
数据结构与算法之一道题感受算法(算法入门)
题目:
给定N个整数的序列{ A1,A2,....An },求函数F(i,j)=Max{ Ai+.....Aj }
题目要求:
这道题的目的是要求给定的一个整数序列中,它所含的连续子序列的最大值,比如现在我有一个整数序列{ -3,2,3,-3,1}
它的最大子序列很显然是 { 2,3 }
第一种方法蛮力法(强制枚举):
我们从第一个整数开始遍历,依次计算一个一个的加起来,知道最后一个元素,我们不断的往后加的时候会一直更新最大的子序列,有情况是从头加到尾不是最大的,它在中间就已经是最大的
所以我们需要在没加一个就更新最大的子序列,当加到最后一个元素时
就换一个元素开始,比如从第二个元素开始,完了就第三个,就这么一直换了换的加,一直到使用最后一个元素开始计算时就结束
我们用举例图片来描述一下我们的蛮力法:
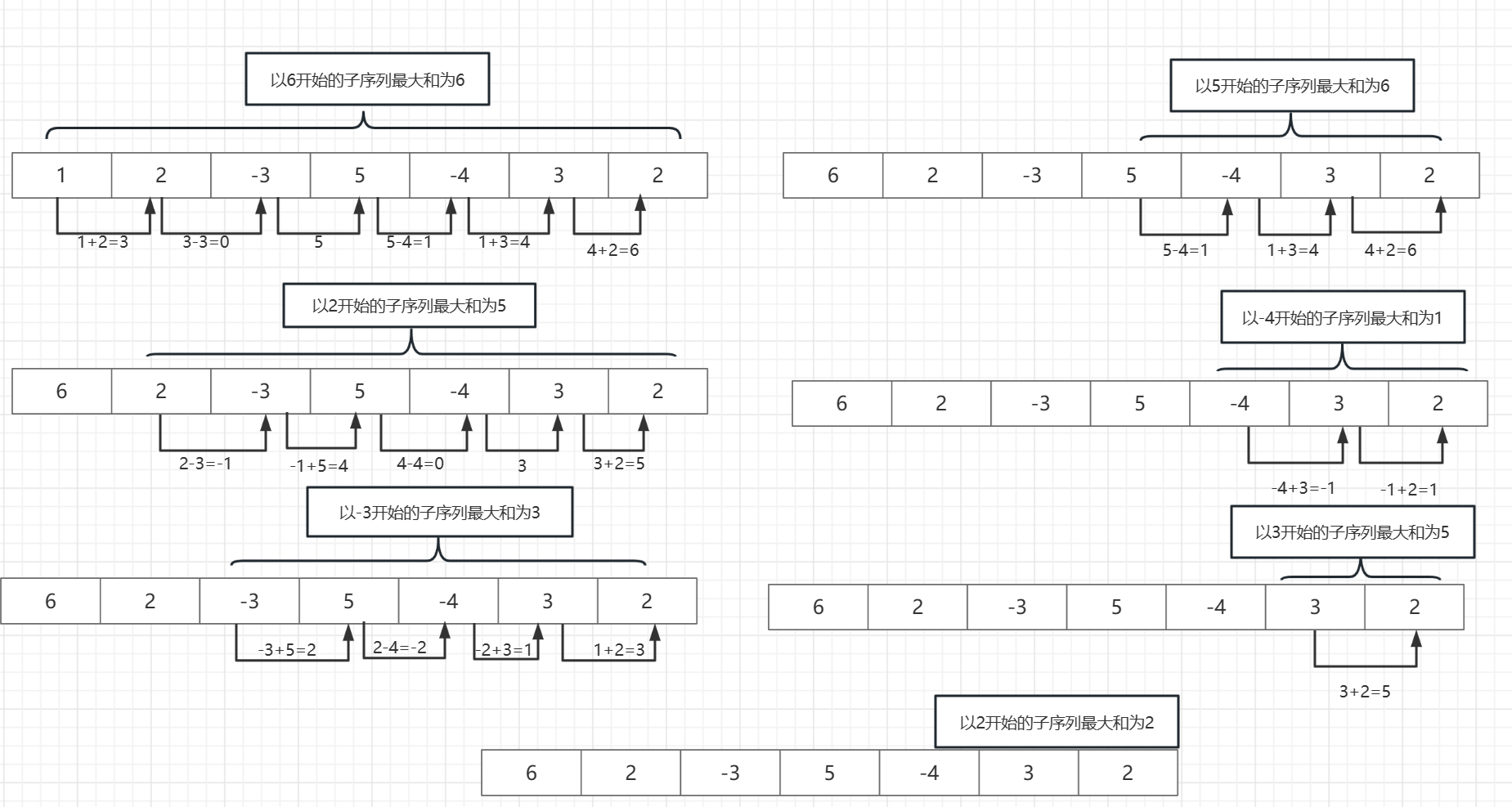
在第一次从第一个元素开始时候,我们的最大子序列和是依次动态更新为 1 ,3 ,5 ,6
在第二次从第二个元素开始时候,我们的最大子序列和是依次动态更新为 (未更新)
在第三次从第三个元素开始时候,我们的最大子序列和是依次动态更新为 (未更新)
在第四次从第四个元素开始时候,我们的最大子序列和是依次动态更新为 6
在第五次从第五个元素开始时候,我们的最大子序列和是依次动态更新为 (未更新)
在第六次从第六个元素开始时候,我们的最大子序列和是依次动态更新为 (未更新)
在第七次从第七个元素开始时候,我们的最大子序列和是依次动态更新为 (未更新)
综上:蛮力法的结果为 最大子序列为{ 5,-4,3,2 } ,最大子序列和为 6
现在我们使用伪代码实现一下这个算法:
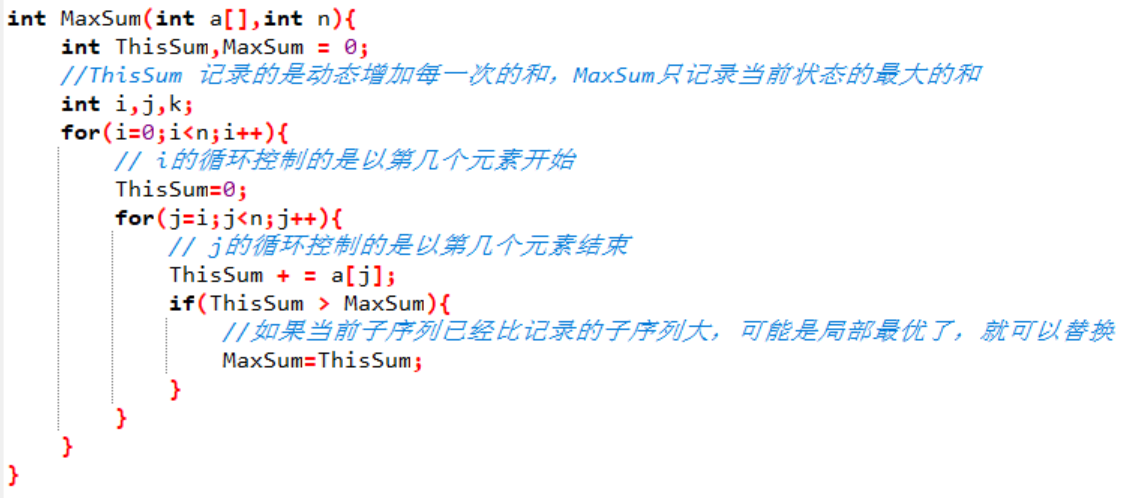
我们可以根据这个伪代码很快的计算出它的时间复杂度,有两个for循环,很明显的就是T(n) = O(n^2)
作为一个程序猿,我们在代码的时间复杂度为n平方时,我们要很自觉的要想到对复杂度进行降级,当n的数字变大时,n的平方就会以倍速增长,
所以,我们要考虑把这个复杂度降到 n log 2^n ,或者更好的 n 级 ,还有 log n
即使不能降到那么低也要考虑试试能不能降到 n log 2^n
二.分而治之(分治法):
首先我们来了解一下什么是分而治之?
分治法,字面意思是“分而治之”,就是把一个复杂的1问题分成两个或多个相同或相似的子问题,再把子问题分成更小的子问题直到最后子问题可以简单地直接求解,原问题的解即子问题的解的合并,这个思想是很多高效算法的基础,
这个算法的简单思路就是:
- 先把一个大问题有规律有技巧的分为小问题
- 对小问题进行计算,按要求求解(此方法的解决思想是解决小问题比直接解决大问题要简单)
- 再把计算好的结果或答案,按要求进行组合归并
基于这个算法还衍生了很多其它算法:但是并未完全使用到它的思想,都只用了一部分
最耳熟能详的就是:
1.二分查找:利用了 分解问题和计算问题的思想
2.归并排序:利用了 计算问题和合并求解的思想
此题的分治法解决思路:
这里,我们对于这个整数序列就可以使用这样的方法,我们先把这个序列一直划分,划分到左右两边要么只有一个元素要么只有一个元素的时候就可以计算了,
当划分到最小单元以后,左右两边都能计算出一个最大的序列,这个序列在最底层还是只有一个元素的,所以长度为一,大小就是它自己,
然后就回溯,回溯的过程中我们可能存在两个序列组合后才是最大的情况,所以我们要对其合并后的序列进行扫描,看看合并的序列比未合并的序列是否要大一些
如果合并序列比子序列大,那么合并序列才是最大子序列,反之,就看看左右两边那边的子序列大,大的就作为返回值,继续回溯,
直到回溯到最开始调用函数的时候,函数就执行完成,这个返回值就是最大子序列和
我们给定一个序列,然后按照分而治之的思想一步一步的做:
第一步:把大问题拆解成一个个小问题
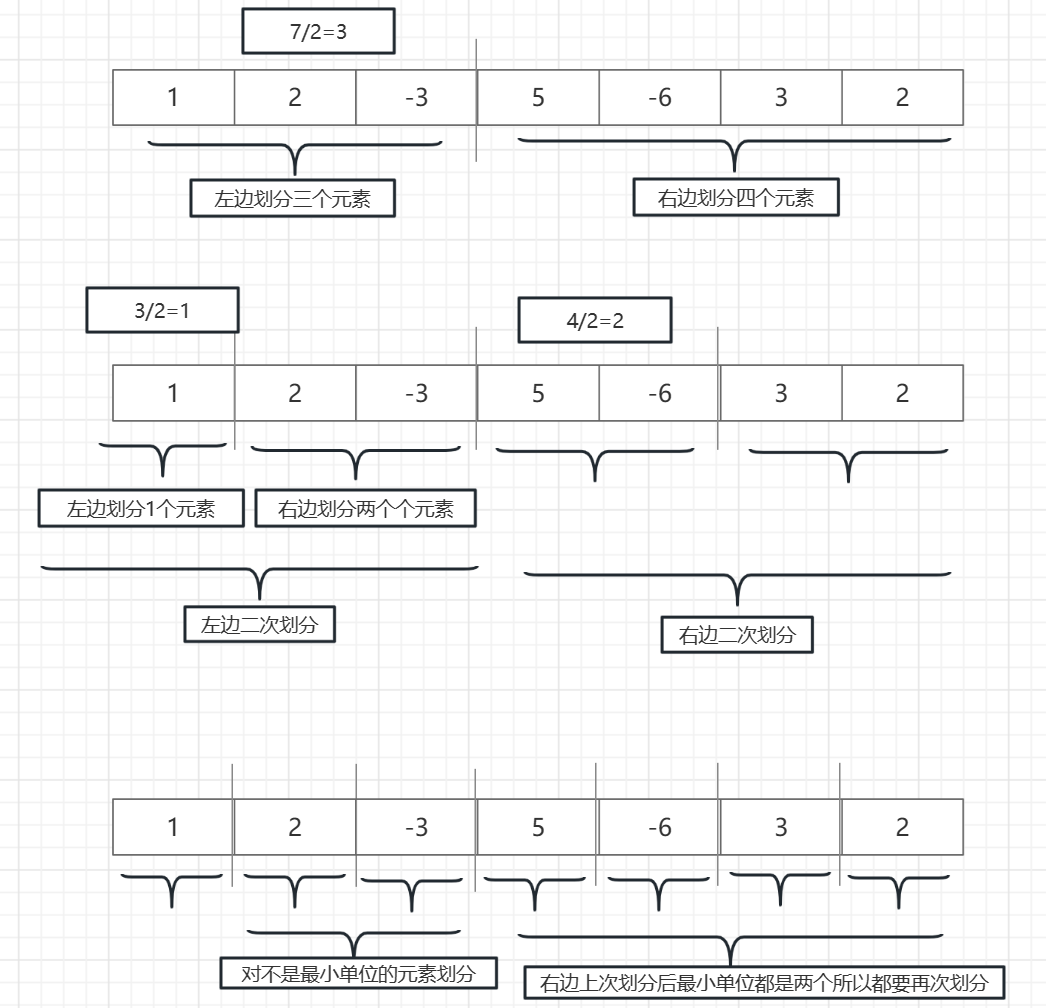
如图:我们把一个七元素的序列,划分成了七分只有一元素的子序列
当图片上的步骤完成以后,我们的第一步也就完成了,把大问题花小,这个时候我们这些小序列中谁的大就返回到上一级
第二步:对小问题进行求解,向上一级带回自己所计算的参数
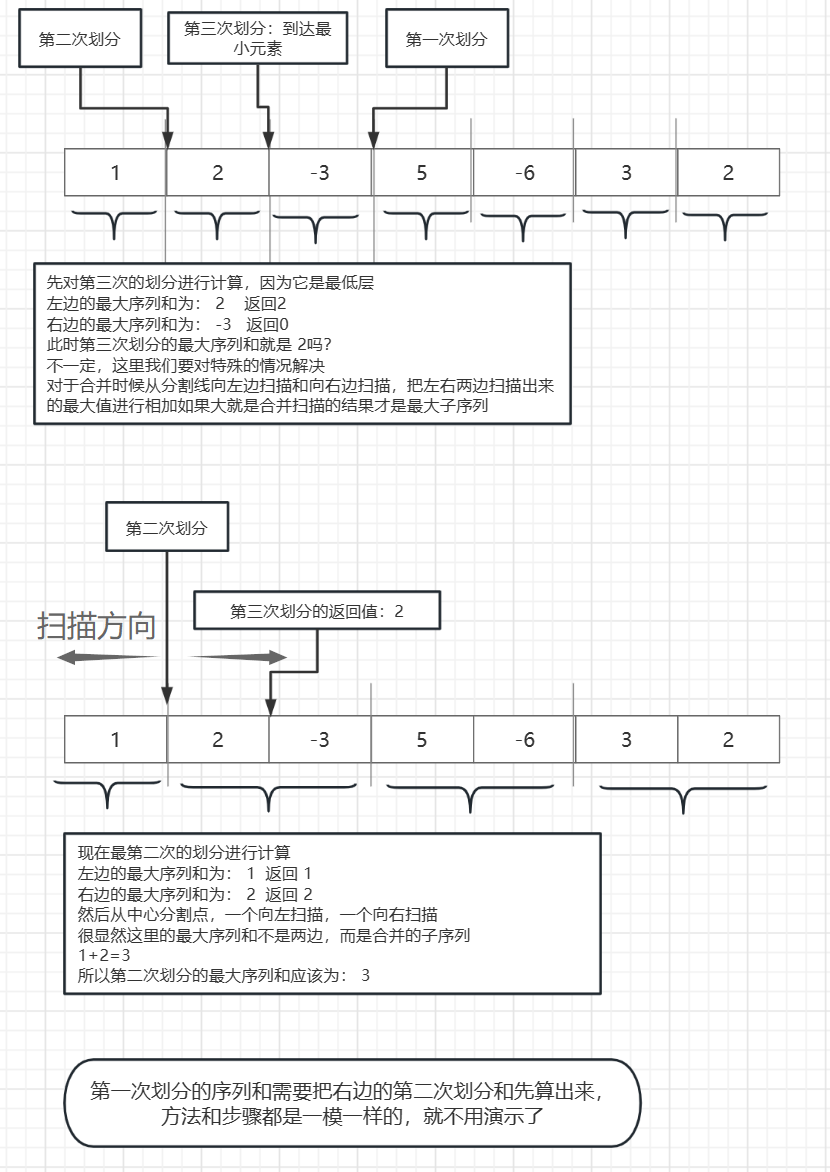
在计算的时候:一定要保证数据已经到达最小单位,比如这里我们是一个数组的话,那每一个最小序列必须是单个的数组元素以后才能计算
在合并计算时,左边会返回一个子序列的最大值,右边也会有一个,但是不一定合并后的子序列它们会是最大的序列和,我们要进行合并扫描
合并扫描左边区域和右边区域的扫描都要从中间断点开始,然后将扫描出的结果和左边返回值,右边返回值对比,大的才是这次划分的最终答案
思考:大家可以想想为什么左右两边,都要从中间开始向两边扫描(思路是连续最小序列和)
第三步:把计算好的结果,按要求进行组合回溯(或参数回带)
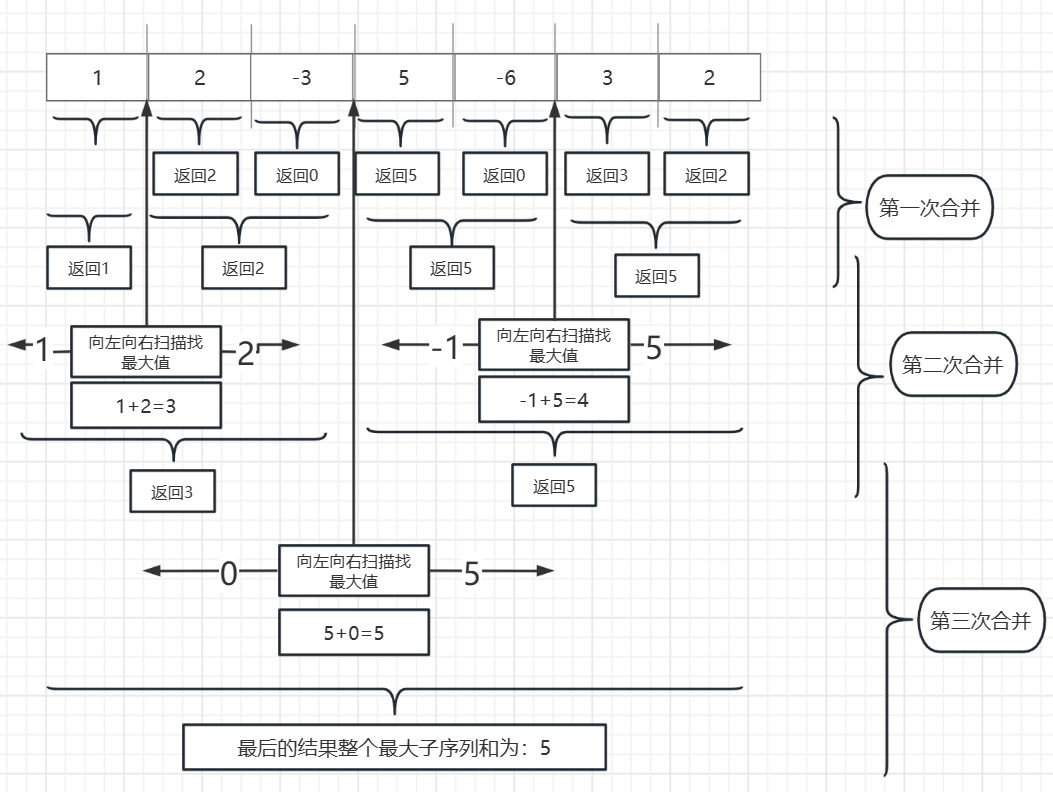
如图,从最低层开始,我们只要把左右两边的结果计算出来以后就已经开始合并了,每次拆分都对应着一次合并,
它们在合并后又开始新的计算,只要合并到最高层以后就有了最后的结果
下面我们用伪代码来看看这个算法的实现:
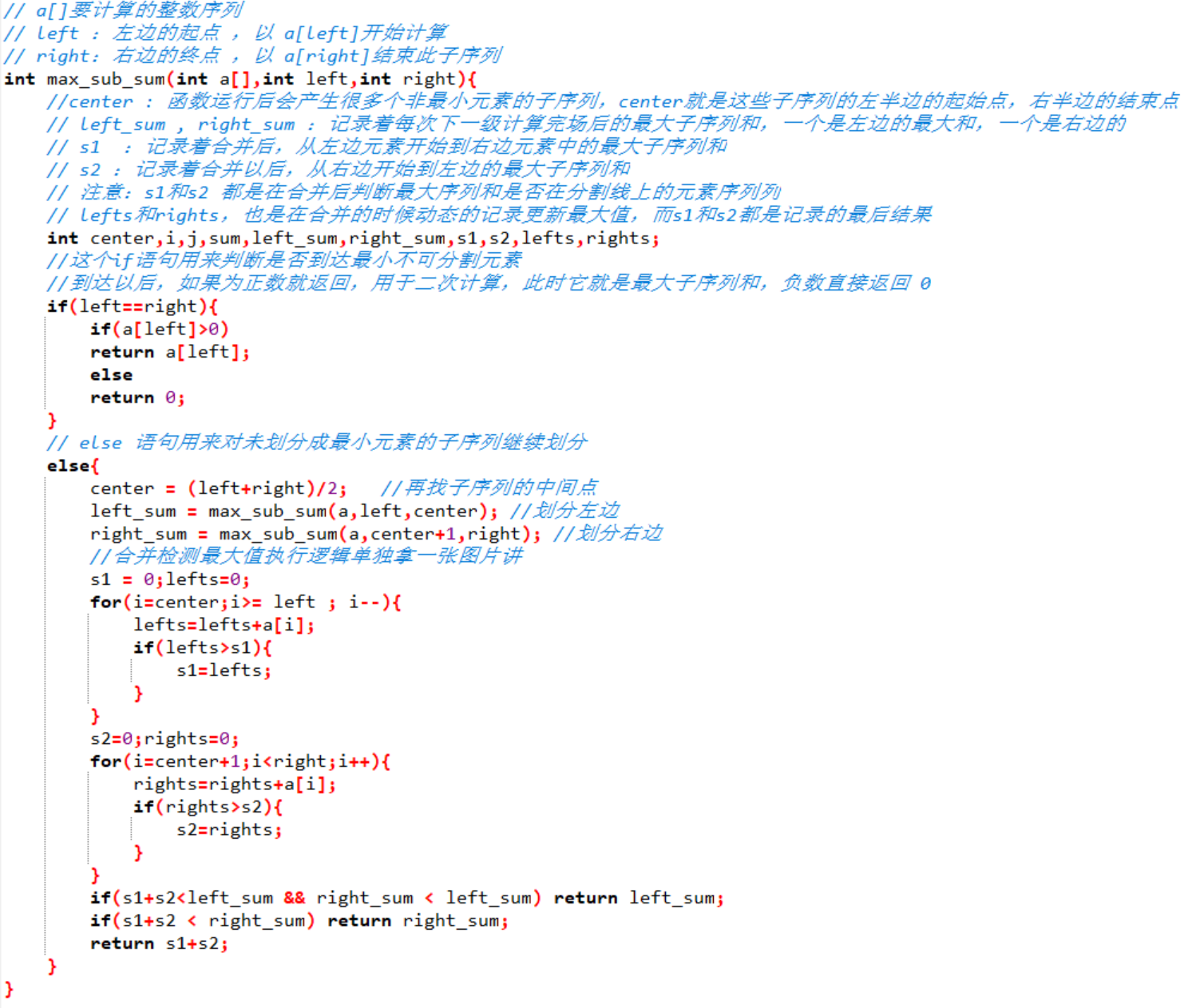
分治法在开始的时候会不断的拆分,当left = = right的时候,说明这数据下标就是它自己,就达到了我们要求的最小元素的要求,就可以计算后回带了
这里都还好理解,对于左右两边要返回一个最大子序列和没问题,主要的重点在于,合并时怎么计算分界点是否才是那个最大子序列
所以这里我们特别讲解一下这个左右扫描的思路:
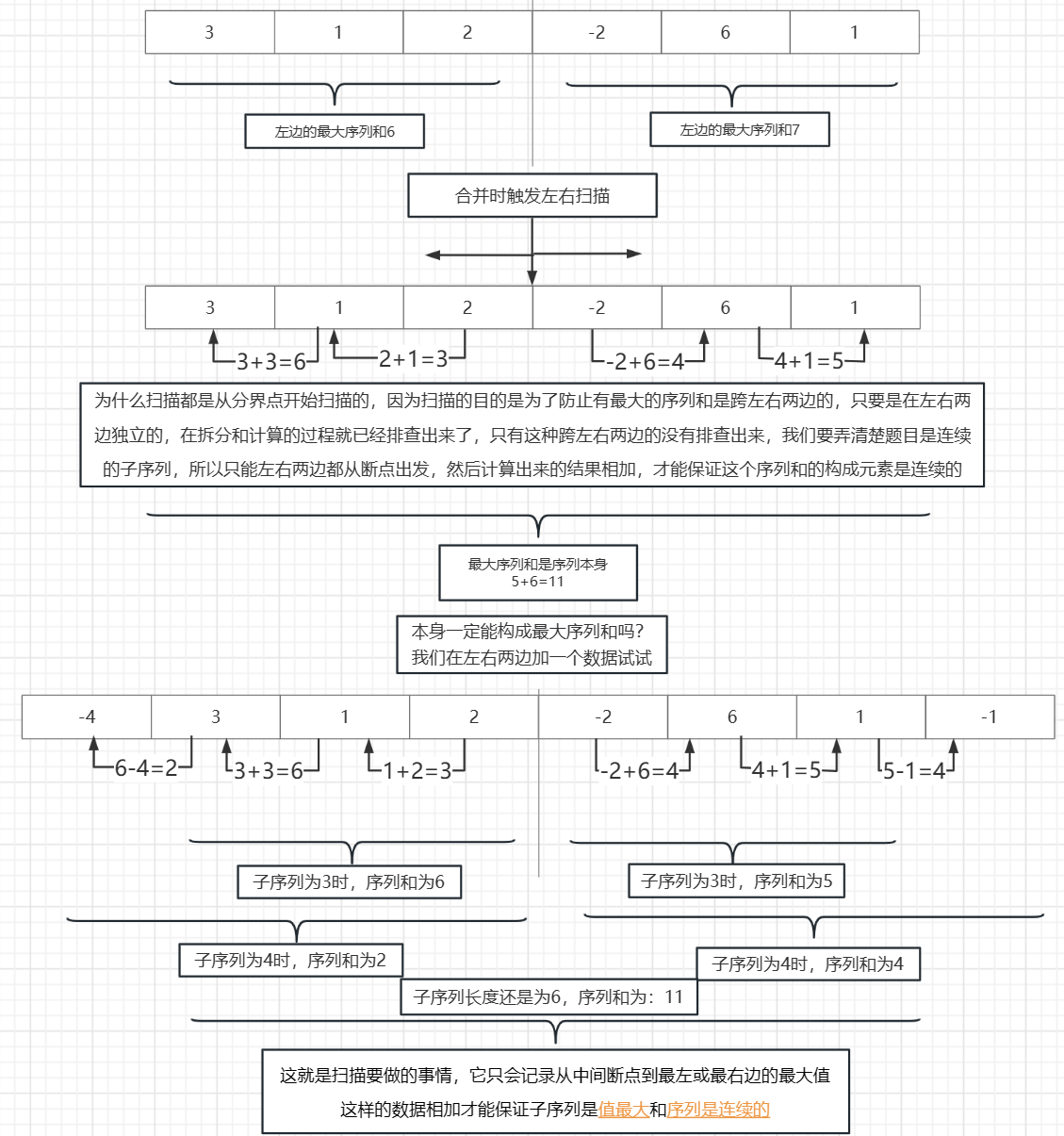
我们试着构造一个序列 { 3,1,2,-2,6,1 },当回溯到最后一次拆分时,
左边的最大子序列和是: 3+1+2 =6
右边的最大子序列和是:6+1=7
结果 7 不一定是最后的总的最大子序列和,我们这个时候就来扫描一下,左边的区域要从 2 开始向 左边扫描 然后实时更新最大序列和,很显然扫描完成以后最大序列和是: 2+1+3=6
然后就是右边区域,它需要从-2开始向右边扫描,扫描完成以后的值是: -2+6+1=5
最后左右关联起来的最大子序列和为 :5+6=11
综上:
11 > 7 >6
所以这个全序列才能构成最大的子序列和,并不是左右两边的数据构成的
以上就是分治法的解题思路了,我们一起来看看分治法的时间复杂度是多少吧
由于分治法的时间开销主要是,拆分和合并,所以计算方法也有点不同
我们可以简单的看一下,每拆分一次,左边右边都需要花费T(n/2)的时间,然后每次合并的扫描时间 就是O(n)也就是扫描会把每个被合并的元素一个一个都遍历一遍
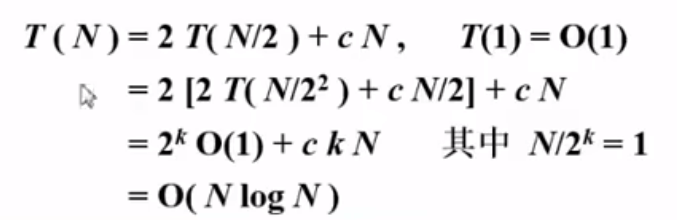
所以,最后分治法解决这一道题的时间复杂度是:O(N log N)
三.在线处理算法(Online Algorithm)
在线处理(Online Algorithm)是一种在数据流到达时实时处理数据的算法。在线处理算法需要在没有全部数据的情况下,即时处理当前接收到的数据,并根据已有的局部信息做出相应的决策,同时保证最终的全局结果是正确的。
在线处理算法就很神奇,它好像活得一样,不管你输入的数据有没有输完,它总能根据已输入的数据先做出判断然后给出答案,感觉有和贪婪算法一样,以局部最优解以定全局最优解
这一题我们使用在线处理算法的思路:
从第一元素开始遍历,依次向后加上后面的元素,当我们的加到后面的元素,所计算的结果集还是整数,就一直和已经记录的最大值比较,时刻记录着最大值,
当加到某个元素为负数时,这时候直接清零,从这个元素开始从新记录,因为负数不管后面元素是什么,都只会让这个子序列和变小
从新记录的是当前最大值,我们在前面记录的最大值还存在,要是从新记录的最大值是比原来的大,依旧可以更新最终的最大值
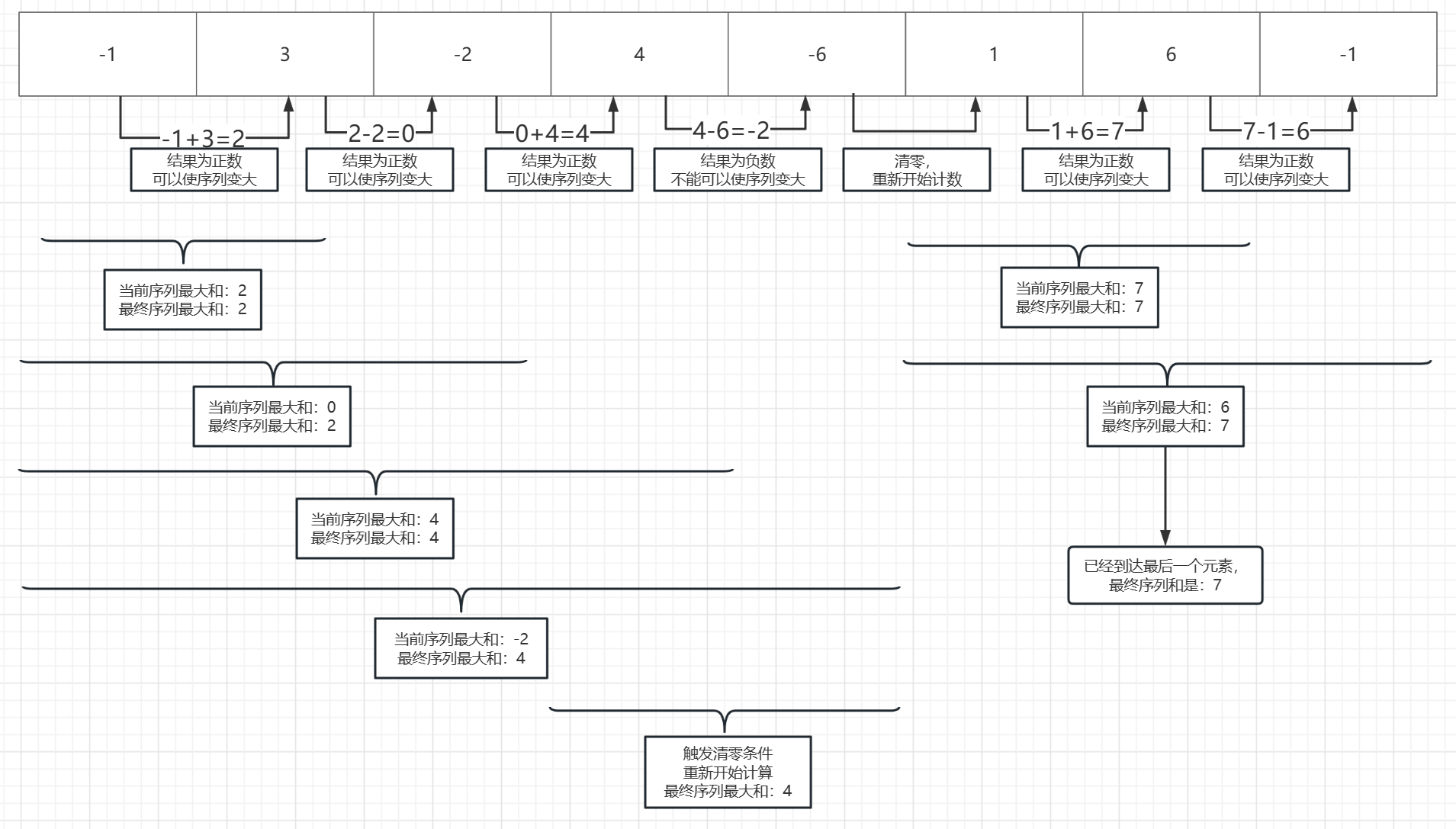
在线处理的有点很明显它的处理速度很快时间复杂度达到了O(n),对于任何一种算法来说,我们至少要把数据遍历一遍,所以这个算法已经算是最优的了

在线处理方法实现比较简单,运行速度快,也会导致它的正确性不是很明显
而且它只能执行依次,不可重复用,比如给它一串数据,它的执行逻辑是扫描完一个就会丢掉,尤其是清零时候,前面的数据原值直接就全部没有了
我们可以思考一下:这种算法的会不会发生错误?或者它能保证不管任何整数序列都可以拿到正确的最大序列和吗?
四.动态规划
我们说了,在线处理已经把时间复杂度降到完美了,所以我们这里的动态规划就作为一个拓展,动态规划的时间复杂的根据所给的题目有关,是不稳定的 常见的有:O(n^2) , O(n^3)
但是如果能构造到最优解,也可以达到 O(n)
什么是动态规划?
动态规划(英语:Dynamic programming,简称 DP),是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。动态规划常常适用于有重叠子问题和最优子结构性质的问题。
以上定义来自维基百科,看定义感觉还是有点抽象。简单来说,动态规划其实就是,给定一个问题,我们把它拆成一个个子问题,直到子问题可以直接解决。然后呢,把子问题答案保存起来,以减少重复计算。再根据子问题答案反推,得出原问题解的一种方法。
再具体一点,它会把算过的值记住,然后下一个计算可能会基于这个值来计算,减少了重复的计算,原始数据只会计算一次,每多一个数据,都是基于已经计算过的结果计算,新值 + 已经计算过的值
我们简单的构造一个例子来描述一下这道题:

对于这道题来说,刚好利用动态规划的时间复杂度也是O(n)
动态规划的灵魂在于,他会记录每一次计算的结果,避免了重复计算,后面新增的数据计算,都会基于它的前一次计算结果
以此,我们对于动态规划的使用就要基于此点
五.总结
算法和数据结构是相辅相成的,只有选定了数据结构,才能依据作出相应的算法
所以,在学算法前,数据结构的知识也要有
————————————博客根据—浙江大学陈越老师的《数据结构》课程总结