
【算法数据结构专题】「延时队列算法」史上手把手教你针对层级时间轮(TimingWheel)实现延时队列的开发实战落地(上)
承接上文
承接之前的【精华推荐 |【算法数据结构专题】「延时队列算法」史上非常详细分析和介绍如何通过时间轮(TimingWheel)实现延时队列的原理指南】,让我们基本上已经知道了「时间轮算法」原理和核心算法机制,接下来我们需要面向于实战开发以及落地角度进行分析如何实现时间轮的算法机制体系。
前言回顾
什么是时间轮
- 调度模型:时间轮是为解决高效调度任务而产生的调度模型/算法思想。
- 数据结构:通常由hash表和双向链表实现的数据结构。
为什么用时间轮?
对比传统队列的优势
相比传统的队列形式的调度器来说,时间轮能够批量高效的管理各种延时任务、周期任务、通知任务等等。例如延时队列/延时任务体系
延时任务/队列体系
**延时任务、周期性任务,应用场景主要在延迟大规模的延时任务、周期性的定时任务等。
案例-Kafka的延时操作系列
比如,对于耗时的网络请求(比如Produce时等待ISR副本复制成功)会被封装成DelayOperation进行延迟处理操作,防止阻塞Kafka请求处理线程,从而影响效率和性能。
传统队列带来的性能问题
Kafka没有使用传统的队列机制(JDK自带的Timer+DelayQueue实现)。因为时间复杂度上这两者插入和删除操作都是 O(logn),不能满足Kafka的高性能要求。
基于JDK自带的Timer+DelayQueue实现
JDK Timer和DelayQueue底层都是个优先队列,即采用了minHeap的数据结构,最快需要执行的任务排在队列第一个,不一样的是Timer中有个线程去拉取任务执行,DelayQueue其实就是个容器,需要配合其他线程工作。
ScheduledThreadPoolExecutor是JDK的定时任务实现的一种方式,其实也就是DelayQueue+池化线程的一个实现。
基于时间轮TimeWheel的实现
时间轮算法的插入删除操作都是O(1)的时间复杂度,满足了Kafka对于性能的要求。除了Kafka以外,像 Netty 、ZooKeepr、Dubbo等开源项目、甚至Linux内核中都有使用到时间轮的实现。
当流量小时,使用DelayQueue效率更高。当流量大事,使用时间轮将大大提高效率。
时间轮算法是怎么样的,算法思想是什么?
时间轮的数据结构
数据结构模型主要由:时间轮环形队列和时间轮任务列表组成。
-
时间轮(TimingWheel) 是一个存储定时任务的环形队列(cycle array),底层采用环形数组实现,数组中的每个元素可以对应一个时间轮任务任务列表(TimeWheelTaskList) 。
-
时间轮任务任务列表(TimeWheelTaskList) 是一个环形的双向链表,其中的每个元素都是延时/定时任务项(TaskEntry),其中封装了任务基本信息和元数据(Metadata)。
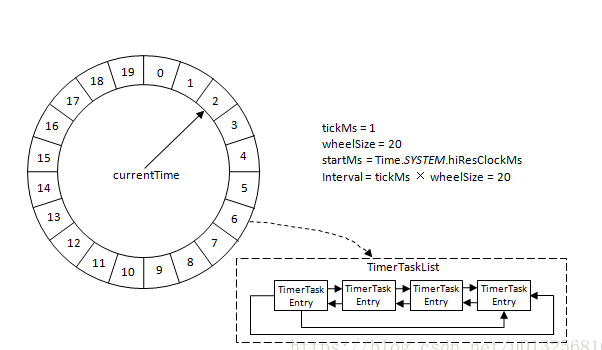
可以看到图中的几个参数:
-
startMs: 开始时间
-
tickMs: 时间轮执行的最小单位。时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度就是tickMs。
-
wheelSize: 时间轮中环形队列的数量。时间轮的时间格数量是固定的,可用wheelSize来表示。
-
interval:时间轮的整体时间跨度 = tickMs * wheelSize
根据上面这两个属性,我们就可以讲整个时间轮的总体时间跨度(interval)可以通过公式tickMs × wheelSize计算得出。例如果时间轮的tickMs=1ms,wheelSize=20,那么可以计算得出interval为20ms。
currentTime游标指针
此外,时间轮还有一个游标指针,我们称之为(currentTime),它用来表示时间轮当前所处的时间,currentTime是tickMs的整数倍。
整个时间轮的总体跨度是不变的,随着指针currentTime的不断流动,当前时间轮所能处理的时间段也在不断后移,整个时间轮的时间范围在currentTime和currentTime+interval之间。
currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimeWheelTaskList中的所有任务。
currentTime游标指针的运作流程
-
初始情况下表盘指针currentTime指向时间格0,此时有一个定时为2ms的任务插入进来会存放到时间格为2的任务列表中。
-
随着时间的不断推移,指针currentTime不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2所对应的任务列表中的任务做相应的到期操作。
-
此时若又有一个定时为8ms的任务插入进来,则会存放到时间格10中,currentTime再过8ms后会指向时间格10。
总之,整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间。
层次化时间轮机制
如果当提交了超过整体跨度(interval)的延时任务,如何解决呢?因此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到层次时间轮中。
层次化时间轮实现原理介绍
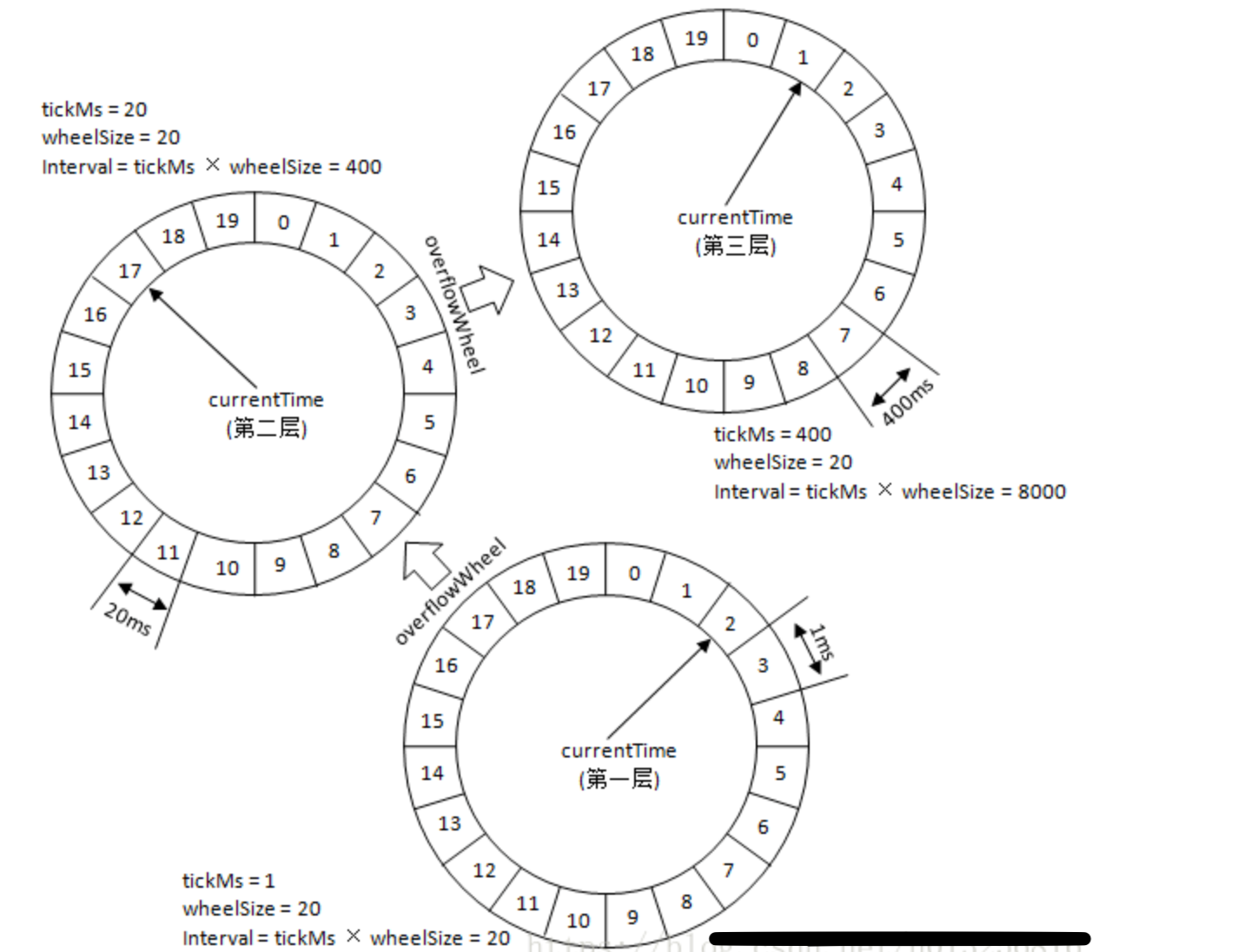
层次化时间轮任务升级跃迁
在任务插入时,如果第一层时间轮不满足条件,就尝试插入到高一层的时间轮,以此类推。
-
第一层的时间轮tickMs=1ms, wheelSize=20, interval=20ms
-
第二层的时间轮的tickMs为第一层时间轮的interval,即为20ms
第一层和第二层时间轮的wheelSize是固定的,都是20,那么第二层的时间轮的总体时间跨度interval为400ms。正好是第一层时间轮的20倍。以此类推,这个400ms也是第三层的tickMs的大小,第三层的时间轮的总体时间跨度为8000ms。
- 第N层时间轮走了一圈,等于N+1层时间轮走一格。即高一层时间轮的时间跨度等于当前时间轮的整体跨度。
层次化时间轮任务降级跃迁
随着时间推进,也会有一个时间轮降级的操作,原本延时较长的任务会从高一层时间轮重新提交到时间轮中,然后会被放在合适的低层次的时间轮当中等待处理;
案例介绍
层次化时间轮任务升级跃迁
例如:350ms的定时任务,显然第一层时间轮不能满足条件,所以就升级到第二层时间轮中,最终被插入到第二层时间轮中时间格17所对应的TimeWheelTaskList中。如果此时又有一个定时为450ms的任务,那么显然第二层时间轮也无法满足条件,所以又升级到第三层时间轮中,最终被插入到第三层时间轮中时间格1的TimeWheelTaskList中。
层次化时间轮任务降级跃迁
在 [400ms,800ms) 区间的多个任务(比如446ms、455ms以及473ms的定时任务)都会被放入到第三层时间轮的时间格1中,时间格1对应的TimerTaskList的超时时间为400ms
随着时间的流逝,当次TimeWheelTaskList到期之时,原本定时为450ms的任务还剩下50ms的时间,还不能执行这个任务的到期操作。
这里就有一个时间轮降级的操作,会将这个剩余时间为50ms的定时任务重新提交到层级时间轮中,此时第一层时间轮的总体时间跨度不够,而第二层足够,所以该任务被放到第二层时间轮到期时间为[40ms,60ms)的时间格中。
再经历了40ms之后,此时这个任务又被“察觉”到,不过还剩余10ms,还是不能立即执行到期操作。所以还要再有一次时间轮的降级,此任务被添加到第一层时间轮到期时间为[10ms,11ms)的时间格中,之后再经历10ms后,此任务真正到期,最终执行相应的到期操作。
后续章节预告
接下来小编会出【算法数据结构专题】「延时队列算法」史上手把手教你针对层级时间轮(TimingWheel)实现延时队列的开发实战落地(下),进行实战编码进行开发对应的层次化的时间轮算法落地。
本文来自博客园,作者:洛神灬殇,转载请注明原文链接:https://www.cnblogs.com/liboware/p/17290435.html,任何足够先进的科技,都与魔法无异。