
MySql的数据存储之B+树(浅谈)
一.MySql的实际存储位置
B+树是MySql数据结构的主流存储方式,包括InnoDB和MYISAM引擎,它们的默认存储结构都是B+树
了解B+树前,我们先要知道MySql 的实际存储位置在哪?
有人会说它存在我么的D盘或C盘的MySql文件夹的Data目录里,这个回答没错,我们在深入的了解一下呢?
不管是在个人电脑上使用本机MySql或者在互联网上把信息存在服务器上,其实它们最终的存储地址都是被写在了物理磁盘上,只有存在物理磁盘上,才能保证数据长久不丢失
物理磁盘一般可以描述为:柱面,磁面,扇区,通过这三个参数可以精准定位到数据所在的地方
我们来看看一个普通的磁面:
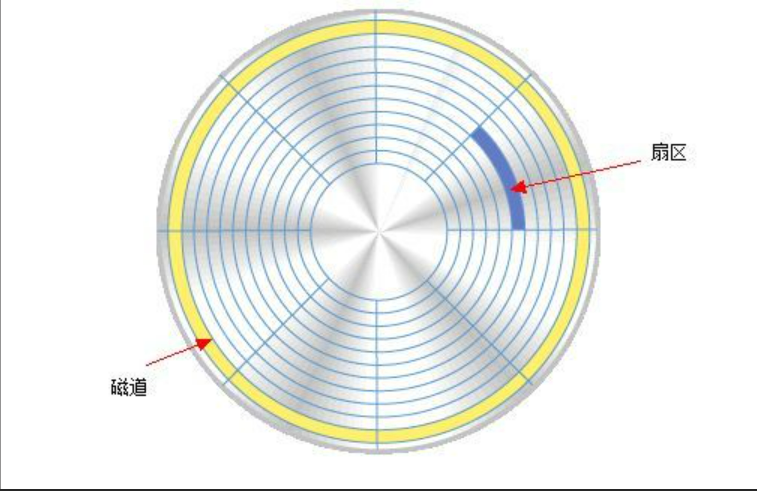
我们可以看到这个磁面上记录着磁道和扇区,
一般磁盘定位有固定头和移动头两种:
固定头每个磁道上都有一个读写头,造价高,但是读写速度快,定位时间短
移动头每个磁面上一个读写头,造价适中,读写速度主要取决于定位时间,从定位磁道,再到定位扇区所化的时间,现行的物理磁盘大多都是使用的移动头定位
我们在了解了我们的磁盘和移动头后,我们就需要了解一次物理磁盘的I/O,它指的是对于磁盘来说,一次磁盘的连续读或者连续写称为一次磁盘 I/O, 磁盘的 IOPS 就是每秒磁盘连续读次数和连续写次数之和。
我们这里就把他当作读写一次扇区,即一次I/O只读写一个扇区(实际上的I/O指的是根据查询的数据大小,可能会连续读写好几个或者几百个扇区,但是也只进行了一次I/O,因为I/O读写的时间开销最大的还是在移动头的定位时间上)
一个扇区的大小比较公认的是512字节(后面慢慢发展的也有一个扇区2048字节的,我们这里就举例512字节)
我们先简单的看一个数据表,数据在扇区上是怎么存储的:
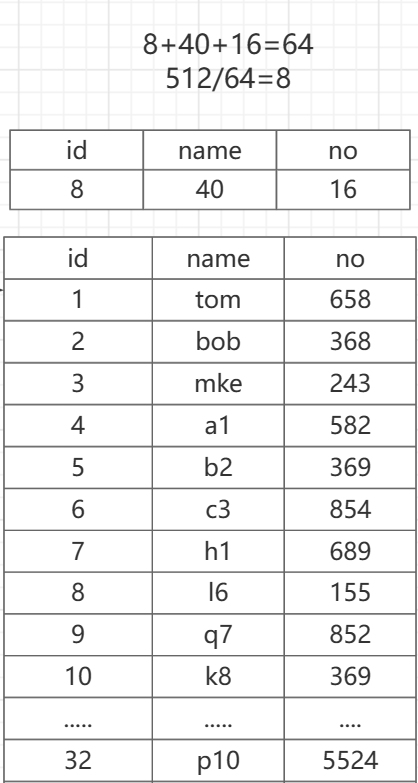
这里我们定义了一张表,还有里面的数据,他有三个属性:id 8字节,name 40字节,no 16字节
由此我们可以推出:这张表的一条记录就是8+40+16=64字节,我们这会儿定义的这张表的一条记录就要占64字节
一个扇区512字节:512/64=8
所以一个扇区就只能装8条记录,我们这32条记录就需要32/8=4,就需要4个扇区去装入,
如果我们按照规定的一次I/O读写一个扇区,那我们要找到32这条记录的话需要4次I/O操作,4次还算一般性能,但是我们在大型的数据库存储一张表可不止32条记录哦
但我们简单的把记录加到800条的时候:800/8 = 100 ,也就是需要100个扇区来装入,那我们要查找第800条记录的时候就需要100次I/O操作,显然这样的I/O操作就太慢了,要是有1000个人需要查找,时间开销就很大了
这种情况我们就需要引入索引;B+树的根节点几乎全是索引
二.MySql的索引
什么是索引呢?
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。索引是针对表而建立的,它是由数据页面以外的索引页面组成的,每个索引页面中的行都会含有逻辑指针,以便加速检索物理数据。
简单的说,索引就是建表或者后期加入的,它可以分为主键索引,复合索引,普通索引,
当我们建立索引以后,就会自动的把建立索引的属性或属性组单独的拿出来然后和这个属性所在的物理地址一起单独构成一个表来存放,虽然多了一个表但是因为属性较少,所占的空间少,查询效率高了
这里我们再来简单的看两个表:
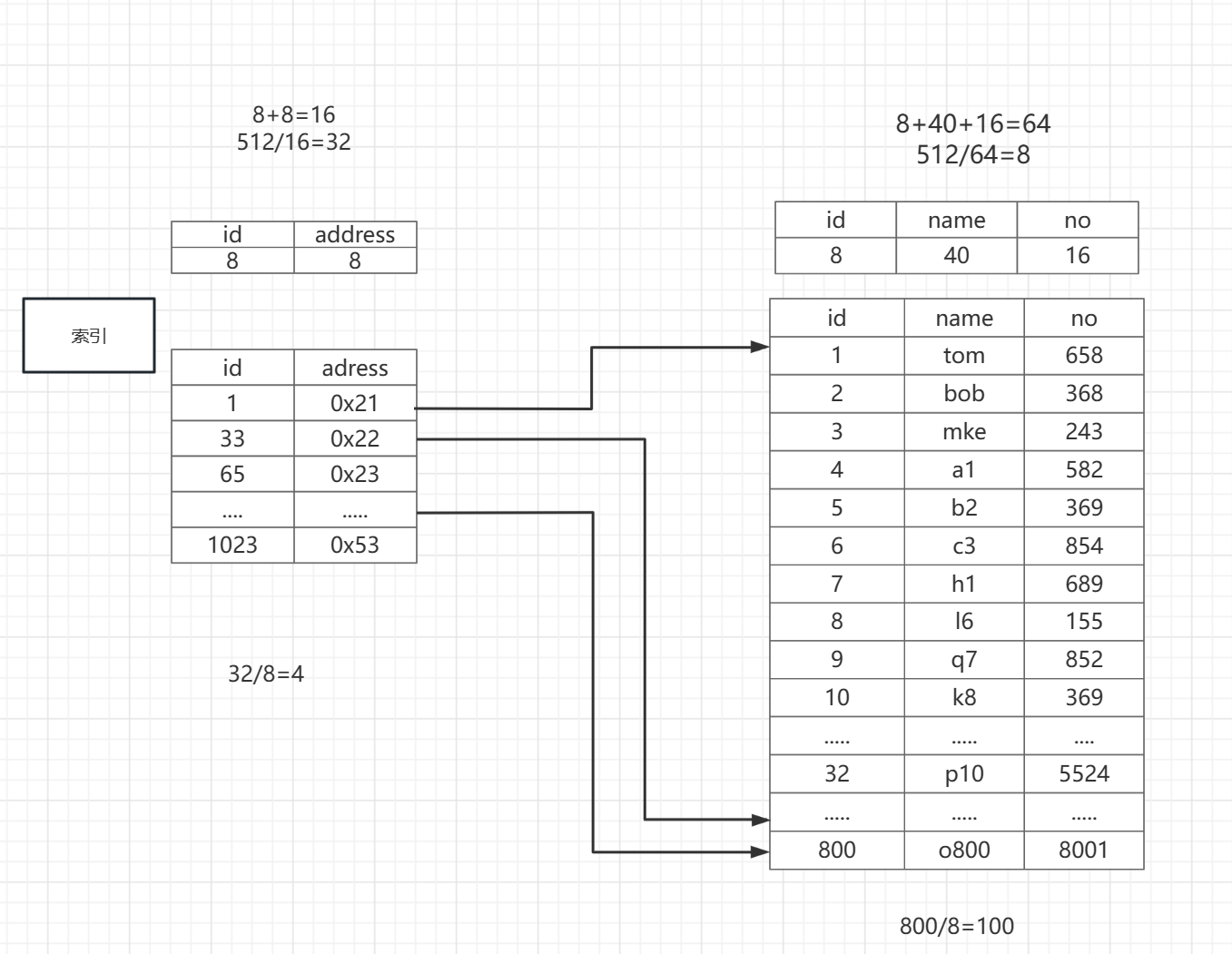
这里我们可以看到右边的表就是我们的数据表,它记录着800条记录,上面我们也看到了它要被查询到的话需要100次I/O,所以我们考虑为id建一个索引
当id被选为索引以后,id会和id所在的实际物理地址构成一个表,这个表id 8字节,地址 8字节,一共16字节,它也是存在一个扇区的还有可能没有和数据原表在相邻的扇区
一个扇区的的大小512字节:512/16 = 32,所以这个索引表所在的扇区,可以装32条记录
第一条记录:记录id为1,它所在的物理地址,
第二条记录:记录id为33,它所在的物理地址,
第三十二条记录:记录id为1023,它所在的物理地址
有了这个索引表之后,我们再查800条记录数据的过程就简单化了
首先,一次I/O操作会把这个索引表查出来(要用到索引才能命中,也就是再sql语句中的条件判断语句带有id),这里只进行了一次I/O就拿到了1~33,33~65,....~1023这些区间的信息
然后,我们查第800条记录的时候我们很幸运,因为索引表中有一个区间是800~833就可以通过地址直接去读800所在的扇区 这里就也只用了一次I/O操作
这是最好的情况:2次I/O就拿到了第800条件记录
我们看看最坏的情况,细心的朋友可以发现再每个区间都有一个最坏情况,
比如:
1~33区间上,当我们要查询32时只能通过找到id=1的扇区,然后依次读取直到读到id=32的扇区
33~65区间上,当我们要查询64时只能通过找到id=33的扇区,然后依次读取直到读到id=64的扇区
......
800~833区间上,我们去查找832时:
只会给我们找到800的首地址,这是一次I/O读写了
从800读到832一共是32条记录:32/8=4(扇区),也就是我们要连续读取4个扇区才可以找到id = 832这条记录,这就需要4次I/O
我们可以看到,即使是最坏的情况:1+4=5,我们也只需要5次I/O就可以拿到任意的数据了
比起没有索引的查询:从第32条记录开始,就会成比例的不断增大读写次数
有索引的情况的查询:最坏的情况也就5次I/O操作,但是索引需要单独存储,总的来说还是利大于弊,不建议建立索引,因为索引的维护需要开销,一般只会给经常查询且不常更改的数据做索引
继续加大数据,这次存放80000条记录:
当数据量达到80000条的时候:我们的一级索引表(紧贴实际数据表的索引表被称为一级索引)就显得的很乏力了,
我们简单的计算一下,我们的一级索引表只能存放1~1025记录的区间地址,当数据为80000
80000/1024 = 78~79,我们需要79个扇区来存储
如果是最坏的情况:我们要查找第80000条记录,那么在一级索引表中我们就进行了79次I/O操作了,再加上一级索引表去查实际数据的地址又是4次I/O,所以在这种情况下就是79+4=83次I/O
对于80000条数据查询就需要83次I/O,很显然,这个I/O次数太多了,我们得想办法把I/O次数压下去
这个时候我们的开发者想到的就是加一层,二级索引来指向一级索引,一级索引指向数据,对于B+树结构来说就是多了一层
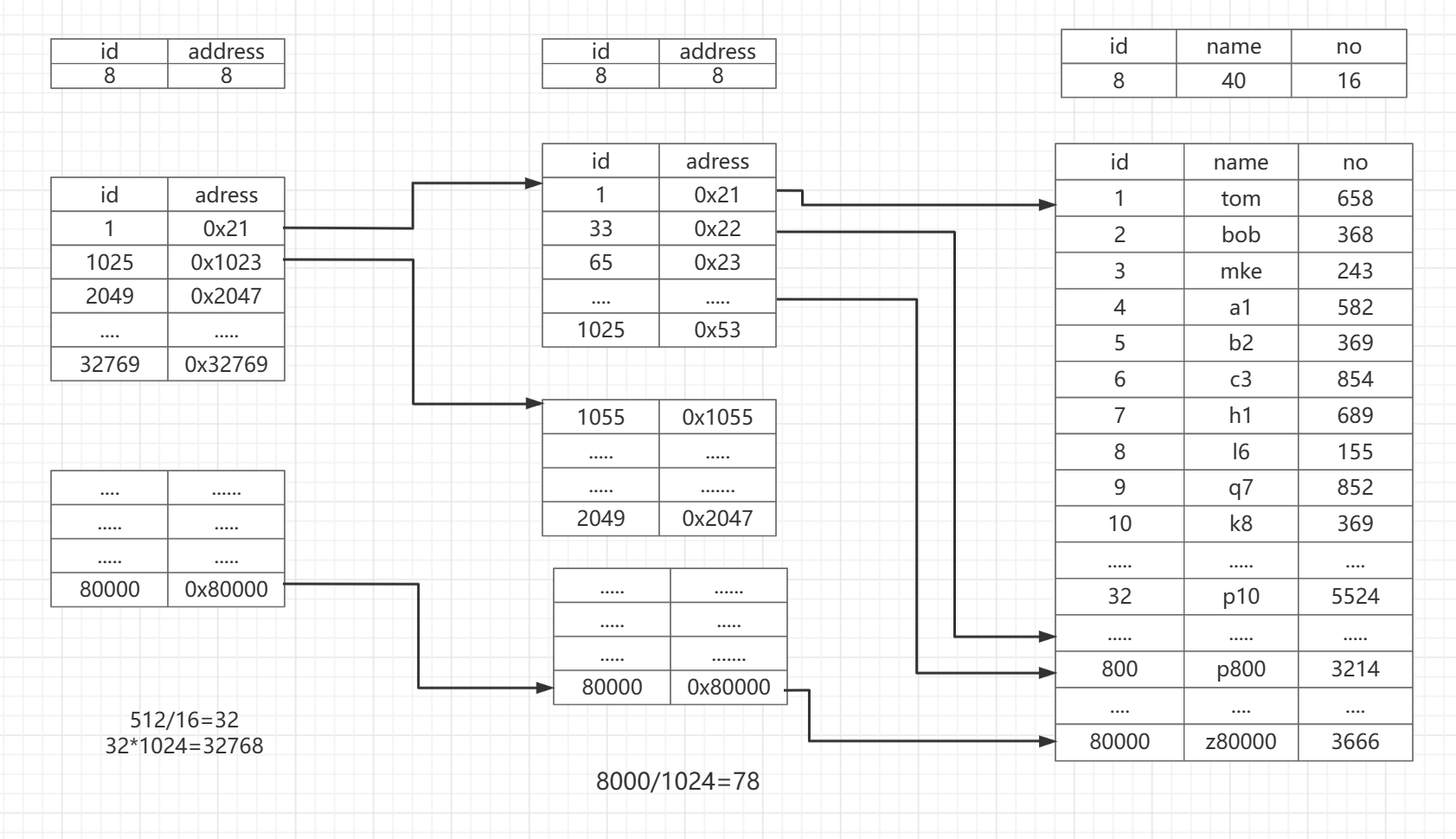
在二级索引上的adress字段就是记录的一级索引的地址,而不直接指向数据,在二级索引就是记录一个一级扇区的位置,
比如:
一级索引一个扇区的数据区间在1~1025
二级索引一条记录的就是一级索引区间的1~1025
所以一个二级索引扇区可以记录一级索引区间的范围是:
1024 * 32 = 32768
对于有80000条记录的表,二级索引扇区只需要3个就可以放下
这个时候利用二级索引查找80000:
1.
首先我们要找到80000这个区间,他在第三个扇区上,那么在二级索引上的I/O读写就需要 3次
然后去一级索引上找,由于是二级索引提供的物理地址,只需要一次I/O就可以读取到那个扇区,一级索引上有一个区间就是80000~81025,
最后去找实际的数据刚好80000就是头指针,也只需要一次I/O就可以完成
这是最好的一种情况:3+1+1=5,最好的状态5次I/O就可以拿到数据了
2.
最坏的情况也是出现在一级索引去找数据:就是80000~80033这个区间
我们要找80032的时候,只能通过首地址为80000的地址去找,要连续查找4个扇区,就是4次I/O操作才能拿到
3+1+4=8
所以在B+树上加了一层以后最坏,不管什么情况下,查找任意数据都只需要8次I/O操作,
综上:查找80000条数据(最坏的情况)
a.没有索引,一个扇区一个扇区的查找,80000/8 = 10000,没有索引需要10000次I/O操作
b.一级索引,由于第80000条记录在最后一个扇区上,80000/1024 = 79 ,一级索引需要79次I/O,利用一级索引去查找数据4次I/O,一级索引需要83次I/O操作
c.二级索引,由于第80000条记录在最后一个扇区上,80000 / 32768 = 3,二级索引需要3次I/O,利用二级索引的区间地址去找一级索引只需要1次I/O,然后一级索引去找数据需要4次I/O,二级索引查找数据就只需要8次I/O操作
到了这里我们就可以很明显的感受到索引的魅力了,其实讲到这里我们也可以很明显看到我们的B+树是怎么组织数据和索引的了
我们把上面的图片顺时针翻转90度,就可以很明显的看到我们的B+树就是这个模型
可能对博客中的例子存在的疑问:
a.索引表的区间范围一定是32吗?
不是,要根据开发人员的默认设置,或者后期数据库管理员去调整,一般人是更改不了物理存储的,只能了解原理
b.索引的表每条记录都是16字节吗?
不是,要根据建立索引属性的大小和实际物理地址大小而定,不一定每个扇区都能存刚好存32条索引记录
c.800条记录没有索引的情况真的要100次I/O操作吗?
不是,要根据一次读取的页面大小,MySql的默认读取是16KB:16kb / 64 =250 条记录,一般的查询一次I/O至少就是250条记录,
根据计算机局部性原理,当一个扇区的数据被使用后,它周围的数据极有可能再最近会被用到,所以mysql的缓存机制会支持一次查询返回4页,即从查询的当前的页开始往后磁头移动4页的大小,4*16=64kb
也就是64kb / 64 = 100条记录,在缓存中有一次I/O是有100条记录被返回,然后怎么查询就是InnoDB引擎所要了解的知识了
三.MySql中B+树索引存储结构的形成
现在我简化一下那张图片,然后把他旋转90度,我们再来看看它是什么样的图形
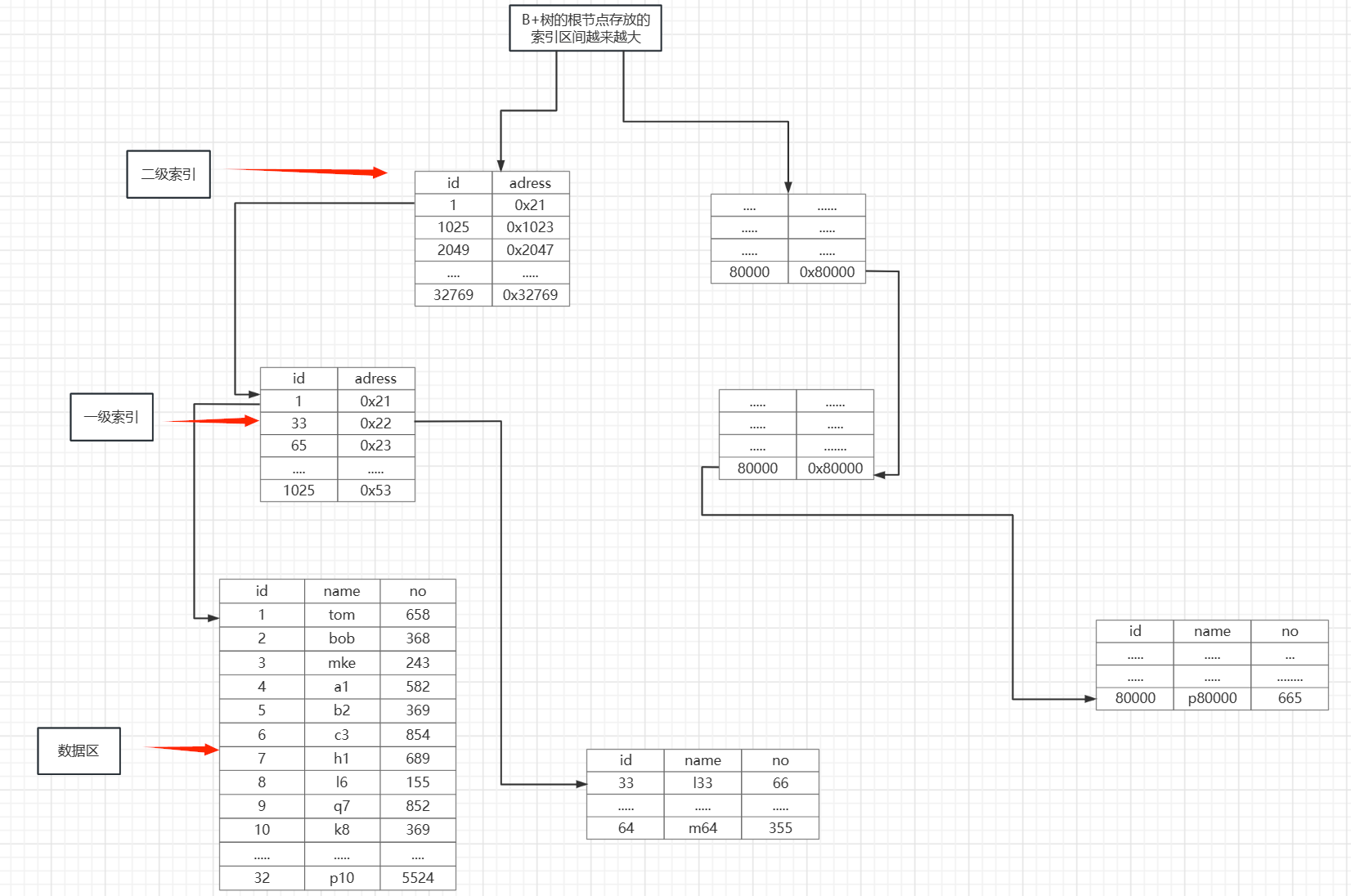
这就是一颗较为完整的B+树了,我们在仔细的看看可以发现B+树的特征
a.索引区间由根节点不断的变小,描述数据所在的扇区也越来越细化
b.根节点存放的都是索引,只有最下面一层的子节点才是数据
我们看完了B+树的形成过程以及它的大致模型,我们就不得不提一下它和B树的区别了,这是更深了解B+树的关键,
现在图片上描述的B+树,其实B树有很大一部分都能做到,我们就来看看B树和B+树的区别吧
B树和B+树的区别(主要的区别)
区别1:
B树的在根节点也存有数据,然后根节点存储的数据又是索引,又是数据
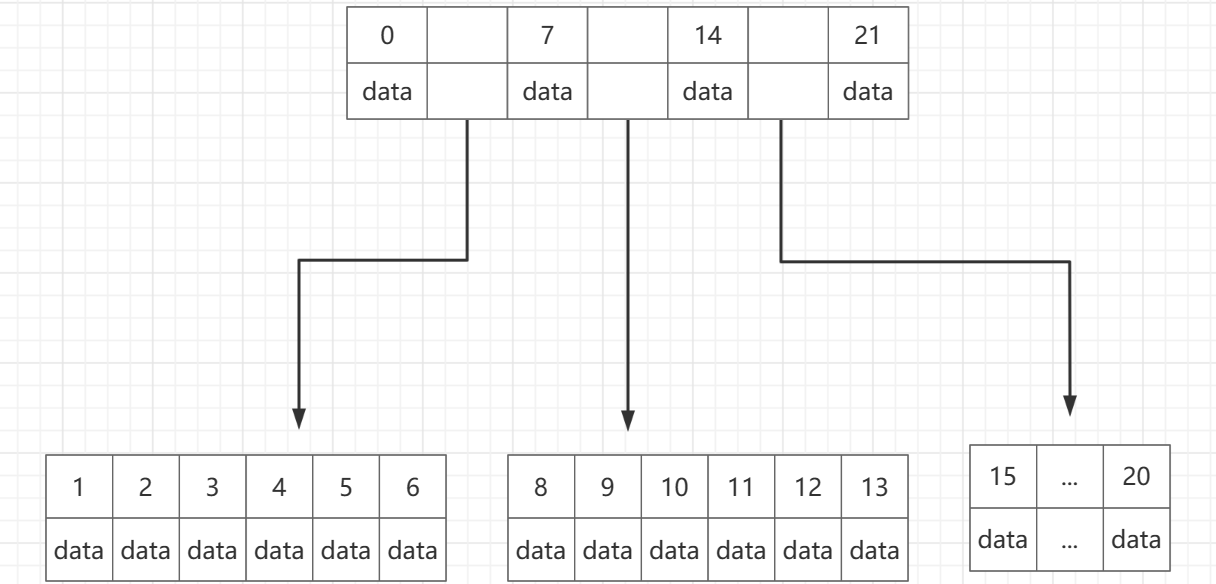
如图,在索引上出现的数据就不会在子节点出现了
可以说父节点可能既有索引又有数据,这就是B树的存储方式
B+树根节点没有数据,只存放索引
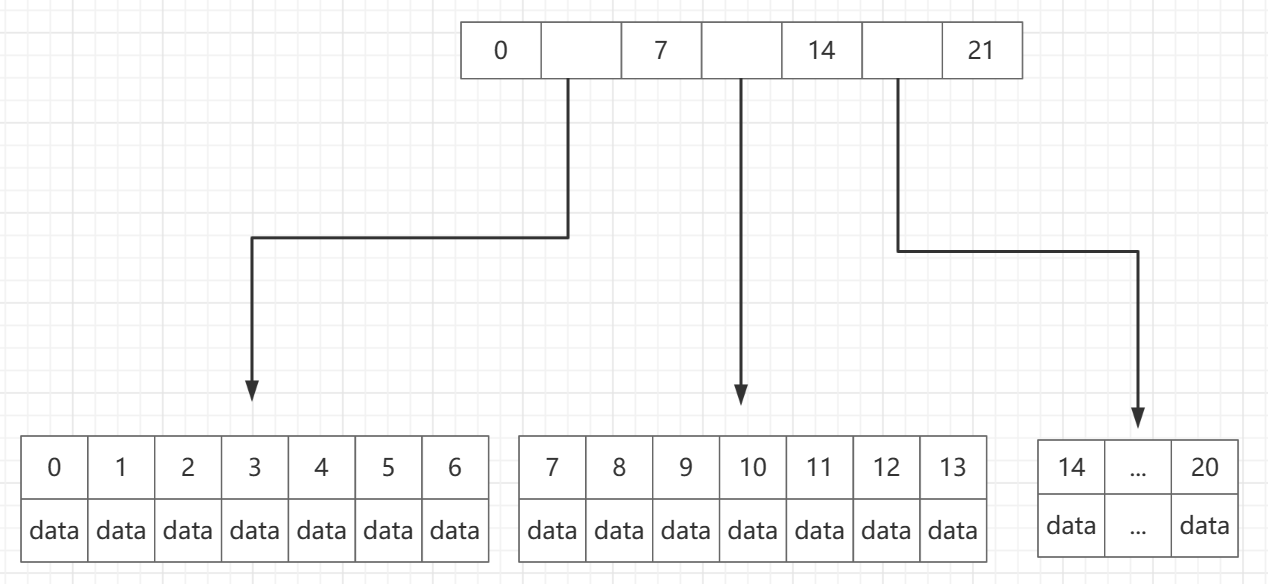
如图,数据都在最下面一层的子节点上,除了这一层以外的父节点全是索引没有数据
总结:
B树,存在一种情况就是所查的数据在最上层,因为节点有数据可能第80000条记录在最上层区间上,所以一次I/O就可以拿到数据,最坏的情况就和B+树一样,要到最后一层才能拿到数据
B+树,每次拿数据都需要在最下一层去拿,即使我们去拿一个表的第一条记录,它也会从根结点一级一级的往下直到最后一层才有数据
感觉有时候B树比B+树快啊,为什么MySql要用B+树呢?
因为B+树的查询比B树更加稳定,有利于开发者,数据库管理员对其进行性能测试,运行时日志检测的数据也会很准确
举个简单的例子,就以上面两张图片:我们要查询第7条数据和第8条数据,这两条记录是紧挨着的
使用B树查询:
第七条记录:1次I/O
第八条记录:2次I/O
使用B+树查询:
第七条记录:2次I/O
第八条记录:2次I/O
我们可以看到使用B树的第一次查询需要1次I/O,第二个需要2次I/O,B+树则都需要两次
这就很明显阿可以看出B树的查询效率很不稳定,尤其是层数变多,数据区间变得的时候,就更加明显
区别2:
这个区别是B+树特有的,
在B树上子节点和子节点是相互隔离开的,现在我们构造一种情况,B树中我们一条查询语句需要查询两条记录,
比如 id = 6 and id = 8
由于这是一条查询语句,所以要一起执行会发生什么,我们的磁头会先移动到根节点进行定位,然后就可以id = 6这条记录,然后从新去根节点查索引,磁头再定位到 id = 8 这条记录
很显然我们的B树查询进行了两次磁头定位,我们知道在读写磁盘时,最大的开销就是磁头的定位,所以我们要尽量少的进行磁头定位
所以,B+树在最后一层的数据结点上都加了指针(指向的是物理地址),让它指向下一个区间的开始位置,把尾部的数据又串起来了,就是专门对付这种相邻区间要重复磁头定位的情况
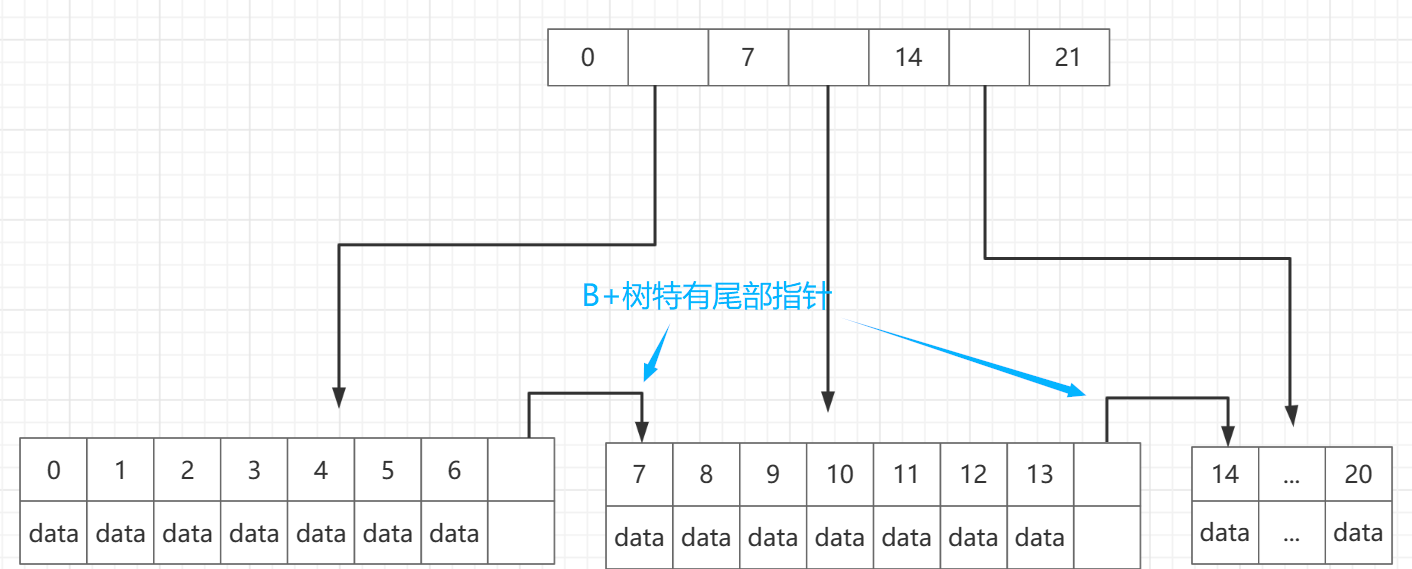
有了这个尾部指针,我们在用B+树去查找 id =6 和 id = 8的记录,当经过一次磁头定位以后找到了id = 6 的记录,它会根据尾指针直接读取 id = 8的记录,加快了相邻扇或几个相邻扇区的读写速度
四.总结
上面所有的描述都只是B+树常规的数据存储方式,实际上MySql的运行存储比B+树要复杂的多,因为我们各自的设备或者后期对物理存储的默认参数不一样
都会导致B+树存储的不同
需要真正的就业或者更进一步学习,MySql的认识还有很长的一段路要走