
MATLAB计算变异函数并绘制经验半方差图
??本文介绍基于MATLAB求取空间数据的变异函数,并绘制经验半方差图的方法。
??由于本文所用的数据并不是我的,因此遗憾不能将数据一并展示给大家;但是依据本篇博客的思想与对代码的详细解释,大家用自己的数据,可以将空间数据变异函数计算与经验半方差图绘制的全部过程与分析方法加以完整重现。
1 数据处理
1.1 数据读取
??本文中,我的初始数据为某区域658个土壤采样点的空间位置(X与Y,单位为米)、pH值、有机质含量与全氮含量。这些数据均存储于data.xls文件中;而后期操作多于MATLAB软件中进行。因此,首先需将源数据选择性地导入MATLAB软件中。
??利用MATLAB软件中xlsread函数可以实现这一功能。具体代码附于本文的1.3 正态分布检验及转换处。
1.2 异常数据剔除
??得到的采样点数据由于采样记录、实验室测试等过程,可能具有一定误差,从而出现个别异常值。选用平均值加标准差法对这些异常数据加以筛选、剔除。
??分别利用平均值加标准差法中“2S”与“3S”方法加以处理,发现“2S”方法处理效果相对后者较好,故后续实验取“2S”方法处理结果继续进行。
??其中,“2S”方法是指将数值大于或小于其平均值±2倍标准差的部分视作异常值,“3S”方法则是指将数值大于或小于其平均值±3倍标准差的部分视作异常值。
??得到异常值后,将其从658个采样点中剔除;剩余的采样点数据继续后续操作。
??本部分具体代码附于1.3 正态分布检验及转换处。
1.3 正态分布检验及转换
??计算变异函数需建立在初始数据符合正态分布的假设之上;而采样点数据并不一定符合正态分布。因此,我们需要对原始数据加以正态分布检验。
??一般地,正态分布检验可以通过数值检验与直方图、QQ图等图像加以直观判断。本文综合采取以上两种数值、图像检验方法,共同判断正态分布特性。
??针对数值检验方法,我在一开始准备选择采用Kolmogorov-Smirnov检验方法;但由于了解到,这一方法仅仅适用于标准正态检验,因此随后改用Lilliefors检验。
??Kolmogorov-Smirnov检验通过样本的经验分布函数与给定分布函数的比较,推断该样本是否来自给定分布函数的总体;当其用于正态性检验时只能做标准正态检验。
??Lilliefors检验则将上述Kolmogorov-Smirnov检验改进,其可用于一般的正态分布检验。
??QQ图(Quantile Quantile Plot)是一种散点图,其横坐标表示某一样本数据的分位数,纵坐标则表示另一样本数据的分位数;横坐标与纵坐标组成的散点图代表同一个累计概率所对应的分位数。
??因此,QQ图具有这样的特点:针对y=x这一直线,若散点图中各点均在直线附近分布,则说明两个样本为同等分布;因此,若将横坐标(纵坐标)表示为一个标准正态分布样本的分位数,则散点图中各点均在上述直线附近分布可以说明,纵坐标(横坐标)表示的样本符合或基本近似符合正态分布。本文采用将横坐标表示为正态分布的方式。
??此外,PP图(Probability Probability Plot)同样可以用于正态分布的检验。PP图横坐标表示某一样本数据的累积概率,纵坐标则表示另一样本数据的累积概率;其根据变量的累积概率对应于所指定的理论分布累积概率并绘制的散点图,用于直观地检测样本数据是否符合某一概率分布。和QQ图类似,如果被检验的数据符合所指定的分布,则其各点均在上述直线附近分布。若将横坐标(纵坐标)表示为一个标准正态分布样本的分位数,则散点图中各点均在直线附近分布可以说明,纵坐标(横坐标)表示的样本符合或基本近似符合正态分布。
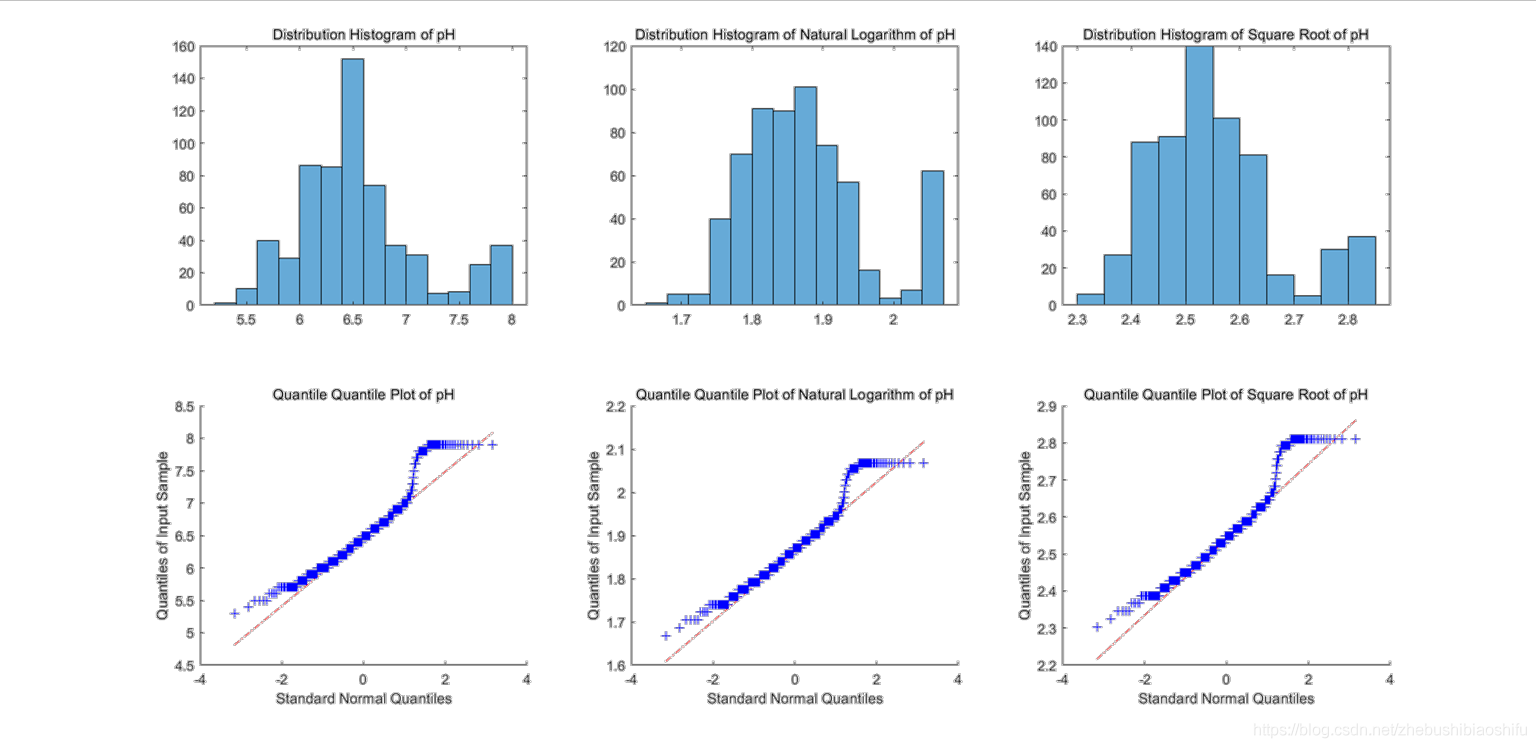
??三种土壤属性,我选择首先以pH数值为例进行操作。通过上述数值检验、图像检验方法,检验得到剔除异常值后的原始pH数值数据并不符合正态分布这一结论。因此,尝试对原数据加以对数、开平方等转换处理;随后发现,原始pH值开平方数据的正态分布特征虽然依旧无法通过较为严格的Lilliefors检验,但其直方图、QQ图的图像检验结果较为接近正态分布,并较之前二者更加明显。故后续取开平方处理结果继续进行。
??值得一提的是,本文后半部分得到pH值开平方数据的实验变异函数及其散点图后,在对其余两种空间属性数据(即有机质含量与全氮含量)进行同样的操作时,发现全氮含量数据在经过“2S”方法剔除异常值后,其原始形式的数据是可以通过Lilliefors检验的,且其直方图、QQ图分布特点十分接近正态分布。
??我亦准备尝试对空间属性数据进行反正弦转换。但随后发现,已有三种属性数值的原始数据并不严格分布在-1至1的区间内,因此并未对其进行反正弦方式的转换。
??经过上述检验、转换处理过后的图像检验结果如下所示。
??以上部分代码如下:
clc;clear;
info=xlsread('data.xls');
oPH=info(:,3);
oOM=info(:,4);
oTN=info(:,5);
mPH=mean(oPH);
sPH=std(oPH);
num2=find(oPH>(mPH+2*sPH)|oPH<(mPH-2*sPH));
num3=find(oPH>(mPH+3*sPH)|oPH<(mPH-3*sPH));
PH=oPH;
for i=1:length(num2)
n=num2(i,1);
PH(n,:)=[0];
end
PH(all(PH==0,2),:)=[];
%KSTest(PH,0.05)
H1=lillietest(PH);
for i=1:length(PH)
lPH(i,:)=log(PH(i,:));
end
H2=lillietest(lPH);
for i=1:length(PH)
sqPH(i,:)=(PH(i,:))^0.5;
end
H3=lillietest(sqPH);
% for i=1:length(PH)
% arcPH(i,:)=asin(PH(i,:));
% end
%
% H4=lillietest(arcPH);
subplot(2,3,1),histogram(PH),title("Distribution Histogram of pH");
subplot(2,3,2),histogram(lPH),title("Distribution Histogram of Natural Logarithm of pH");
subplot(2,3,3),histogram(sqPH),title("Distributio n Histogram of Square Root of pH");
subplot(2,3,4),qqplot(PH),title("Quantile Quantile Plot of pH");
subplot(2,3,5),qqplot(lPH),title("Quantile Quantile Plot of Natural Logarithm of pH");
subplot(2,3,6),qqplot(sqPH),title("Quantile Quantile Plot of Square Root of pH");
2 距离量算
??接下来,需要对筛选出的采样点相互之间的距离加以量算。这是一个复杂的过程,需要借助循环语句。
??本部分具体代码如下。
poX=info(:,1);
poY=info(:,2);
dis=zeros(length(PH),length(PH));
for i=1:length(PH)
for j=i+1:length(PH)
dis(i,j)=sqrt((poX(i,1)-poX(j,1))^2+(poY(i,1)-poY(j,1))^2);
end
end
3 距离分组
??计算得到全部采样点相互之间的距离后,我们需要依据一定的范围划定原则,对距离数值加以分组。
??距离分组首先需要确定步长。经过实验发现,若将步长选取过大会导致得到的散点图精度较低,而若步长选取过小则可能会使得每组点对总数量较少。因此,这里取步长为500米;其次确定最大滞后距,这里以全部采样点间最大距离的一半为其值。随后计算各组对应的滞后级别、各组上下界范围等。
??本部分具体代码附于本文4 平均距离、半方差计算及其绘图处。
4 平均距离、半方差计算及其绘图
??分别计算各个组内对应的点对个数、点对间距离总和以及点对间属性值差值总和等。随后,依据上述参数,最终求出点对间距离平均值以及点对间属性值差值平均值。
??依据各组对应点对间距离平均值为横轴,各组对应点对间属性值差值平均值为纵轴,绘制出经验半方差图。
??本部分及上述部分具体代码如下。
madi=max(max(dis));
midi=min(min(dis(dis>0)));
radi=madi-midi;
ste=500;
clnu=floor((madi/2)/ste)+1;
ponu=zeros(clnu,1);
todi=ponu;
todiav=todi;
diff=ponu;
diffav=diff;
for k=1:clnu
midite=ste*(k-1);
madite=ste*k;
for i=1:length(sqPH)
for j=i+1:length(sqPH)
if dis(i,j)>midite && dis(i,j)<=madite
ponu(k,1)=ponu(k,1)+1;
todi(k,1)=todi(k,1)+dis(i,j); diff(k,1)=diff(k,1)+(sqPH(i)-sqPH(j))^2;
end
end
end
todiav(k,1)=todi(k,1)/ponu(k,1);
diffav(k,1)=diff(k,1)/ponu(k,1)/2;
end
plot(todiav(:,1),diffav(:,1)),title("Empirical Semivariogram of Square Root of pH");
xlabel("Separation Distance (Metre)"),ylabel("Standardized Semivariance");
5 绘图结果
??通过上述过程,得到pH值开平方后的实验变异函数折线图及散点图。

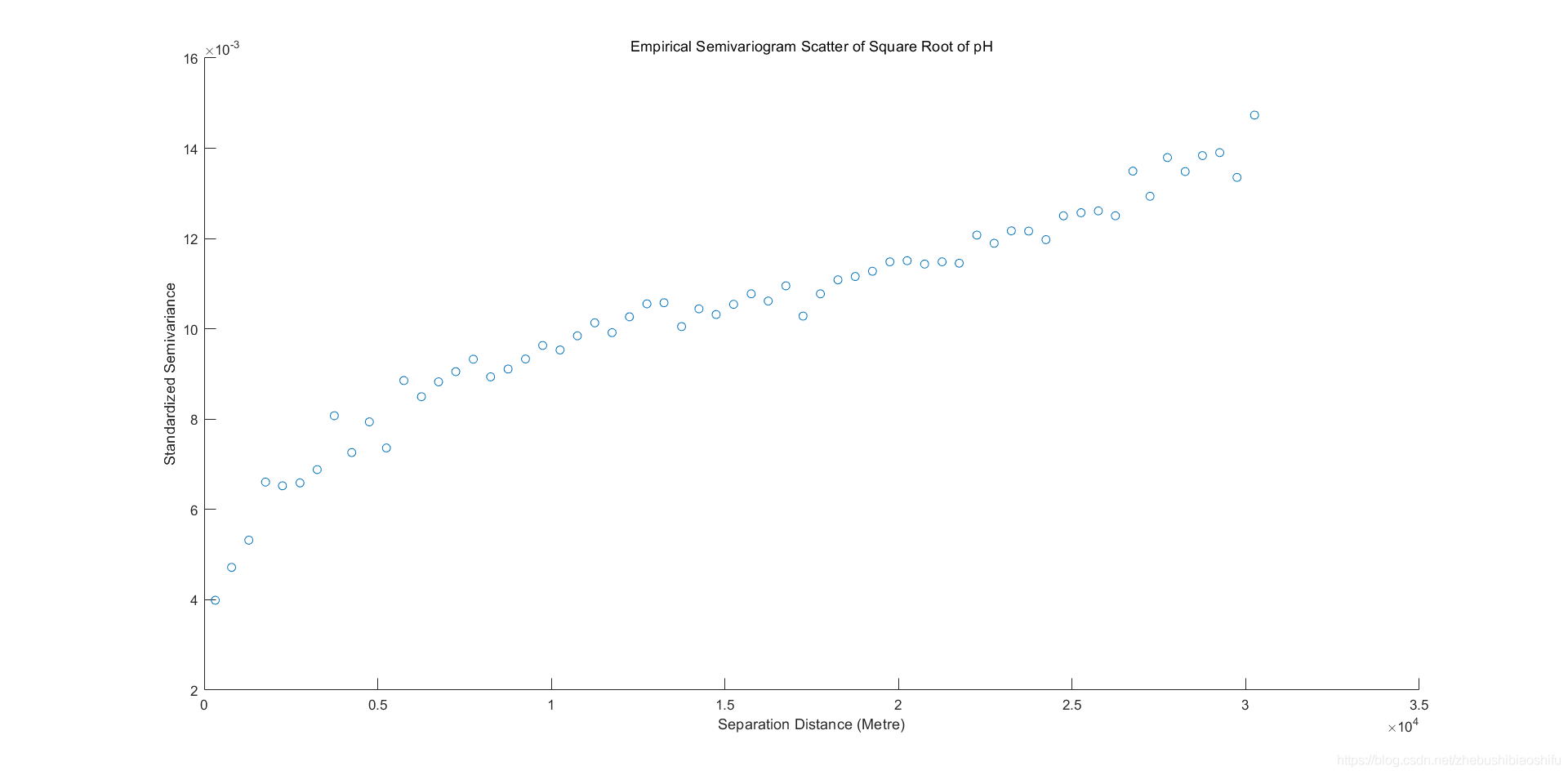
??可以看到,pH值开平方后的实验变异函数较符合于有基台值的球状模型或指数模型。函数数值在距离为0至8000米区间内快速上升,在距离为8000米后数值上升放缓,变程为25000米左右;即其“先快速上升,再增速减缓,后趋于平稳”的图像整体趋势较为明显。但其数值整体表现较低——块金常数为0.004左右,而基台值仅为0.013左右。为验证数值正确性,同样对有机质、全氮进行上述全程操作。
??得到二者对应变异函数折线图与散点图。

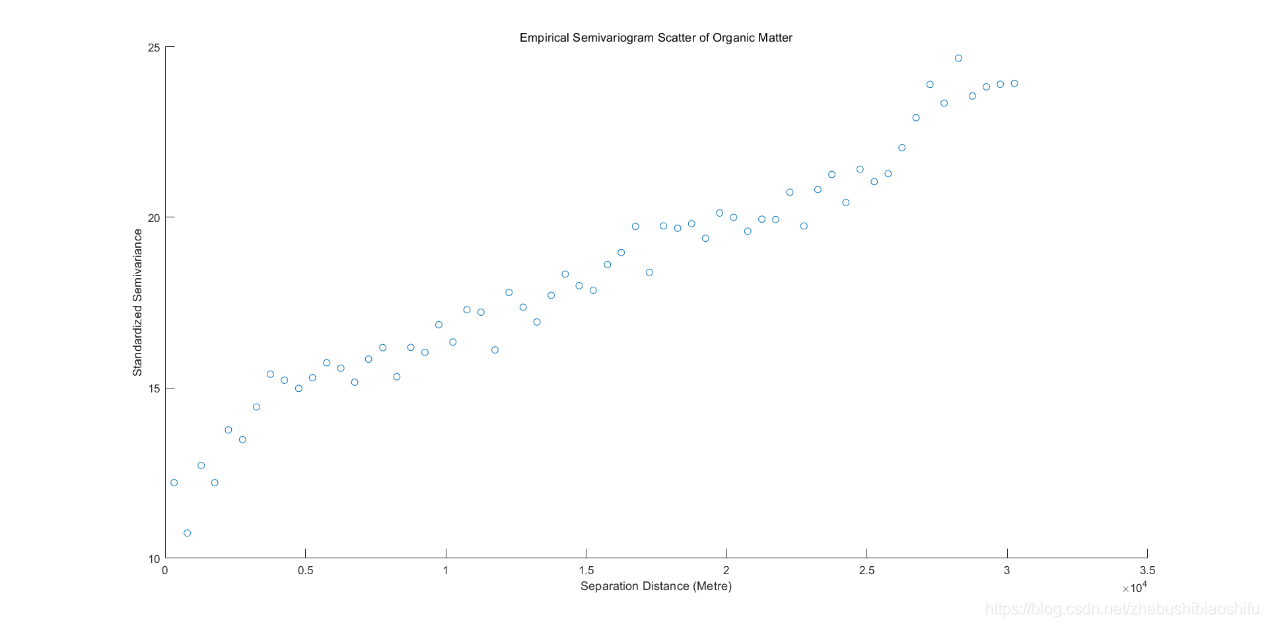
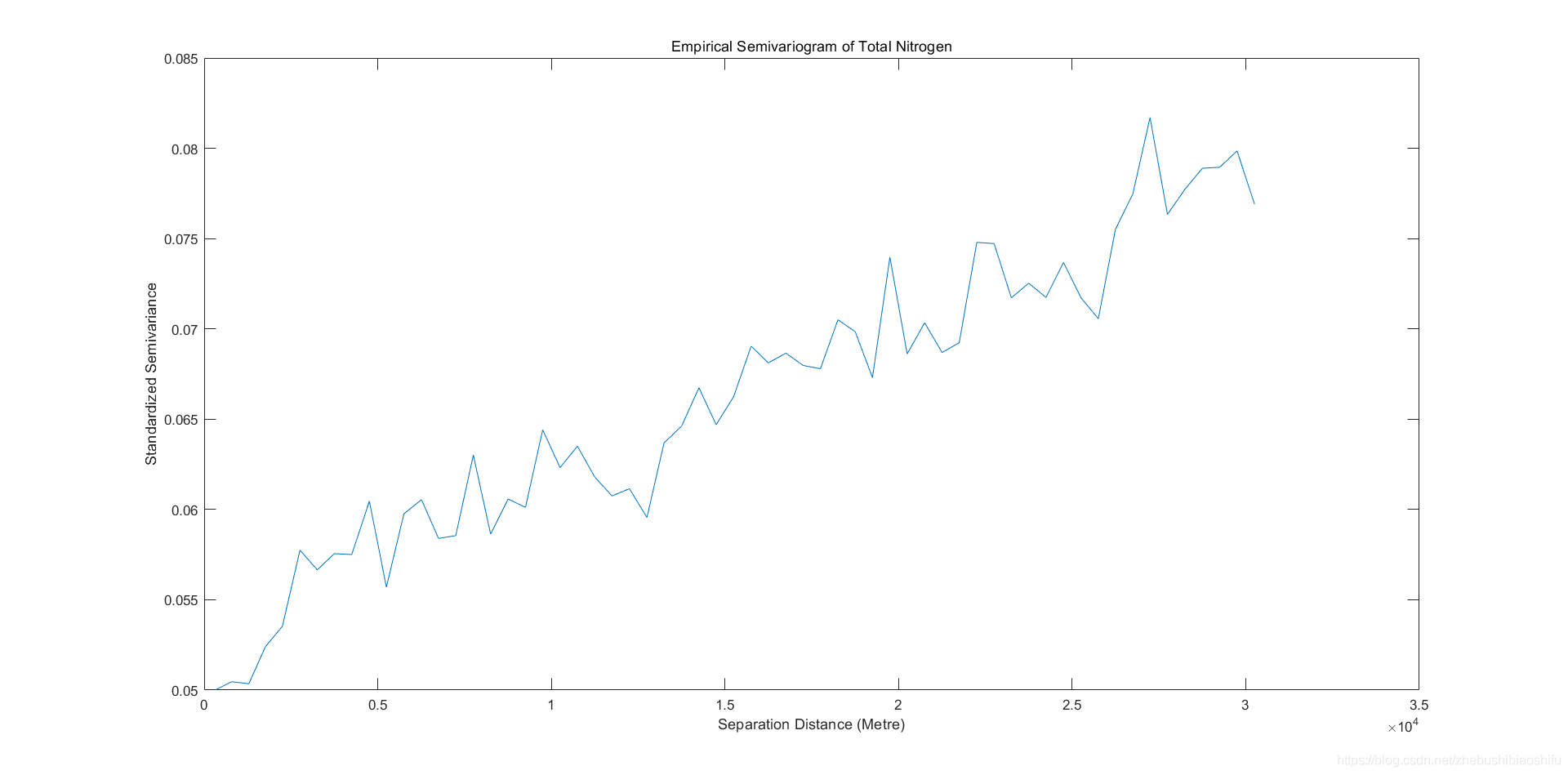
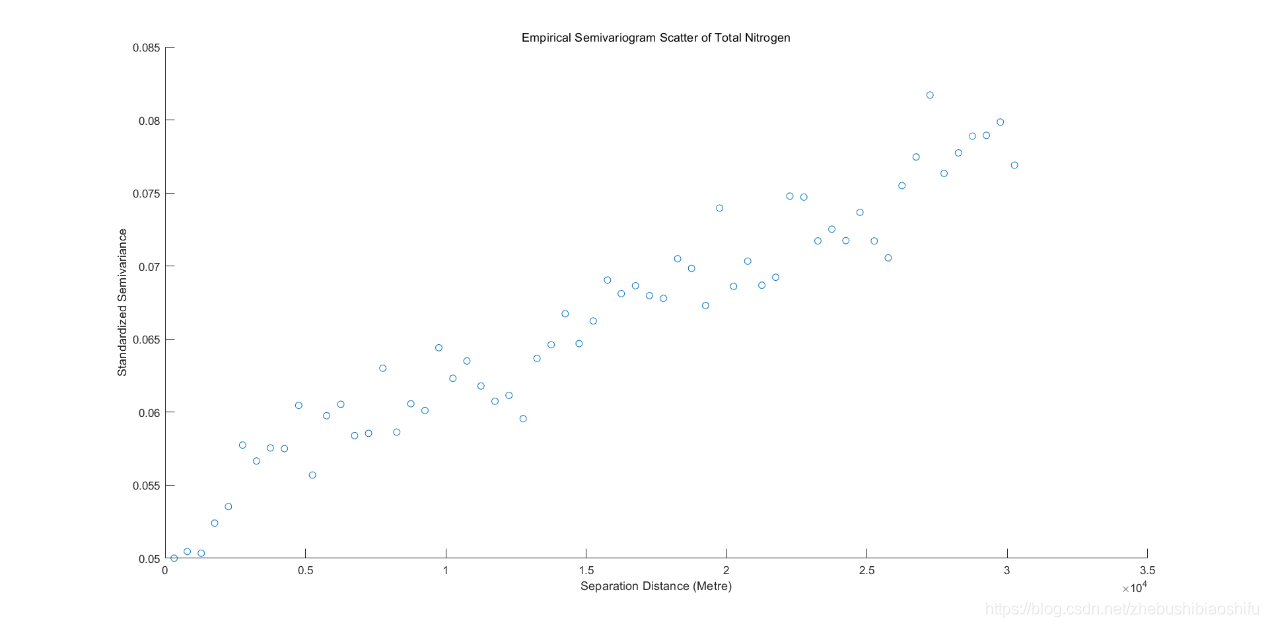
??由以上三组、共计六幅的pH值开平方、有机质与全氮对应的实验变异函数折线图与散点图可知,不同数值对应实验变异函数数值的数量级亦会有所不同;但其整体“先快速上升,再增速减缓,后趋于平稳”的图像整体趋势是十分一致的。
??此外,如上文所提到的,针对三种空间属性数据(pH值、有机质含量与全氮含量)中最符合正态分布,亦是三种属性数据各三种(原始值、取对数与开平方)、共九种数据状态中唯一一个通过Lilliefors正态分布检验的数值——全氮含量经过异常值剔除后的原始值,将其正态分布的图像检验结果特展示如下。

至此,我们就完成了全部的操作、分析过程~