2023-05-08:我们定义了一个函数 countUniqueChars(s) 来统计字符串 s 中的唯一字符, 并返回唯一字符的个数。 例如:s = “LEETCODE“ ,则其中 “L“, “T
2023-05-08:我们定义了一个函数 countUniqueChars(s) 来统计字符串 s 中的唯一字符,
并返回唯一字符的个数。
例如:s = "LEETCODE" ,则其中 "L", "T","C","O","D" 都是唯一字符,
因为它们只出现一次,所以 countUniqueChars(s) = 5 。
本题将会给你一个字符串 s ,我们需要返回 countUniqueChars(t) 的总和,
其中 t 是 s 的子字符串。输入用例保证返回值为 32 位整数。
注意,某些子字符串可能是重复的,但你统计时也必须算上这些重复的子字符串
(也就是说,你必须统计 s 的所有子字符串中的唯一字符)。
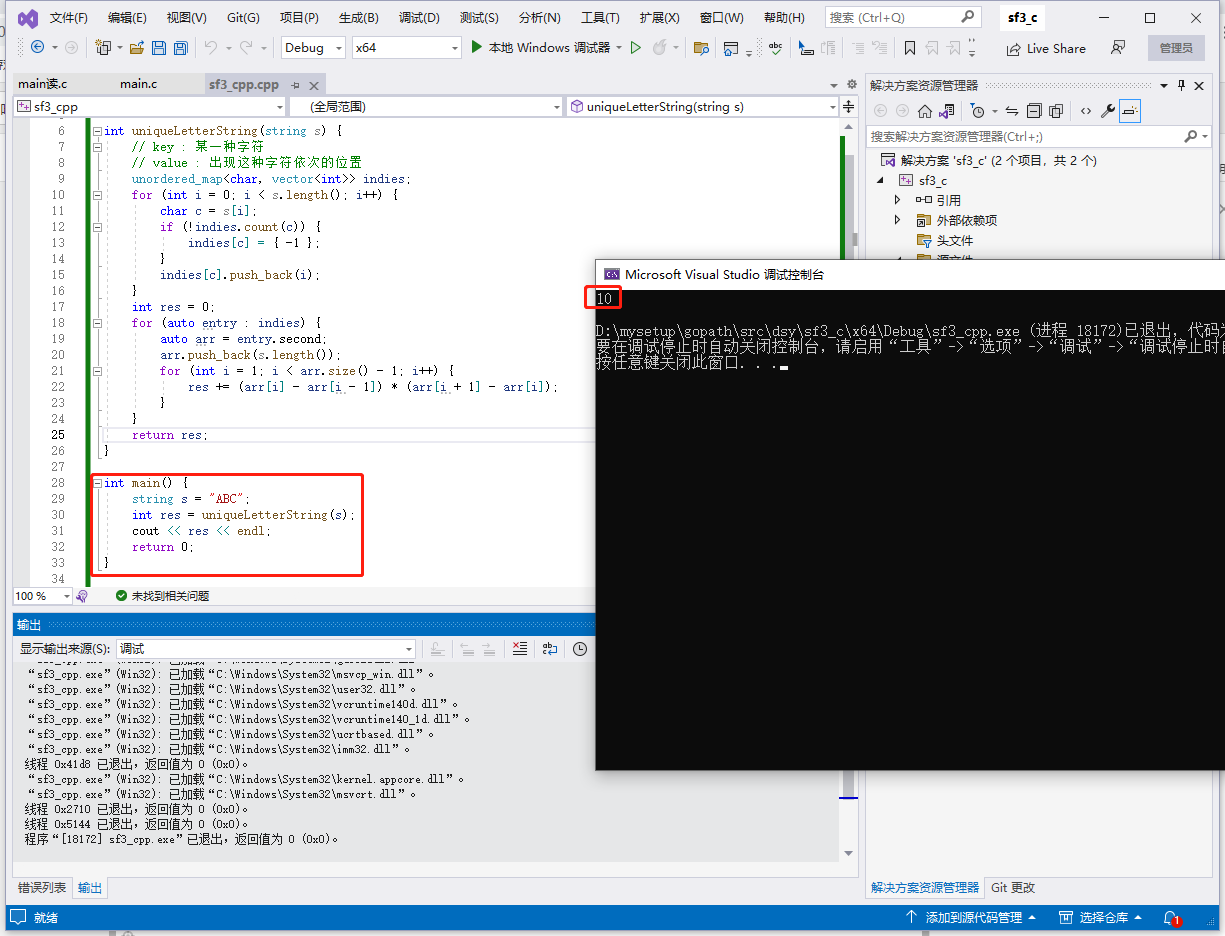
输入: s = "ABC"。
输出: 10。
答案2023-05-08:
1.定义函数 countUniqueChars(s),参数为字符串 s,返回值为整数。
2.创建一个空的哈希表 indies 来记录每个字符出现的位置。
3.遍历字符串 s 中的每个字符,对于每个字符:
3.1.检查该字符是否已经在 indies 中出现过,如果没有则将其加入哈希表,并将初始位置 -1 添加到其位置数组中。
3.2.将当前字符的位置添加到其位置数组中。
4.初始化计数器 res 为 0。
5.遍历哈希表 indies 中的每个键值对,对于每个键值对:
5.1.在该键所对应的位置数组的末尾添加字符串 s 的长度,方便后续计算。
5.2.遍历该键所对应的位置数组中除了开头和结尾的位置,对于每组相邻的位置 i 和 j,计算左侧有多少个连续的该键字符和右侧有多少个连续的该键字符,累加乘积到 res 中。
6.返回计数器 res。
注意:该题目要求统计所有子字符串中的唯一字符的数量,因此需要遍历所有子串。具体实现方法可以枚举所有子串,或者使用一个双重循环来分别枚举子串的起始位置和结束位置,时间复杂度为 O(n^3),其中 n 是字符串 s 的长度。但由于该题目的数据范围较小,因此可以使用暴力枚举来实现。
时间复杂度:
遍历字符串 s 的时间复杂度为 O(n),其中 n 是字符串的长度。
遍历哈希表 indies 中的每个位置数组的时间复杂度为 O(k),其中 k 是该键对应的字符在字符串 s 中出现的次数。
因此,整个程序的时间复杂度为 O(nk)。
额外空间复杂度:
哈希表 indies 和每个键所对应的位置数组的空间复杂度都是 O(k),其中 k 是该键对应的字符在字符串 s 中出现的次数。因此,整个程序的额外空间复杂度为 O(nk)。
go完整代码如下:
package main
import "fmt"
func uniqueLetterString(s string) int {
// key : 某一种字符
// value : 出现这种字符依次的位置
indies := make(map[byte][]int)
for i := 0; i < len(s); i++ {
c := s[i]
if _, ok := indies[c]; !ok {
indies[c] = []int{-1}
}
indies[c] = append(indies[c], i)
}
res := 0
for _, arr := range indies {
arr = append(arr, len(s))
for i := 1; i < len(arr)-1; i++ {
res += (arr[i] - arr[i-1]) * (arr[i+1] - arr[i])
}
}
return res
}
func main() {
s := "ABC"
res := uniqueLetterString(s)
fmt.Println(res)
}
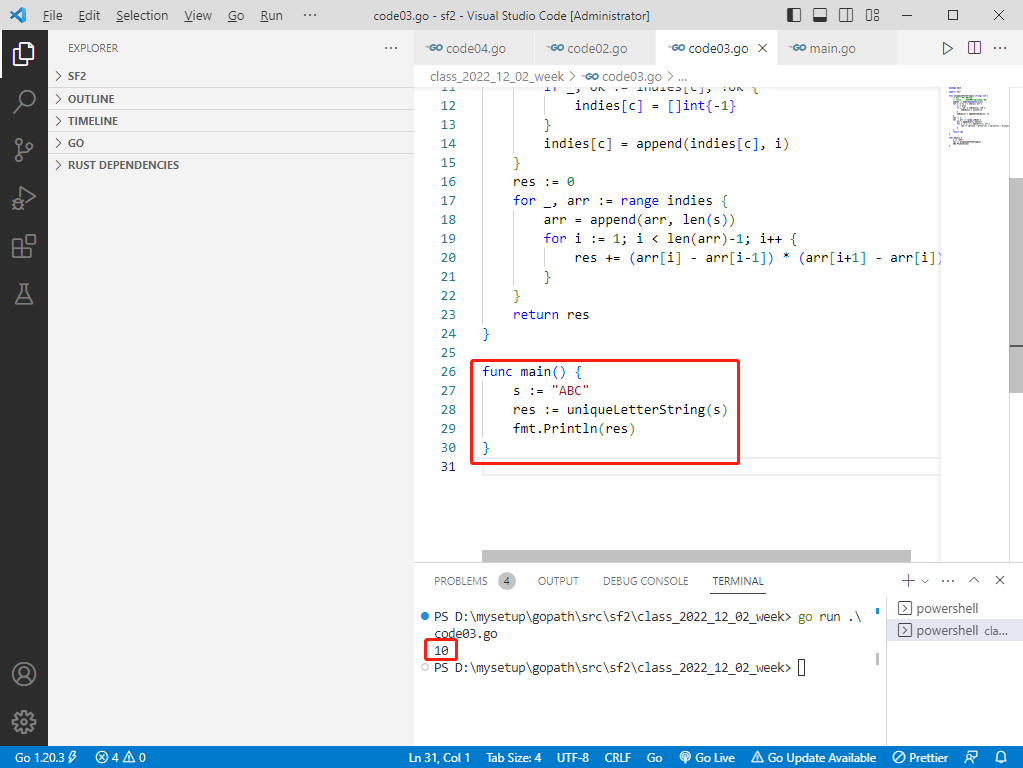
rust完整代码如下:
use std::collections::HashMap;
fn unique_letter_string(s: &str) -> i32 {
// key : 某一种字符
// value : 出现这种字符依次的位置
let mut indies: HashMap<char, Vec<i32>> = HashMap::new();
for (i, c) in s.chars().enumerate() {
indies.entry(c).or_insert_with(Vec::new).push(i as i32);
}
let mut res = 0;
for (_, arr) in indies.iter() {
let mut arr = arr.clone();
arr.insert(0, -1);
arr.push(s.len() as i32);
for i in 1..arr.len() - 1 {
res += (arr[i] - arr[i - 1]) * (arr[i + 1] - arr[i]);
}
}
res as i32
}
fn main() {
let s = "ABC";
let res = unique_letter_string(s);
println!("{}", res);
}
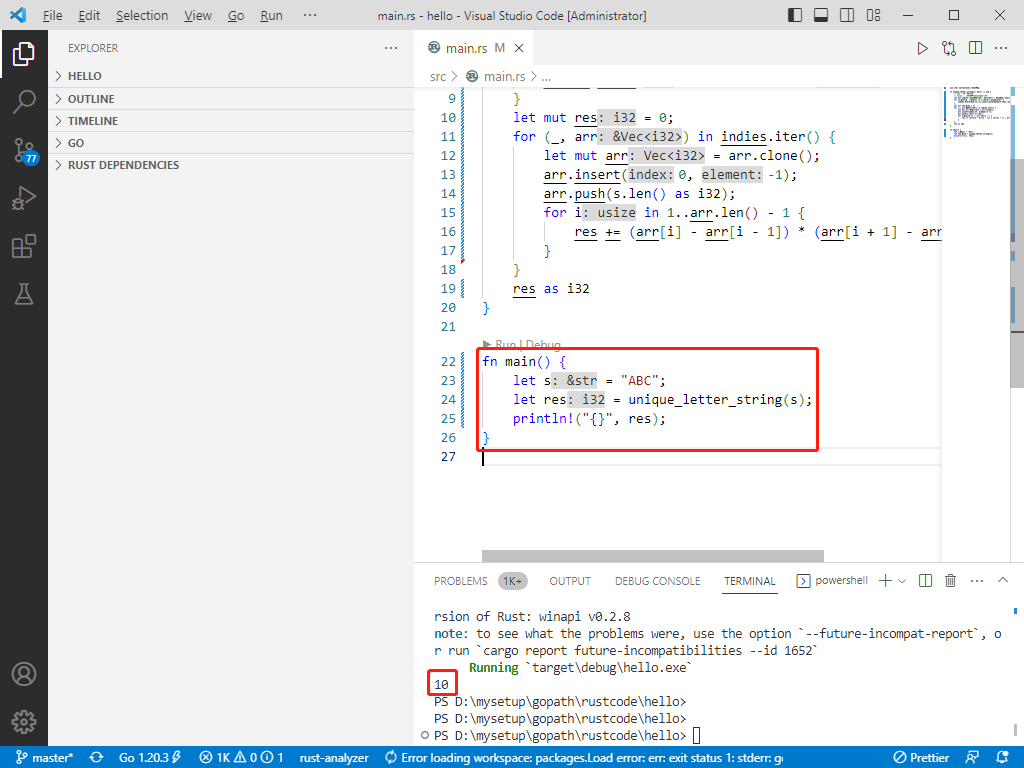
c完整代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_N 1000
struct Vector {
int data[MAX_N];
int size;
};
void vector_init(struct Vector* vec) {
memset(vec->data, -1, sizeof(vec->data));
vec->data[0] = -1;
vec->size = 1;
}
void vector_push_back(struct Vector* vec, int x) {
vec->data[vec->size++] = x;
}
int uniqueLetterString(char* s) {
// key : 某一种字符
// value : 出现这种字符依次的位置
struct Vector indies[256];
int cnt[256] = { 0 };
for (int i = 0; s[i]; i++) {
char c = s[i];
if (cnt[c] == 0) {
vector_init(&indies[c]);
}
vector_push_back(&indies[c], i);
cnt[c]++;
}
int res = 0;
for (int c = 0; c < 256; c++) {
if (cnt[c] == 0) continue;
vector_push_back(&indies[c], strlen(s));
for (int i = 1; i < indies[c].size - 1; i++) {
int left = indies[c].data[i] - indies[c].data[i - 1];
int right = indies[c].data[i + 1] - indies[c].data[i];
res += left * right;
}
}
return res;
}
int main() {
char s[] = "ABC";
int res = uniqueLetterString(s);
printf("%d\n", res);
return 0;
}
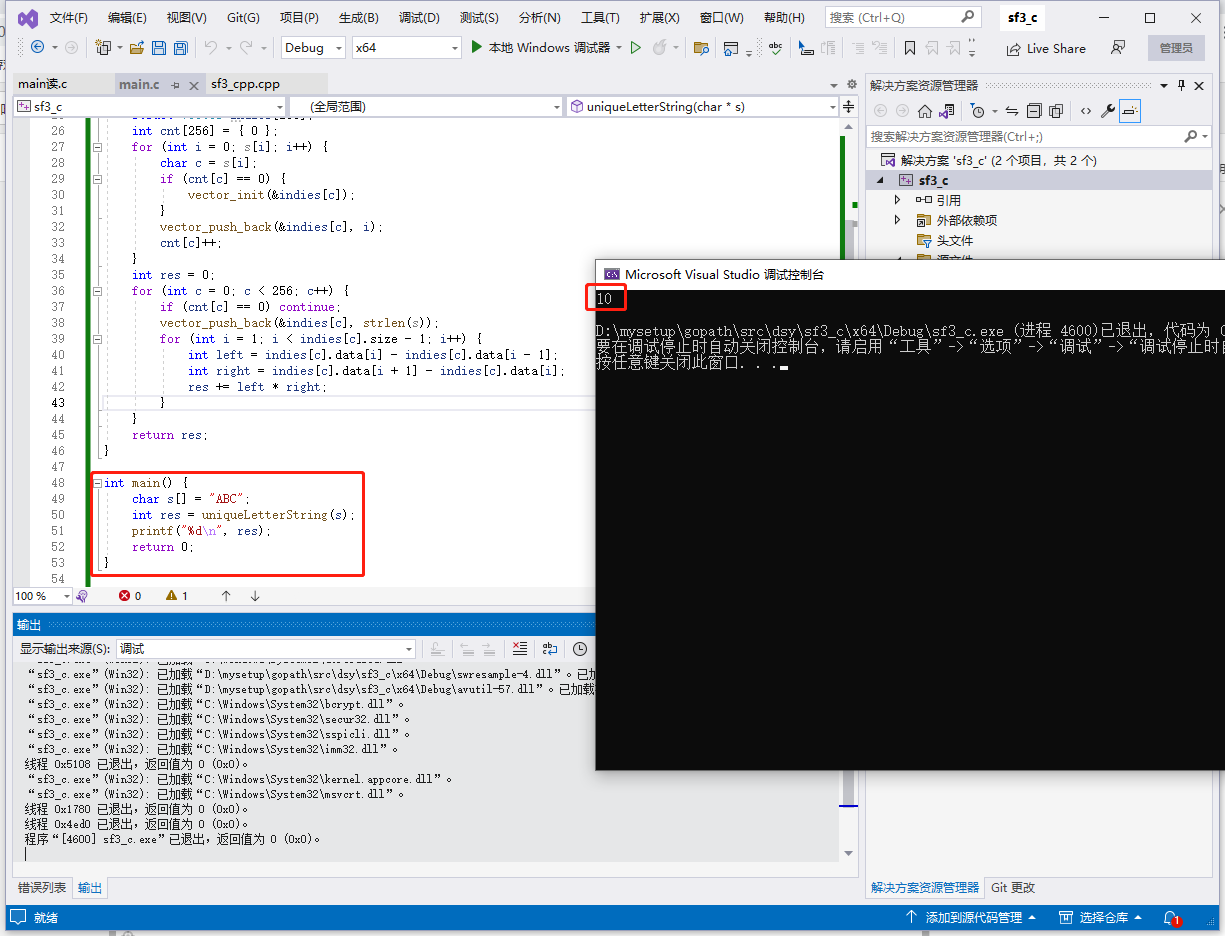
c++完整代码如下:
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
int uniqueLetterString(string s) {
// key : 某一种字符
// value : 出现这种字符依次的位置
unordered_map<char, vector<int>> indies;
for (int i = 0; i < s.length(); i++) {
char c = s[i];
if (!indies.count(c)) {
indies[c] = { -1 };
}
indies[c].push_back(i);
}
int res = 0;
for (auto entry : indies) {
auto arr = entry.second;
arr.push_back(s.length());
for (int i = 1; i < arr.size() - 1; i++) {
res += (arr[i] - arr[i - 1]) * (arr[i + 1] - arr[i]);
}
}
return res;
}
int main() {
string s = "ABC";
int res = uniqueLetterString(s);
cout << res << endl;
return 0;
}