
扯什么kafka顺序消费,然后呢?古尔丹,代价是什么
著名面试八股文之kafka为什么读写效率高,写的答案之一是partition顺序写,因而能保证分区内的不连续的有序性。
这里的重点是有序追加到磁盘,而不是严格意义上的完全有序性。
几年前参加了一大数据岗位面试,95%的时间在扯java基础(这个可以有)和java web相关。剩下大约5%的时间换了人聊了一个kafka问题,算是大数据直接相关的东西吧。
于是有以下对话。
M:kafka能保证顺序消费吗?
我:呃,我觉得不能。
几秒停顿,措词中。。。。。
M:kafka分区内能保证顺序消费啊!
M君带着一丝得意,看看我的简历。
又抬起头,仿佛在说,你改悔罢!

我:是的,但有前提,不能完全保证,得看场景。。。
M:其实我们公司没有大数据开发,大数据相关用的XXX(不记得了,大约是某公司的一个什么大数据一揽子解决方案)
我:???
该公司是做车联相关的产品的(没有自己独立的大数据平台,应该车辆用户不多,数据不大,业务不复杂),
凑巧,我也刚好做过某网红新能源车相关的大数据平台。
这里结合新能源车背景来聊一聊kafka在该背景业务场景下,单分区顺序消费到底靠不靠谱。
我们从数据生产消费两端分别讲一讲。
生产端
1.终端问题
终端故障,网络或未知原因
比如车辆传感器故障等问题导致本身就乱序发送了,徒之奈何?
比如我们在T+1做定时任务计算车辆前一天的充电行程等任务时,就少部份地发现,还有前两天三天的数据,延迟尺度达到了天。
常规性地发现,网络情况达到小时级别的延迟。
之所以是凌晨定时任务跑前一天的数据,就是因为数据延迟时有发生。
如果实时计算,需要数据延迟尽可能的小,在watermark机制(这部份最后会提到)下,超出部份数据将不会被纳入计算。这样行程充电等业务就会被漏算,或者一个完整的过程会被切割等异常情形。
关于数据延迟这一块,某些情形上游甲方厂商可能可以解决,有些情形它也束手无策啊,它控制不了终端操作用户的行为。
这时候作为一线开发者,如果一开始答应了产品/运维为了时效性而使用实时计算,到时候出了问题,你能用各种理由解释不是我们的问题?
当初规划选型的时候考虑到了吗?有备案吗?现在还认可吗?
2.数据倾斜
当时我们的业务主要是基于某车怎么样进行计算。想要对车辆产生的数据进行顺序消费,至少应该将单辆车的数据统一发送到固定的某个partition分区。
对吧?
也就是我们今天讨论的前提是基于一个常识,当我们讨论kafka能否顺序消费,一定是分区内才有讨论的可能,跨分区整个topic是不能够的。
当然,你也可以说我需要基于上百万辆车全部进行顺序消费。那每辆车有一千多个传感信号,只要在操作过程中,每两秒钟相关的信号都会上报一条记录,每天几十上百亿的数据全部统一顺序处理?
这样kafka topic就只能有一个分区,这样的kafka集群吞吐量不敢想象。
要保证某辆车产生的数据固定发到某个分区,一般情况下,是对车辆的VIN码(车辆唯一标识,相当于人的身份证)对分区数求模,得到的就是该车辆应该发送的分区ID。
kafka的发送分区策略:
-
如果未自定义分区策略,且key为空,轮询分区发送,保证各分区数据平衡。
kafkaTemplate.send(topic, info); -
如果未自定义分区策略,指定了key,则使用默认分区策略。key对分区数求模得到发送的分区。
kafkaTemplate.send(topic,key, info);
默认分区策略为org.apache.kafka.clients.producer.internals.DefaultPartitioner

- 如果指定了自定义分区策略,不管指没指定key,以自定义策略为准。
@Component
public class DefinePartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 这里也可以配置分区数或者定时获取分区数
return key.hashCode() % (cluster.partitionsForTopic(topic).size() - 1);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
然后指定分区策略
spring.kafka.producer.properties.partitioner.class = com.nyp.test.service.DefinePartitioner
将vin作为key,或者自定义分区,可以将同一辆车发送的数据指定到同一分区。
但是在实践的过程当中,我们会发现,有的车作为长途或短途的运输车辆,或者作为网约车,那么每天上报的数据会相对较大,
而有的车当天没有出行或其它充电等任何操作,则没有上报数据。
这样就会造成数据倾斜,导致各节点(broker)各分区之间数据严重不平衡。
可能会导致以下情况(2,3主要针对大数据框架)
- GC 频繁
过多的数据集中在某些分区,使得JVM 的内存资源短缺,导致频繁 GC。 - 吞吐下降、延迟增大
数据单点和频繁 GC 导致吞吐下降、延迟增大。 - 系统崩溃
严重情况下,过长的 GC 导致 TaskManager 失联,系统崩溃。
3.扩容分区的代价
kafka的弱点,也是Pulsar的优点。
简单点说,kafka的数据与broker是存放在一起的,如果要加broker,就需要将数据平衡到新的broker。
而Pulsar的架构则是节点与数据分离,消息服务层与存储层完全解耦,从而使各层可以独立扩展,所以扩容的时候会非常方便。当然这不是本文的重点。
总之,
当kafka需要扩容或者对topic增加分区时,由第2点我们得知,数据将发往哪个分区将由key%分区数决定,当分区数量变化后,所有的现有数据在进行扩容或重分区的时候都必须进行key%分区数进行重路由。
这一步的代价必须考虑进去。
4.单分区,A,B消息顺序发送,A失败B成功,A再重试发送,变成BA顺序?
4.1 消息的发送
kafka需要在单分区保证消息按产生时间正序排列,至少应该保证按消息产生的时间正序发送。
假设消息源严格按照时间产生的前提,
-
可以同步发送,一次只发送一条。
同步发送,阻塞直至发送成功,返回SendResult对象,里面包含ProducerRecord和RecordMetadata对象。
SendResult result = kafkaTemplate.send(topic, key, info).get(); -
也可以异步发送,当达到1000条批量提交到集群,或者3秒钟提交一次到集群。
异步发送,返回一个ListenableFuture对象,大家应该对Future不陌生。此对象可以添加回调方法。在成功或失败时执行相应的任务。
ListenableFuture<SendResult<Object, Object>> listenableFuture = kafkaTemplate.send(topic, key, info);
listenableFuture.addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable ex) {
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
}
});
同时,异步发送需要添加相应的配置,比如一次提交多少条数据,比如如果数据迟迟没有达到发送数据量,需要设定一个最大时间,超过这个时间阀值需提交一次,等等。
注意后两个参数的配置。
不同版本之间,参数名称会有差异。
batch.size
每当多个记录被发送到同一个分区时,生产者将尝试将记录批处理到更少的请求中。这有助于提高客户机和服务器上的性能。此配置控制以字节为单位的默认批处理大小。
较小的批大小将使批处理不那么常见,并可能降低吞吐量(批大小为零将完全禁用批处理)。非常大的批处理大小可能会更浪费内存,因为我们总是会分配指定批处理大小的缓冲区,以预期会有额外的记录。
注意几点:
- 此参数控制的发送批次的大小是以字节数,而不是数据条数。
- 此参数控制粒度为分区,而不是topic。当发往某个分区的数据大于等于此大小时将发起一次提交。
- 合理控制此参数。
linger.ms
这个设置给出了批处理延迟的上限:一旦我们获得了一个分区的batch_size值的记录,无论这个设置如何,它都会立即发送,但是如果我们为这个分区积累的字节少于这个数,我们将在指定的时间内“逗留”,等待更多的记录出现。该设置默认为0(即没有延迟)。例如,设置LINGER_MS_CONFIG =5可以减少发送的请求数量,但在没有负载的情况下,发送的记录将增加5ms的延迟。max.block.ms
前两个参数能阻塞(等待)多长时间。buffer.memory
生产者可以用来缓冲等待发送到服务器的记录的内存的总字节数。如果发送记录的速度比发送到服务器的速度快,生产者将阻塞max.block.ms,之后它将抛出异常。
这个设置应该大致对应于生产者将使用的总内存,但不是硬性限制,因为不是生产者使用的所有内存都用于缓冲。一些额外的内存将用于压缩(如果启用了压缩)以及维护正在运行的请求。
4.2 消息的确认(ack)
前面消息已经发送出去了,但要保证不丢消息,不重发消息,即Exactly Once 精次一次性消费,至少需要保证生产端的消息确认机制。
acks参数控制的是消息发出后,kafka集群是否需要响应,以及响应的级别。
-
acks=0
如果设置为0,那么生产者将不会等待服务器的任何确认。该记录将立即添加到套接字缓冲区并被认为已发送。在这种情况下,不能保证服务器已经接收到记录,重试配置将不会生效(因为客户端通常不会知道任何失败)。为每条记录返回的偏移量将始终设置为-1。
为方便记忆,这里的0指是的需要0个节点确认。 -
ack= 1
这将意味着leader将记录写入其本地日志,但将在不等待所有follower完全确认的情况下进行响应。在这种情况下,如果leader在确认记录后立即失败,但在follower复制它之前,那么记录将丢失。
为方便记忆,这里的1指的是只需一个节点确认,这里一个节点肯定指的是主节点leader. -
ack=all或-1
这是最高级别的确认机制,同时也意味着吞吐量受到限制。它将等待leader和所有follower副本都响应,才认为发送完毕。
为方便记忆,这里的all指的是需要所有节点确认。
4.3 幂等性
回到第4小节的主题,当由于网络抖动或者其它任何已知未知原因,消息AB发送顺序由于A失败重试最终变成了BA的倒序,那么kafka分区还能保持最初期望中的AB有序性吗?
答案是可以,只要开启幂等性,在Producer ID(即PID)和Sequence Number的基础上,消息最终将保持AB的顺序。
幂等性对于WEB程序员应该不会陌生,前端调用后端接口,写入订单或者发起支付,由于用户重复操作网络重试等各种异常原因导致多次请求,后端应保证只响应一次请求或/且最终效果一致。
后端各微服务之间调用也有重试,也是同样的道理。
具体到kafka消息发送,跟4.2小节中的Exactly Once实际上有相同的地方,通过设置enable.idempotence=true 开启幂等性,它的基础或前提条件是,会自动设置ack=all。
如何设置kafka生产端的幂等性?
-
enable.idempotence=true
显式开启幂等性。kafka 3.0以上的版本,此值为false,这里应该显式设置。 -
replication.factor
kafka集群的副本数 至少应大于1 -
acks=all
kafka 3.0 以后的版本,此值为1,这里应该显式设置。 -
max.in.flight.requests.per.connection=1
在阻塞之前,客户端将在单个连接上发送的未确认请求的最大数量。请注意,如果将此设置设置为大于1,并且存在失败的发送,则存在由于重试(即,如果启用了重试)而导致消息重新排序的风险。
默认值为5,如果要开启幂等性,此值应<=5。
但如果引值>1 <=5 不会报错,但还是有乱序的风险。 -
retries > 0
重试次数应大于0,如果没有重试,当A失败时不会再成功,也就无从谈起。
注意:当用户设置了enable.idempotence=true,但没有显式设置3,4,5,则系统将选择合适的值。如果设置了不兼容的值,将抛出ConfigException。
同时,为保证完整性,消费端应保证 enable.auto.commit=false,isolation.level=read_committed,即自动确认改为手动确认,事务隔离级别改为读已提交。
4.3 幂等性原理
kafka为解决数据乱序和重发引入了PID和Sequence Number的概念。 每个producer都会有一个producer id即PID。这对用户不可见。
生产端发送的每条消息的每个<Topic, Partition>都对应一个单调递增的Sequence Number。
同样,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每Commit一条消息时将其对应序号递增。
-
对于接收的每条消息,如果其序号比Broker维护的序号大1,则Broker会接受它,否则将其丢弃.
-
如果消息序号比Broker维护的序号差值比1大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息
-
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息
发送失败后会重试,这样可以保证每个消息都被发送到broker。
这里再解释一下为什么能解决乱序,假设broker在接收到 A消息之前的Sequence Number为10,
A在生产端为11,B为12,
由于某种原因,A失败了,此时broker端的Sequence Number仍然为10
此时,B到达broker,它为12,大于10,且它们之间的差异大于1,此时拒绝消息B.B消息发送失败。
然后A重试,成功,Sequence Number变为11,
再然后B重试,此时成功。
最终,AB两条消息以最初的顺序写入成功。
消费端(非大数据模式)
5 单线程和多线程都不能保证跨分区顺序
消息量非常大,topic具有几十几百分区的情况下,消费端只用一个线程去消费,单是想想就知道不太现实,性能拉跨。
先搞搞一个测试demo测试多线程消费
向10个分区随机发送100条数据,数据末尾带上1-100递增的序号.
public void sendDocInfo(String info) {
try {
Random random = new Random();
kafkaTemplate.send("test10", random.nextInt(9)+"", info + "_" + i).get();
} catch (Exception e) {
log.error("kafka发送异常 " + e);
}
}
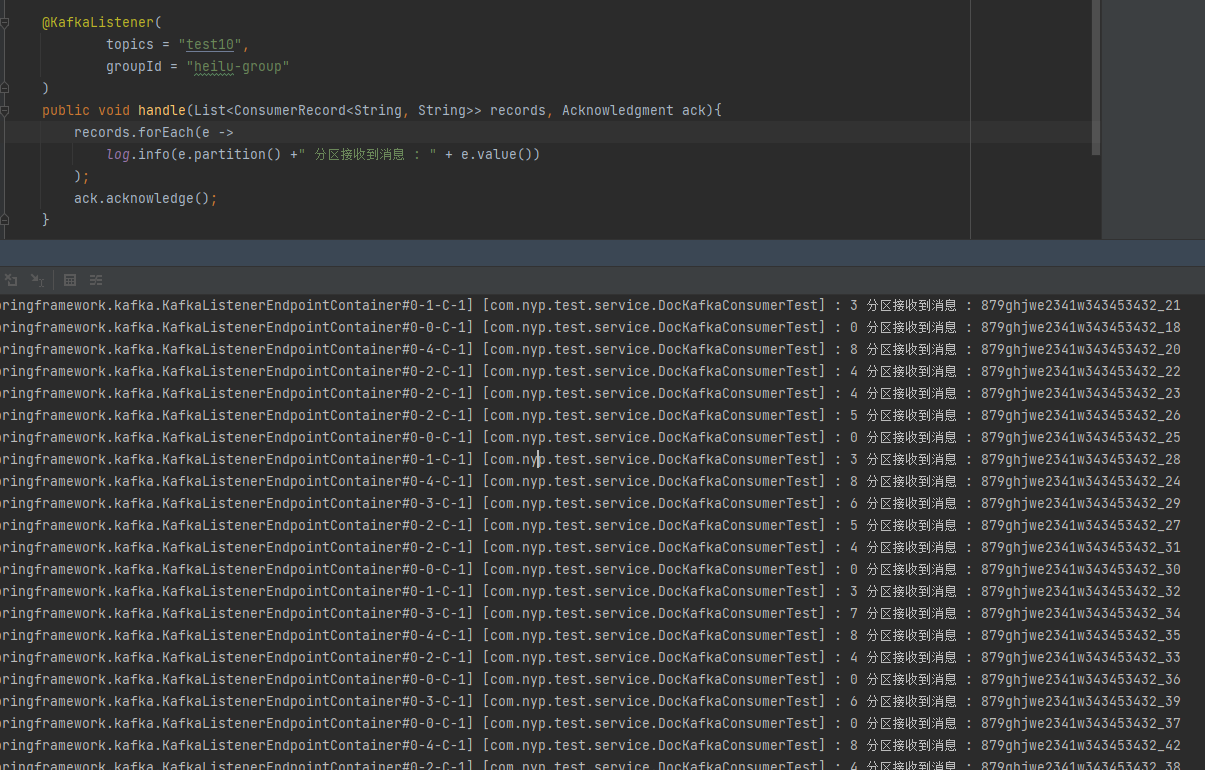
在消费端打印消费,带上分区ID。
@KafkaListener(
topics = "test10",
groupId = "heilu-group"
)
public void handle(List<ConsumerRecord<String, String>> records, Acknowledgment ack){
records.forEach(e -> {
log.info(e.partition() +" 分区接收到消息 : " + e.value());
});
ack.acknowledge();
}
可以很明显的看到跨分区乱序。
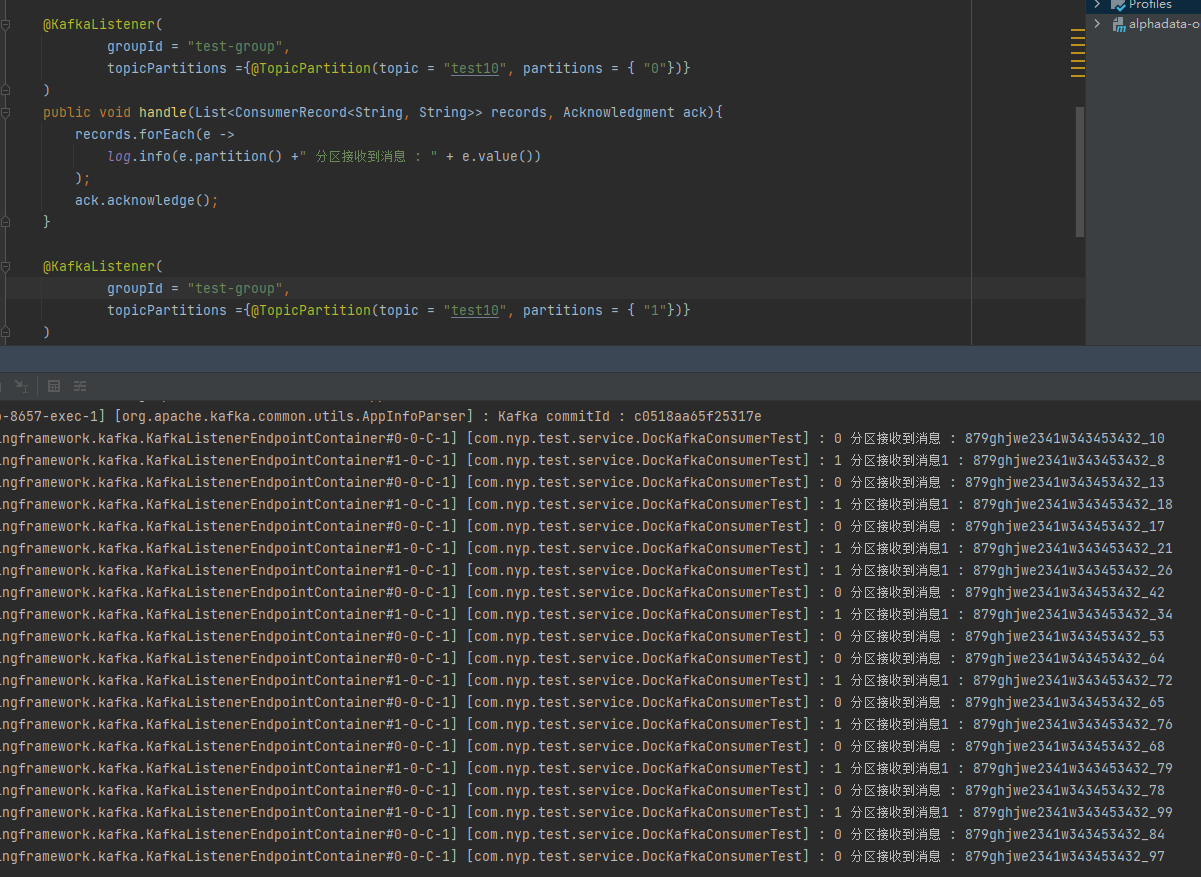
6.线程-分区一一对应
每个线程只消费一个对应的分区
@KafkaListener(
groupId = "test-group",
topicPartitions ={@TopicPartition(topic = "test10", partitions = { "0"})}
)
如图
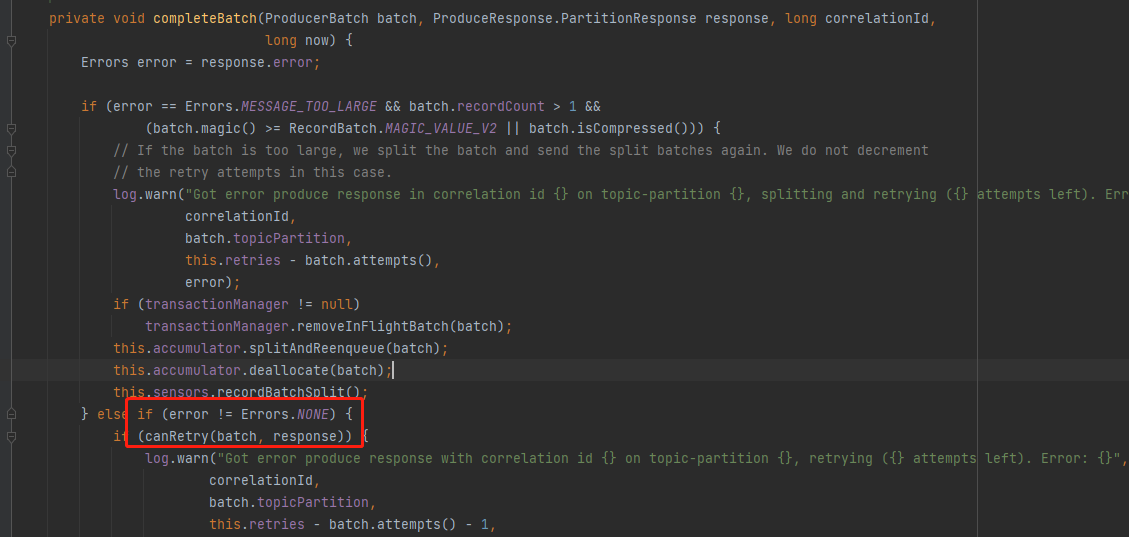
至于Retry的情况,根据源码,需要kafka集群模拟一个异常才能实现,在本地通过拦截器或其它方式都是模拟不出来的。
所以没做这块的演示。
response.error不为NONE的情况下,才做canRetry判断.
7.大数据领域的解决(缓解)方案watermark机制。
在任何生产领域,数据的延迟和乱序是一定会产生的。无非是概率大小,严重程度不同而已。
对于这种情况,大数据框架的共识是,对于数据乱序延迟,我们要等,但不能无限等待下去。
因此flink/spark引入了watermark俗称水印机制。
请注意,此机制是为了缓解数据的延迟和乱序,而不是彻底解决该问题。
就像开篇所说的第1点,车辆跑在路上总会有各种突发状态,传感器会老化,深山老林信号不好,这种情况连终端生产厂商都无法彻底解决,下游数据厂商怎么能根除呢?
watermark一般配合Window一起使用。
如果对window不了解的,可以参考我之前写的这篇文章 关于我因为flink成为spark源码贡献者这件小事
可以简单理解为一个时间段(微批,短至毫秒,长可至时分秒),处理一批数据。
不是搞大数据的,对大数据不感兴趣的,可以跳过这一部份。
- watermark的本质是一个时间戳,它是为了应对数据乱序和延迟的一种机制。
- watermark = max(eventTime) - 允许迟到的长度
- window中,不考虑allowLateness,当watermark等于大于end-of-window时,窗口触发计算和销毁。
比如:
- 有一个窗口`[12:00-12:05)`,watermark允许迟到1分钟, 接收到两条数据时间分别为`12:03:43`,`12:05:23`,
那么watermark = `12:05:23 - 1 minute = 12:04:23` 小于12:05,所以窗口没有结束,不触发计算
注:严格意义来讲,[watermark = `12:05:23 - 1 minute -1ms`] 因为 end-of-window判断的时候是>= - 当接收到一条数据时间为12:06时,窗口触发计算 如果allowLateness>0,窗口延迟销毁,假如来了一条数据时间为12:04:49会再次触发窗口计算 假如来了一条数据时间为12:05:01,不会进行当前窗口,会进入到下一个窗口
- 有一个窗口`[12:00-12:05)`,watermark允许迟到1分钟, 接收到两条数据时间分别为`12:03:43`,`12:05:23`,
那么watermark = `12:05:23 - 1 minute = 12:04:23` 小于12:05,所以窗口没有结束,不触发计算
- 考虑到代码并发度与上游(如kafka,socket)分区数不匹配可能会导致有些分区消费不到数据,如测试socket只有一个分区,而flink代码中有8个并发度,
那么
- 会有7个并发度里消费不到数据,它的watermark为Long.minvalue,
- 而flink的watermark在多并发度下,以最迟的那个为准,所以
-
整个flink任务中的watermark就为Long.minvalue,这时整个任务不会输出任务数据,因为watermark过小,触发不了任务window.
类似于木桶理论,一个木桶能装多少水由最短的那根木桶决定;同样的,flink任务中的watermark由最小的分区的watermark决定。
解决方法:
- 设置两边分区度保持一致
- 高版本里 .withIdleness(Duration.ofSeconds(x)) 在这个时间里,如果有空闲分区没有消费数据,那么它将不持有水印, 即全局水印的推进将不考虑这些空闲分区。
- 如果flink任务收到一个错误数据,远超现在的系统时间,如2100-09-09 00:00:00,在除了空闲分区外的分区都收到这样的数据,那么flink任务的watermark 将超过系统时间,那么正常数据将不会被系统正常处理。这时,在watermark生成器这里要做特殊处理。
- Watermark怎样生成?实时生成和周期性生成(时间或者条数),别忘了第5条。
这部份的源码,感兴趣的可以试一下,引入flink依赖,版本1.14,没有使用kafka,使用
nc -lk 9090可生产数据。我的观点是,每一个后端程序员都应该了解一点大数据计算。
可以看下我这篇文章。public static void main(String[] args) { Configuration configuration = new Configuration(); configuration.setInteger("heartbeat.timeout", 180000); configuration.setInteger(RestOptions.PORT, 8082); StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(configuration); // 并行度和上游数据分区数对watermark生效的影响 // streamExecutionEnvironment.setParallelism(1); // nc -lk 9090 DataStream<TestObject> dataStream = streamExecutionEnvironment .socketTextStream( "192.168.124.123", 9090) .map( e -> { try { Gson gson = new GsonBuilder() .setDateFormat("yyyy-MM-dd HH:mm:ss") .create(); TestObject object = gson.fromJson(e, TestObject.class); return object; } catch (Exception exception) { exception.printStackTrace(); System.out.println("异常数据 = " + e); return new TestObject(); } }); try { OutputTag<TestObject> lateOutput = new OutputTag<>("lateData", TypeInformation.of(TestObject.class)); SingleOutputStreamOperator result = dataStream .filter(e -> StringUtils.isNoneBlank(e.key)) .assignTimestampsAndWatermarks( (WatermarkStrategy<TestObject>) WatermarkStrategy .<TestObject> forBoundedOutOfOrderness(Duration.ofSeconds(10)) .withTimestampAssigner( (row, ts) -> { System.out.println("source = " + row); DateTimeFormatter dtf2 = DateTimeFormatter .ofPattern("yyyy-MM-dd HH:mm:ss", Locale.CHINA); Long time = row.getTime().getTime(); System.out.println("time = " + time); // 如果eventTime > 系统时间,这里要做处理 // TODO 如果eventTime远小于系统时间,可能会拖慢整体的Watermark Long now = System.currentTimeMillis(); return time > now ? now : time; } ) .withIdleness(Duration.ofSeconds(5)) ) .keyBy(e -> e.key) .window( SlidingEventTimeWindows.of( Time.seconds(60 * 2), Time.seconds(60))) // 将延迟的数据旁路输出 .sideOutputLateData(lateOutput) .process( new ProcessWindowFunction<TestObject, Object, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<TestObject> elements, Collector<Object> out) throws Exception { System.out.println("watermark = " + context.currentWatermark()); System.out.println("watermark = " + new Timestamp(context.currentWatermark()) +" window.start = " + new Timestamp(context.window().getStart()) +" window.end = " + new Timestamp(context.window().getEnd())); elements.forEach(e -> System.out.println("e + " + e)); } }); result.print(); // 迟到不处理的数据 result.getSideOutput(lateOutput).print(); streamExecutionEnvironment.execute("WaterMark test"); } catch (Exception exception) { exception.printStackTrace(); } } @Data @NoArgsConstructor public static class TestObject { private String key; private Timestamp time; private float price; }
8. 小结
kafka为了吞吐量,在生产端设计了顺序追加模式,这两者才是因果。
得益于此,kafka单分区内的数据可以变得有序,这只是一个副产品。它同时得考虑到数据终端带来的先天不足,
分区节点间的数据倾斜带来的性能问题,
分区节点扩容的代价,
幂等性所需要代价带来的吞吐量限制,
以及消费端的限制。种种问题考量。
幂等性更多的是做一次精准消费,防止重复消费,有序只是副产品。
有且只有一次精准消费,可比什么劳什子有序消费重要得多!就像摩托车是一个交通工具,能跑在廉价的道路(普通服务器)上,将便利(曾经高大上的大数据)带到千家万户(普通小公司)。
但它不是装X工具。给我个人的感觉,如果真要把kafka的分区有序性强行用到生产环境,就像下图这样。

告辞。
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/dev/datastream/operators/windows/#allowed-lateness
https://juejin.cn/post/7200672322113077303
https://juejin.cn/post/7226612646543818807