G1 中提供了 Young GC、Mixed GC 两种垃圾回收模式,这两种垃圾回收模式,都是 Stop The World(STW) 的。
G1 没有 fullGC 概念,需要 fullGC 时,调用 serialOldGC 进行全堆扫描(包括 eden、survivor、o、perm)。
一、G1 堆内存结构
堆内存会被切分成为很多个固定大小区域(Region),每个是连续范围的虚拟内存。
1、Region
堆内存中一个区域 (Region) 的大小,可以通过 -XX:G1HeapRegionSize 参数指定,大小区间最小 1M 、最大 32M ,总之是 2 的幂次方。
默认是将堆内存按照 2048 份均分。
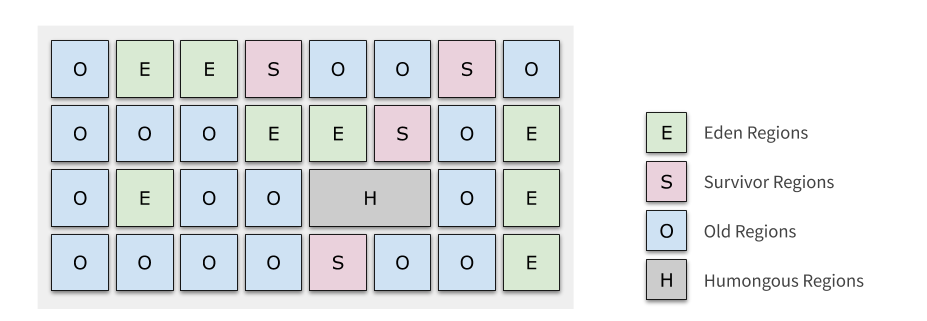
每个 Region 被标记了 E、S、O 和 H,这些区域在逻辑上被映射为 Eden,Survivor 和老年代。
存活的对象从一个区域转移(即复制或移动)到另一个区域。区域被设计为并行收集垃圾,可能会暂停所有应用线程。如上图所示,区域可以分配到 Eden,survivor 和老年代。
此外,还有第四种类型,被称为巨型区域(Humongous Region)。
Humongous 区域主要是为存储超过 50% 标准 region 大小的对象设计,它用来专门存放巨型对象。如果一个 H 区装不下一个巨型对象,那么 G1 会寻找连续的 H 分区来存储。为了能找到连续的 H 区,有时候不得不启动 Full GC 。
2、小对象
G1默认启用了UseTLAB优化,创建对象(小对象)时,优先从TLAB中分配内存,如果分配失败,说明当前TLAB的剩余空间不满足分配需求,则调用allocate_new_tlab方法重新申请一块TLAB空间,之前都是从eden区分配,G1需要从eden region中分配,不过也有可能TLAB的剩余空间还比较大,JVM不想就这么浪费掉这些内存,就会从eden region中分配内存。
3、大对象
要特别注意的是,巨型对象(Humongous Object),即大小超过 3/4 的 Region 大小的对象会作特殊处理,分配到由一个或多个连续 Region 构成的区域。巨型对象会引起其他一些问题。
二、停顿预测模型
Pause Prediction Model 即停顿预测模型。
它在G1中的作用是: >G1 uses a pause prediction model to meet a user-defined pause time target and selects the number of regions to collect based on the specified pause time target.
G1 GC是一个响应时间优先的GC算法,它与CMS最大的不同是,用户可以设定整个GC过程的期望停顿时间,参数-XX:MaxGCPauseMillis指定一个G1收集过程目标停顿时间,默认值200ms,不过它不是硬性条件,只是期望值。
G1根据这个模型统计计算出来的历史数据来预测本次收集需要选择的Region数量,从而尽量满足用户设定的目标停顿时间。
停顿预测模型是以衰减标准偏差为理论基础实现的:
// share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
}
在这个预测计算公式中:davg表示衰减均值,sigma()返回一个系数,表示信赖度,dsd表示衰减标准偏差,confidence_factor表示可信度相关系数。
而方法的参数TruncateSeq,顾名思义,是一个截断的序列,它只跟踪了序列中的最新的n个元素。
三、YoungGC 年轻代收集
在分配一般对象(非巨型对象)时,当所有 eden region 使用达到最大阀值、并且无法申请足够内存时,会触发一次 YoungGC 。
每次 younggc 会回收所有Eden 、以及 Survivor 区,并且将存活对象复制到 Old 区以及另一部分的 Survivor 区。
第一阶段:扫描根
跟 CMS 类似,Stop the world,扫描 GC Roots 对象;
第二阶段:处理 Dirty card,更新 RSet
处理 dirty card queue 中的 card,更新 RSet。此阶段完成后,RSet 可以准确的反映老年代对所在的内存分段中对象的引用。
第三阶段:扫描 RSet
扫描 RSet 中所有 old 区,对扫描到的 young 区或者 survivor 区的引用;
第四阶段:复制扫描出的存活的对象到 survivor2/old 区
Eden 区内存段中存活的对象会被复制到 Survivor 区中空的内存分段,Survivor 区内存段中存活的对象如果年龄未达阈值,年龄会加1,达到阀值会被会被复制到 old 区中空的内存分段。如果 Survivor 空间不够,Eden 空间的部分数据会直接晋升到老年代空间。
第五阶段:处理引用队列、软引用、弱引用、虚引用
处理 Soft,Weak,Phantom,Final,JNI Weak 等引用。
最终 Eden 空间的数据为空,GC 停止工作,而目标内存中的对象都是连续存储的,没有碎片,所以复制过程可以达到内存整理的效果,减少碎片。
四、Mixed GC 混合GC
多次 Young GC 之后,当越来越多的对象晋升到老年代 old region,Old Regions 慢慢累积,直到到达阈值(InitiatingHeapOccupancyPercent,简称 IHOP),我们不得不对 Old Regions 做收集。这个阈值在 G1 中是根据用户设定的 GC 停顿时间动态调整的,也可以人为干预。
对 Old Regions 的收集会同时涉及若干个 Young 和 Old Regions,因此被称为 Mixed GC。
Mixed GC 很多地方都和 Young GC 类似,不同之处是:它还会选择若干最有潜力的 Old Regions(收集垃圾的效率最高的 Regions),这些选出来要被 Evacuate 的 Region 称为本次的 Collection Set (CSet)。
这里需要注意:是一部分老年代,而不是全部老年代,可以选择哪些 old region 进行收集,从而可以对垃圾回收的耗时时间进行控制。
结合Region 的设计,只要把每次的 Collection Set 规模控制在一定范围,就能把每次收集的停顿时间软性地控制在 MaxGCPauseMillis 以内。起初这个控制可能不太精准,随着 JVM 的运行估算会越来越准确。
那来不及收集的那些 Region 呢?多来几次就可以了。所以你在 GC 日志中会看到 continue mixed GCs 的字样,代表分批进行的各次收集。这个过程会多次重复,直到垃圾的百分比降到 G1HeapWastePercent 以内,或者到达 G1MixedGCCountTarget 上限。
1、STAB和TAMS
在 Evacuation 之前,我们要通过并发标记来确定哪些对象是垃圾、哪些还活着。G1 中的 Concurrent Marking 是以 Region 为单位的,为了保证结果的正确性,这里用到了 Snapshot-at-the-beginning(SATB)算法。
SATB 算法顾名思义是对 Marking 开始时的一个(逻辑上的)Snapshot 进行标记。为什么要用 Snapshot 呢?下面就是一个直接标记导致问题的例子:对象 X 由于没有被标记到而被标记为垃圾,导致 B 引用失效。

如果只是对现场情况做标记,可能会漏掉某些对象。SATB 算法为了解决这一问题,在修改引用 X.f = B 之前插入了一个 Write Barrier,记录下被覆写之前的引用地址。这些地址最终也会被 Marking 线程处理,从而确保了所有在 Marking 开始时的引用一定会被标记到。
这个 Write Barrier 伪代码如下:
|
1
2
3
|
t = the previous referenced address // 记录原本的引用地址
if (t has been marked && t != NULL) // 如果地址 t 还没来的及标记,且 t 不为 NULL
satb_enqueue(t) // 放到 SATB 的待处理队列中,之后会去扫描这个引用
|
通过以上措施,SATB 确保 Marking 开始时存活的对象一定会被标记到。
2、Concurrent Marking
G1标记的过程和 CMS 中是类似的,可以看作一个优化版的 DFS:记当前已经标记到的 offset 为 cur,随着标记的进行 cur 不断向后推进。每当访问到地址 < cur 的对象,就对它做深度扫描,递归标记所有应用;反之,对于地址 > cur 的对象,只标记不扫描,等到 cur 推进到那边的时候再去做扫描。
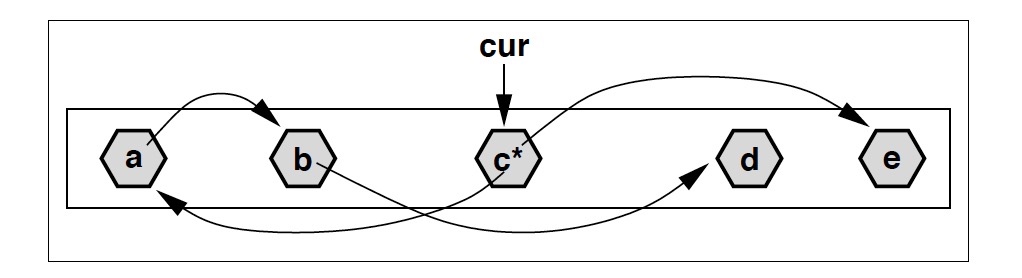
上图中,假设当前 cur 指向对象 c,c有两个引用:a 和 e,其中 a 的地址小于 cur,因而做了扫描;而 e 则仅仅是标记。扫描 a 的过程中又发现了对象 b,b 同样被标记并继续扫描。但是 b 引用的 d 在 cur 之后,所以 d 仅仅是被标记,不再继续扫描。
最后一个问题是:如何处理 Concurrent Marking 中新产生的对象?因为 SATB 算法只保证能标记到开始时 snapshot 的对象,对于新出现的那些对象,我们可以简单地认为它们全都是存活的,毕竟数量不是很多。
2、回收过程
G1垃圾回收周期如下图所示:
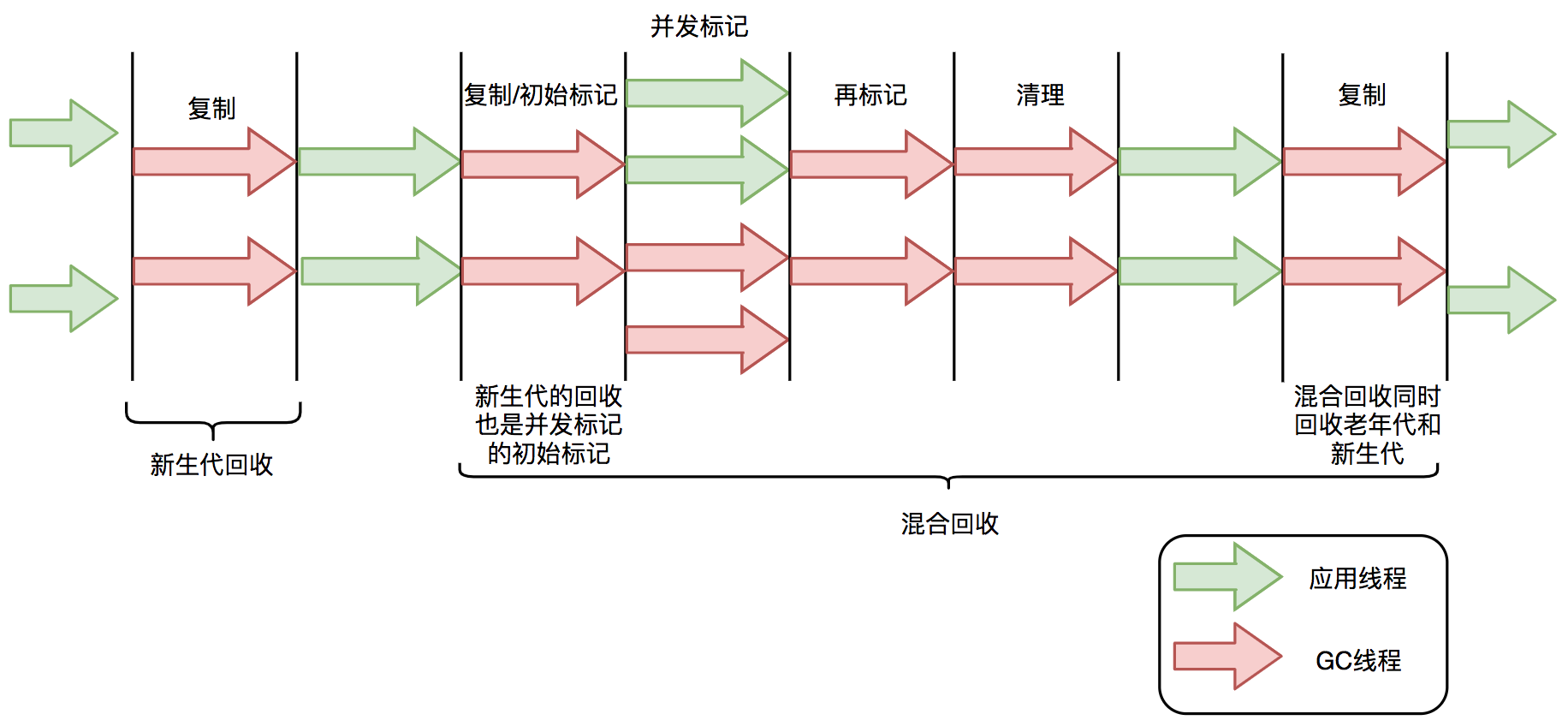
G1的Mixed GC回收过程可以分为标记阶段、清理阶段和复制阶段。
(1)标记阶段停顿分析
- 初始标记阶段:初始标记阶段是指从GC Roots出发标记全部直接子节点的过程,该阶段是STW的。由于GC Roots数量不多,通常该阶段耗时非常短。
- 并发标记阶段:并发标记阶段是指从GC Roots开始对堆中对象进行可达性分析,找出存活对象。该阶段是并发的,即应用线程和GC线程可以同时活动。并发标记耗时相对长很多,但因为不是STW,所以我们不太关心该阶段耗时的长短。
- 再标记阶段:重新标记那些在并发标记阶段发生变化的对象。该阶段是STW的。
(2)清理阶段停顿分析
- 清理阶段清点出有存活对象的分区和没有存活对象的分区,该阶段不会清理垃圾对象,也不会执行存活对象的复制。该阶段是STW的。
(3)复制阶段停顿分析
- 复制算法中的转移阶段需要分配新内存和复制对象的成员变量。转移阶段是STW的,其中内存分配通常耗时非常短,但对象成员变量的复制耗时有可能较长,这是因为复制耗时与存活对象数量与对象复杂度成正比。对象越复杂,复制耗时越长。
四个STW过程中,初始标记因为只标记GC Roots,耗时较短。
再标记因为对象数少,耗时也较短。清理阶段因为内存分区数量少,耗时也较短。
转移阶段要处理所有存活的对象,耗时会较长。
因此,G1停顿时间的瓶颈主要是标记-复制中的转移阶段STW。
为什么转移阶段不能和标记阶段一样并发执行呢?主要是G1未能解决转移过程中准确定位对象地址的问题。
五、Serial Old GC
如果mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会使用serial old GC(full GC)来收集整个GC heap。所以我们可以知道,G1是不提供full GC的。
Serial Old是Serial收集器的老年代版本,是一个单线程收集器,使用标记-整理算法。
1、Serial Old收集
Serial收集器过程如下:
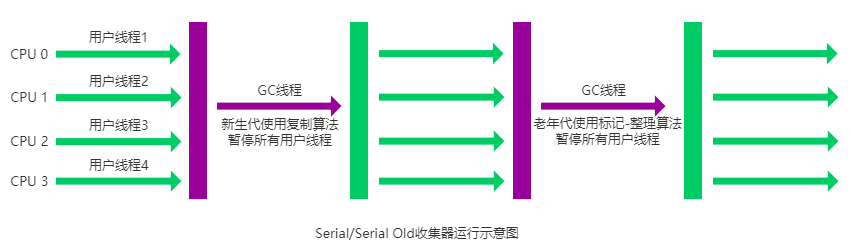
优点:算法简单,内存占用少,CPU不用切换进程,导致上下文切换时间短,总体效率高
缺点:GC阶段卡顿
2、G1产生FGC如何解决
- 扩展内存
- 提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大)
- 降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%)
六、对比CMS
1、G1 相比较 CMS的改进
- 算法: G1 基于标记--整理算法, 不会产生空间碎片,在分配大对象时,不会因无法得到连续的空间,而提前触发一次 FULL GC 。
- 停顿时间可控: G1可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间避免应用雪崩现象。
- 并行与并发:G1 能更充分的利用 CPU 多核环境下的硬件优势,来缩短 stop the world 的停顿时间。
2、CMS 和 G1 的区别
- CMS 中,堆被分为 PermGen,YoungGen,OldGen ;而 YoungGen 又分了两个 survivo 区域。在 G1 中,堆被平均分成几个区域 (region) ,在每个区域中,虽然也保留了新老代的概念,但是收集器是以整个区域为单位收集的。
- G1 在回收内存后,会立即同时做合并空闲内存的工作;而 CMS ,则默认是在 STW(stop the world)的时候做。
- G1 会在 Young GC 中使用;而 CMS 只能在 O 区使用。
参考资料:
https://ericfu.me/g1-garbage-collector/
https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html
https://tech.meituan.com/2016/09/23/g1.html
https://juejin.cn/post/6844904106268557320
