
飞桨Paddle动转静@to_static技术设计
一、整体概要
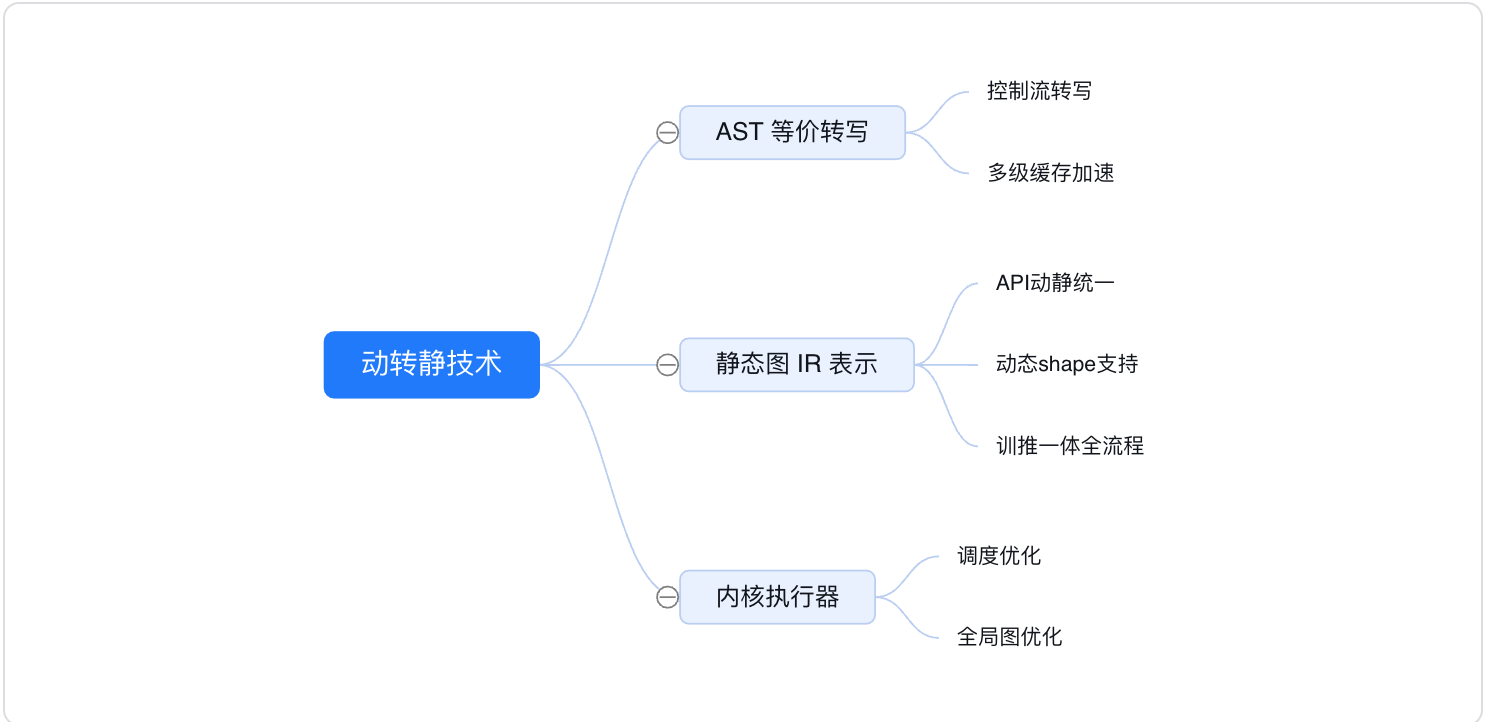
在深度学习模型构建上,飞桨框架支持动态图编程和静态图编程两种方式,其代码编写和执行方式均存在差异:
- 动态图编程: 采用 Python 的编程风格,解析式地执行每一行网络代码,并同时返回计算结果。
- 静态图编程: 采用先编译后执行的方式。需先在代码中预定义完整的神经网络结构,飞桨框架会将神经网络描述为 Program 的数据结构,并对 Program 进行编译优化,再调用执行器获得计算结果。
动态图编程体验更佳、更易调试,但是因为采用 Python 实时执行的方式,开销较大,在性能方面与 C++ 有一定差距;静态图调试难度大,但是将前端 Python 编写的神经网络预定义为 Program 描述,转到 C++ 端重新解析执行,脱离了 Python 依赖,往往执行性能更佳,并且预先拥有完整网络结构也更利于全局优化。
从2.0 版本开始,Paddle默认开启了动态图执行模式,Paddle提供了动转静(@to_static)模块功能支持用户实现动态图编程,一键切换静态图训练和部署的编程体验。
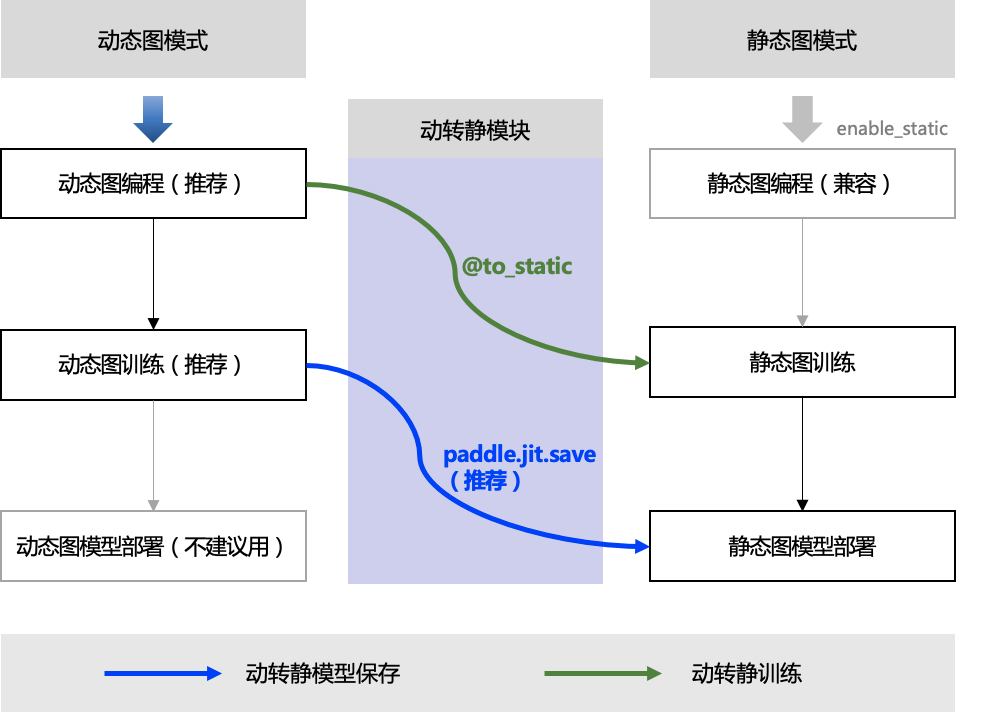
二、转换原理
在飞桨框架内部,动转静模块在转换上主要包括对输入数据 InputSpec 的处理,对函数调用的递归转写,对 IfElse、For、While 控制语句的转写,以及 Layer 的 Parameters 和 Buffers 变量的转换。如下是动转静模块的转换技术大致流程:
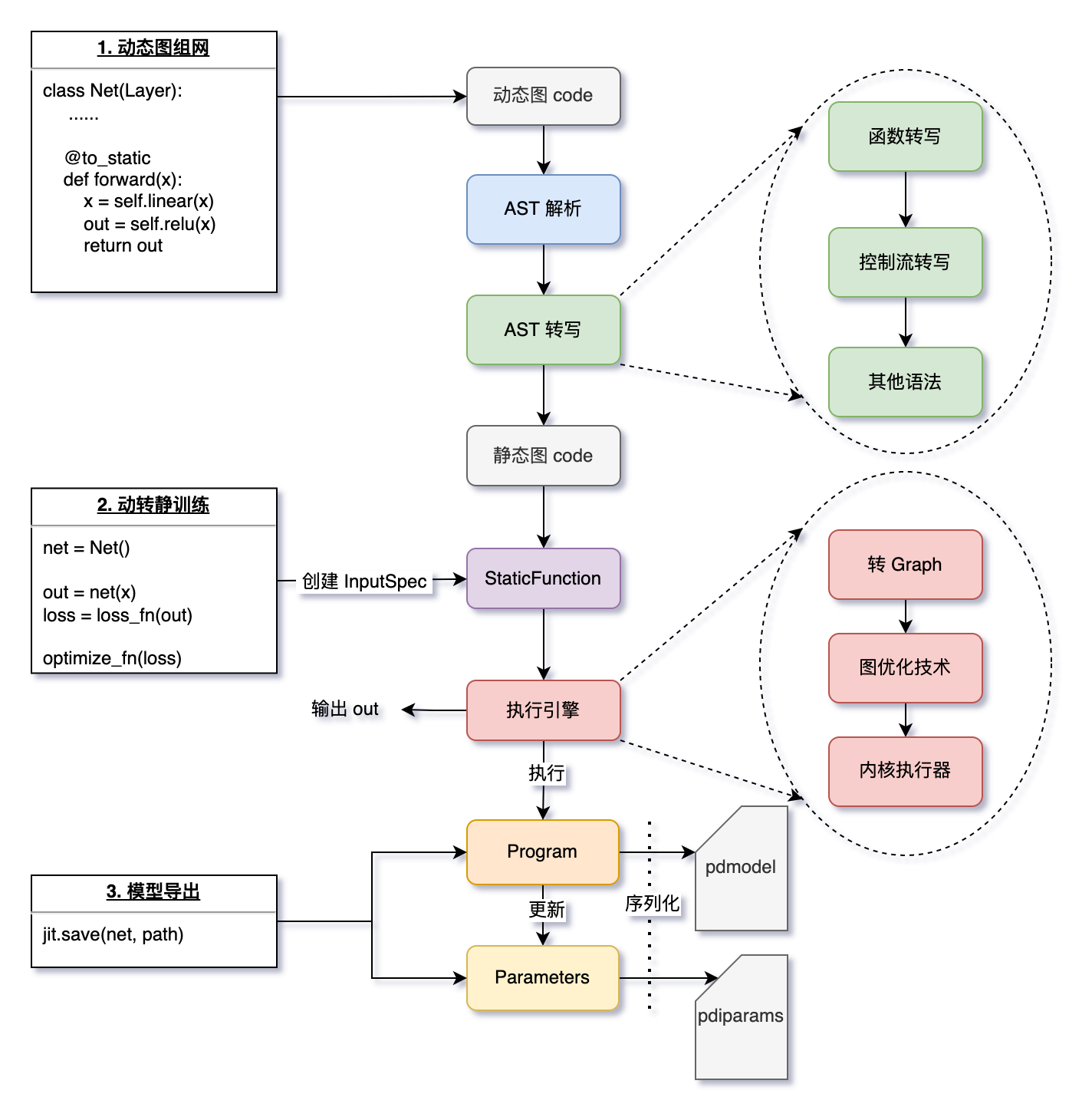
2.1 AST 解析动态图代码
当某个函数被 @to_static 装饰、或用 paddle.jit.to_static() 包裹时,飞桨会隐式地解析动态图的 Python 代码(即解析:抽象语法树,简称 AST)。
2.2 AST 转写,得到静态图代码
- 函数转写:递归地对所有函数进行转写,实现用户仅需在最外层函数添加 @to_static 的体验效果。
- 控制流转写:用户的代码中可能包含依赖 Tensor 的控制流代码,飞桨框架会自动且有选择性地将 if、for、while 转换为静态图对应的控制流。
- 其他语法处理:包括 break、continue、assert、提前 return 等语法的处理。
2.3 生成静态图的 Program 和 Parameters
- 得到静态图代码后,根据用户指定的 InputSpec 信息(或训练时根据实际输入 Tensor 隐式创建的 InputSpec)作为输入,执行静态图代码生成 Program。每个被装饰的函数,都会被替换为一个 StaticFunction 对象,其持有此函数对应的计算图 Program,在执行 paddle.jit.save 时会被用到。
- 对于 trainable=True 的 Buffers 变量,动转静会自动识别并将其和 Parameters 一起保存到 .pdiparams 文件中。
2.4 执行动转静训练
- 使用执行引擎执行函数对应的 Program,返回输出 out。
- 执行时会根据用户指定的 build_strategy 策略应用图优化技术,提升执行效率。
2.5使用 paddle.jit.save 保存静态图模型
- 使用 paddle.jit.save 时会遍历模型 net 中所有的函数,将每个的 StaticFunction 中的计算图 Program 和涉及到的 Parameters 序列化为磁盘文件。
三、转静组网流程
3.1 样例解读
import numpy as np
import paddle
import paddle.nn as nn
class LinearNet(paddle.nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(10, 3)
@paddle.jit.to_static
def forward(self, x):
y = self._linear(x)
return y
# create network
layer = LinearNet()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
for batch_id, x in enumerate(data_loader()):
out = layer(image)
loss = paddle.mean(out)
loss.backward()
opt.step()
opt.clear_grad()
文档开始的样例中 forward 函数包含一行组网代码: Linear 。以 Linear 为例,在 Paddle 的框架底层,每个 Paddle 的组网 API 的实现包括两个分支:
class Linear(...):
def __init__(self, ...):
# ...(略)
def forward(self, input):
if in_dygraph_mode(): # 动态图分支
core.ops.matmul(input, self.weight, pre_bias, ...)
return out
else: # 静态图分支
self._helper.append_op(type="matmul", inputs=inputs, ...) # <----- 生成一个 Op
if self.bias is not None:
self._helper.append_op(type='elementwise_add', ...) # <----- 生成一个 Op
return out
动态图 layer 生成 Program ,其实是开启 paddle.enable_static() 时,在静态图下逐行执行用户定义的组网代码,依次添加(对应append_op 接口) 到默认的主 Program(即 main_program ) 中。当调用 loss.backward() 函数时,飞桨框架会根据loss的计算路径,进行反向自动链式求导生成对应的反向静态图子图。
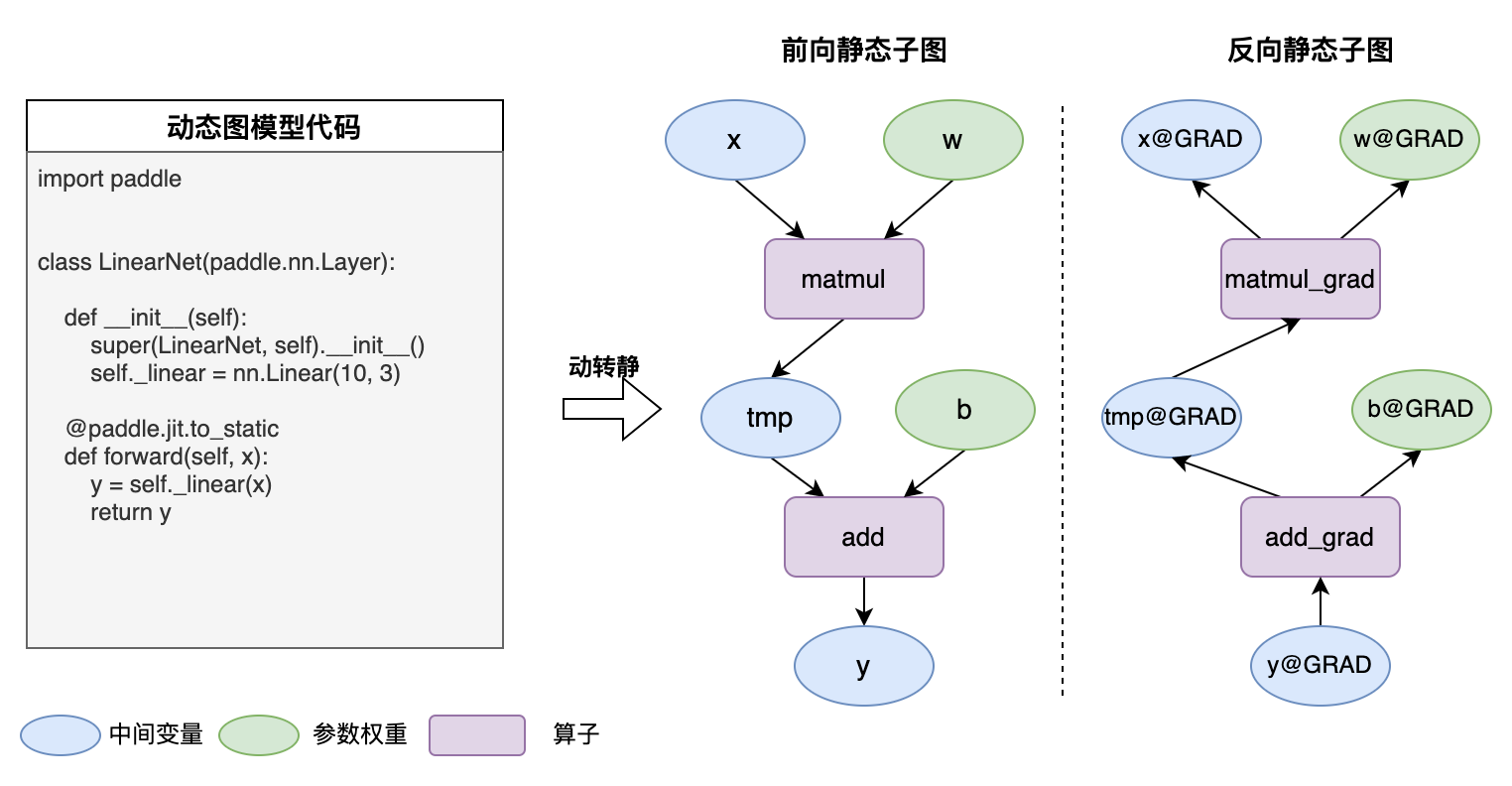
上面提到,所有的组网代码都会在静态图模式下执行,以生成完整的 Program 。但静态图 append_op 有一个前置条件必须满足:
- 前置条件:append_op() 时,所有的 inputs,outputs 必须都是静态图的 Variable 类型,不能是动态图的 Tensor 类型。
- 原因:静态图下,操作的都是描述类单元:计算相关的 OpDesc ,数据相关的 VarDesc 。可以分别简单地理解为 Program 中的 Op 和 Variable 。
因此,在动转静时,我们在需要在某个统一的入口处,将动态图 Layers 中 Tensor 类型(包含具体数据)的 Weight 、Bias 等变量转换为同名的静态图 Variable。
- ParamBase → Parameters
- VarBase → Variable
技术实现上,我们选取了框架层面给飞桨静态图 Program 添加算子的 append_op 函数作为类型转换的统一入口:即 Block.append_op 函数中,生成 Op 之前
def append_op(self, *args, **kwargs):
if in_dygraph_mode():
# ... (动态图分支)
else:
inputs=kwargs.get("inputs", None)
outputs=kwargs.get("outputs", None)
# param_guard 会确保将 Tensor 类型的 inputs 和 outputs 转为静态图 Variable
with param_guard(inputs), param_guard(outputs):
op = Operator(
block=self,
desc=op_desc,
type=kwargs.get("type", None),
inputs=inputs,
outputs=outputs,
attrs=kwargs.get("attrs", None))
3.2 一键递归转写
Python语言的灵活性对动转静模块要求极高。相对于静态图编程,动态图下完全继承了Python语言的灵活性,因此对动转静的语法功能实现要求很高,既要兼顾对原生Python语法的支持,也要保证静态图接口的正确转换,在API使用上要尽量减少用户使用的成本。飞桨扩展优化了动转静核心API@to_static接口功能,除了支持装饰器模式之外,并实现用户实现仅需一行代码即可一键递归转成静态图,极大的减少了用户动转静时的代码改写量,提升了功能的易用性和用户的使用体验。
一键递归转写,得益于飞桨动转静的自动递归转写技术组件。通过借助对Python抽象语法树(下简称:AST)的解析,感知用户的函数调用栈信息,逐层对内部嵌套函数进行动态解析和转写,模拟实现“自动递归”的效果。为了减少同一函数的重复转写,飞桨新引入了两级缓存机制:即函数转写缓存和Program转写缓存。
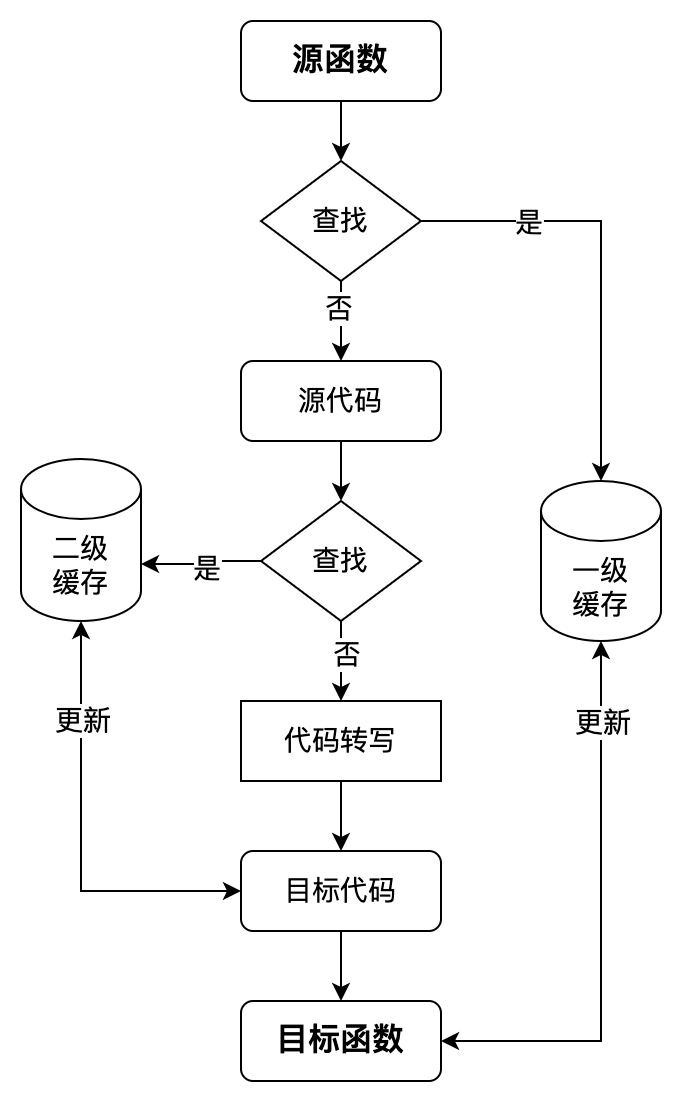
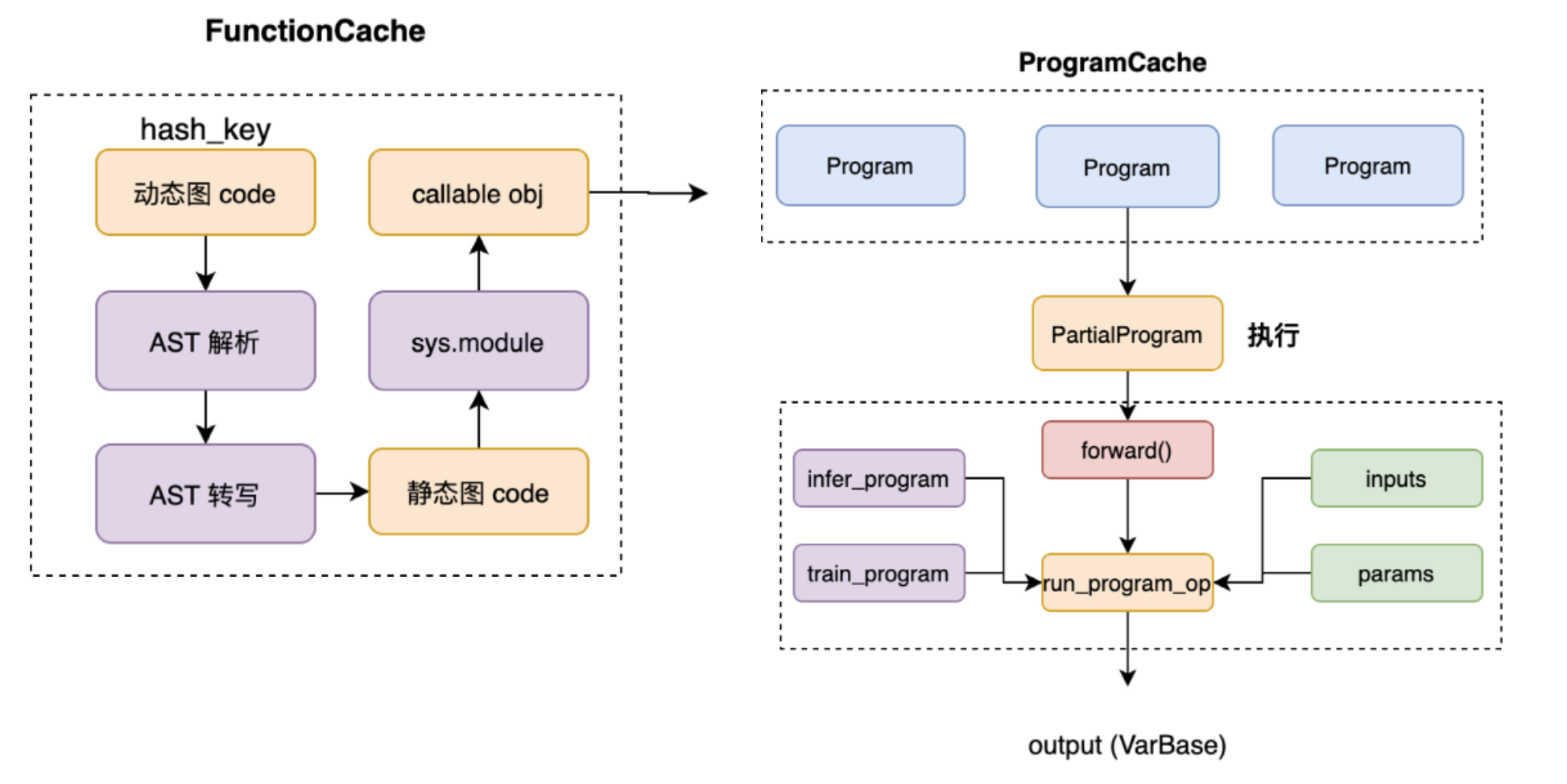
函数转写缓存指对于同一个函数,在第一次转写时会缓存转写结果,在出现函数重复调用时直接命中缓存,减少相同code的AST抽象语法树解析和转写开销,达到复用的效果;Program转写缓存指对于同一个模型在每轮迭代执行时,会自动根据输入张量的shape、dtype信息,缓存已转写的Program,避免训练时每个step重复转写Program。
四、 动转静训练
在飞桨框架中,通常情况下使用动态图训练,即可满足大部分场景需求。 飞桨经过多个版本的持续优化,动态图模型训练的性能已经可以和静态图媲美。如果在某些场景下确实需要使用静态图模式训练,则可以使用动转静训练功能,即仍然采用更易用的动态图编程,添加少量代码,便可在底层转为静态图训练。
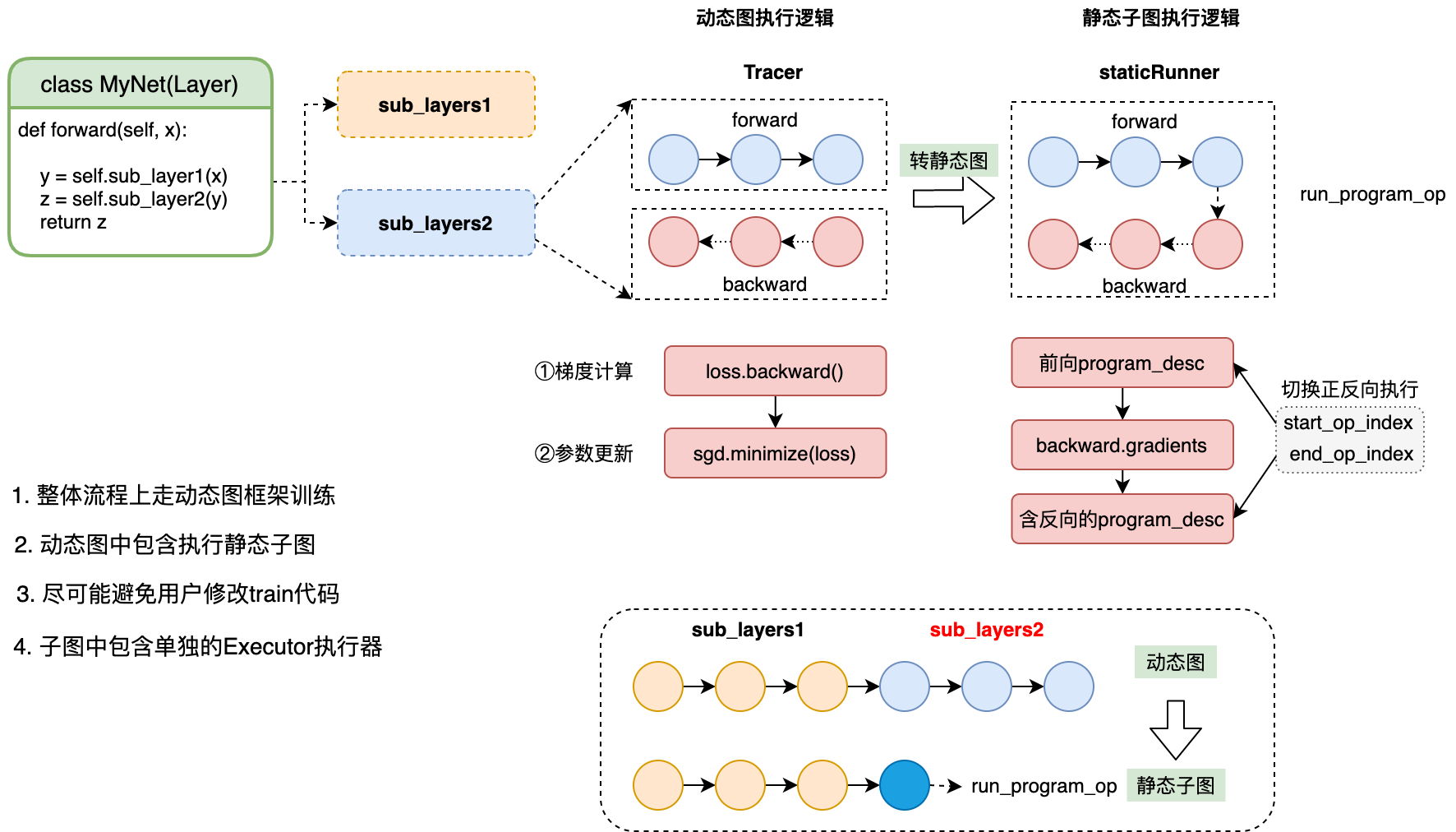
当用户在组网入口的forward函数处添加装饰器@to_static,会将此函数内的所 有subLayers 转化为一个静态子图,并分别执行。
在如下场景时可以考虑使用动转静进行模型训练,带来的性能提升效果较明显:
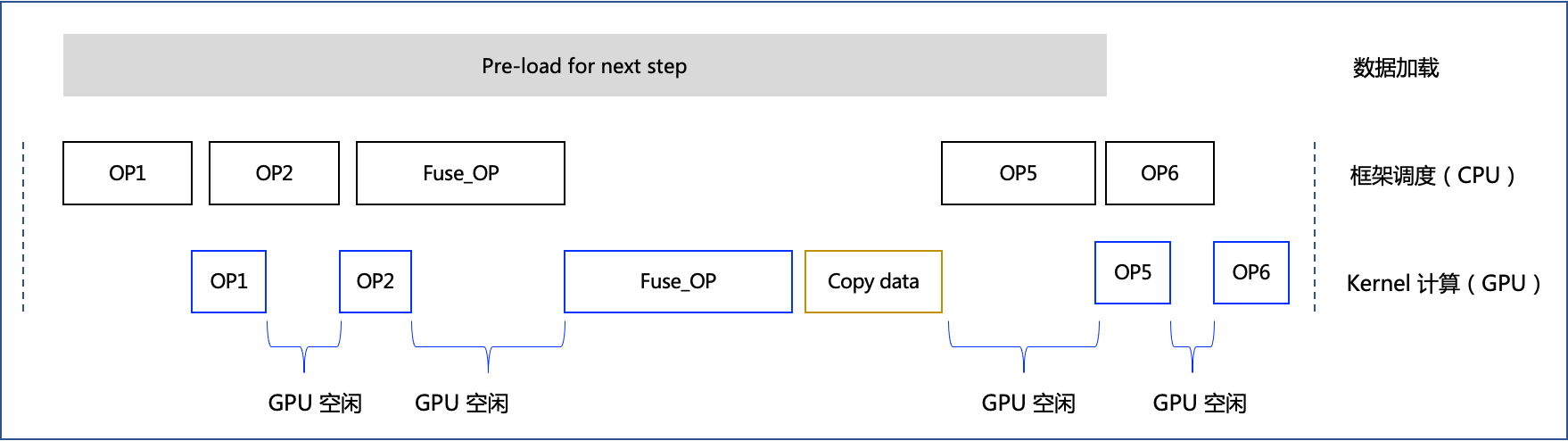
- 如果发现模型训练 CPU 向 GPU 调度不充分的情况下。如下是模型训练时执行单个 step 的 timeline 示意图,框架通过 CPU 调度底层 Kernel 计算,在某些情况下,如果 CPU 调度时间过长,会导致 GPU 利用率不高(可终端执行
watch -n 1 nvidia-smi观察)。
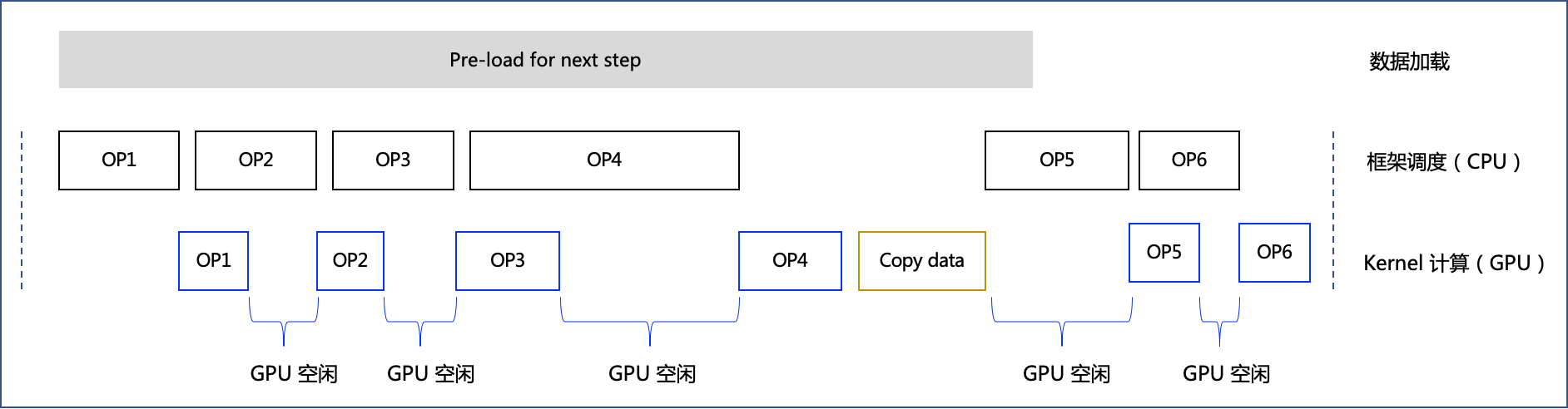
动态图和静态图在 CPU 调度层面存在差异:
- 动态图训练时,CPU 调度时间涉及 Python 到 C++ 的交互(Python 前端代码调起底层 C++ OP)和 C++ 代码调度;
- 静态图训练时,是统一编译 C++ 后执行,CPU 调度时间没有 Python 到 C++ 的交互时间,只有 C++ 代码调度,因此比动态图调度时间短。
因此如果发现是 CPU 调度时间过长,导致的 GPU 利用率低的情况,便可以采用动转静训练提升性能。从应用层面看,如果模型任务本身的 Kernel 计算时间很长,相对来说调度到 Kernel 拉起造成的影响不大,这种情况一般用动态图训练即可,比如 Bert 等模型,反之如 HRNet 等模型则可以观察 GPU 利用率来决定是否使用动转静训练。
如果想要进一步对计算图优化,以提升模型训练性能的情况下。相对于动态图按一行行代码解释执行,动转静后飞桨能够获取模型的整张计算图,即拥有了全局视野,因此可以借助算子融合等技术对计算图进行局部改写,替换为更高效的计算单元,我们称之为“图优化”。如下是应用了算子融合策略后,模型训练时执行单个 step 的 timeline 示意图。相对于图 2,飞桨框架获取了整张计算图,按照一定规则匹配到 OP3 和 OP4 可以融合为 Fuse_OP,因此可以减少 GPU 的空闲时间,提升执行效率。
五、 动转静导出部署
动转静模块是架在动态图与静态图的一个桥梁,旨在打破动态图模型训练与静态部署的鸿沟,消除部署时对模型代码的依赖,打通与预测端的交互逻辑。下图展示了动态图模型训练——>动转静模型导出——>静态预测部署的流程。
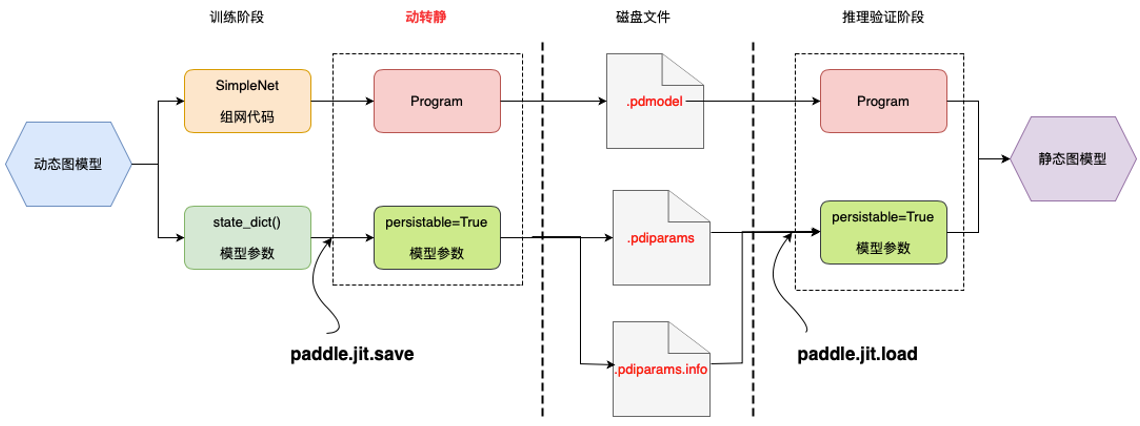
在处理逻辑上,动转静主要包含两个主要模块:
- 代码层面:将模型中所有的 layers 接口在静态图模式下执行以转为 Op ,从而生成完整的静态 Program
- Tensor层面:将所有的 Parameters 和 Buffers 转为可导出的 Variable 参数( persistable=True )
通过 forward 导出预测模型导出一般包括三个步骤:
- 切换 eval() 模式:类似 Dropout 、LayerNorm 等接口在 train() 和 eval() 的行为存在较大的差异,在模型导出前,请务必确认模型已切换到正确的模式,否则导出的模型在预测阶段可能出现输出结果不符合预期的情况。
- 构造 InputSpec 信息:InputSpec 用于表示输入的shape、dtype、name信息,且支持用 None 表示动态shape(如输入的 batch_size 维度),是辅助动静转换的必要描述信息。
- 调用 save 接口:调用 paddle.jit.save接口,若传入的参数是类实例,则默认对 forward 函数进行 @to_static 装饰,并导出其对应的模型文件和参数文件。
如下是一个简单的示例:
import paddle
from paddle.jit import to_static
from paddle.static import InputSpec
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
def forward(self, x, y):
out = self.linear(x)
out = out + y
return out
def another_func(self, x):
out = self.linear(x)
out = out * 2
return out
net = SimpleNet()
# train(net) 模型训练 (略)
# step 1: 切换到 eval() 模式
net.eval()
# step 2: 定义 InputSpec 信息
x_spec = InputSpec(shape=[None, 3], dtype='float32', name='x')
y_spec = InputSpec(shape=[3], dtype='float32', name='y')
# step 3: 调用 jit.save 接口
net = paddle.jit.save(net, path='simple_net', input_spec=[x_spec, y_spec]) # 动静转换
执行上述代码样例后,在当前目录下会生成三个文件,即代表成功导出预测模型:
simple_net.pdiparams // 存放模型中所有的权重数据
simple_net.pdmodel // 存放模型的网络结构
simple_net.pdiparams.info // 存放额外的其他信息