
深度学习--LSTM网络、使用方法、实战情感分类问题
深度学习--LSTM网络、使用方法、实战情感分类问题
1.LSTM基础
长短期记忆网络(Long Short-Term Memory,简称LSTM),是RNN的一种,为了解决RNN存在长期依赖问题而设计出来的。
LSTM的基本结构:

2.LSTM的具体说明
LSTM与RNN的结构相比,在参数更新的过程中,增加了三个门,由左到右分别是遗忘门(也称记忆门)、输入门、输出门。
图片来源:

1.点乘操作决定多少信息可以传送过去,当为0时,不传送;当为1时,全部传送。
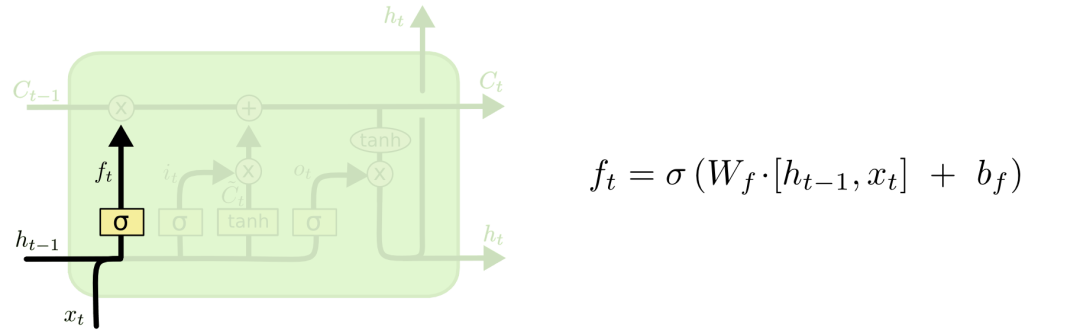
2.1 遗忘门
对于输入xt和ht-1,遗忘门会输出一个值域为[0, 1]的数字,放进Ct?1中。当为0时,全部删除;当为1时,全部保留。
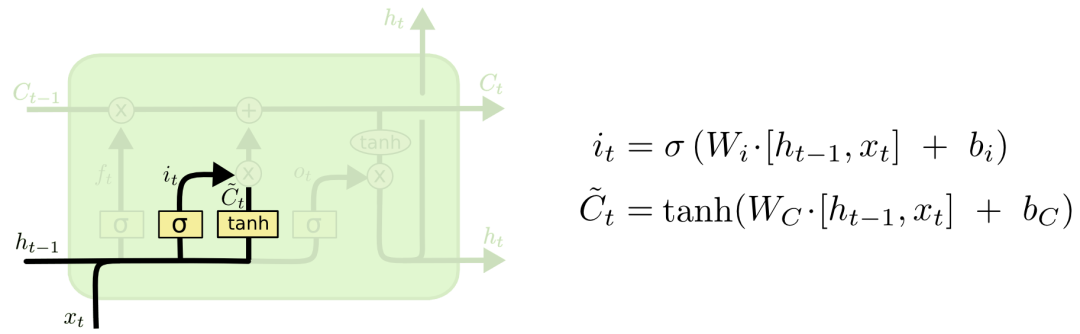
2.2 输入门
对于对于输入xt和ht-1,输入门会选择信息的去留,并且通过tanh激活函数更新临时Ct
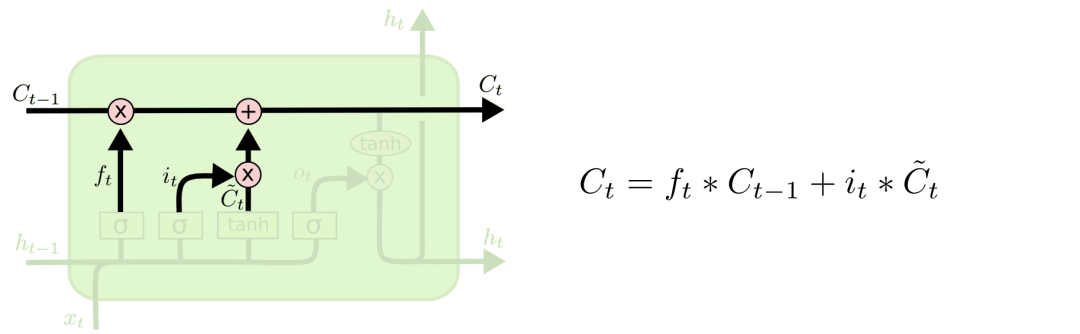
通过遗忘门和输入门输出累加,更新最终的Ct
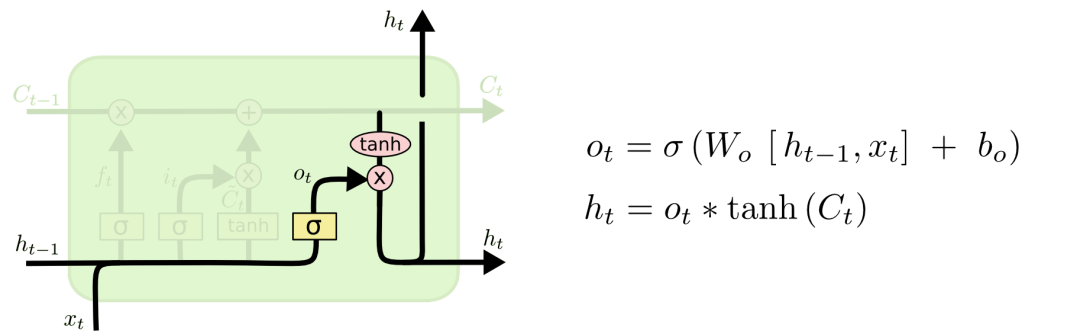
2.3输出门
通过Ct和输出门,更新memory
3.PyTorch的LSTM使用方法
-
__ init __(input _ size, hidden_size,num _layers)
-
LSTM.foward():
? out,[ht,ct] = lstm(x,[ht-1,ct-1])
? x:[一句话单词数,batch几句话,表示的维度]
? h/c:[层数,batch,记忆(参数)的维度]
? out:[一句话单词数,batch,参数的维度]
import torch
import torch.nn as nn
lstm = nn.LSTM(input_size = 100,hidden_size = 20,num_layers = 4)
print(lstm)
#LSTM(100, 20, num_layers=4)
x = torch.randn(10,3,100)
out,(h,c)=lstm(x)
print(out.shape,h.shape,c.shape)
#torch.Size([10, 3, 20]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])
单层使用方法:
cell = nn.LSTMCell(input_size = 100,hidden_size=20)
x = torch.randn(10,3,100)
h = torch.zeros(3,20)
c = torch.zeros(3,20)
for xt in x:
h,c = cell(xt,[h,c])
print(h.shape,c.shape)
#torch.Size([3, 20]) torch.Size([3, 20])
LSTM实战--情感分类问题
Google CoLab环境,需要魔法。
import torch
from torch import nn, optim
from torchtext import data, datasets
print('GPU:', torch.cuda.is_available())
torch.manual_seed(123)
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print('len of train data:', len(train_data))
print('len of test data:', len(test_data))
print(train_data.examples[15].text)
print(train_data.examples[15].label)
# word2vec, glove
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
batchsz = 30
device = torch.device('cuda')
train_iterator, test_iterator = data.BucketIterator.splits(
(train_data, test_data),
batch_size = batchsz,
device=device
)
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
"""
"""
super(RNN, self).__init__()
# [0-10001] => [100]
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# [100] => [256]
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2,
bidirectional=True, dropout=0.5)
# [256*2] => [1]
self.fc = nn.Linear(hidden_dim*2, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
"""
x: [seq_len, b] vs [b, 3, 28, 28]
"""
# [seq, b, 1] => [seq, b, 100]
embedding = self.dropout(self.embedding(x))
# output: [seq, b, hid_dim*2]
# hidden/h: [num_layers*2, b, hid_dim]
# cell/c: [num_layers*2, b, hid_di]
output, (hidden, cell) = self.rnn(embedding)
# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)
# [b, hid_dim*2] => [b, 1]
hidden = self.dropout(hidden)
out = self.fc(hidden)
return out
rnn = RNN(len(TEXT.vocab), 100, 256)
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')
optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)
import numpy as np
def binary_acc(preds, y):
"""
get accuracy
"""
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float()
acc = correct.sum() / len(correct)
return acc
def train(rnn, iterator, optimizer, criteon):
avg_acc = []
rnn.train()
for i, batch in enumerate(iterator):
# [seq, b] => [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
print(i, acc)
avg_acc = np.array(avg_acc).mean()
print('avg acc:', avg_acc)
def eval(rnn, iterator, criteon):
avg_acc = []
rnn.eval()
with torch.no_grad():
for batch in iterator:
# [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:', avg_acc)
for epoch in range(10):
eval(rnn, test_iterator, criteon)
train(rnn, train_iterator, optimizer, criteon)