
迁移学习(APE)《Attract, Perturb, and Explore: Learning a Feature Alignment Network for Semi-supervised Domain Adaptation》
论文信息
论文标题:Attract, Perturb, and Explore: Learning a Feature Alignment Network for Semi-supervised Domain Adaptation
论文作者:Taekyung Kim
论文来源:2020 ECCV
论文地址:download
论文代码:download
视屏讲解:click
1 摘要
提出了目标域内的域内差异问题。
提出了一个 SSDA 框架,旨在通过减轻域内差异来对齐特征。 本文框架主要由三种方案组成,即吸引、扰动和探索。 首先,吸引方案全局最小化目标域内的域内差异。 其次,我们证明了传统的对抗性扰动方法与 SSDA 的不相容性。 然后,我们提出了一种域自适应对抗性扰动方案,该方案以减少域内差异的方式扰动给定的目标样本。 最后,探索方案通过选择性地对齐与扰动方案互补的未标记目标特征,以与吸引方案互补的类方式局部对齐特征。 我们对域适应基准数据集(例如 DomainNet、Office-Home 和 Office)进行了广泛的实验。 我们的方法在所有数据集上实现了最先进的性能。
2 介绍
在本文中,我们引入了一个称为域内差异的新概念来分析 UDA 和 SSL 方法的失败并解决 SSDA 问题。 域内差异是 SSDA 问题中的一个长期问题,在标记样本监督期间出现,但迄今为止从未被讨论过。 在 UDA 问题中,对标记源样本的监督一般不会严重影响目标域分布,但会隐式吸引一些与源特征相似的可对齐目标特征。 因此,通过减少域间差异来对齐源域和目标域是合理的。 然而,在 SSDA 问题中,对标记目标样本的监督强制将相应的特征及其邻域吸引到源特征簇中,这保证了两个域分布之间的部分对齐。此外,未标记的目标样本与已标记的目标样本相关性较低,受监督的影响较小,最终保持不对齐(Fig. 1中Top一行)。因此,目标域分布分为对齐的目标子分布和未对齐的目标子分布,导致目标域内域内差异。UDA和SSL方法的失败将在第3节中详细讨论。
受此启发,我们提出了一个 SSDA 框架,该框架通过解决目标域内的域内差异来对齐跨域特征。 我们的框架侧重于增强未对齐目标样本的可辨别性并调制类原型,即每个类的代表性特征。 它由三种方案组成,即吸引、扰动和探索,如图 1 所示。首先,吸引方案通过域内差异最小化将未对齐的目标子分布与对齐的目标子分布对齐。 其次,我们讨论了为什么传统的对抗性扰动方法在 SSDA 问题中无效。 与这些方法不同,我们的扰动方案将目标子分布扰动到它们的中间区域,以将标签传播到未对齐的目标子分布。 请注意,我们的扰动方案不会破坏已经对齐的目标特征,因为它还会临时生成扰动特征以进行正则化。 最后,探索方案以类感知方式局部调制原型,与吸引和扰动方案互补。 我们进行了大量实验,以评估所提出的方法在域适应数据集(如 DomainNet、Office-Home、Office)上的表现,并取得了最先进的性能。 我们还深入详细地分析了我们的方法。
贡献:
- 我们在 SSDA 问题中引入了目标域内的域内差异问题。
- 我们提出了一个 SSDA 框架,通过三种方案解决域内差异问题,即吸引、扰动和探索。我们在 DomainNet、Office-Home 和 Office 上进行了广泛的实验。 我们在各种方法中实现了最先进的性能,包括香草深度神经网络、UDA、SSL 和 SSDA 方法。我们在 DomainNet、Office-Home 和 Office 上进行了广泛的实验。 我们在各种方法中实现了最先进的性能,包括香草深度神经网络、UDA、SSL 和 SSDA 方法。qqq
- 吸引方案通过域内差异最小化将未对齐的目标子分布与对齐的目标子分布对齐。
- 扰动方案将目标子分布扰动到它们的中间区域,以将标签传播到未对齐的目标子分布。
- 探索方案以类感知方式局部调制原型,与吸引和扰动方案互补。
3 域内差异
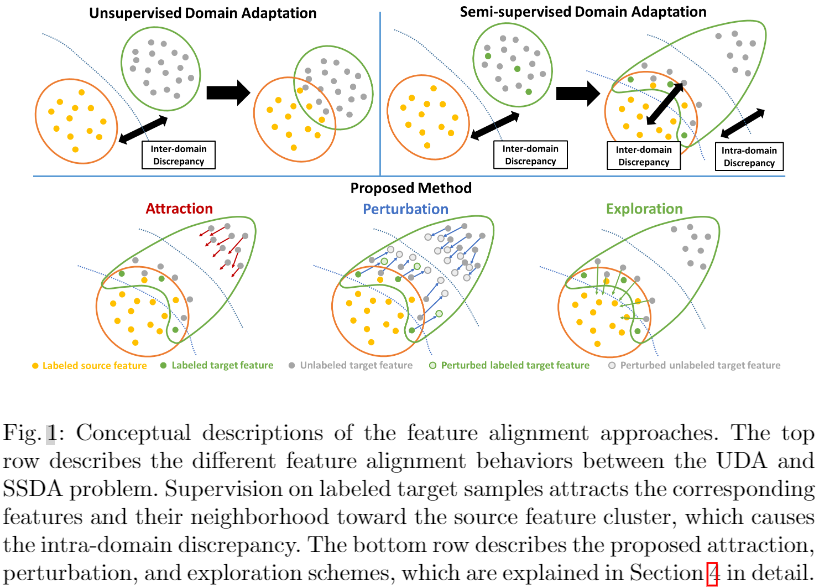
域的域内差异是域内子分布之间的内部分布差距。 尽管我们在半监督域适应 (SSDA) 问题中展示了域内差异问题,但此类子分布也可能出现在无监督域适应 (UDA) 问题中,因为通常存在与源集群对齐的目标样本。 然而,由于每个域通常在域样本之间具有独特的相关性,因此目标域分布不容易分离成不同的子分布,最终导致域内差异不足。 因此,传统的域间差异最小化方法已有效地应用于 UDA 问题。相反,在SSDA 问题,对标记目标样本的监督强制将目标域确定性地分为对齐的子分布和未对齐的子分布。 更具体地说,如 Fig. 1 的第一行所示,标签的存在将目标样本及其邻域拉向每个相应标签的源特征簇。 此外,与给定标记目标样本相关性较低的未标记目标样本仍然远离源特征簇,产生不准确甚至无意义的推理结果。 Fig. 2 演示了目标域中域内差异的存在。 尽管每个类只给出了三个目标标签,但大量目标样本已对齐,而错误预测的目标样本 Fig. 2(f)中的红色圆圈)仍然远离源域。
域内差异的存在使得传统的域自适应方法不太适合 SSDA 问题。 域自适应的最终目标是增强目标域的可辨别性,这种情况下大部分错误发生在未对齐的目标子分布上。 因此,解决 SSDA 问题取决于未对齐子分布的对齐程度。 然而,通用域自适应方法侧重于减少源域和目标域之间的域间差异,而不考虑目标域内的域内差异。 由于对齐的目标子分布的存在导致域间差异的低估,域间差异减少方法在 SSDA 问题中的效果较差。 此外,由于对齐的目标子分布是以类感知方式对齐的,因此这种方法甚至可能产生负面影响。
同样,传统的半监督学习 (SSL) 方法也存在 SSDA 问题中的域内差异问题。 它源于 SSDA 和 SSL 问题之间的不同假设。 由于 SSL 问题假设从相同分布中抽样标记和未标记数据,SSL 方法主要关注将正确的标签传播到它们的邻居。 相反,SSDA 问题假设源域和目标域之间存在显着的分布差异,并且标记样本由源域主导。 由于正确预测的目标样本与源分布高度一致,而错误预测的目标样本远离它们,我们不能再假设这些目标样本共享相同的分布。 因此,SSL 方法仅在错误预测的子分布内传播错误,并且由于源域的丰富分布,在正确预测的子分布中传播也毫无意义。 受解释的启发,我们提出了一个解决域内差异的框架。

4 方法
4.1 问题表述
Let us denote the set of source domain samples by $\mathcal{D}_{s}=\left\{\left(\mathrm{x}_{i}^{s}, y_{i}^{s}\right)\right\}_{i=1}^{m_{s}}$ . For the target domain, $\mathcal{D}_{t}=\left\{\left(\mathbf{x}_{i}^{t}, y_{i}^{t}\right)\right\}_{i=1}^{m_{t}}$ and $\mathcal{D}_{u}=\left\{\left(\mathbf{x}_{i}^{u}\right)\right\}_{i=1}^{m_{u}}$ denote the sets of labeled and unlabeled target samples, respectively. SSDA aims to enhance the target domain discriminability through training on $\mathcal{D}_{s}$, $\mathcal{D}_{t}$ , and $\mathcal{D}_{u}$ .
4.2 整体框架
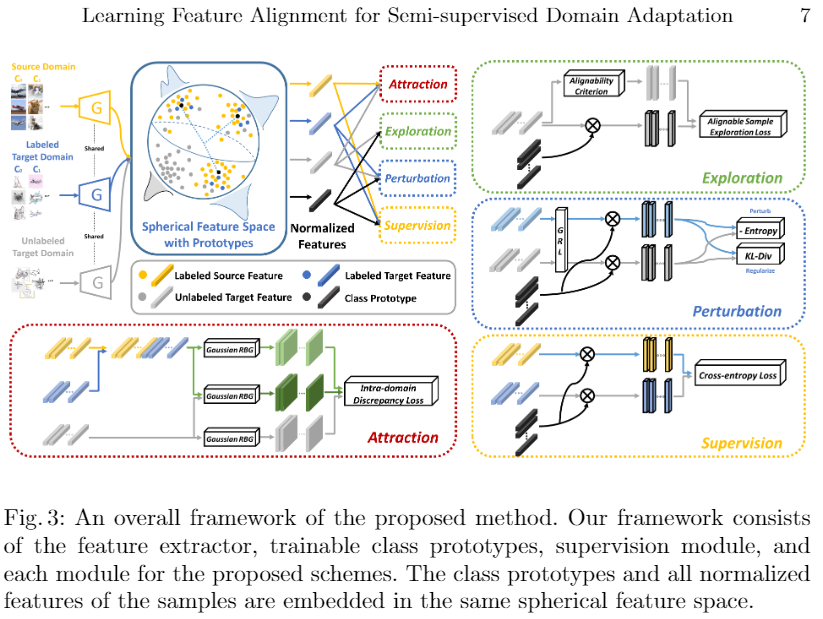
4.3 带有原型的球形特征空间
在对齐特征分布时,确定要适应的特征空间至关重要。 即使使用相同的方法,性能也可能不会提高,具体取决于应用的特征空间。 因此,我们在[2]中采用基于相似性的原型分类器来准备合适的特征空间以更好地适应。 简而言之,原型分类器输入归一化特征并比较所有类原型之间的相似性,从而减少类内变化作为结果。 对于分类器训练,我们使用交叉熵损失作为我们的分类损失来训练具有参数 $\theta$ 的嵌入函数 $f_{\theta}(\cdot) $ 和源域样本上的原型 $\mathbf{p}_{k}(k=1, \ldots, \mathrm{K})$ 和 标记目标样本:
$\begin{aligned}\mathcal{L}_{c l s} & =\mathbb{E}_{(\mathbf{x}, y) \in \mathcal{D}_{s} \cup \mathcal{D}_{t}}[-\log p(y \mid \mathbf{x}, \mathbf{p})] \\& =\mathbb{E}_{(\mathbf{x}, y) \in \mathcal{D}_{s} \cup \mathcal{D}_{t}}\left[-\log \left(\frac{\exp \left(\mathbf{p}_{y} \cdot f_{\theta}(\mathbf{x}) / T\right)}{\sum_{i=1}^{K} \exp \left(\mathbf{p}_{i} \cdot f_{\theta}(\mathbf{x}) / T\right)}\right)\right]\end{aligned}$
虽然原型分类器试图减少标记样本特征的类内变化,但所提出的方案侧重于对齐归一化特征在球形特征空间上的分布。
4.4 Attraction Scheme
目的:通过域内差异最小化将未对齐的目标子分布全局对齐到子分布级别的对齐目标子分布。
因为,有限数量的标记目标样本不足以代表对齐目标子分布的特征分布。 因此,由于观察到对齐的目标子分布的特征以类感知方式与源域的特征高度对齐,本文改为使用标记的源数据和目标数据的复杂分布。
源域数据+带标记目标数据 全局对齐 未带标记的目标数据,对于域内差异的经验估计,采用最大平均差异(MMD)。因此,球形特征空间上估计的域内差异可以写成:
$\begin{aligned}d\left(\mathcal{D}_{s} \cup \mathcal{D}_{t}, \mathcal{D}_{u}\right) & =\mathbb{E}_{(\mathbf{x}, y),\left(\mathbf{x}^{\prime}, y^{\prime}\right) \in \mathcal{D}_{s} \cup \mathcal{D}_{t}}\left[k\left(f_{\theta}(\mathbf{x}), f_{\theta}\left(\mathbf{x}^{\prime}\right)\right)\right] \\& +\mathbb{E}_{(\mathbf{z}, w),\left(\mathbf{z}^{\prime}, w^{\prime}\right) \in \mathcal{D}_{u}}\left[k\left(f_{\theta}(\mathbf{z}), f_{\theta}\left(\mathbf{z}^{\prime}\right)\right)\right] \\& -2 \mathbb{E}_{(\mathbf{x}, y) \in \mathcal{D}_{s} \cup \mathcal{D}_{t},(\mathbf{z}, w) \in \mathcal{D}_{u}}\left[k\left(f_{\theta}(\mathbf{x}), f_{\theta}(\mathbf{z})\right)\right] \end{aligned} \quad\quad\quad(2)$
其中,$\mathbf{x}^{\prime}$、$\mathbf{z}$ 和 $\mathbf{z}^{\prime}$ 代表样本,$y^{\prime}$、$w$ 和 $w^{\prime}$ 代表相应的标签。
该方案最小化了域内差异,因此损失可以写成:
$L_{a}=d\left(\mathcal{D}_{s} \cup \mathcal{D}_{t}, \mathcal{D}_{u}\right)\quad\quad\quad(3)$
4.5 Perturbation scheme
传统的对抗性扰动是半监督学习 (SSL) 方法之一,在 SSDA 问题中被证明是无效的,甚至会导致负迁移。标记的目标样本及其邻域与源域对齐,与不准确的目标样本分开,导致域内差异。 此时,对齐的特征已经通过源域的丰富信息保证了其置信度,而不对齐的特征只能传播不准确的预测。 因此,对 对齐和未对齐的目标子分布的扰动意义不大。
与常见的对抗性扰动方法不同,我们的方案将目标子分布扰动到它们的中间区域,以实现1)从对齐子分布到未对齐子分布的精确预测传播和2)类原型向该区域的调制。这种扰动可以通过搜索目标特征的各向异性高熵的方向来实现,因为元素熵随着特征远离原型而增加,而远离原型的特征会被吸引到原型上。请注意,微扰方案不会破坏已经对齐的子分布,因为它在时间上生成了对齐特征的额外摄动特征以进行正则化。为了实现这一点,我们首先在熵最大化的方向上扰动类原型。然后,我们优化一个小的有界扰动对扰动原型。最后,通过 KullbackLeibler divergence 对扰动数据和给定数据进行正则化。综上所述,扰动损失可表示为:
$\begin{aligned}H_{\mathbf{p}}(\mathbf{x}) & =-\sum_{i=1}^{K} p(y=i \mid \mathbf{x}) \log p(y=i \mid \mathbf{x}, \mathbf{p}) \\r_{\mathbf{x}} & =\underset{\|r\|<\epsilon}{\operatorname{argmin}} \max _{\mathbf{p}} H_{\mathbf{p}}(\mathbf{x}+r) \\\mathcal{L}_{p} & =\mathbb{E}_{\mathbf{x} \in \mathcal{D}_{u}}\left[\sum_{i=1}^{K} D_{K L}\left[p(y=i \mid \mathbf{x}, \mathbf{p}), p\left(y=i \mid \mathbf{x}+\mathbf{r}_{\mathbf{x}}, \mathbf{p}\right)\right]\right] +\mathbb{E}_{(\mathbf{z}, w) \in \mathcal{D}_{t}}\left[\sum_{i=1}^{K} D_{K L}\left[p(y=i \mid \mathbf{z}, \mathbf{p}), p\left(y=i \mid \mathbf{z}+\mathbf{r}_{\mathbf{z}}, \mathbf{p}\right)\right]\right]\end{aligned}$
其中 $H_{\mathbf{p}}(\cdot)$ 是根据给定特征和原型之间的相似性定义的逐元素熵函数,$\mathrm{x}$ 和 $\mathbf{z}$ 代表样本,$y$ 代表相应的标签。
4.6 Exploration scheme
探索方案旨在以与吸引方案互补的类感知方式局部调制原型,同时通过与扰动方案互补的适当标准选择性地对齐未标记的目标特征。 尽管吸引方案在不考虑原型的情况下在特征空间上全局对齐目标子分布,但它并没有明确强制对原型进行调制,这可以通过局部和分类对齐来补充。 另一方面,由于扰动方案对各向异性高熵的扰动特征进行正则化,扰动特征及其邻域的熵逐渐变低。 探索方案对齐这些特征,使它们的熵变得各向同性,因此对齐的特征可以被进一步扰动到未对齐的子分布。 为了实际实现这一点,我们有选择地收集元素熵小于特定阈值的未标记目标数据,然后应用最近原型类的交叉熵损失。 探索方案的目标函数可以写成:
$\begin{aligned}M_{\epsilon} & =\left\{\mathbf{x} \in \mathcal{D}_{u} \mid H_{\mathbf{p}}(\mathbf{x})<\epsilon\right\} \\\hat{y}_{\mathbf{x}} & =\underset{i \in\{1, \ldots, K\}}{\operatorname{argmax}} p(y=i \mid \mathbf{x}, \mathbf{p}) \\\mathcal{L}_{e} & =\mathbb{E}_{\mathcal{D}_{u}}\left[-\mathbf{1}_{M_{\epsilon}}(\mathbf{x}) \log p\left(y=\hat{y}_{\mathbf{x}} \mid \mathbf{x}, \mathbf{p}\right)\right] .\end{aligned}$
其中 $M_{\epsilon}$ 是一组熵值小于超参数 $\epsilon$ 的未标记目标数据,$\mathbf{1}_{M_{\epsilon}}(\cdot)$ 是从给定的未标记目标样本中过滤掉可对齐样本的指示函数。
4.7 整体框架和训练目标
我们方法的整体训练目标是监督损失、吸引力损失、扰动损失和探索损失的加权和。 优化问题可以表述如下:
$\underset{\mathbf{p}, \theta}{\text{min}} \mathcal{L}_{c l s}+\alpha \mathcal{L}_{a}+\beta \mathcal{L}_{e}+\gamma \mathcal{L}_{p} .$
我们将所有方案集成到一个框架中,如图 3 所示。
因上求缘,果上努力~~~~ 作者:VX账号X466550,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17305196.html