
案例分享-full gc导致k8s pod重启

在之前的记一次k8s pod频繁重启的优化之旅中分享过对于pod频繁重启的一些案例,最近又遇到一例,继续分享出来希望能给大家带来些许收获。
问题现象
报警群里突然显示某pod频繁重启,我随即上去查看日志,主要分这么几步:
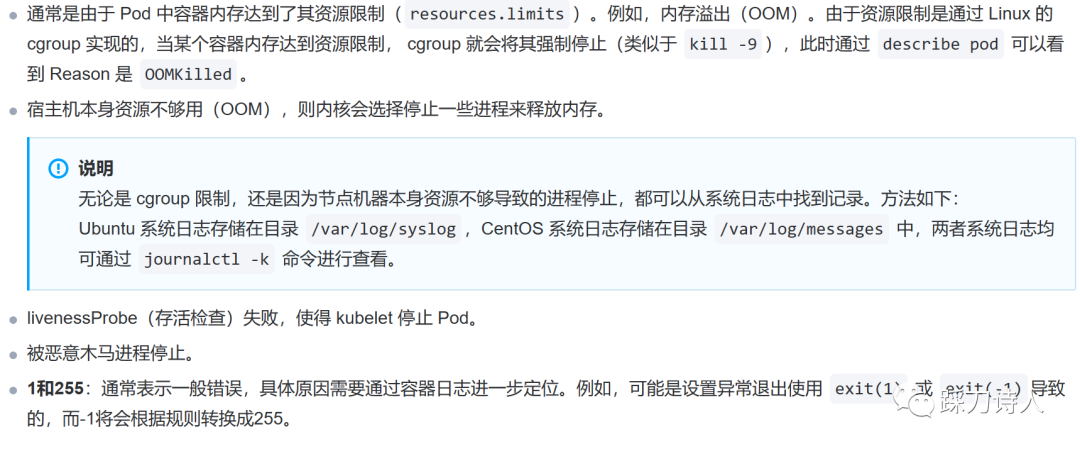
1.查看pod重启的原因,kubectl descirbe pod
Last State: Terminated
Reason: Error
Exit Code: 137
上面的Reason:Error太宽泛了,不能直观的知道原因,Exit code:137一般表示程序被 SIGKILL 中断信号杀死,异常原因可能为:
https://cloud.tencent.com/document/product/457/42945
首先排除OOMKilled情况,剩余的就是livenessProbe(存活检查)失败。
2.查看pod事件,kubectl descirbe pod,重点关注输出的Events部分
Warning Unhealthy 2m56s (x8 over 7m16s) kubelet Liveness probe failed: Get http://10.244.11.136:8080/jc_actuator_1/health: net/http: request canceled (Client.Timeout exceeded while awaiting headers) Normal Killing 2m56s kubelet Container enterprise-service failed liveness probe, will be restarted
熟悉的健康检查失败(超时),是什么导致超时呢,继续找日志。
3.结合之前的排查经验,我认为gc的嫌疑最大,所以查看gc日志
贴一部分日志,可以看到Full GC很繁忙,而且每次结束后内存几乎没有释放,应用已经是处于停摆状态,接下来要做的就是找出Full GC的凶手。
2023-04-22T14:30:58.772+0000: 574.764: [Full GC (Allocation Failure) 2023-04-22T14:30:58.772+0000: 574.764: [Tenured: 2097151K->2097151K(2097152K), 3.6358812 secs] 2569023K->2568977K(2569024K), [Metaspace: 119379K->119379K(1163264K)], 3.6359987 secs] [Times: user=3.64 sys=0.00, real=3.63 secs] 2023-04-22T14:31:02.410+0000: 578.402: [Full GC (Allocation Failure) 2023-04-22T14:31:02.410+0000: 578.402: [Tenured: 2097151K->2097151K(2097152K), 3.5875116 secs] 2569023K->2568980K(2569024K), [Metaspace: 119379K->119379K(1163264K)], 3.5876388 secs] [Times: user=3.59 sys=0.00, real=3.59 secs] 2023-04-22T14:31:05.999+0000: 581.991: [Full GC (Allocation Failure) 2023-04-22T14:31:05.999+0000: 581.991: [Tenured: 2097152K->2097151K(2097152K), 3.5950824 secs] 2569024K->2568987K(2569024K), [Metaspace: 119379K->119379K(1163264K)], 3.5951774 secs] [Times: user=3.59 sys=0.00, real=3.60 secs] 2023-04-22T14:31:09.596+0000: 585.587: [Full GC (Allocation Failure) 2023-04-22T14:31:09.596+0000: 585.587: [Tenured: 2097151K->2097151K(2097152K), 3.5822343 secs] 2569023K->2568849K(2569024K), [Metaspace: 119379K->119379K(1163264K)], 3.5823244 secs] [Times: user=3.58 sys=0.00, real=3.58 secs] 2023-04-22T14:31:13.180+0000: 589.172: [Full GC (Allocation Failure) 2023-04-22T14:31:13.180+0000: 589.172: [Tenured: 2097151K->2097151K(2097152K), 3.6316461 secs] 2569020K->2568910K(2569024K), [Metaspace: 119380K->119380K(1163264K)], 3.6317393 secs] [Times: user=3.63 sys=0.00, real=3.64 secs] 2023-04-22T14:31:16.813+0000: 592.805: [Full GC (Allocation Failure) 2023-04-22T14:31:16.813+0000: 592.805: [Tenured: 2097151K->2097151K(2097152K), 3.6070671 secs] 2569021K->2568907K(2569024K), [Metaspace: 119380K->119380K(1163264K)], 3.6071998 secs] [Times: user=3.60 sys=0.00, real=3.60 secs] 2023-04-22T14:31:20.425+0000: 596.417: [Full GC (Allocation Failure) 2023-04-22T14:31:20.425+0000: 596.417: [Tenured: 2097151K->2097151K(2097152K), 4.7111087 secs] 2569020K->2568899K(2569024K), [Metaspace: 119381K->119381K(1163264K)], 4.7112440 secs] [Times: user=4.71 sys=0.00, real=4.71 secs] 2023-04-22T14:31:25.142+0000: 601.133: [Full GC (Allocation Failure) 2023-04-22T14:31:25.142+0000: 601.133: [Tenured: 2097151K->2097151K(2097152K), 3.8752248 secs] 2569023K->2568899K(2569024K), [Metaspace: 119381K->119381K(1163264K)], 3.8753506 secs] [Times: user=3.88 sys=0.01, real=3.87 secs] 2023-04-22T14:31:29.021+0000: 605.012: [Full GC (Allocation Failure) 2023-04-22T14:31:29.021+0000: 605.012: [Tenured: 2097151K->2097151K(2097152K), 3.5892311 secs] 2569023K->2568910K(2569024K), [Metaspace: 119381K->119381K(1163264K)], 3.5893335 secs] [Times: user=3.59 sys=0.00, real=3.59 secs] 2023-04-22T14:31:32.612+0000: 608.604: [Full GC (Allocation Failure) 2023-04-22T14:31:32.612+0000: 608.604: [Tenured: 2097151K->2097151K(2097152K), 3.5236182 secs] 2569023K->2568915K(2569024K), [Metaspace: 119381K->119381K(1163264K)], 3.5237085 secs] [Times: user=3.52 sys=0.00, real=3.52 secs]
背景知识
我们的服务部署在k8s中,k8s可以对容器执行定期的诊断,要执行诊断,kubelet 调用由容器实现的 Handler (处理程序)。有三种类型的处理程序:
-
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction:对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction:对容器的 IP 地址上指定端口和路径执行 HTTP Get 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
-
Success(成功):容器通过了诊断。
-
Failure(失败):容器未通过诊断。
-
Unknown(未知):诊断失败,因此不会采取任何行动。
针对运行中的容器,kubelet 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
-
livenessProbe:指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来。如果容器不提供存活探针, 则默认状态为 Success。
-
readinessProbe:指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。初始延迟之前的就绪态的状态值默认为 Failure。如果容器不提供就绪态探针,则默认状态为 Success。
-
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器,而容器依其 重启策略进行重启。如果容器没有提供启动探测,则默认状态为 Success。
以上探针介绍内容来源于https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
寻找原因
前面提到是由于Full GC STW导致jvm无法提供服务,那我们就看看是什么导致Full GC,具体的手段就是获取heap dump文件,然后分析,什么时机去获取呢?
这里采用的办法是守株待兔,开两个窗口,一个盯着gc日志,当看到有大量Full GC产生时在另一个窗口生成heap dump文件。
接下来通过Eclipse MAT工具分析dump文件
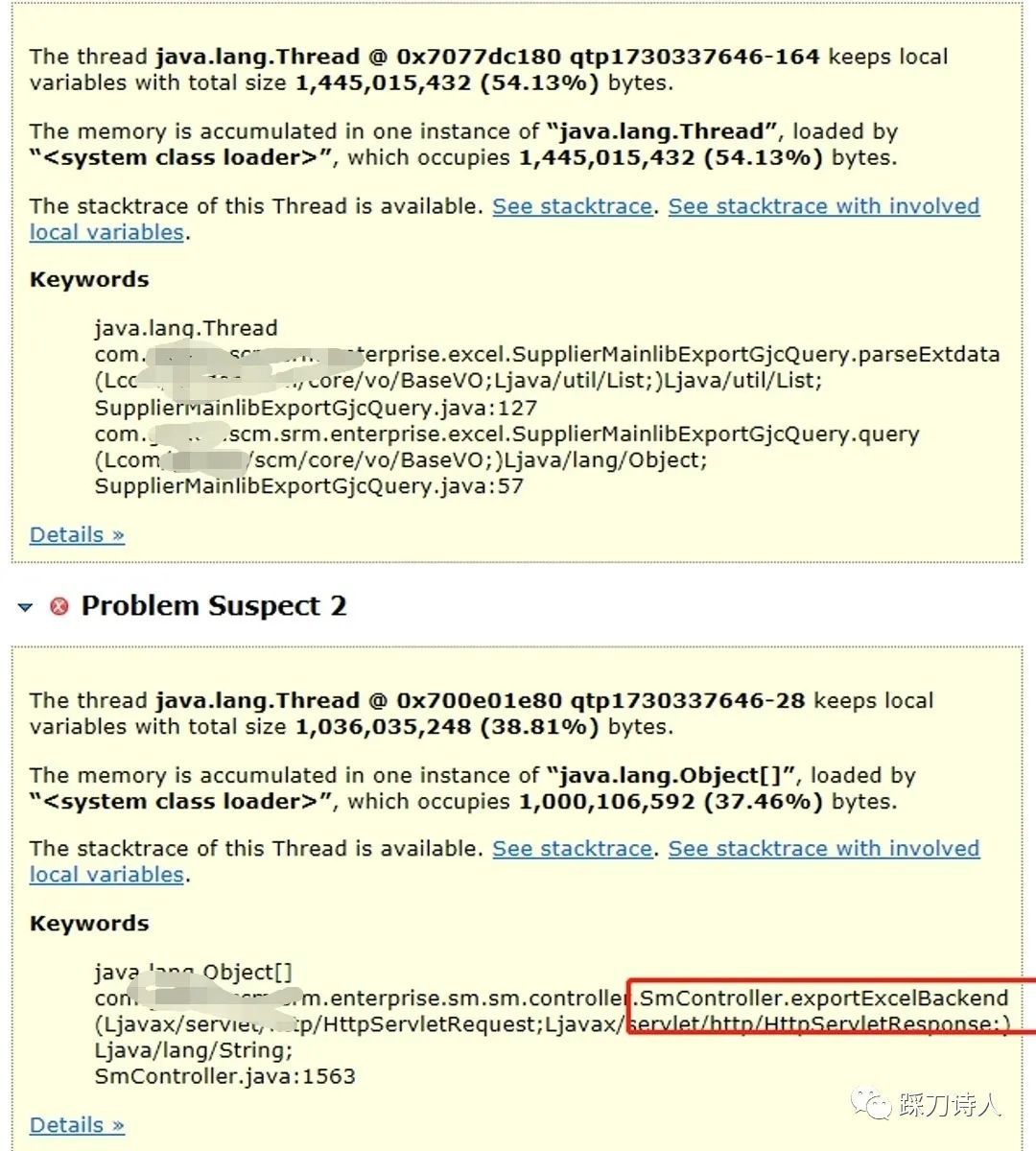
原因一目了然,是导出excel导致,涉及的数据接近10w条,且列比较多。
分析代码
大概看了一下导出的代码,问题集中在以下四点:
1.查询数据没有使用分页;
2.使用的Apache poi工具本身性能不好,内存占用过高;
3.导出没有限流,对于极度消耗资源的操作必须要控制并发,保护系统;
4.同步导出,用户等待时间过长时会选择重试,对系统来讲是雪上加霜。
改进措施
1.查询分页,保证往excel写数据时内存中只会有一页数据;
2.使用性能更好的工具,如easyexcel;
3.异步导出,控制同时导出的并发数;
经过这三步改造以后,导出导致的Full GC问题得以改善,上线一周再没有发现由于大数据量的导出导致的pod重启问题。
推荐阅读
1.容器服务pod异常排查
https://cloud.tencent.com/document/product/457/42945
2.通过Exit Code定位 Pod 异常退出原因
https://cloud.tencent.com/document/product/457/43125
3.pod异常问题排查
https://help.aliyun.com/document_detail/412618.html#6
4. easyexcel
http://easyexcel.opensource.alibaba.com/
