
Golang每日一库之regex
本文地址: https://www.cnblogs.com/zichliang/p/17387436.html
Golang日库合集:https://www.cnblogs.com/zichliang/category/2297320.html
简介
正则表达式是一种用来查询、匹配或替换字符串的技术。你可以使用它来找到符合特定模式的文本、删除或替换匹配的字符串。它可以用于各种编程语言和工具中,如Perl、Python、JavaScript、Java等等。
一句话概括就是,“正则表达式可以帮你快速、简便地处理需要查找、匹配或替换的文本内容,它可以大大提高程序的效率。”
正则介绍
正则表达式通常可以分为以下几个步骤:
- 定义正则表达式模式:即给出需要匹配或查找的文本规则,如匹配所有以"A"开头的单词,模式可以是 "^A\w+"。
- 编译正则表达式:将正则表达式模式编译成程序可识别的格式。
- 指定匹配文本:输入需要进行匹配操作的文本,如一段英语文章。
- 进行匹配操作:程序会根据输入的正则表达式和匹配文本进行匹配操作,搜索所有与正则表达式模式匹配的子串。
- 获取匹配结果:输出匹配到的所有子串,包括位置、长度,或将它们替换成所需要的格式。
元字符
上文说的第一步与第二步匹配特定字符或字符类型的字符在正则表达式中具有特殊含义。一般来说,它们都是特殊符号或字母,用于匹配某个字符类或执行某种操作。
这里就不列举了
推荐个网站: 里面包含了基本上所有的元字符: https://www.runoob.com/regexp/regexp-metachar.html
Golang中的正则
其实非常简单主要分为三步
- 正则( 针对字符串匹配规则)
- 元字符(基本上大同小异)
- 方法(特定语言有特定方法)
Golang 中常用的元字符:
- .:匹配任意单个字符,除了换行符和回车符。
- ^:匹配输入字符串的开始位置。
- $:匹配输入字符串的结束位置。
- *:匹配前面的字符(包括字符类)零次或多次。
- +:匹配前面的字符(包括字符类)一次或多次。
- ?:匹配前面的字符(包括字符类)零次或一次。
- |:分隔两个可选模式,匹配任意一个模式。
- []:匹配其中的任意一个字符。可以使用短横线表示范围,如 [a-z] 表示匹配任意小写字母。
- \d:匹配任意一个数字字符,相当于 [0-9]。
- \w:匹配任意一个字母、数字或下划线,相当于 [a-zA-Z0-9_]。
- \s:匹配任意一个空白字符,包括空格、制表符、换行符等。
Golang中的函数和方法介绍
在 Golang 中,标准库 regexp 提供了一系列正则操作函数,下面是这些函数的简要介绍:
Compile(expr string) (*Regexp, error):将一个字符串编译成一个正则表达式对象Regexp。如果编译失败,会返回一个非nil的错误对象。CompilePOSIX(expr string) (*Regexp, error):类似于Compile函数,但是将正则表达式解释为 POSIX 语法。MustCompile(expr string) *Regexp:类似于Compile函数,但是在编译失败时会直接抛出一个 panic。MustCompilePOSIX(expr string) *Regexp:类似于MustCompile函数,但是将正则表达式解释为 POSIX 语法。Match(pattern string, b []byte) (bool, error):判断一个字节数组中是否包含指定的正则表达式。MatchString(pattern string, s string) (bool, error):判断一个字符串中是否包含指定的正则表达式。MatchReader(pattern string, r io.RuneReader) (bool, error):类似于Match函数,但是适用于io.RuneReader类型。MatchRegexp(r *Regexp, s string) bool:对一个字符串执行已编译的正则表达式对象Regexp进行匹配。MatchReaderRegexp(r *Regexp, r io.RuneReader) bool:类似于MatchRegexp函数,但是适用于io.RuneReader类型。QuoteMeta(s string) string:将一个字符串中的元字符以外的所有字符都转义,使它们成为字面量。
除此之外,Regexp 对象还提供了一系列操作方法,例如:
Find(b []byte) []byte:返回第一个匹配的子字符串。FindAll(b []byte, n int) [][]byte:返回所有匹配的子字符串,n 表示最大匹配次数。FindAllIndex(b []byte, n int) [][]int:返回所有匹配的子字符串的起止索引,n 表示最大匹配次数。FindIndex(b []byte) (loc []int):返回第一个匹配的子字符串的起止索引。FindString(s string) string:返回第一个匹配的子字符串。FindAllString(s string, n int) []string:返回所有匹配的子字符串,n 表示最大匹配次数。FindAllStringIndex(s string, n int) [][]int:返回所有匹配的子字符串的起止索引,n 表示最大匹配次数。FindStringIndex(s string) (loc []int):返回第一个匹配的子字符串的起止索引。FindAllSubmatch(b []byte, n int) [][][]byte返回的是字节切片的切片的切片FindAllSubmatchIndex(b []byte, n int) [][]int返回所有匹配子串的开始和结束的字符索引位置。FindAllStringSubmatch(s string, n int) [][]string返回的是字符串切片的切片的切片。FindAllStringSubmatchIndex(s string, n int) [][]int返回各个子串的开始和结束的索引值,ReplaceAll(src []byte, repl []byte) []byte:将 src 中的所有匹配项替换为 repl,返回替换后的结果。ReplaceAllString(src, repl string) string:类似于ReplaceAll函数,但是输入输出都是字符串类型。Split(s string, n int) []string:将 s 按照正则表达式分割,n 表示最大分割次数。SplitN(s string, n int) []string:类似于Split函数,但是只分割前 n 个子字符串。
这些函数和方法可以满足我们对正则表达式进行各种查询、替换、分割等常见操作的需求。
Compile 和 MustCompile
在 Golang 中,我们可以使用 Compile 函数和 MustCompile 函数来将正则表达式字符串编译为一个 Regexp 对象。
这两个函数的作用是相同的,都是将正则表达式字符串编译成一个正则表达式对象,只不过 MustCompile 函数在编译失败时会直接抛出一个 panic。
Compile
// Compile 函数的使用方式
re, err := regexp.Compile(`\d+`)
if err != nil {
// 正则表达式编译失败
return
}
// 使用编译后的正则表达式对象
fmt.Println(re.MatchString("123"))
结果
true
MustCompile
// MustCompile 函数的使用方式
re = regexp.MustCompile(`\d+`)
fmt.Println(re.MatchString("456"))
结果
true
FindAllSubmatch和FindAllStringSubmatch
FindAllSubmatch 方法是 Golang 中 Regexp 对象提供的一个方法。
用于在指定字符串中查找所有符合正则表达式规则的子字符串,并返回子字符串所对应的分组信息及匹配位置。
其函数签名如下:
func (re *Regexp) FindAllSubmatch(b []byte, n int) [][][]byte
func (re *Regexp) FindAllSubmatchIndex(b []byte, n int) [][]int
func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string
func (re *Regexp) FindAllStringSubmatchIndex(s string, n int) [][]int
FindAllSubmatch 和 FindAllStringSubmatch 方法都用于在字符串中查找所有匹配正则表达式的子字符串,它们返回的是一个包含所有匹配子串和索引位置的二维切片。
FindAllStringSubmatchIndex 方法返回一个二维的整数切片,每个子切片表示一次匹配,每个子切片中的两个整数分别表示匹配子串在源字符串中的开始和结束位置的索引。
FindAllSubmatchIndex 方法也返回一个二维的整数切片,不同的是,每个子切片中都包含一系列整数,每两个整数表示匹配的一组子表达式在源字符串中的开始和结束位置的索引。
其实说的还是有些笼统
例子
package main
import (
"fmt"
"regexp"
"strings"
)
func main() {
content := `111 aba 1024 bbb 2048 ccc aba aba`
pattern := `aba`
compile, _ := regexp.Compile(pattern)
results := compile.FindAllSubmatch([]byte(content), -1)
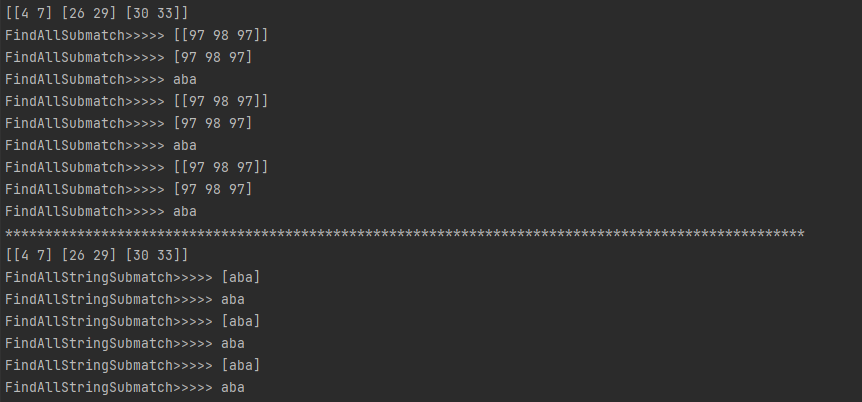
fmt.Println(compile.FindAllSubmatchIndex([]byte(content), -1))
for _, result := range results {
fmt.Println("FindAllSubmatch>>>>>", result)
fmt.Println("FindAllSubmatch>>>>>", result[0])
fmt.Println("FindAllSubmatch>>>>>", string(result[0]))
}
fmt.Println(strings.Repeat("*", 100))
results1 := compile.FindAllStringSubmatch(content, -1)
fmt.Println(compile.FindAllStringSubmatchIndex(content, -1))
for _, result := range results1 {
fmt.Println("FindAllStringSubmatch>>>>>", result)
fmt.Println("FindAllStringSubmatch>>>>>", result[0])
}
}
结果如下:
例子2:
如果我们需要正则提取网站该如何实现呢?
package main
import (
"fmt"
"regexp"
"strings"
)
func main() {
content := `<a href="https://www.jd.com" target="_blank">京东</a> <a href="https://www.taobao.com" target="_blank">淘宝</a>`
pattern := `<a href="(.*?)" target="_blank">(.*?)</a>`
compile, _ := regexp.Compile(pattern)
results := compile.FindAllSubmatch([]byte(content), -1)
/*
[][][]byte
[]byte=""
// 一旦加了括号等于分了组 后面会向这个切片追加值,所以下文只要切片取第二个值就行了 多分组就以此类推
[
[<a href="https://www.jd.com" target="_blank">京东</a>,https://www.jd.com,京东]
[<a href="https://www.taobao.com" target="_blank">淘宝</a>,https://www.taobao.com,淘宝]
]
*/
for _, result := range results {
fmt.Println(strings.Repeat("*", 100))
fmt.Println(string(result[0]), string(result[1]), string(result[2]))
}
}
结果

本文地址: https://www.cnblogs.com/zichliang/p/17387436.html
Golang日库合集:https://www.cnblogs.com/zichliang/category/2297320.html