBuilder */ public static JobBuilder newJob(Class <? extends Job> jobClass) { JobBuilder b = new JobBuilder(); b.ofType(jobClass); return b; } /** * Produce the <code>JobDetail</code> instance defined by this * <code>JobBuilder</code>. * * @return the defined JobDetail. */ public JobDetail build() { JobDetailImpl job = new JobDetailImpl(); job.setJobClass(jobClass); job.setDescription(description); if(key == null) key = new JobKey(Key.createUniqueName(null), null); job.setKey(key); job.setDurability(durability); job.setRequestsRecovery(shouldRecover); if(!jobDataMap.isEmpty()) job.setJobDataMap(jobDataMap); return job; }同样,构建 Trigger 对象是使用 TriggerBuilder 类以及 SimpleScheduleBuilder 类构建的,Schedule 主要是一个时间安排表,就是定义何时执行任务的时间表。
-
当然,除了上面说的两种设计模式外,还有其他的设计模式,这里就不细说了。比如单例模式,观察者模式。
简单理解 Job、Trigger、Scheduler
每天中午12点唱、跳、Rap、篮球
- Job:唱、跳、Rap、篮球
- Trigger:每天中午12点为一个触发点
- Scheduler:自己,我自己调度 Trigger 和 Job,让自己每天中午12点唱、跳、Rap、篮球
关于 Job
Job 接口源码:
package org.quartz;
public interface Job {
void execute(JobExecutionContext context) throws JobExecutionException;
}
当该任务的 Trigger 触发时,那么 Job 接口的 execute 方法就会被 Scheduler 的某一个工作线程调用。JobExecutionContext 对象就会作为参数传入这个方法,该对象就提供 Job 实例的一些关于任务运行时的信息。
我们知道,写完一个 Job 类后,需要将定义一个 JobDetail 绑定到我们的 Job 类:
// 定义一个 Job(用JobDetail描述的Job),并将这个 Job 绑定到我们写的 HelloJob 这个任务类上
JobDetail job = newJob(HelloJob.class)
.withIdentity("job1", "group1") // 名字为 job1,组为 group1
.build();
在这个过程中,有许多属性是可以设置的,比如 JobDataMap,这个对象能够存储一些任务的状态信息数据,这个后面说。
Trigger 对象用于触发任务的执行。当我们想要调度某个任务时,可以实例化 Trigger 并设置一些我们想要的属性。Trigger 也可以有一个与之相关的 JobDataMap,这对于特定的触发器触发时,传递一些参数给任务是很有用。Quartz 有几种不同的 Trigger 类型,但最常用的类型是 SimpleTrigger 和 CronTrigger。
关于 SimpleTrigger 和 CronTrigger
如果我们想要在某个时间点执行一次某个任务,或者想要在给定时间启动一个任务,并让它重复 N 次,执行之间的延迟为 T,那么就可以使用 SimpleTrigger。
如果我们想根据类似日历的时间表来执行某个任务,例如每天晚上凌晨 4 点这种,那么就可以使用 CronTrigger。
为什么会设计出 Job 和 Trigger 这两个概念?
在官网上是这样说的:
Why Jobs AND Triggers? Many job schedulers do not have separate notions of jobs and triggers. Some define a ‘job’ as simply an execution time (or schedule) along with some small job identifier. Others are much like the union of Quartz’s job and trigger objects. While developing Quartz, we decided that it made sense to create a separation between the schedule and the work to be performed on that schedule. This has (in our opinion) many benefits.
For example, Jobs can be created and stored in the job scheduler independent of a trigger, and many triggers can be associated with the same job. Another benefit of this loose-coupling is the ability to configure jobs that remain in the scheduler after their associated triggers have expired, so that that it can be rescheduled later, without having to re-define it. It also allows you to modify or replace a trigger without having to re-define its associated job.
简而言之,这有许多好处:
- 任务可以独立于触发器,它可以在调度器中创建和存储,并且许多触发器可以与同一个任务关联。
- 这种松耦合能够配置任务,在其关联的触发器已过期后仍然保留在调度器中,以便之后重新安排,而无需重新定义它。
- 这也允许我们修改或替换触发器的时候无需重新定义其关联的任务。
Job 和 Trigger 的身份标识(Identities)
在上面的代码中我们也看到了,Job 和 Trigger 都有一个 withIdentity 方法。
JobBuilder 中的 withIdentity 方法:
private JobKey key;
public JobBuilder withIdentity(String name, String group) {
key = new JobKey(name, group);
return this;
}
TriggerBuilder 中的 withIdentity 方法:
private TriggerKey key;
public TriggerBuilder<T> withIdentity(String name, String group) {
key = new TriggerKey(name, group);
return this;
}
当 Job 和 Trigger 注册到 Scheduler 中时,就会通过这个 key 来标识 Job 和 Trigger。
任务和触发器的 key(JobKey 和 TriggerKey)允许将它们放入「组」中,这有助于将任务和触发器进行分组,或者说分类。而且任务或触发器的 key 的名称在组中必须是唯一的,他们完整的 key(或标识符)是名称和组的组合。从上面的代码中也可以看到,构造方法都是两个参数的,第一个参数是 name,第二个参数是 group,构造出来的就是整个 key 了。
关于 JobDetail 和 JobDataMap
我们通过写一个 Job 接口的实现类来编写我们等待执行的任务,而 Quartz 需要知道你将哪些属性给了 Job。那 Quartz 是如何知道的呢?Quartz 就是通过 JobDetail 知道的。
注意,我们向 Scheduler 提供了一个 JobDetail 实例, Scheduler 就能知道要执行的是什么任务,只需在构建 JobDetail 时提供任务的类即可(即 newJob(HelloJob.class))。
每次调度程序执行任务时,在调用其 execute 方法之前,它都会创建该任务类的一个新实例。执行完成任务后,对任务类实例的引用将被丢弃,然后该实例将被垃圾回收。
那我们如何为作业实例提供属性或者配置?我们如何在执行的过程中追踪任务的状态?这两个问题的答案是一样的:关键是 JobDataMap,它是 JobDetail 对象的一部分。
JobDataMap 可以用来保存任意数量的(可序列化的)数据对象,这些对象在任务实例执行时需要使用的。JobDataMap 是 Java 中 Map 接口的一个实现,具有一些用于存储和检索原始类型数据的方法。
示例:
PlayGameJob:
public class PlayGameJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobKey key = context.getJobDetail().getKey();
// 获取JobDataMap,该Map在创建JobDetail的时候设置的
JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();
String gameName = jobDataMap.getString("gameName");
float gamePrice = jobDataMap.getFloat("gamePrice");
System.out.println("我玩的" + gameName + "才花费了我" + gamePrice + "块钱");
}
}
接着使用 usingJobData 设置该任务需要的数据,最后调度该任务:
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
JobDetail job = newJob(PlayGameJob.class)
.withIdentity("myJob", "group1")
.usingJobData("gameName", "GTA5")
.usingJobData("gamePrice", 55.5f)
.build();
Trigger trigger = newTrigger()
.withIdentity("myJob", "group1")
.build();
scheduler.scheduleJob(job, trigger);
Thread.sleep(10000);
scheduler.shutdown();
控制台输出:
14:18:43.295 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.simpl.PropertySettingJobFactory - Producing instance of Job 'group1.myJob', class=cn.god23bin.demo.quartz.job.PlayGameJob
14:18:43.299 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 0 triggers
14:18:43.300 [DefaultQuartzScheduler_Worker-1] DEBUG org.quartz.core.JobRunShell - Calling execute on job group1.myJob
我玩的GTA5才花费了我55.5块钱
当然,也可以这样写:
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("gameName", "GTA5");
jobDataMap.put("gamePrice", 55.5f);
JobDetail job = newJob(PlayGameJob.class)
.withIdentity("myJob", "group1")
.usingJobData(jobDataMap)
.build();
之前还说过,Trigger 也是可以有 JobDataMap 的。当你有这种情况,就是在调度器中已经有一个 Job 了,但是想让不同的 Trigger 去触发执行这个 Job,每个不同的 Trigger 触发时,你想要有不同的数据传入这个 Job,那么就可以用到 Trigger 携带的 JobDataMap 了。
噢对了!对于我们上面自己写的 PlayGameJob ,还可以换一种写法,不需要使用通过 context.getJobDetail().getJobDataMap() 获取 JobDataMap 对象后再根据 key 获取对应的数据,直接在这个任务类上写上我们需要的属性,提供 getter 和 setter 方法,这样 Quartz 会帮我们把数据赋值到该对象的属性上。
PlayGameJob:
// 使用Lombok的注解,帮我们生成 getter 和setter 方法以及无参的构造方法
@Data
@NoArgsConstructor
public class PlayGameJob implements Job {
// Quartz 会把数据注入到任务类定义的属性上,直接用就可以了
private String gameName;
private float gamePrice;
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobKey key = context.getJobDetail().getKey();
System.out.println("我玩的" + gameName + "才花费了我" + gamePrice + "块钱");
}
}
这样的效果,就是减少了 execute 方法中的代码量。
如何理解 Job 实例?
这个确实会有一些困惑,比如一开始说的 Job 接口,还有 JobDetail 接口,而且为什么会说成 JobDetail 对象是 Job 的实例?是吧。
想要理解,举个例子:
现在我们写了一个发送消息的 Job 实现类——SendMessageJob。
接着我们创建了多个 JobDetail 对象,这些对象都有不同的定义,比如有叫做 SendMessageToLeBron 的 JobDetail、有 SendMessageToKobe 的 JobDetail,这两个 JobDetail 都有它各自的 JobDataMap 传递给我们的 Job 实现类。
当 Trigger 触发时,Scheduler 将加载与其关联的 JobDetail(任务定义),并通过 Scheduler上配置的 JobFactory 实例化它所引用的任务类(SendMessageJob)。默认的 JobFactory 只是在任务类上调用newInstance() ,然后尝试在与 JobDataMap 中键的名称匹配的类中的属性名,进而调用 setter 方法将 JobDataMap 中的值赋值给对应的属性。
在 Quartz 的术语中,我们将每个 JobDetail 对象称为「Job 定义或者 JobDetail 实例」,将每个正在执行的任务称为「Job 实例或 Job 定义的实例」。
一般情况下,如果我们只使用「任务」这个词,我们指的是一个名义上的任务,简而言之就是我们要做的事情,也可以指 JobDetail。当我们提到实现 Job 接口的类时,我们通常使用术语「任务类」。
两个需要知道的注解
JobDataMap 可以说是任务状态的数据,这里的数据和并发也有点关系。Quartz 提供了几个注解,这几个注解会影响到 Quartz 在这方面的动作。
@DisallowConcurrentExecution 注解是用在任务类上的。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface DisallowConcurrentExecution {
}
DisallowConcurrentExecution 这个注解的作用就是告知 Quartz 这个任务定义的实例(JobDetail 实例)不能并发执行,举个例子,就上面的 SendMessageToLeBron 的 JobDetail 实例,是不能并发执行的,但它是可以与 SendMessageToKobe 的 JobDetail 的实例同时执行。需要注意的是它指的不是任务类的实例(Job 实例)。
@PersistJobDataAfterExecution 注解也是用在任务类上的。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface PersistJobDataAfterExecution {
}
@PersistJobDataAfterExecution 这个注解的作用是告知 Quartz 在 execute 方法成功完成后更新 JobDetail 的 JobDataMap 的存储副本(没有引发异常),以便同一任务的下一次执行能接收更新后的值,而不是最初存储的值。
与 @DisallowConcurrentExecution 注解一样,这是适用于任务定义实例(JobDetail 实例),而不是任务类实例(Job 实例)。
关于 Trigger
我们需要了解 Trigger 有哪些属性可以去设置,从最开始的初体验中,我们给 Trigger 设置了一个 TriggerKey 用来标识这个 Trigger 实例,实际上,它还有好几个属性给我们设置。
共用的属性
上面也说过 Trigger 有不同的类型(比如 SimpleTrigger 和 CronTrigger),不过,即使是不同的类型,也有相同的属性。
- jobKey:作为 Trigger 触发时应执行的任务的标识。
- startTime:记录下首次触发的时间;对于某些触发器,它是指定触发器应该在何时触发。
- endTime:触发器不再生效的时间
- ...
还有更多,下面说一些重要的。
priority
优先级,这个属性可以设置 Trigger 触发的优先级,值越大则优先级越高,就优先被触发执行任务。当然这个是在同一时间调度下才会有这个优先级比较的,如果你有一个 A 任务在 6 点触发,有一个 B 任务在 7 点触发,即使你的 B 任务的优先级比 A 任务的高,也没用,6 点 的 A 任务总是会比 7点 的 B 任务先触发。
misfireInstruction
misfire instruction,错失触发指令,也就是说当某些情况下,导致触发器没有触发,那么就会执行这个指令,默认是一个「智能策略」的指令,它能够根据不同的 Trigger 类型执行不同的行为。
当 Scheduler 启动的时候,它就会先搜寻有没有错过触发的 Trigger,有的话就会基于 Trigger 配置的错失触发指令来更新 Trigger 的信息。
calendar
Quartz 中也有一个 Calendar 对象,和 Java 自带的不是同一个。
在设置 Trigger 的时候,如果我们想排除某些日期时间,那么就可以使用这个 Calendar 对象。
SimpleTrigger
如果我们想在特定的时间点执行一次任务,或者在特定的时刻执行一次,接着定时执行,那么 SimpleTrigger 就能满足我们的需求。
SimpleTrigger 包含了这么几个属性:
- startTime:开始时间
- endTime:结束时间
- repeatCount:重复次数,可以是 0,正整数,或者是一个常量
SimpleTrigger.REPEAT_INDEFINITELY - repeatInterval:重复的时间间隔,必须是 0,或者是一个正的长整型的值(long 类型的值),表示毫秒,即多少毫秒后重复触发
SimpleTrigger 的实例对象可以由 TriggerBuilder 和 SimpleScheduleBuilder 来创建。
示例
下面举几个例子:
- 构建一个给定时刻触发任务的 Trigger,不会重复触发:
// 今天22点30分0秒
Date startAt = DateBuilder.dateOf(22, 30, 0);
// 通过强转构建一个 SimpleTrigger
SimpleTrigger trigger = (SimpleTrigger) newTrigger()
.withIdentity("trigger1", "group1")
.startAt(startAt) // 开始的日期时间
.forJob("job1", "group1") // 通过 job 的 name 和 group 识别 job
.build();
- 构建一个给定时刻触发任务的 Trigger,每十秒重复触发十次:
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.startAt(startAt) // 如果没有给定开始时间,那么就默认现在开始触发
.withSchedule(SimpleScheduleBuilder.simpleSchedule() // 通过 simpleSchedule 方法构建 SimpleTrigger
.withIntervalInSeconds(10)
.withRepeatCount(10)) // 每隔10秒重复触发10次
.forJob(job) // 通过 JobDetail 本身来识别 Job
.build();
- 构建一个给定时刻触发任务的 Trigger,在未来五分钟内触发一次:
Date futureDate = DateBuilder.futureDate(5, DateBuilder.IntervalUnit.MINUTE);
JobKey jobKey = job.getKey();
trigger = (SimpleTrigger) newTrigger()
.withIdentity("trigger5", "group1")
.startAt(futureDate) // 使用 DateBuilder 创建一个未来的时间
.forJob(jobKey) // 通过 jobKey 识别 job
.build();
- 构建一个给定时刻触发任务的 Trigger,然后每五分钟重复一次,直到晚上 22 点:
trigger = newTrigger()
.withIdentity("trigger7", "group1")
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInMinutes(5)
.repeatForever())
.endAt(DateBuilder.dateOf(22, 0, 0))
.build();
- 构建一个给定时刻触发任务的 Trigger,然后每下一个小时整点触发,然后每2小时重复一次,一直重复下去:
trigger = newTrigger()
.withIdentity("trigger8") // 这里没有指定 group 的话,那么 "trigger8" 就会在默认的 group 中
.startAt(DateBuilder.evenHourDate(null)) // 下一个整点时刻 (分秒为零 ("00:00"))
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInHours(2)
.repeatForever())
.forJob("job1", "group1")
.build();
错失触发指令
比如我在要触发任务的时候,机器宕机了,当机器重新跑起来后怎么办呢?
当 Trigger 错失触发时间去触发任务时,那么 Quartz 就需要执行 Misfire Instruction,SimpleTrigger 有如下的以常量形式存在的 Misfire 指令:
- MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
- MISFIRE_INSTRUCTION_FIRE_NOW
- MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
- MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
- MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
- MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT
我们知道,所有的 Trigger,SimpleTrigger 也好,CronTrigger 也好,不管是什么类型,都有一个 Trigger.MISFIRE_INSTRUCTION_SMART_POLICY 可以使用,如果我们使用这个指令,那么 SimpleTrigger 就会动态地在上面 6 个指令中选择,选择的行为取决于我们对于 SimpleTrigger 的设置。
当我们在构建 Trigger 的时候,就可以给 Trigger 设置上 Misfire 指令:
trigger = newTrigger()
.withIdentity("trigger7", "group1")
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInMinutes(5)
.repeatForever()
.withMisfireHandlingInstructionNextWithExistingCount())
.build();
CronTrigger
使用 CronTrigger,我们可以指定触发任务的时间安排(schedule),例如,每周五中午,或 每个工作日和上午9:30, 甚至 每周一,周三上午9:00到上午10:00之间每隔5分钟 和 1月的星期五 。
CronTrigger 也有一个 startTime,用于指定计划何时生效,以及一个(可选的)endTime,用于指定何时停止这个任务的执行。
cron 表达式
cron 表达式有 6 位,是必须的,从左到右分别表示:秒、分、时、日、月、周。
当然也可以是 7 位,最后一位就是年(可选项):秒、分、时、日、月、周、年。
取值说明:正常认识,秒分都是 0 - 59,时则是 0 - 23,日则是 1 - 31,月在这边则是 0-11,周则是 1 - 7(这里的1指的是星期日)。年则只有 1970 - 2099
月份可以指定为0到11之间的值,或者使用字符串 JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV 和 DEC
星期几可以使用字符串 SUN,MON,TUE,WED,THU,FRI 和 SAT 来表示
详细可参考这里:简书-Cron表达式的详细用法
Cron 生成工具:cron.qqe2.com/
示例
- 构建一个 Trigger,每天上午8点到下午5点之间每隔一分钟触发一次:
Trigger trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 0/1 8-17 * * ?"))
.forJob("myJob", "group1")
.build();
- 构建一个 Trigger,每天上午10:42触发:
JobKey myJobKey = job.getKey();
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(CronScheduleBuilder.dailyAtHourAndMinute(10, 42))
.forJob(myJobKey)
.build();
- 构建一个触发器,该触发器将在星期三上午10点42分在TimeZone中触发,而不是系统的默认值:
JobKey myJobKey = job.getKey();
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(CronScheduleBuilder
.weeklyOnDayAndHourAndMinute(DateBuilder.WEDNESDAY, 10, 42)
.inTimeZone(TimeZone.getTimeZone("America/Los_Angeles")))
.forJob(myJobKey)
.build();
错失触发指令
对于 CronTrigger,它有 3 个 Misfire 指令
- MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
- MISFIRE_INSTRUCTION_DO_NOTHING
- MISFIRE_INSTRUCTION_FIRE_NOW
我们在构建 Tirgger 的时候就可以给这个 Trigger 指定它的 Misfire 指令:
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 0/2 8-17 * * ?")
.withMisfireHandlingInstructionFireAndProceed())
.forJob("myJob", "group1")
.build();
关于CRUD
存储定时任务
存储定时任务,方便后续使用,通过 Scheduler 的 addJob 方法
void addJob(JobDetail jobDetail, boolean replace) throws SchedulerException;
该方法会添加一个没有与 Trigger 关联的 Job 到 Scheduler 中,然后这个 Job 是处于休眠的状态直到它被 Trigger 触发进行执行,或者使用 Scheduler.triggerJob() 指定了这个 Job,这个 Job 才会被唤醒。
JobDetail job1 = newJob(MyJobClass.class)
.withIdentity("job1", "group1")
.storeDurably() // Job 必须被定义为 durable 的
.build();
scheduler.addJob(job1, false);
更新已存储的定时任务
addJob 方法的第二个参数-replace,就是用在这里,设置为 true,那么就是更新操作。
JobDetail job1 = newJob(MyJobClass.class)
.withIdentity("job1", "group1")
.build();
// store, and set overwrite flag to 'true'
scheduler.addJob(job1, true);
更新触发器
替换已存在的 Trigger:
// 定义一个新的 Trigger
Trigger trigger = newTrigger()
.withIdentity("newTrigger", "group1")
.startNow()
.build();
// 让 Scheduler 根据 Key 去移除旧的 Trigger, 然后将新的 Trigger 放上去
scheduler.rescheduleJob(new TriggerKey("oldTrigger", "group1"), trigger);
更新已存在的 Trigger:
// 根据 Key 检索已存在的 Trigger
Trigger oldTrigger = scheduler.getTrigger(new TriggerKey("oldTrigger", "group1");
// 获取 TriggerBuilder
TriggerBuilder tb = oldTrigger.getTriggerBuilder();
// 更新触发动作,并构建新的 Trigger
// (other builder methods could be called, to change the trigger in any desired way)
Trigger newTrigger = tb.withSchedule(simpleSchedule()
.withIntervalInSeconds(10)
.withRepeatCount(10)
.build();
// 重新用新的 Trigger 调度 Job
scheduler.rescheduleJob(oldTrigger.getKey(), newTrigger);
取消定时任务
使用 Scheduler 的 deleteJob 方法,入参为一个 TriggerKey,即 Trigger 标识,这样就能取消特定的 Trigger 去触发对应的任务,因为一个 Job 可能有多个 Trigger。
scheduler.unscheduleJob(new TriggerKey("trigger1", "group1"));
使用 Scheduler 的 deleteJob 方法,入参为一个 JobKey,即 Job 标识,这样就能删除这个 Job 并取消对应的 Trigger 进行触发。
scheduler.deleteJob(new JobKey("job1", "group1"));
获取调度器中的所有定时任务
思路:通过 scheduler 获取任务组,然后遍历任务组,进而遍历组中的任务。
// 遍历每一个任务组
for(String group: scheduler.getJobGroupNames()) {
// 遍历组中的每一个任务
for(JobKey jobKey : scheduler.getJobKeys(GroupMatcher.groupEquals(group))) {
System.out.println("通过标识找到了 Job,标识的 Key 为: " + jobKey);
}
}
获取调度器中的所有触发器
思路:同上。
// 遍历每一个触发器组
for(String group: scheduler.getTriggerGroupNames()) {
// 遍历组中的每一个触发器
for(TriggerKey triggerKey : scheduler.getTriggerKeys(GroupMatcher.groupEquals(group))) {
System.out.println("通过标识找到了 Trigger,标识的 Key 为: " + triggerKey);
}
}
获取某一个定时任务的触发器列表
因为一个任务可以有多个触发器,所以是获取触发器列表。
List<Trigger> jobTriggers = scheduler.getTriggersOfJob(new JobKey("jobName", "jobGroup"));
总结
想要使用 Quartz,那么就引入它的依赖。
从使用上来说:
- 对于一个任务,我们可以写一个任务类,即实现了 Job 接口的 Java 类,并重写
execute方法。接着需要一个 JobDetail 来描述这个 Job,或者说把这个 Job 绑定到这个 JobDetail 上。然后我们就需要一个 Trigger,这个 Trigger 是用来表示何使触发任务的,可以说是一个执行计划,在何时如何触发,Trigger 是有好几种类型的,目前常用的就是 SimpleTrigger 和 CronTrigger。最后,在把 JobDetail 和 Trigger 扔给 Scheduler,让它去组织调度; - 对于一个触发器,它有对应的类型,以及对应的 Misfire 指令,一般在创建 Trigger 的时候,就指定上这些信息;
- 对于它们的 CRUD,都是使用调度器进行操作的,比如往调度器中添加任务,更新任务。
从 Quartz 的设计上来说,它有涉及到多种设计模式,包括 Builder 模式,Factory 模式等等。
以上,便是本篇文章的内容,我们下期再见!
最后的最后
希望各位屏幕前的靓仔靓女们给个三连!你轻轻地点了个赞,那将在我的心里世界增添一颗明亮而耀眼的星!
咱们下期再见!