
编译原理(前端)的算法和实现
编译原理(前端)的算法和实现
本文介绍从零实现Lex+YACC(即一键生成编译器(前端))的算法。完整代码在(https://gitee.com/bitzhuwei/grammar-mentor)和(https://github.com/bitzhuwei/GrammarMentor)。
下文将用“解析器”指代编译器前端(即词法分析和语法分析)。
本文主要以四则运算为例,其文法如下:
// GrammarName = Calc
// ExtractedType = FinalValue
Additive : Additive '+' Multiplicative // R[0]
| Additive '-' Multiplicative // R[1]
| Multiplicative ; // R[2]
Multiplicative : Multiplicative '*' Primary // R[3]
| Multiplicative '/' Primary // R[4]
| Primary ; // R[5]
Primary : '(' Additive ')' // R[6]
| 'number' ; // R[7]
// 用 %%xxx%% 格式 描述单词
'number' : %%[0-9]+%% ; // 为便于演示,仅处理正整数
本文按如下顺序进行:
-
手工实现四则运算
Calc的解析器CompilerCalc。 -
总结出文法的文法
Grammar。 -
手工实现文法的解析器
CompilerGrammar。 -
用
CompilerGrammar一键生成CompilerCalc。 -
用
CompilerGrammar一键生成CompilerGrammar。
练手预热——四则运算解析器CompilerCalc
从源文件内容string到单词流TokenList到语法树Node到语义结构TExtracted,是各种解析器共同的处理过程。
如果从源文件读到的内容是46*(87-19),我预想中的CompilerCalc会逐步给出如下的数据:
// 源文件内容string:
46*(87-19)
// 词法分析的结果:单词流TokenList:
T[0]='number' 46 [ln:1, col:1, i:0, L:2]
T[1]='*' * [ln:1, col:3, i:2, L:1]
T[2]='(' ( [ln:1, col:4, i:3, L:1]
T[3]='number' 87 [ln:1, col:5, i:4, L:2]
T[4]='-' - [ln:1, col:7, i:6, L:1]
T[5]='number' 19 [ln:1, col:8, i:7, L:2]
T[6]=')' ) [ln:1, col:10, i:9, L:1]
// 语法分析的结果:语法树Node:
R[2]=Additive : Multiplicative ; T[0->6]
└─R[3]=Multiplicative : Multiplicative '*' Primary ; T[0->6]
├─R[5]=Multiplicative : Primary ; T[0]
│ └─R[7]=Primary : 'number' ; T[0]
│ └─T[0]='number' 46
├─T[1]='*' *
└─R[6]=Primary : '(' Additive ')' ; T[2->6]
├─T[2]='(' (
├─R[1]=Additive : Additive '-' Multiplicative ; T[3->5]
│ ├─R[2]=Additive : Multiplicative ; T[3]
│ │ └─R[5]=Multiplicative : Primary ; T[3]
│ │ └─R[7]=Primary : 'number' ; T[3]
│ │ └─T[3]='number' 87
│ ├─T[4]='-' -
│ └─R[5]=Multiplicative : Primary ; T[5]
│ └─R[7]=Primary : 'number' ; T[5]
│ └─T[5]='number' 19
└─T[6]=')' )
// 语义分析的结果:extracted:
3128 = 46 * ( 87 - 19 )
词法分析器
我设定,用'xxx'的形式表示Token,也就是用'前后包围起来。
词法分析的原理是自动机/状态机。自动机可以用正则表达式来表示。
上文中的[0-9]+是一个正则表达式,表示“1个或多个0到9”,也就是0或正整数。Lex的主要功能就是将字符串格式的正则表达式转化为自动机,再将自动机转为等价的代码形式。
我设定,描述Token的正则表达式,用%%前后包围起来。
如果文法中的某个Token没有明示其正则表达式,那么它的字面本身就是它的正则表达式。准确来说,它的字面本身就是它的正则表达式的内容(在涉及转义字符时会有区别)。例如'+'和'(',它们隐含的正则表达式分别是%%[+]%%和%%(%%。当然,%%[+]%%可以换为%%\+%%或%%\u002B%%。
我们可以手工画出识别Calc文法的全部Token的自动机。

图中的☆代表初始状态initialState。
以图中的状态7为例:
-
对于一个没有词法错误的源文件,当词法分析器读入的
char是[0-9]中的某个时,就可以断定接下来会遇到的是一个'number'类型的Token,并进入它的终止状态7; -
之后可以继续收集此
Token的内容; -
当读到一个不属于
[0-9]的char时,会从终止状态7返回initialState。也就是说,对于每个状态A,都有一条没有被画出来的边,从状态A指向initialState;initialState本身也是如此。有的文章将这种状态称为“死状态”。有死就有生,有生就有死。死就是生,生就是死。“死状态”就是初始状态☆。
现在我们手工将此自动机转化为C#代码。
对于initialState,也就是lexicalState0:
private static readonly LexicalState lexicalState0 = new LexicalState(
new LexicalRule(/* ☆ --> 1 */
currentChar => currentChar == '+',
context => {
BeginToken(context, EType.@Plus);
ExtendToken(context);
return lexicalState1; // go to state 1
}),
new LexicalRule(/* ☆ --> 2 */
currentChar => currentChar == '-',
context => {
BeginToken(context, EType.@Dash);
ExtendToken(context);
return lexicalState2; // go to state 2
}),
new LexicalRule(/* ☆ --> 3 */
currentChar => currentChar == '*',
context => {
BeginToken(context, EType.@Asterisk);
ExtendToken(context);
return lexicalState3; // go to state 3
}),
new LexicalRule(/* ☆ --> 4 */
currentChar => currentChar == '/',
context => {
BeginToken(context, EType.@Slash);
ExtendToken(context);
return lexicalState4; // go to state 4
}),
new LexicalRule(/* ☆ --> 5 */
currentChar => currentChar == '(',
context => {
BeginToken(context, EType.@LeftParenthesis);
ExtendToken(context);
return lexicalState5; // go to state 5
}),
new LexicalRule(/* ☆ --> 6 */
currentChar => currentChar == ')',
context => {
BeginToken(context, EType.@RightParenthesis);
ExtendToken(context);
return lexicalState6; // go to state 6
}),
new LexicalRule(/* ☆ --> 7 */
currentChar => '0' <= currentChar && currentChar <= '9',
context => {
BeginToken(context, EType.@number);
ExtendToken(context);
return lexicalState7; // go to state 7
}),
new LexicalRule(/* ☆ --> ☆ */
currentChar => IsOther(currentChar),/*非以上字符*/
context => {
char c = context.CurrentChar;
if (c == ' ' || c == '\r' || c == '\n' || c == '\t' || c == '\0') { return lexicalState0; }
// default handler: unexpected char.
var token = new Token(context.Cursor, context.Line, context.Column);
token.value = c.ToString(); token.type = EType.Error;
context.result.Add(token);
return lexicalState0; // go to state 0
})
);
对于状态7:
private static readonly LexicalState lexicalState7 = new LexicalState(
new LexicalRule(/* 7 --> 7 */
currentChar => '0' <= currentChar && currentChar <= '9',
context => {
ExtendToken(context);
return lexicalState7; // go to state 7
}),
new LexicalRule(/* 7 --> ☆ */
currentChar => IsOther(currentChar),/*非数字*/
context => {
AcceptToken(context, EType.@number);
return lexicalState0; // go to state 0
})
);
自动机与代码是一一对应的。其他状态不再重述。
调用自动机的过程是所有解析器通用的,因此应当独立出一个基础类库:
public TokenList Analyze(string sourceCode) {
var context = new LexicalContext(sourceCode, this.initialState);
while (!context.EOF) {
char currentChar = context.CurrentChar;
Func<LexicalContext, LexicalState> function = context.GetFunction(currentChar);
LexicalState nextState = function(context);
context.currentState = nextState;// prepare the current state to meet with next char.
context.MoveForward();// move cursor to next char
}
// finish lexical analyzing with external char('\0').
{
char currentChar = context.CurrentChar;
Func<LexicalContext, LexicalState> function = context.GetFunction(currentChar);
LexicalState nextState = function(context);
// practically not needed.
context.currentState = nextState;// prepare the current state to meet with next char.
context.MoveForward();// move cursor to next char
}
return context.result;
}
用'\0'收尾,是一个编程处理的小技巧。在语法分析时,也会用到类似的技巧。
语法分析器
文法里都有什么
我按下图所示称呼文法中的各个部分:

回看上文预想中的语法树,可知,每个语法树的叶结点,都对应一个Token。如果按后序优先遍历的方式过一遍语法树,就可以得到依索引排列的TokenList。这说明,语法树是对TokenList的进一步组织,语法树的叶结点类型与Token类型完全重合,非叶结点类型则是自己独有的。
本文用Vt(terminal)表示叶结点,用Vn(non-terminal)表示非叶结点,用V表示两者的总和。
语法分析三大件
nullable(VList)
如果一个V可能推导出空ε,也就是说,一个Vt都没推出来,那么我们就说它是可空的,即nullable(V)=true。
如果一串V可能推导出空ε,也就是说,一个Vt都没推出来,那么我们就说它是可空的,即nullable(V1 V2 V3 ..)=true。
显然,对于任何Vt,nullable(Vt)=false。
FIRST(VList)
一个V,它能推出的第一个Vt都有谁呢?这些Vt合起来,就是FIRST(V)。
一串V,它能推出的第一个Vt都有谁呢?这些Vt合起来,就是FIRST(V1 V2 V3 ..)。
显然,FIRST(V1 V2 V3 ..)包含FIRST(V1);如果nullable(V1)=true,那么FIRST(V1 V2 V3 ..)也包含FIRST(V2);以此类推。
如果nullable(VList)=true,那么FIRST(VList)包含空ε。
FOLLOW(Vn)
在所有的Regulation中,紧跟在Vn后面的Vt都有哪些?这就是FOLLOW(Vn)。
显然,在left : 某V 某V .. Vn V1 V2 .. ;中,FOLLOW(Vn)包含FIRST(V1 V2 ..);如果FIRST(V1 V2 ..)包含空ε,那么FOLLOW(Vn)包含FOLLOW(left)。
LL(1)分析法
以下面的文法SAB为例:
S : A 'a' 's' // R[0]
| B 'b' 's' // R[1]
| 'd' ; // R[2]
A : 'a' ; // R[3]
B : 'c' // R[4]
| empty ; // R[5] empty means (ε)
对于一个没有语法错误的TokenList,如果语法分析器读入的第一个Token是'a',就可以断定应当使用R[0]展开/推导,因为在R[0]、R[1]、R[2]中,只有R[0]的FIRST(A 'a' 's')包含'a',也就是说,只有R[0]能匹配一个内容为'a' Vt1 Vt2 ..的TokenList;如果用R[1]或R[2],就不可能使第一个Vt为'a'了。
抽象化地说,只要语法分析器读入一个Token,就可以根据它的类型断定,应当使用哪个Regulation。凭什么呢?就凭对于当前结点(上例中是S)的所有Regulaion,FIRST(R[0])、FIRST(R[1])、FIRST(R[2])全都没有交集。
这就是LL(1)文法的核心思想。这与词法分析器有相似之处。
对于上面这个文法,可以用LL(1)分析法。但Calc文法不能用LL(1)分析,因为
FIRST( Additive '+' Multiplicative ) = { '(' 'number' }
FIRST( Additive '-' Multiplicative ) = { '(' 'number' }
FIRST( Multiplicative '\*' Primary ) = { '(' 'number' }
各个Regulation的FIRST集都有共同的Vt(即'('和'number')。当词法分析器读到一个'number'时,它该用哪个Regulation展开/推导呢?它不知道呀。
LR(0)分析法
以Calc的源文件46*(87-19)为例:
最初,我左手上是第一个Vn(Additive);右手上是一个没有语法错误的TokenList,也就是未来的Vt串。
我只在最抽象的程度上知道:这个Additive对应着整个TokenList(即T[0->6])。
现在,我需要让Additive具体地对应上TokenList,也就是逐步地展开/推导它,也就是具体化。
Additive有3个Regulation,每个都对应一个展开/推导的可能路线。问题是,选哪个?
从左手上看,我面对是的一个抽象的Vt串;从右手上看,我面对的是一个具体的Vt串。
从左手上看,我位于抽象的Vt串的开头;从右手上看,我位于具体的Vt串的开头。
观察左手,由于R[0]、R[1]、R[2]的存在,实际上我是位于Additive '+' Multiplicative的开头或Additive '-' Multiplicative的开头或Multiplicative的开头,也就是Additive的开头或Multiplicative的开头。这就向具体化迈进了一步。
继续观察Multiplicative,由于R[3]、R[4]、R[5]的存在,实际上我是位于Multiplicative '*' Primary的开头或Multiplicative '/' Primary的开头或Primary的开头,也就是Multiplicative的开头或Primary的开头。这就又向具体化迈进了一步。
继续观察Primary,由于R[6]、R[7]的存在,实际上我是位于'(' Additive ')'的开头或'number'的开头,也就是说,我直接面对的是'('或'number'。这就又向具体化迈进了一步。由于'('和'number'是Vt,就没有继续展开的可能了。
像用放大镜观察物体一样,我们一级一级地放大观察当前直接面对的Vn,直至没有Vn可放大。这个过程,就是求解闭包(Closure)的算法。之所以闭包中的各个项(Item)算作处于同一状态,是因为它们本来就在描述同一状态,只不过是在不同的放大级别上描述同一状态。
此时已经能够断定,我们首先面对的,只会是'('或'number'。
如果语法分析器读入的第一个Token是'(',那么可以立即断定,应当选择R[6]展开/推导。此时,我将移进(shift-in)到Primary : '(' ? Additive ')'中的?处,意思是,我读到了'(',我期待着读到Additive ')'。这提示我们,在读入第一个Token之前,我们是位于如下图所示的?处:

syntaxState0
[-1] FinalValue> : ? Additive ;
[0] Additive : ? Additive '+' Multiplicative ;
[1] Additive : ? Additive '-' Multiplicative ;
[2] Additive : ? Multiplicative ;
[3] Multiplicative : ? Multiplicative '*' Primary ;
[4] Multiplicative : ? Multiplicative '/' Primary ;
[5] Multiplicative : ? Primary ;
[6] Primary : ? '(' Additive ')' ;
[7] Primary : ? 'number' ;
图中的[-1]是为了便利编程添加的额外起始Regulation,也就是后文将介绍的扩展Regulation。
仿照上面的步骤,可以找到 Primary : '(' ? Additive ')'的闭包,也就是:

syntaxState4
[6] Primary : '(' ? Additive ')' ;
[0] Additive : ? Additive '+' Multiplicative ;
[1] Additive : ? Additive '-' Multiplicative ;
[2] Additive : ? Multiplicative ;
[3] Multiplicative : ? Multiplicative '*' Primary ;
[4] Multiplicative : ? Multiplicative '/' Primary ;
[5] Multiplicative : ? Primary ;
[6] Primary : ? '(' Additive ')' ;
[7] Primary : ? 'number' ;
如果语法分析器读入的第一个Token是'number',那么可以立即断定,应当选择R[7]展开/推导。此时,我将移进到Primary : 'number' ? ;中的?处。注意,此处是R[7]的末尾,也就是说,实际上我们已经读入了这个R[7]对应的全部Vt,那么此时就应当用R[7]进行规约(Reduction)了,也就是说,应当建造这样的树结构:
R[7]=Primary : 'number' ; T[0]
└─T[0]='number' 46
刚刚,我直接面对的是'number';现在,我直接面对的是它的上级Primary。当syntaxState0遇到Primary时,[5] Multiplicative : ? Primary ;这一放大级别诉我们,应当跳入(Goto)Multiplicative : Primary ? ;这个状态。
继续求闭包,继续移进/规约,直至没有新的syntaxState出现,LR(0)分析法的语法分析表就形成了,如下图所示。这个过程就是LR(0)分析表的构造算法。

也可以用表格表示:
| 状态 | '+' | '-' | '*' | '/' | '(' | ')' | 'number' | '¥' | Additive | Multiplicative | Primary |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | S4 | S5 | G1 | G2 | G3 | ||||||
| 1 | S6 | S7 | 完成 | ||||||||
| 2 | R[2] | R[2] | S8 R[2] | S9 R[2] | R[2] | R[2] | R[2] | R[2] | |||
| 3 | R[5] | R[5] | R[5] | R[5] | R[5] | R[5] | R[5] | R[5] | |||
| 4 | S4 | S5 | G10 | G2 | G3 | ||||||
| 5 | R[7] | R[7] | R[7] | R[7] | R[7] | R[7] | R[7] | R[7] | |||
| 6 | S4 | S5 | G11 | G3 | |||||||
| 7 | S4 | S5 | G12 | G3 | |||||||
| 8 | S4 | S5 | G13 | ||||||||
| 9 | S4 | S5 | G14 | ||||||||
| 10 | S6 | S7 | S15 | ||||||||
| 11 | R[0] | R[0] | S8 R[0] | S9 R[0] | R[0] | R[0] | R[0] | R[0] | |||
| 12 | R[1] | R[1] | S8 R[1] | S9 R[1] | R[1] | R[1] | R[1] | R[1] | |||
| 13 | R[3] | R[3] | R[3] | R[3] | R[3] | R[3] | R[3] | R[3] | |||
| 14 | R[4] | R[4] | R[4] | R[4] | R[4] | R[4] | R[4] | R[4] | |||
| 15 | R[6] | R[6] | R[6] | R[6] | R[6] | R[6] | R[6] | R[6] |
其中的第一行0和列'('对应的内容为S4,表示在状态0读到'('类型的Vt时,应当移进并进入状态4。
其中的第一行0和列Additive对应的内容为G1,表示在状态0遇到Additive类型的Vn时,应当跳入状态1。
其中的第三行2和列'+'对应的内容为R[2],表示在状态2遇到'+'类型的Vt时,应当用R[2]规约。
其中的列'¥'表示额外的结束符,其作用类似词法分析中最后额外添加的文件结束符'\0'。读到此Vt就表示整个TokenList已读完。
从表格中可以看到,有的状态下,既可以移进,也可以规约。这是语法冲突。这说明Calc不能用LR(0)分析法。
例如,用Calc解析123+456*789:
读入'number':从状态0移进到状态5;
状态5规约:Primary : 'number' ;,回到状态0;
从状态0跳入状态3;
状态3规约:Multiplicative : Primary ;,回到状态0;
从状态0跳入状态2;
状态2规约:Additive : Multiplicative ;,回到状态0;
从状态0跳入状态1;
读入'+':从状态1移进到状态6;
读入'number':从状态6移进到状态5;
状态5规约:Primary : 'number' ;,回到状态6;
从状态6跳入状态3;
状态3规约:Multiplicative : Primary ;,回到状态6;
从状态6跳入状态11;★★★
读入'*':从状态11移进到状态8;
读入'number':从状态8移进到状态5;
状态5规约:Primary : 'number' ;,回到状态8;
从状态8跳入状态13
状态13规约:Multiplicative : Multiplicative '*' Primary ;,回到状态6;
从状态6跳入状态11
状态11规约:Additive : Additive '+' Multiplicative ;,回到状态0;
从状态0跳入状态1
完成,回到状态0
注意上面标★★★的位置,状态11应当移进下一个Vt呢还是规约成Additive并回到状态0呢?
如果规约,那么就是先计算123+456后与789相乘了,其含义就变成了(123+456)*789。作为人类,我们知道此时应当移进;但作为计算机,它是没有这种认知的。计算机是没有任何认知的。
有冲突的位置不止这一个,读者可以自行寻找。
读者可以尝试下面的例子,看看能否用LR(0)分析法。适量的练习是快速理解复杂内容的不二法门。
A : A '+' B // [0]
| 'a' ; // [1]
B : 'b' ; // [2]
完成练习后,可以在(https://www.cnblogs.com/bitzhuwei/p/ABB-readme-full.html#_lab2_1_4)查看答案。
SLR(1)分析法
继续上面的例子,如果456后面跟的是'*',那么就应当移进,如果是'+',那么就应当规约。
理论化地说,在Calc文法中,当?位于Additive : Additive '+' Multiplicative ? ;状态,只有?后面紧跟的是FOLLOW(Addtive)中的Token类型时,才有可能“状态11应当用R[0]规约”,否则就不可能。
这就是SLR(1)的核心思想,也是SLR(1)与LR(0)的唯一区别。S代表simple。
这样,就可以减少一些R[n]的出现。Calc文法的SLR(1)分析表如下:
| 状态 | '+' | '-' | '*' | '/' | '(' | ')' | 'number' | '¥' | Additive | Multiplicative | Primary |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | S4 | S5 | G1 | G2 | G3 | ||||||
| 1 | S6 | S7 | 完成 | ||||||||
| 2 | R[2] | R[2] | S8 | S9 | R[2] | R[2] | |||||
| 3 | R[5] | R[5] | R[5] | R[5] | R[5] | ||||||
| 4 | S4 | S5 | G10 | G2 | G3 | ||||||
| 5 | R[7] | R[7] | R[7] | R[7] | R[7] | ||||||
| 6 | S4 | S5 | G11 | G3 | |||||||
| 7 | S4 | S5 | G12 | G3 | |||||||
| 8 | S4 | S5 | G13 | ||||||||
| 9 | S4 | S5 | G14 | ||||||||
| 10 | S6 | S7 | S15 | ||||||||
| 11 | R[0] | R[0] | S8 | S9 | R[0] | R[0] | |||||
| 12 | R[1] | R[1] | S8 | S9 | R[1] | R[1] | |||||
| 13 | R[3] | R[3] | R[3] | R[3] | R[3] | ||||||
| 14 | R[4] | R[4] | R[4] | R[4] | R[4] | ||||||
| 15 | R[6] | R[6] | R[6] | R[6] | R[6] |
可以发现,此表中没有冲突了。这说明Calc是可以用SLR(1)方法分析的。
LR(1)分析法
对于下面的文法,SLR(1)分析表仍然有冲突:
// GrammarName = Assignment
// ExtractedType = Assignment2
S : L '=' R | R ;
L : '*' R | 'id' ;
R : L ;
这是描述C语言中常见的a = *p或*p = x或*p = **d语句的文法部分。
它的SLR(1)分析表如下:
| 状态 | '=' | '*' | 'id' | '¥' | S | L | R |
|---|---|---|---|---|---|---|---|
| 0 | S4 | S5 | G1 | G2 | G3 | ||
| 1 | 完成 | ||||||
| 2 | S6 R[4] | ||||||
| 3 | R[1] | ||||||
| 4 | S4 | S5 | G8 | G7 | |||
| 5 | R[3] | ||||||
| 6 | S4 | S5 | G8 | G9 | |||
| 7 | R[2] | ||||||
| 8 | R[4] | ||||||
| 9 | R[0] |
如表所示,在状态2遇到'='时,仍旧存在冲突。
它的状态图如下:

如图所示,在状态2遇到'='时,既可以按R[4]规约,又可以移进到状态6。SLR(1)分析法无力解决这个冲突。
我们需要更细腻的分析法。
在认识LR(0)的闭包时,我们用放大镜一级一级地展开?后面的Vn,但我们没有管过:我们所在的Regulation对应的Vt串,紧跟着它的下一个Vt可能是什么类型,可能是这个文法的所有Vt类型吗?
当然不可能是。既然如此,我们应当在求解闭包的时候,把这个后面紧跟着的Token类型记录下来。这个后面紧跟着的Token类型,被称为lookAhead。这样,当?位于某个Regulation的末尾,只有?后面是lookAhead时,才应当规约。
这就是LR(1)分析法的核心思想。在求解闭包时,除了像LR(0)一样的操作外,还记录了各个Regulation后面跟随的Vt类型。这就是LR(1)与LR(0)的区别。
SLR(1)粗放地做了LR(1)的工作,因而适用范围比LR(0)广,比LR(1)窄。
上面的Assignment文法的LR(1)分析表如下:
| 状态 | '=' | '*' | 'id' | '¥' | S | L | R |
|---|---|---|---|---|---|---|---|
| 0 | S4 | S5 | G1 | G2 | G3 | ||
| 1 | 完成 | ||||||
| 2 | S6 | R[4] | |||||
| 3 | R[1] | ||||||
| 4 | S4 | S5 | G8 | G7 | |||
| 5 | R[3] | R[3] | |||||
| 6 | S11 | S12 | G10 | G9 | |||
| 7 | R[2] | R[2] | |||||
| 8 | R[4] | R[4] | |||||
| 9 | R[0] | ||||||
| 10 | R[4] | ||||||
| 11 | S11 | S12 | G10 | G13 | |||
| 12 | R[3] | ||||||
| 13 | R[2] |
此表中就没有冲突了,但状态数量也增加了。它的状态图如下:

LR(1)分析法是我实现的适用范围最广的语法分析法。
LALR(1)分析法
LR(1)状态的每个Item,都由Regulaiton、?的位置、跟随的Vt(即lookAhead)这三条数据组成,其信息详尽,优点是适用范围广,缺点是它的状态非常多,状态包含的Item也非常多。在我处理GLSL Shader文法的时候,常常见到包含上万个Item的LR(1)状态。
两个LR(1)状态的Item,如果它们的Regulaiton相同、?的位置相同、只有lookAhead不同,我们也将这两个Item视为相同。这就可以合并一些状态。这样,虽然在有的文法里会产生冲突,但状态的数量会大大减少。
这就是LALR(1)分析法的核心思想。很多程序语言,都可以用LALR(1)分析法进行语法分析。因此,它是很实用的优化技巧。
我们的Calc文法,可以用LALR(1)分析。它的LALR(1)分析表如下:
| 状态 | '+' | '-' | '*' | '/' | '(' | ')' | 'number' | '¥' | Additive | Multiplicative | Primary |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | S4 | S5 | G1 | G2 | G3 | ||||||
| 1 | S6 | S7 | 完成 | ||||||||
| 2 | R[2] | R[2] | S8 | S9 | R[2] | R[2] | |||||
| 3 | R[5] | R[5] | R[5] | R[5] | R[5] | R[5] | |||||
| 4 | S4 | S5 | G10 | G2 | G3 | ||||||
| 5 | R[7] | R[7] | R[7] | R[7] | R[7] | R[7] | |||||
| 6 | S4 | S5 | G11 | G3 | |||||||
| 7 | S4 | S5 | G12 | G3 | |||||||
| 8 | S4 | S5 | G13 | ||||||||
| 9 | S4 | S5 | G14 | ||||||||
| 10 | S6 | S7 | S15 | ||||||||
| 11 | R[0] | R[0] | S8 | S9 | R[0] | R[0] | |||||
| 12 | R[1] | R[1] | S8 | S9 | R[1] | R[1] | |||||
| 13 | R[3] | R[3] | R[3] | R[3] | R[3] | R[3] | |||||
| 14 | R[4] | R[4] | R[4] | R[4] | R[4] | R[4] | |||||
| 15 | R[6] | R[6] | R[6] | R[6] | R[6] | R[6] |
它的LALR(1)状态图如下:

下面的文法用LALR(1)分析,就会产生冲突:
// GrammarName = LALR1Error
// ExtractedType = LALR1Error2
S : 'a' A 'd' | 'b' B 'd' | 'a' B 'e' | 'b' A 'e' ;
A : 'c' ;
B : 'c' ;
它的分析表如下:
| 状态 | 'a' | 'd' | 'b' | 'e' | 'c' | '¥' | S | A | B |
|---|---|---|---|---|---|---|---|---|---|
| 0 | S2 | S3 | G1 | ||||||
| 1 | 完成 | ||||||||
| 2 | S6 | G4 | G5 | ||||||
| 3 | S6 | G8 | G7 | ||||||
| 4 | S9 | ||||||||
| 5 | S10 | ||||||||
| 6 | R[4] R[5] | R[5] R[4] | |||||||
| 7 | S11 | ||||||||
| 8 | S12 | ||||||||
| 9 | R[0] | ||||||||
| 10 | R[2] | ||||||||
| 11 | R[1] | ||||||||
| 12 | R[3] |
在分析表中可以看到,状态6在遇到'd'或'e'时有冲突。
它的状态图如下:

在状态图中也可以看到,状态6在遇到'd'或'e'时可以按R[4]或R[5]进行规约。那到底是按R[4]规约还是按R[5]规约呢?它不知道呀。
LR分析法小结
从LR(0)到SLR(1)到LALR(1)到LR(1),能够解析的文法范围逐步扩大,每一个分析法能解析的文法,都是后一个的真子集。
Calc文法一键生成解析器相关的数据,可见于(https://www.cnblogs.com/bitzhuwei/p/Calc-readme-full.html)。
语义分析器
前文提过,如果按后序优先遍历的方式过一遍语法树,就可以得到依索引排列的TokenList。我们想知道46*(87-19)的算术结果是多少,这可以通过按后序优先遍历的顺序对各个V分别执行相应的操作来实现。相应的操作,反映到代码上,就是针对每种V都设计一个delegate。
每个Vt的操作都是一样的:将它的Token入栈,供上级使用。
private static readonly Action<Node, TContext<FinalValue>> VtHandler =
(node, context) => {
var token = context.tokens[node.tokenIndex];
context.objStack.Push(token);
};
对Multiplicative : Multiplicative '*' Primary这个Regulation来说,栈里会有3个对象,分别出栈,执行乘法计算,将结果入栈即可。其它Vn的思路相同,不再重述。
// 3: Multiplicative : Multiplicative '*' Primary ;
var primary0 = context.objStack.Pop() as Primary;
var asterisk1 = context.objStack.Pop() as Token;
var multiplicative2 = context.objStack.Pop() as Multiplicative;
var multiplicative = new Multiplicative(multiplicative2.value * primary0.value);
context.objStack.Push(multiplicative);
后序优先遍历的递归版如下:
public void PostOrderRecursion(Node node)
{
for (int i = 0; i < node.Children.Count; i++)
{
PostOrderRecursion(node.Children[i]);
}
Visit(node);
}
private void Visit(Node node) {
// do something.
}
后序优先遍历的非递归版如下:
public void PostOrder(Node rootNode) {
// post-order traverse rootNode with stack(without recursion).
var nodeStack = new Stack<Node>();
var indexStack = new Stack<int>();
// init stack.
{
// push nextLeft and its next pending children.
var nextLeft = rootNode;
nodeStack.Push(nextLeft); indexStack.Push(0);
while (nextLeft.Children.Count > 0) {
nextLeft = nextLeft.Children[0];
nodeStack.Push(nextLeft);
indexStack.Push(0);
}
}
while (nodeStack.Count > 0) {
var current = nodeStack.Pop();
var index = indexStack.Pop() + 1;
if (index < current.Children.Count) {
// push this node back again.
nodeStack.Push(current); indexStack.Push(index);
// push nextLeft and its next pending children.
var nextLeft = current.Children[index];
nodeStack.Push(nextLeft); indexStack.Push(0);
while (nextLeft.Children.Count > 0) {
nextLeft = nextLeft.Children[0];
nodeStack.Push(nextLeft);
indexStack.Push(0);
}
}
else {
Visit(current);
}
}
}
private void Visit(Node node) {
// do something.
}
其它
手工编写词法分析器和语法分析器是简单而枯燥的。如果文法比较复杂,那么工作量也会大增,很容易写错。下面我们来实现解析器的一键生成功能。
读者可以预先看看Calc一键生成的各种数据结构(nullable、FIRST、FOLLOW、词法分析表、语法分析表等)(https://www.cnblogs.com/bitzhuwei/p/Calc-readme-full.html)。
进入正题——文法解析器CompilerGrammar
读者可在下述链接(https://www.cnblogs.com/bitzhuwei/p/some-grammars.html)中找到一些文法的例子。
经过一些练习,我们可以用文法来描述文法:
// GrammarName = Grammar
// ExtractedType = GrammarDraft
StatementList : StatementList Statement | Statement ;
Statement : SyntaxProduction | LexiProduction ;
SyntaxProduction : 'Vn' ':' CandidateList ';' ;
CandidateList : CandidateList '|' Candidate | Candidate ;
Candidate : VList | 'empty' ;
VList : VList V | V ;
V : 'Vn' | 'Vt' ;
LexiProduction : 'Vt' ':' 'pattern' ';' ;
// 3 VtPatterns:
'Vn' : %%[a-zA-Z_][a-zA-Z0-9_]*%% ;
'Vt' : %%'([ -&]|\\'|[(-\[]|\\\\|[\]-~])+'%% ;
'pattern' : %%[%]{2}[ -~]([^%]|%[^%])*[%]{2}%% ;
我们可以照葫芦画瓢,借助写CompilerCalc的经验,得到Grammar的数据结构GrammarDraft。对GrammarDraft进行一系列算法操作,就可以得到任意文法的解析器了。
一键生成词法分析器
词法分析器,需要生成的是自动机对应的代码。自动机在文法中是用%%xxx%%里的正则表达式描述的。我们要做的,就是把string格式的正则表达式,转化为Automaton数据结构,最后转化为C#代码。
正则表达式也是一门程序语言,应当用文法描述和解析。这里需要解析的正则表达式格式如下:
// something(xxx) between %%xxx%%
// GrammarName=Pattern
// ExtractedType=TokenDraft
// VnRegulations:
Pattern : PreRegex Regex PostRegex ;
PreRegex : 'refVt' | empty ;
PostRegex : '/' Regex | empty ;
Regex : Regex '|' Bunch | Bunch;
Bunch : Bunch Unit | Unit ;
Unit : 'char' Repeat | '.' Repeat | 'scope' Repeat | '(' Regex ')' Repeat ;
Repeat : '?' | '+' | '*' | '{' 'min' UpperBound '}' | empty ;
UpperBound : ',' 'max' | ',' | empty ;
// VtRegex:
'refVt' : %%\<'([ -&]|\\'|[(-\[]|\\\\|[\]-~])+'\>%% ; // start with <' and end with '>
'min' : %%<'{'>[0-9]+%% ;
'max' : %%<','>[0-9]+%% ;
// 'char' is a letter or an escape
'char' : %%[ !"#%&',]|-|[0-9:;<=>@A-Z_`a-z~]|\\[$()*+]|\\-|\\[./<>?]|\\\[|\\\\|\\\]|\\\^|\\\{|\\\||\\\}|\\u[0-9a-fA-F]{4}%% ;
//'scope' : %%\[((firstLetter1)(char)*|\^(firstLetter2)(char)*)\]%% ; // a-z or A-Z or ...
//firstLetter1 = \\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\[|\\\\|]|\\\^|[_-~]
//firstLetter2 = \\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\[|\\\\|]|\^|\\\^|[_-~]
//char = \\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\\\[|\\\\|\\\]|\^|\\\^|[_-~]
'scope' : %%\[((\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\[|\\\\|]|\\\^|[_-~])(\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\\\[|\\\\|\\\]|\^|\\\^|[_-~])*|\^(\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\[|\\\\|]|\^|\\\^|[_-~])(\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\\\[|\\\\|\\\]|\^|\\\^|[_-~])*)\]%% ; // a-z or A-Z or ...
这个文法看起来吓人,实际上用手工实现也不困难,只是需要耐心和细心。
Lex用前缀和后缀增强了描述自动机的能力,它使用的已经不是纯粹的正则表达式(regex)了,而是<'xxx'>regex/post-regex。因此,我将此文法称为Pattern而不是Regex。我认为这个增强的功能很有必要,且其实现并不特别困难,所以这里也实现了它。
前缀<'xxx'>
前缀能起到这样的作用:在识别了一个'xxx'类型的Token后,应当将后续的regex认定为某个类型。
例如,'min' : %%<'{'>[0-9]+%% ;的意思是,在识别了一个'{'后,应当将后续的数值认定为一个'min'。而'max' : %%<','>[0-9]+%% ;的意思是,在识别了一个','后,应当将后续的数值认定为一个'max'。这样,同样的内容就能够在不同的前缀下被认定为不同的类型了。这大大有利于后续的语法分析。
此功能的实现,就是将[0-9]+的自动机的开头链接到'{'或','的自动机的末尾。
后缀/post-regex
后缀能起到这样的作用:在识别了一个post-regex之后,才将'/'前面的regex认定为某个类型。
例如,下述文法:
Item : 'entityId' '=' 'refEntity' ;
'entityId' : %%[A-Za-z_][A-Za-z0-9_]*/=%% ;
'refEntity' : %%[A-Za-z_][A-Za-z0-9_]*%% ;
只有识别了一个'='的时候,才会将前面的标识符认定为'entityId'。也就是说,像平时一样记录Token的起始位置和长度,但直到读到了'='才设置Token的类型。
此功能的实现,就是将post-regex(/后面的regex)链接到regex末尾。
从string到Automaton,需要经历string => ε-NFA => NFA => DFA => MiniDFA的过程。
ε-NFA
为了链接regex内部和外部各种结构,我们先用空ε边把它们链接起来。空ε边就是不需要读入任何char就可以跳转过去的边。有空ε边的自动机,我们称为ε-NFA。
Calc文法的ε-NFA如下图所示:

NFA
现在,我们设法去掉空ε边,也就是将ε-NFA转换为NFA。
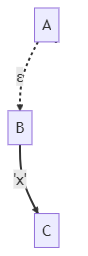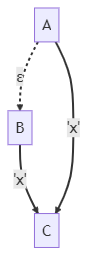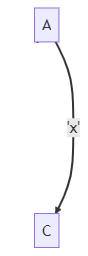
算法思想如下:如上图所示,A可以通过空ε边到达B,B可以通过'x'到达C。这说明,A也可以通过'x'到达C。也就是说,隐含着一条A-'x'->C的边。
我们将此边建立起来,使它不再隐式存在,而是显式存在。
这样,就不需要继续保持原来的空ε边了。因为空ε边的意义,就是隐式的表明A-'x'->C边的存在,再无其他。
为了去掉空ε边,我们只需遍历此图的各个结点N,当从N走出去的边为空ε边时,直接忽略它,不去遍历它指向的结点。这样,将全部被遍历到的结点及其非空ε边收集起来,就是不含空ε边的NFA了。
将Calc文法的ε-NFA隐含的边都显示出来,如下图所示:

将Calc文法的ε-NFA的空ε边都去掉,得到的NFA如下图所示:

DFA
如果既需要识别整数[0-9]+,又需要识别浮点数[0-9]+[.][0-9]+,那么当词法分析器读入的char是[0-9]中的一个时,就无法判断接下来会遇到的是什么类型的Token了,这怎么办?
理论化的说,如果一个自动机里的状态A,存在A-'x'->C和A-'x'->D这样的两个边,那么,状态A读到'x'时,就不知道该跳转到状态C还是状态D了。
将NFA转化为DFA,就是为了去掉这样的边。不含这样的边的NFA,就成了DFA。这个过程被称为确定化。
算法(子集法)思想如下:
-
假设,
状态A,存在A-'x'->C和A-'x'->D这样的两个边。那好,状态A构成一个新状态X{A},状态C和状态D合起来构成一个新状态Y{C,D},X{A}-'x'->Y{C,D}。我们可以说状态C和状态D组成了一个小家庭,住进了它们的小房子Y{C,D},它们共享一切;状态A是单身汉,自己住一套小房子X{A}。状态C和状态D的任何边,都是Y{C,D}的边,都是这个小家庭的边。状态A的任何边,都是X{A}的边,都是这个独居户的边。 -
继续假设,
状态A,存在A-'t'->D和A-'t'->E这样的两个边。类似上一步,状态A组成新状态X{A},状态D和状态E合起来构成一个新状态Z{D,E},X{A}-'t'->Z{D,E}。我们可以说状态D和状态E组成了一个小家庭,住进了它们的小房子Z{D,E},它们共享一切;状态A是单身汉,自己住一套小房子X{A}。状态D和状态E的任何边,都是Z{D,E}的边,都是这个小家庭的边。状态A的任何边,都是X{A}的边,都是这个独居户的边。 -
注意,
状态D同时参与了小房子Y{C,D}和小房子Z{D,E}的构建,它脚踏两只船。在人间,这是被批判的;在自动机,这是很普遍的,而且是可以脚踏好多船的。 -
全部小房子就是DFA的状态,小房子之间的边就是DFA状态的边。
一个小房子里,任何一个NFA状态都可能住进去,也可能不住进去,仅此两种可能。如果NFA有10个状态,那么,可能的小家庭就有2^10-1=1023种(10个人都不住进去,就空了)。这说明,从有n个状态的NFA转换为DFA,此DFA最多可能有2^n-1个状态。
Calc文法的DFA如下图所示:
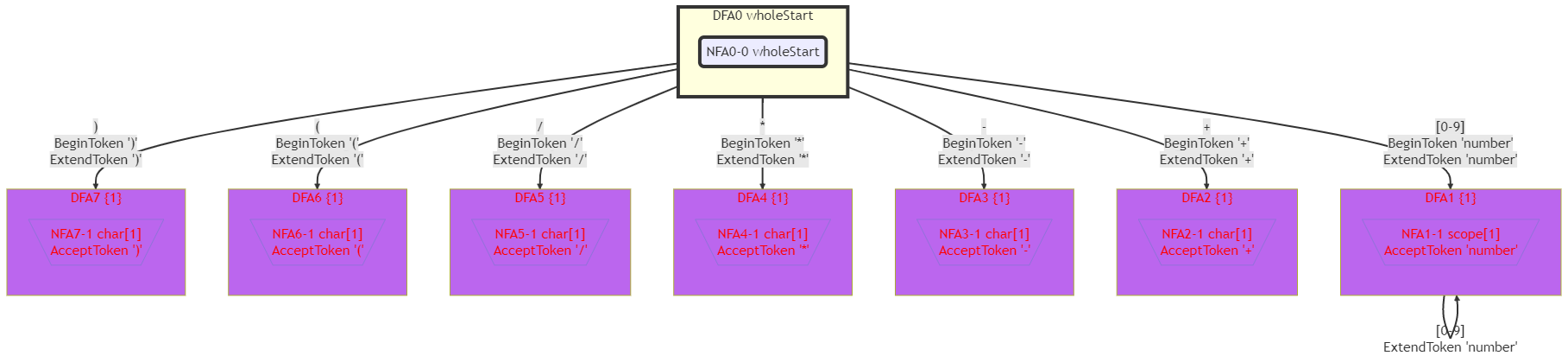
可见,每个DFA小房子里都只有1个NFA。如果不如此详细地绘制包含的NFA,那么DFA如下图所示:

如果每个DFA小房子里都只有1个NFA,说明那个NFA本身就已经是DFA了。
为了直观展示NFA与DFA的区别,这里再举一个文法的例子:
// GrammarName = Scope
// ExtractedType = ResolvedScope
Scope : '[' 'firstItem1' RangeItems ']' ;
Scope : '[^' 'firstItem2' RangeItems ']' ;
Scope : '[' 'firstItem1' ']' ;
Scope : '[^' 'firstItem2' ']' ;
RangeItems : RangeItems RangeItem | RangeItem ;
RangeItem : 'char' ;
// \uNNNN \t \n \r 口 ! " # $ % & '
// ( ) * + , - . /
// 0 1 2 3 4 5 6 7 8 9
// : ; < = > ? @
// A B C D E F G H I J K L M
// N O P Q R S T U V W X Y Z
// [ \ ] ^ _ `
// a b c d e f g h i j k l m
// n o p q r s t u v w x y z
// { | } ~
// escape: \ ^
'firstItem1' : %%<'['>\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\[|\\\\|]|\\\^|[_-~]%% ;
// escape: \
'firstItem2' : %%<'[^'>\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\[|\\\\|]|\^|\\\^|[_-~]%% ;
// escape: [ \ ]
'char' : %%\\u[0-9]{4}|\\t|\\n|\\r|\\-|[ -Z]|\\\[|\\\\|\\\]|\^|\\\^|[_-~]%% ;
这个Scope文法,是为了解析正则表达式中的[xxx]结构而作的。当然,我们可以把这个文法融入Pattern文法中,还可以再把Pattern文法融入Grammar文法中。但那样的文法太庞大,不易维护。
读者可以在(https://www.cnblogs.com/bitzhuwei/p/Scope-readme-full.html)浏览直接用Mermaid展示的详情。
这个Scope文法的ε-NFA如下图所示:
由于显式的ε-NFA太庞大,Mermaid渲染器拒绝了渲染:

这个Scope文法的NFA如下图所示:

这个Scope文法的DFA如下图所示:
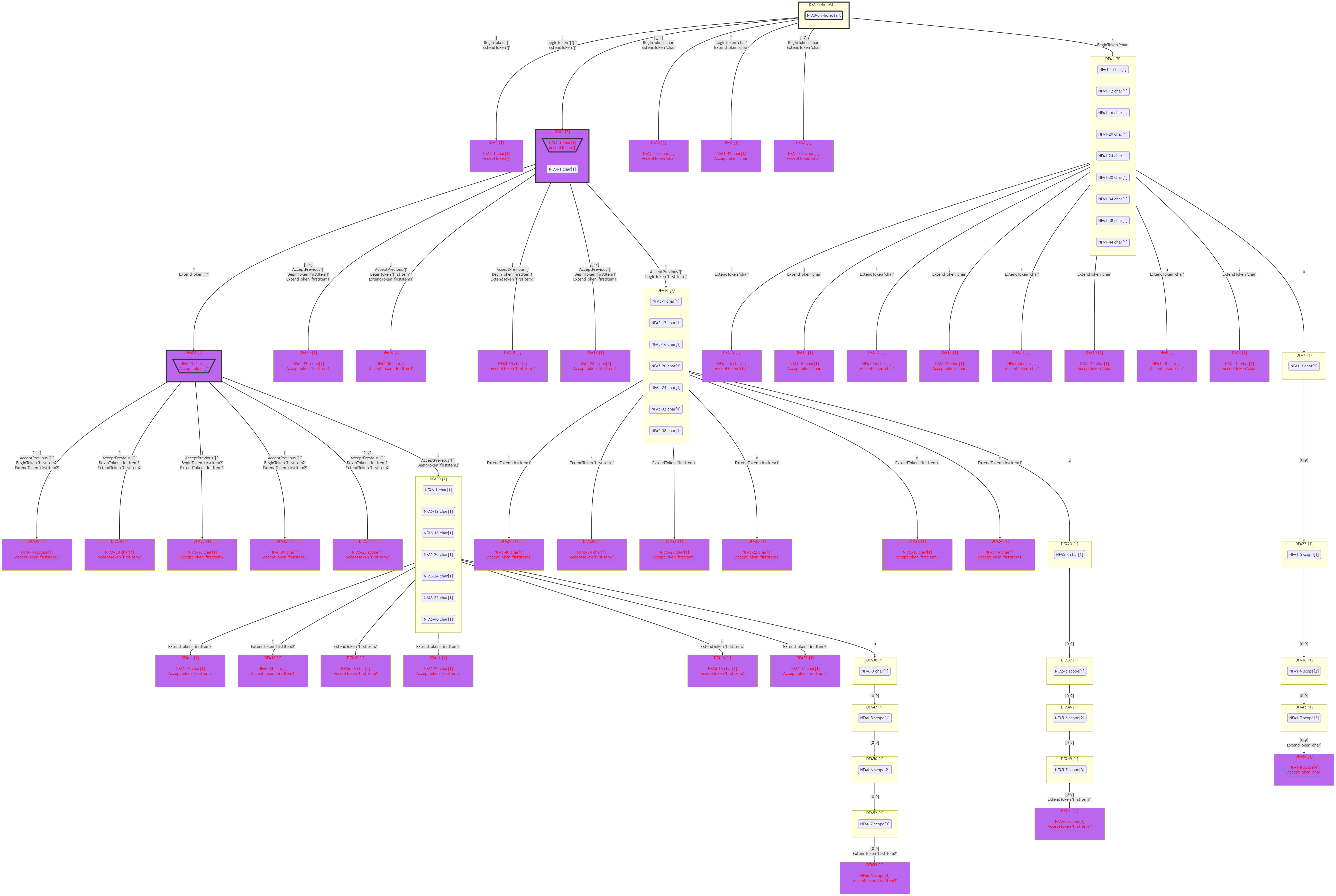
可见,有的DFA小房子里包含多个NFA状态。会出现这种情况,是因为存在[和[^这样的含有相同的开头的Token类型。可惜这个例子里没有出现脚踏两只船的情况。
这个Scope文法的DFA(简化显示)如下图所示:
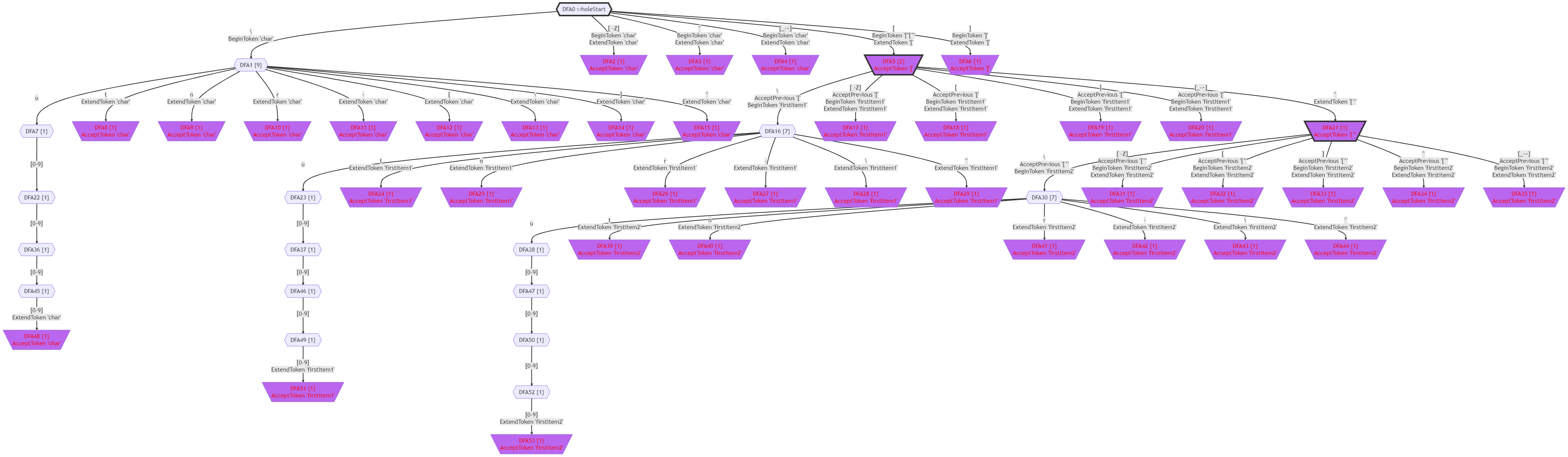
下面这个文法的DFA里出现了脚踏两只船的情况:
// 1 VnRegulations:
PreRegex : 'refVt' ; // [0]
// 1 VtPatterns:
'refVt' : %%(\\|[Y-\\])+%% ; // [0]
这个文法实际上是Pattern的一小部分,当时的'refVt'我写错了,却恰好见到了脚踏两只船的情况。
这个文法的ε-NFA如下图所示:
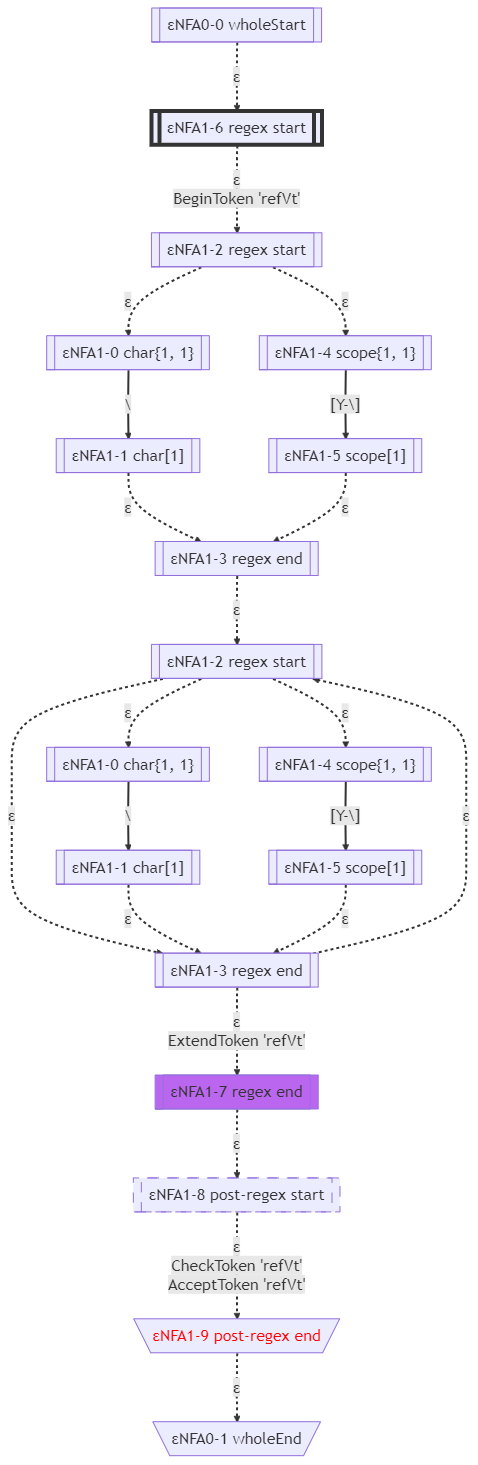
这个文法的显式的ε-NFA如下图所示:
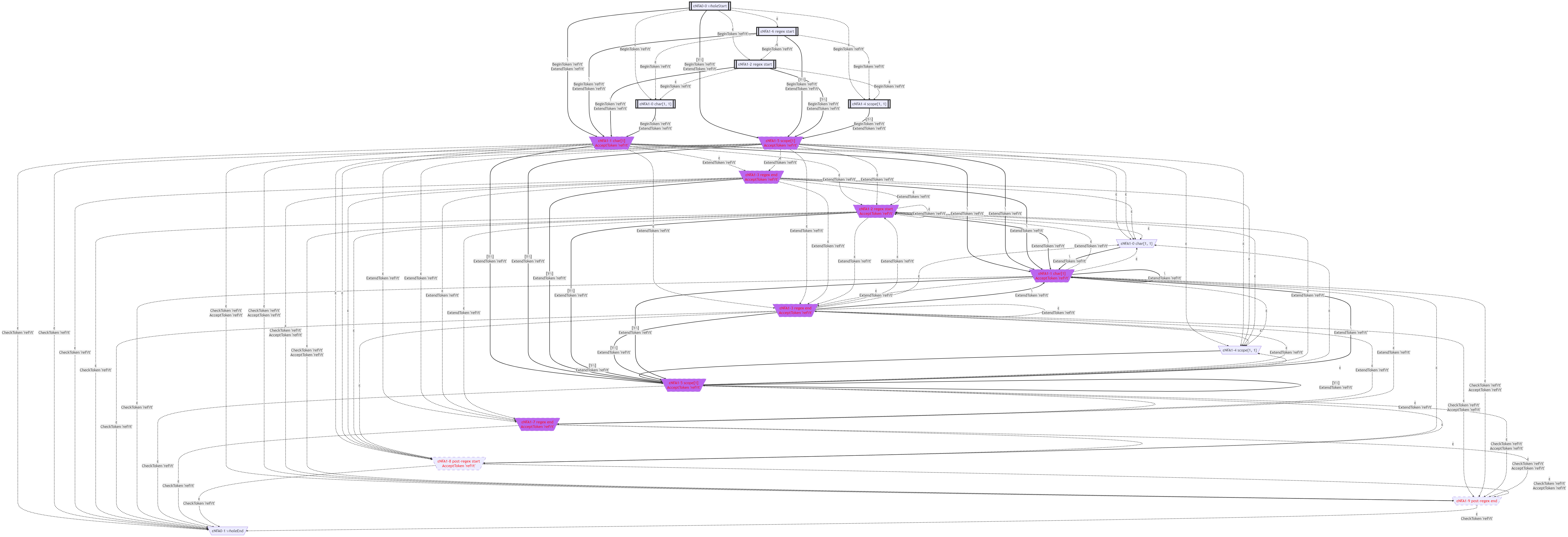
这个文法的NFA如下图所示:
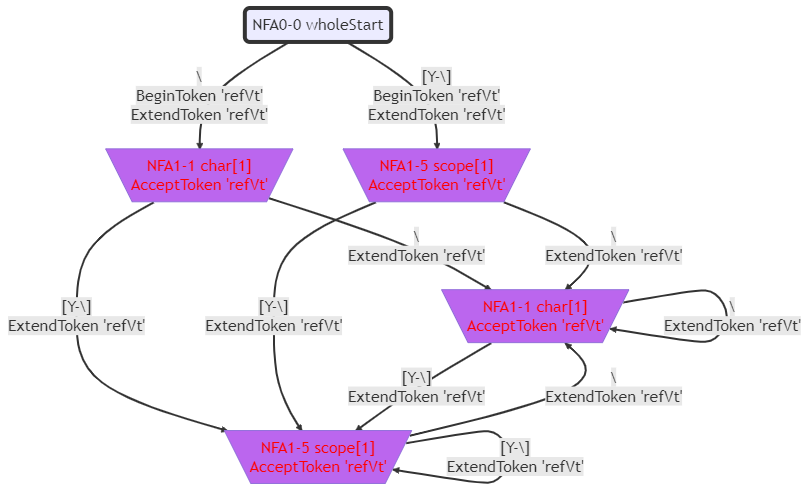
这个文法的DFA如下图所示:
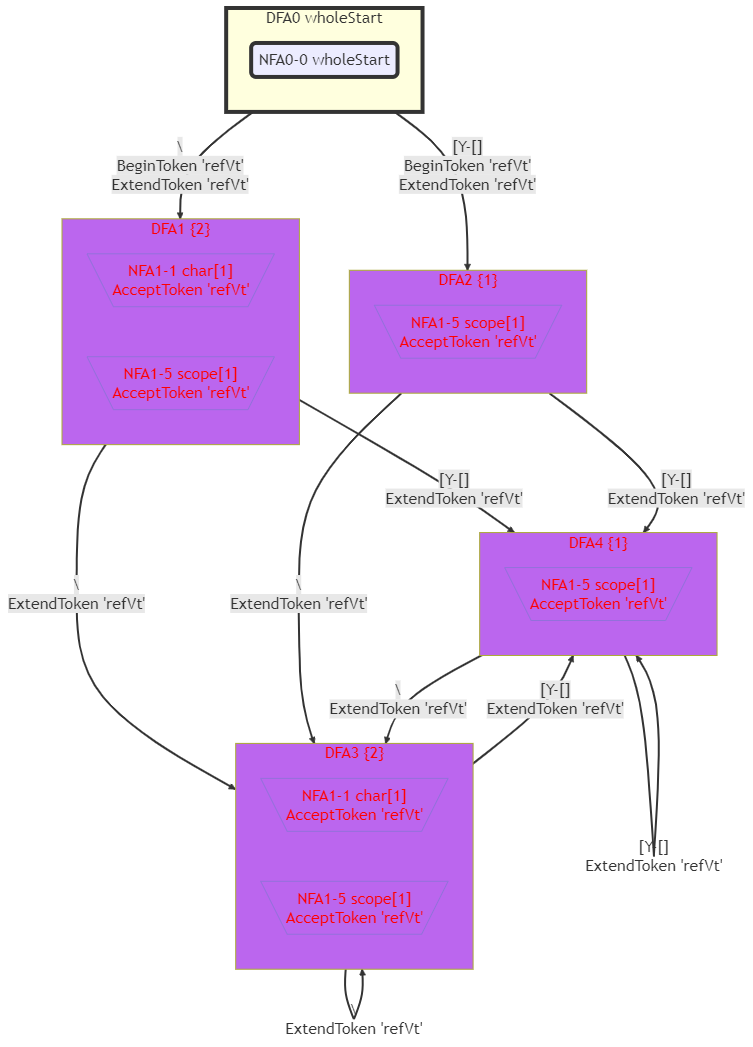
MiniDFA
有了DFA,就可以将其转换为C#代码了。但DFA还有减少状态的可能。将DFA的状态减至最少,它转换出的C#代码也会占用更少的内存,有利于提升效率。这种可能的最少状态的DFA,我们称为MiniDFA。
算法(Hopcroft)思想如下:
-
将终态放到同一个小房子(集合),非终态放到另一个小房子(集合)。哪些是终态呢?能够认定一个
Token的状态,就是终态,否则就是非终态。 -
同一个小房子里的
DFA状态A和DFA状态B,如果它们在经过某个'x'时,DFA状态A指向了一个小房子,DFA状态B指向了另一个小房子,就说明它们不等价,它们应当被放到不同的小房子里;如果它们在经过ASCII码中每一个char时,指向的小房子都相同,就说明它们等价,它们应当被放到相同的小房子里。例如,如果它们在经过'\0'-'P'这些char时,都指向小房子M;它们在经过'Q'-'~'这些char时,都指向小房子N,就说明它们等价。 -
所有的小房子构成
MiniDFA状态,小房子中各个DFA状态之间的边就是MiniDFA状态的边。
MiniDFA的小房子与DFA的小房子不同:一个DFA状态,只会住进一个MiniDFA的小房子里,不会出现脚踩两只船的情况。
Calc文法的MiniDFA如下图所示:
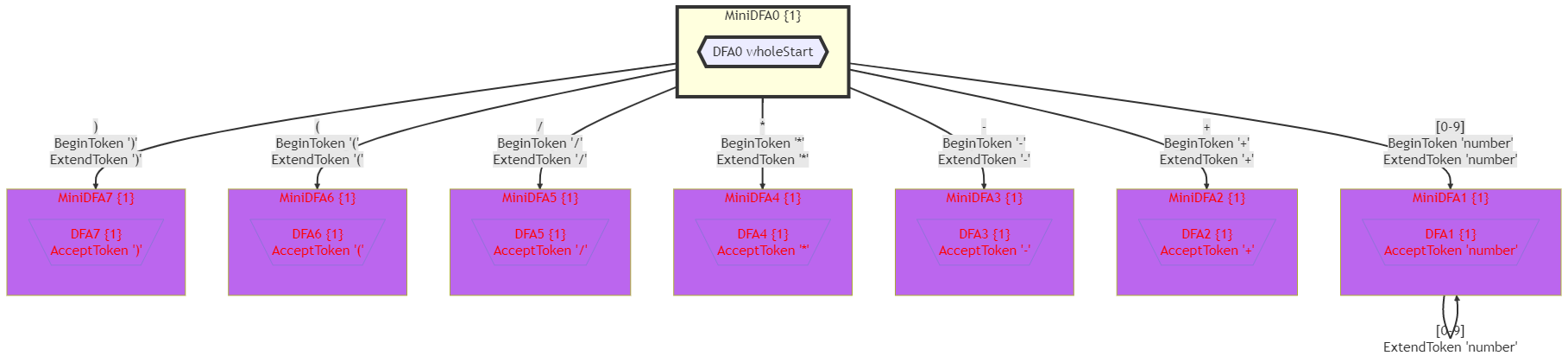
如果不详细地显示包含的DFA,那么MiniDFA如下图所示:

MiniDFA在Calc文法中没有显示出明显的作用。在Pattern文法中,它能够将词法分析器状态从611个DFA状态降低到86个MiniDFA状态。
一键生成语法分析器
上文运用LL(1)、LR(0)、SLR(1)、LALR(1)、LR(1)分析法的过程,就是手工执行算法的过程。将此过程整理成代码,就是一键生成语法分析器的功能。
计算nullable(VList)
算法思想:
-
全部
Vt都是不可空的,即nullable(Vt)=false。 -
先假设全部
Vn也都是不可空的,即nullable(Vn)=false。 -
如果有
Vn : empty ;这样的Regulation,那么nullable(Vn)=true。 -
对于
Vn : V1 V2 V3 .. ;这样的Regulation,如果nullable(V1 V2 V3 ..)=true,那么nullable(Vn)=true。 -
迭代到不动点。
public static Dictionary<string, bool> GetNullableDict(this VnRegulationDraft[] vnRegulations) {
var nullableDict = new Dictionary<string/*Node.type*/, bool>();
// allocate space for all kinds of nodes(Vt and Vn, no empty).
var allNodeTypes = vnRegulations.GetNodes();
foreach (var item in allNodeTypes) {
nullableDict.Add(item, false);
}
nullableDict.Add(string.Empty, true);
// iterate untill not changed.
bool changed = false;
do {
changed = false;
foreach (var regulation in vnRegulations) {
// 如果regulation.right可推导出empty,就说明regulation.left可推导出empty。
// if regulation.right can refer to 'empty',
// then regulation.left, too.
if (CanBeEmpty(regulation.Right, nullableDict)) {
var left = regulation.left;
if (!nullableDict[left]) {
nullableDict[left] = true;
changed = true;
}
}
}
} while (changed);
return nullableDict;
}
计算FIRST(VList)
算法思想:
-
对于全部
Vt都有:FIRST(Vt)={ Vt }。 -
对于全部
Vn都有:若nullable(Vn)=true,则FIRST(Vn)包含空ε。 -
对于
Vn : V1 V2 V3 .. ;这样的Regulation:FIRST(Vn)包含FIRST(V1);若nullable(V1)=true,则FIRST(Vn)还包含FIRST(V2);若nullable(V1 V2)=true,则FIRST(Vn)还包含FIRST(V3);以此类推。 -
迭代到不动点。
private static Dictionary<string, FIRST> GetFIRSTDict4Node(this VnRegulationDraft[] regulations, Dictionary<string, bool> nullableDict) {
var result = new Dictionary<string/*V*/, FIRST>();
var empty = "empty"; /* ε */
// allocate space for all single nodes.
// 初始化FIRST(Vn)
foreach (var Vn in regulations.GetVnNodes()) {
if (nullableDict[Vn]) {
var first = new FIRST(Vn, empty);
result.Add(Vn, first);
}
else {
var first = new FIRST(Vn);
result.Add(Vn, first);
}
}
// 初始化FIRST(Vt)(FIRST(Vt)实际上已经完工)
foreach (var Vt in regulations.GetVtNodes()) {
var first = new FIRST(Vt, Vt);
result.Add(Vt, first);
}
bool changed = false;
do {
changed = false;
foreach (var regulation in regulations) {
var left = regulation.left; var right = regulation.Right;
// try to collect FIRST( left )
for (int checkpoint = 0; checkpoint < right.Count; checkpoint ++) {
// 如果前checkpoint个结点都可为null,
// 就说明 FIRST(left) 包含 FIRST(right[checkpoint]),empty除外。
// if regulation.right[(-1)->(checkpoint-1)] can be empty,
// then FIRST( left ) includes FIRST( right[checkpoint] )
// except for empty.
if (CanBeEmpty(right, 0, checkpoint, nullableDict)) {
var refKey = right[checkpoint];
if (left != refKey) {
if (!result.TryGetValue(left, out FIRST first)) { throw new Exception(algorithmError); }
if (!result.TryGetValue(refKey, out FIRST refFirst)) { throw new Exception(algorithmError); }
foreach (var value in refFirst.Values) {
if (value != empty) {
changed = first.TryInsert(value) || changed;
}
}
}
}
}
{
// if regulation.right can be empty,
// then regulation.left can be empty.
if (CanBeEmpty(right, nullableDict)) {
if (!result.TryGetValue(left, out FIRST first)) { throw new Exception(algorithmError); }
changed = first.TryInsert(empty) || changed;
}
}
}
} while (changed);
}
计算FOLLOW(Vn)
算法思想:
-
对于
left : 某V 某V .. Vn V1 V2 .. ;这样的Regulation:FOLLOW(Vn)包含FIRST(V1);若
nullable(V1)=true,则FOLLOW(Vn)还包含FIRST(V2);以此类推;若
nullable(V1 V2 ..)=true,则FOLLOW(Vn)还包含FOLLOW(left)。 -
迭代到不动点。
public static Dictionary<string/*FOLLOW.target*/, FOLLOW> GetFOLLOWDict(this VnRegulationDraft[] regulations,
Dictionary<string, bool> nullableDict, Dictionary<string, FIRST> firstDict) {
var result = new Dictionary<string/*FOLLOW.Vn*/, FOLLOW>();
// 初始化Follow Dict
// allocate space for the FOLLOW( Vn ) items.
foreach (var item in regulations.GetVnNodes()) {
var follow = new FOLLOW(item);
result.Add(follow.Vn, follow);
}
// 迭代到不动点
// iterate untill not changed.
bool changed = false;
do {
changed = false;
foreach (var regulation in regulations) {
var right = regulation.Right; int count = right.Count;
for (int checkpoint = 0; checkpoint < count; checkpoint++) {
string/*Node.type*/ target = right[checkpoint];
if (target.IsVt()) { continue; } // 叶结点没有FOLLOW
// 准备为target添加follow元素
// try to collect FOLLOW( target )
var checkIndex = checkpoint + 1;
for (int checkCount = 0; checkCount < count - checkIndex; checkCount++) {
// if right[checkIndex->(checkIndex+checkCount-1)] can be empty,
// then FOLLOW( target ) includes FIRST( right[checkInde+checkCount] )
// except empty.
if (CanBeEmpty(right, checkIndex, checkCount, nullableDict)) {
// FOLLOW( target ) 包含 FIRST( right[checkInde+checkCount] )(除了empty)
var Vn = target;
if (!result.TryGetValue(Vn, out FOLLOW follow)) { throw new Exception(algorithmError); }
string key = right[checkIndex + checkCount];
if (!firstDict.TryGetValue(key, out FIRST first)) { throw new Exception(algorithmError); }
foreach (var value in first.Values) {
if (value != "empty") {
changed = follow.TryInsert(value) || changed;
}
}
}
}
{
var checkCount = count - checkIndex;
// 如果target之后的全部结点都可为empty,那么 FOLLOW( target ) 包含 FOLLOW( regulation.left )
// if right[checkIndex->(count - checkIndex-1)] can be empty,
// then FOLLOW( target ) includes FOLLOW( regulation.left ).
if (CanBeEmpty(right, checkIndex, checkCount, nullableDict)) {
if (!result.TryGetValue(target, out FOLLOW follow)) { throw new Exception(algorithmError); }
if (!result.TryGetValue(regulation.left, out FOLLOW refFollow)) { throw new Exception(algorithmError); }
if (follow != refFollow) {
foreach (var item in refFollow.Values) {
changed = follow.TryInsert(item) || changed;
}
}
}
}
}
}
} while (changed);
return result;
}
扩展文法
这是一个编程技巧:对任何文法,都在开头添加一个S2结点,作为初始结点。这样可以使得完成动作只存在1个。我将扩展的文法称为eGrammar,其产生式部分称为eRegulations,(e代表extended)额外新增的这个Regulation称为扩展Regulation。
例如,扩展的四则运算Calc文法如下:
// GrammarName = Calc
// ExtractedType = FinalValue
S2 : Additive ;
Additive : Additive '+' Multiplicative // R[0]
| Additive '-' Multiplicative // R[1]
| Multiplicative ; // R[2]
Multiplicative : Multiplicative '*' Primary // R[3]
| Multiplicative '/' Primary // R[4]
| Primary ; // R[5]
Primary : '(' Additive ')' // R[6]
| 'number' ; // R[7]
// 用 %%xxx%% 格式 描述单词
'number' : %%[0-9]+%% ; // 为便于演示,仅处理正整数
LL(1)分析法
算法思想:
-
对于
Vn : V1 V2 V3 .. ;这样的Regulation:对于
FIRST(V1 V2 V3 ..)中的每个元素Vt(不含空ε),在LL(1)分析表中记录下“Vn行Vt列对应Vn : V1 V2 V3 .. ;”,意为“在Vn状态下遇到Vt时,应当使用Vn : V1 V2 V3 .. ;进行规约”;若
FIRST(V1 V2 V3 ..)包含空ε,则在LL(1)分析表中记录下“Vn行全部FOLLOW(Vn)列对应Vn : V1 V2 V3 .. ;”,意为“在Vn状态下遇到Vt时,应当使用Vn : V1 V2 V3 .. ;进行规约”。
public static LL1SyntaxInfo GetLL1SyntaxInfo(this VnRegulationDraft[] regulations,
VnRegulationDraft[] eRegulations,
Dictionary<string, FOLLOW> eFOLLOWDict, Dictionary<string, FIRST> eFIRSTDict) {
var regCount = regulations.Length;
var table = new LL1ParsingTableDraft();
for (int regulationId = 0; regulationId < regulations.Length; regulationId++) {
var regulation = regulations[regulationId];
var Vn = regulation.left;
var key = FIRST.MakeKey(regulation.Right);
var first = eFIRSTDict[key]; // FIRST( regulation.Right )
var firstCount = first.Values.Count;
for (int index = 0; index < firstCount; index++) {
var VtOrEmpty = first.Values[index];
if (VtOrEmpty != "empty" /* ε */) {
table.SetAction(Vn, VtOrEmpty, new LL1ParsingActionDraft(regulationId));
}
else {
var follow = eFOLLOWDict[Vn];
foreach (var Vt in follow.Values) {
table.SetAction(Vn, Vt, new LL1ParsingActionDraft(regulationId));
}
}
}
}
var result = new LL1SyntaxInfo(table);
return result;
}
LR(0)分析法
算法思想:
-
拿到第一个
Regulation(Vn:V1 V2 V3 .. ;),以Vn: ? V1 V2 V3 .. ;为初始LR(0)状态,并求解其闭包。实际上,第一个Regulation就是扩展Regulation。 -
对每个LR(0)状态A,让?向前移动一个
V,得到下一个LR(0)状态B,并求解其闭包。 -
将
A-V->B设置为LR(0)边。 -
设置LR(0)分析表:对每个LR(0)边(例如
A-V->B),若V是Vt,则在A行V列记录移进到B;若V是Vn,则在A行V列记录跳入B。 -
设置LR(0)分析表:对每个LR(0)状态(例如A)中的每个Item,若Item中的?位于
Regulation末尾,一般情况下,则在A行全部Vt列(包括'¥'列)记录用Regulation规约;特殊情况(Regulation是扩展Regulation)下,则在A行'¥'列记录完成。
public static LR0SyntaxInfo GetLR0SyntaxInfo(this VnRegulationDraft[] regulations,
VnRegulationDraft[] eRegulations) {
var stateList = new LR0StateList();
var edgeList = new LR0EdgeList();
var queue = new Queue<LR0State>(); {
var firstItem = LR0Item.GetItem(eRegulations[0], 0);
var firstState = new LR0State(firstItem); Closure(firstState, eRegulations);
stateList.TryInsert(firstState);
queue.Enqueue(firstState);
}
while (queue.Count > 0) {
var from = queue.Dequeue();
foreach (var item in from.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) { continue; }
var to = Goto(from, V); Closure(to, eRegulations);
if (stateList.TryInsert(to)) { // to是新状态
queue.Enqueue(to);
var edge = new LR0Edge(from, V, to);
edgeList.TryInsert(edge);
}
else { // to是已有状态
int t = stateList.IndexOf(to);
var oldTo = stateList.States[t];
var edge = new LR0Edge(from, V, to);
edgeList.TryInsert(edge);
}
}
}
var table = new LRParsingTableDraft();
foreach (var edge in edgeList.Edges) {
if (edge.V.IsVt()) {
// shift in action
table.SetAction(edge.from.index, edge.V, new LRShiftInActionDraft(edge.to.index));
}
else { // V is Vn
// goto action
table.SetAction(edge.from.index, edge.V, new LRGotoActionDraft(edge.to.index));
}
}
var Vts = eRegulations.GetVtNodes();
var eLeft = eRegulations[0].left; // the S' in many books.
var eEnd = '¥'; // similar to '\0' in lexical analyzing
foreach (var state in stateList.States) {
foreach (var item in state.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) {
if (item.VnRegulation.left == eLeft) {
// accept action
var acceptAction = new LRAcceptActionDraft();
table.SetAction(state.index, eEnd, acceptAction);
}
else {
// reduction action
int reductionIndex = Array.IndexOf(eRegulations, item.VnRegulation) - 1;
var action = new LRReducitonActionDraft(reductionIndex);
foreach (var Vt in Vts) {
table.SetAction(state.index, Vt, action);
}
{
table.SetAction(state.index, eEnd, action);
}
}
}
}
}
var result = new LR0SyntaxInfo(stateList, edgeList, table);
return result;
}
LR(0)状态求解闭包的算法:
-
对LR(0)状态中的每个Item,若?后面的第一个
V是Vn,则将所有的Vn : ? V1 V2 V3 ..作为一个新的Item加入此状态。 -
迭代至不再新增Item。
static void Closure(this LR0State state, VnRegulationDraft[] eRegulations) {
var queue = new Queue<LR0Item>();
foreach (var item in state.Items) { queue.Enqueue(item); }
while (queue.Count > 0) {
var item = queue.Dequeue();
string/*Node.type*/ node = item.nodeNext2Dot;
if (node == null || node.IsVt()) { continue; }
foreach (var regulation in eRegulations) {
if (regulation.left == node) {
const int dotPosition = 0;
var newItem = LR0Item.GetItem(regulation, dotPosition);
if (state.TryInsert(newItem)) {
queue.Enqueue(newItem);
}
}
}
}
}
SLR(1)分析法
算法思想:
-
拿到第一个
Regulation(Vn:V1 V2 V3 .. ;),以Vn: ? V1 V2 V3 .. ;为初始SLR(1)状态,并求解其闭包。实际上,第一个Regulation就是扩展Regulation。 -
对每个SLR(1)状态A,让?向前移动一个
V,得到下一个SLR(1)状态B,并求解其闭包。 -
将
A-V->B设置为SLR(1)边。 -
设置SLR(1)分析表:对每个SLR(1)边(例如
A-V->B),若V是Vt,则在A行V列记录移进到B;若V是Vn,则在A行V列记录跳入B。 -
设置SLR(1)分析表:对每个SLR(1)状态(例如A)中的每个Item,若Item中的?位于
Regulation末尾,一般情况下,则在A行全部FOLLOW(Vn)列记录用Regulation规约;特殊情况(Regulation是扩展Regulation)下,则在A行'¥'列记录完成。
在记录用Regulation规约方面,SLR(1)比LR(0)细腻,其他方面并无不同。
public static SLR1SyntaxInfo GetSLR1SyntaxInfo(this VnRegulationDraft[] regulations,
VnRegulationDraft[] eRegulations, Dictionary<string, FOLLOW> eFOLLOWDict) {
var stateList = new SLR1StateList();
var edgeList = new SLR1EdgeList();
var queue = new Queue<SLR1State>(); {
var firstItem = SLR1Item.GetItem(eRegulations[0], 0);
var firstState = new SLR1State(firstItem); Closure(firstState, eRegulations);
stateList.TryInsert(firstState);
queue.Enqueue(firstState);
}
while (queue.Count > 0) {
var from = queue.Dequeue();
foreach (var item in from.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) { continue; }
var to = Goto(from, V); Closure(to, eRegulations);
if (stateList.TryInsert(to)) { // to是新状态
queue.Enqueue(to);
var edge = new SLR1Edge(from, V, to);
edgeList.TryInsert(edge);
}
else { // to是已有状态
int t = stateList.IndexOf(to);
var oldTo = stateList.States[t];
var edge = new SLR1Edge(from, V, oldTo);
edgeList.TryInsert(edge);
}
}
}
var table = new LRParsingTableDraft();
foreach (var edge in edgeList.Edges) {
if (edge.V.IsVt()) {
// shift action
table.SetAction(edge.from.index, edge.V, new LRShiftInActionDraft(edge.to.index));
}
else { // V is Vn
// goto action
table.SetAction(edge.from.index, edge.V, new LRGotoActionDraft(edge.to.index));
}
}
var eLeft = eRegulations[0].left; // the S' in many books.
var eEnd = '¥';
foreach (var state in stateList.States) {
foreach (var item in state.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) {
if (item.VnRegulation.left == eLeft) {
// accept action
var action = new LRAcceptActionDraft();
table.SetAction(state.index, eEnd, action);
}
else {
// reduction action
int reductionIndex = Array.IndexOf(eRegulations, item.VnRegulation) - 1;
var action = new LRReducitonActionDraft(reductionIndex);
if (!eFOLLOWDict.TryGetValue(item.VnRegulation.left, out FOLLOW follow)) { throw new Exception(algorithmError); }
foreach (var Vt in follow.Values) {
table.SetAction(state.index, Vt, action);
}
}
}
}
}
var result = new SLR1SyntaxInfo(stateList, edgeList, table);
return result;
}
SLR(1)状态求解闭包的算法与LR(0)完全相同。
LR(1)分析法
算法思想:
-
拿到第一个
Regulation(Vn:V1 V2 V3 .. ;),以Vn: ? V1 V2 V3 .. ;为初始LR(1)状态,并求解其闭包。实际上,第一个Regulation就是扩展Regulation。 -
对每个LR(1)状态A,让?向前移动一个
V,得到下一个LR(1)状态B,并求解其闭包。 -
将
A-V->B设置为LR(1)边。 -
设置LR(1)分析表:对每个LR(1)边(例如
A-V->B),若V是Vt,则在A行V列记录移进到B;若V是Vn,则在A行V列记录跳入B。 -
设置LR(1)分析表:对每个LR(1)状态(例如A)中的每个Item,若Item中的?位于
Regulation末尾,一般情况下,则在A行全部lookAhead列记录用Regulation规约;特殊情况(Regulation是扩展Regulation)下,则在A行'¥'列记录完成。
public static LR1SyntaxInfo GetLR1SyntaxInfo(this VnRegulationDraft[] regulations,
VnRegulationDraft[] eRegulations, Dictionary<string, bool> eNullableDict, Dictionary<string, FIRST> eFIRSTDict) {
var stateList = new LR1StateList();
var edgeList = new LR1EdgeList();
var eEnd = '¥';
var queue = new Queue<LR1State>(); {
var firstItem = LR1Item.GetItem(eRegulations[0], 0, eEnd);
var firstState = new LR1State(firstItem); Closure(firstState, eRegulations, eNullableDict, eFIRSTDict);
stateList.TryInsert(firstState);
queue.Enqueue(firstState);
}
while (queue.Count > 0) {
var from = queue.Dequeue();
foreach (var item in from.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) { continue; }
var to = Goto(from, V); to.Closure(eRegulations, eNullableDict, eFIRSTDict);
if (stateList.TryInsert(to)) { // to是新状态
queue.Enqueue(to);
var edge = new LR1Edge(from, V, to);
edgeList.TryInsert(edge);
}
else { // to是已有状态
int t = stateList.IndexOf(to);
var oldTo = stateList.States[t];
var edge = new LR1Edge(from, V, oldTo);
edgeList.TryInsert(edge);
}
}
}
var table = new LRParsingTableDraft();
foreach (var edge in edgeList.Edges) {
if (edge.V.IsVt()) {
// shift in action
table.SetAction(edge.from.index, edge.V, new LRShiftInActionDraft(edge.to.index));
}
else { // V is Vn
// goto action
table.SetAction(edge.from.index, edge.V, new LRGotoActionDraft(edge.to.index));
}
}
var eLeft = eRegulations[0].left; // the S' in many books.
foreach (var state in stateList.States) {
foreach (var item in state.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) {
if (item.VnRegulation.left == eLeft) {
// accept action
var action = new LRAcceptActionDraft();
table.SetAction(state.index, eEnd, action);
}
else {
// reduction action
int reductionIndex = Array.IndexOf(eRegulations, item.VnRegulation) - 1;
var action = new LRReducitonActionDraft(reductionIndex);
{
table.SetAction(state.index, item.lookAhead, action);
}
}
}
}
}
var result = new LR1SyntaxInfo(stateList, edgeList, table);
return result;
}
LR(1)状态求解闭包的算法:
-
对LR(1)状态中的每个Item(
left : 某V 某V .. ? V 某V1 某V2 .. ; z),若?后面的第一个V是Vn,则将所有的Vn : ? V1 V2 V3 .. ; lookAhead加入此状态,其中的lookAhead=FIRST(某V1 某V2 .. z)。 -
迭代至不再新增Item。
private static void Closure(this LR1State state, VnRegulationDraft[] eRegulations,
Dictionary<string/*Node.type*/, bool> emptyDict, Dictionary<string, FIRST> firstDict) {
var queue = new Queue<LR1Item>();
foreach (var item in state.Items) { queue.Enqueue(item); }
while (queue.Count > 0) {
var item = queue.Dequeue();
string/*Node.type*/ node = item.nodeNext2Dot;
if (node == null || node.IsVt()) { continue; }
nodeRegulations = eRegulations.GetVnRegulations(left: node);
first = GetFIRST(item.betaZ, firstDict, emptyDict);
foreach (var regulation in nodeRegulations) {
foreach (var lookAhead in first.Values) {
const int dotPosition = 0;
var newItem = LR1Item.GetItem(regulation, dotPosition, lookAhead);
if (state.TryInsert(newItem)) {
queue.Enqueue(newItem);
}
}
}
}
}
LALR(1)分析法
算法思想:
-
拿到第一个
Regulation(Vn:V1 V2 V3 .. ;),以Vn: ? V1 V2 V3 .. ;为初始LR(1)状态,并求解其闭包。实际上,第一个Regulations就是扩展Regulation。 -
对每个LR(1)状态A,让?向前移动一个
V,得到下一个LR(1)状态B,并求解其闭包。 -
将
A-V->B设置为LR(1)边。 -
设置LR(1)分析表:对每个LR(1)边(例如
A-V->B),若V是Vt,则在A行V列记录移进到B;若V是Vn,则在A行V列记录跳入B。 -
设置LR(1)分析表:对每个LR(1)状态(例如A)中的每个Item,若Item中的?位于
Regulation末尾,一般情况下,则在A行全部lookAhead列记录用Regulation规约;特殊情况(Regulation是扩展Regulation)下,则在A行'¥'列记录完成。
乍一看,LALR(1)算法与LR(1)算法完全相同。它们只在一点上有区别:Regulation相同、?位置相同而lookAhead不同的两个状态,在LALR(1)眼里是相同的,在LR(1)眼里是不同的。
public static LALR1SyntaxInfo GetLALR1SyntaxInfo(this VnRegulationDraft[] regulations,
VnRegulationDraft[] eRegulations, Dictionary<string, bool> eEmptyDict, Dictionary<string, FIRST> eFIRSTDict) {
var stateList = new LALR1StateList();
var edgeList = new LALR1EdgeList();
var eEnd = '¥';
var queue = new Queue<LALR1State>(); {
var firstItem = LALR1Item.GetItem(eRegulations[0], 0, eEnd);
var firstState = new LALR1State(firstItem); Closure(firstState, eRegulations, eEmptyDict, eFIRSTDict);
stateList.TryInsert(firstState);
queue.Enqueue(firstState);
}
while (queue.Count > 0) {
var from = queue.Dequeue();
foreach (var item in from.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) { continue; }
var to = Goto(from, V); to.Closure(eRegulations, eEmptyDict, eFIRSTDict);
if (stateList.TryInsert(to)) { // to是新状态
queue.Enqueue(to);
var edge = new LALR1Edge(from, V, to);
edgeList.TryInsert(edge);
}
else { // to是已有状态
int t = stateList.IndexOf(to);
var oldTo = stateList.States[t];
// add lookAheads in toState to target.
var updated = false;
foreach (var item in to.Items) { if (oldTo.TryInsert(item)) { updated = true; } }
if (updated) { queue.Enqueue(oldTo); }
var edge = new LALR1Edge(from, V, oldTo);
edgeList.TryInsert(edge);
}
}
}
var table = new LRParsingTableDraft();
foreach (var edge in edgeList.Edges) {
if (edge.V.IsVt()) {
// shift in action
table.SetAction(edge.from.index, edge.V, new LRShiftInActionDraft(edge.to.index));
}
else {
// goto action
table.SetAction(edge.from.index, edge.V, new LRGotoActionDraft(edge.to.index));
}
}
var eLeft = eRegulations[0].left; // the S' in many books.
foreach (var state in stateList.States) {
foreach (var item in state.Items) {
string/*Node.type*/ V = item.nodeNext2Dot;
if (V == null) {
if (item.VnRegulation.left == eLeft) {
// accept action
var action = new LRAcceptActionDraft();
table.SetAction(state.index, eEnd, action);
}
else {
// reduction action
int reductionIndex = Array.IndexOf(eRegulations, item.VnRegulation) - 1;
var action = new LRReducitonActionDraft(reductionIndex);
{
table.SetAction(state.index, item.lookAhead, action);
}
}
}
}
}
var result = new LALR1SyntaxInfo(stateList, edgeList, table);
return result;
}
LALR(1)状态求解闭包的算法与LR(1)完全相同。
其他
快速比较两个集合
LR(0)状态、SLR(1)状态、LALR(1)状态、LR(1)状态都是各自Item的集合。计算语法分析表时,需要比较两个状态是否相同,这实质上就是比较两个集合包含的元素是否完全相同。
要想快速比较两个集合是否相同,就得先排序,而后比较排序完毕的集合。如果对排序完毕的集合,先计算int Hashcode并缓存之,那么,只需比较两个Hashcode是否相等即可。当然,如果集合新增了元素,就要重新计算Hashcode,这意味着需要有一个bool dirty;标记是否需要重新计算Hashcode。
在我们的应用场景里,只需要新增元素,不需要修改或删除元素,因而实现起来就简单得多。
据此,我实现了对IList<T>的二分法快速插入算法:
public static bool TryBinaryInsert<T>(this IList<T> list, T item)
where T : IComparable<T> {
bool inserted = false;
if (list == null || item == null) { return inserted; }
int left = 0, right = list.Count - 1;
if (right < 0) {
list.Add(item);
inserted = true;
}
else {
while (left < right) {
int mid = (left + right) / 2;
T current = list[mid];
int result = item.CompareTo(current);
if (result < 0) { right = mid; }
else if (result == 0) { left = mid; right = mid; }
else { left = mid + 1; }
}
{
T current = list[left];
int result = item.CompareTo(current);
if (result < 0) {
list.Insert(left, item);
inserted = true;
}
else if (result > 0) {
list.Insert(left + 1, item);
inserted = true;
}
}
}
return inserted;
}
擦除控制台的文字
可以通过输出退格符'\u0008'来退回到控制台的上一个char的位置,相当于手动按一次键盘上的退格键(但不删除char)。这在显示进度的时候很有用。下面的代码可以擦除上次写的内容,写入新的内容:
private static int lastOutputLength = 0;
/// <summary>
/// erase content written the last time and write something new.
/// </summary>
/// <param name="content"></param>
public static void Rewrite(string content) {
if (content == null) { content = string.Empty; }
var currentLength = content.Length;
var delta = lastOutputLength - currentLength;
for (int t = 0; t < delta; t++) { Console.Write('\u0008'); } // move back
for (int t = 0; t < delta; t++) { Console.Write(' '); } // erase with space
for (int t = 0; t < lastOutputLength; t++) { Console.Write('\u0008'); } // move back
Console.Write(content);
lastOutputLength = content.Length;
}
用Mermaid画图
如果能画出词法分析自动机和语法分析状态机的图,会极大提升学习、开发、调试的效率。将自动机导出为Mermaid格式的文件(*.mmd)即可实现这个功能。本文的图示,除了Calc文法的全部Token的自动机外,都是自动导出的mmd文件,在浏览器中实时渲染的。
ASCII码
为处理正则表达式,我整理了ASCII码及其10进制和16进制表,以便查阅。
#032 !#033 "#034 ##035 $#036 %#037 & '#039
(#040 )#041 *#042 +#043 ,#044 -#045 .#046 /#047
0#048 1#049 2#050 3#051 4#052 5#053 6#054 7#055 8#056 9#057
:#058 ;#059 <#060 =#061 >#062 ?#063 @#064
A#065 B#066 C#067 D#068 E#069 F#070 G#071 H#072 I#073 J#074
K#075 L#076 M#077 N#078 O#079 P#080 Q#081 R#082 S#083 T#084
U#085 V#086 W#087 X#088 Y#089 Z#090
[#091 \#092 ]#093 ^#094 _#095 `#096
a#097 b#098 c#099 d#100 e#101 f#102 g#103 h#104 i#105 j#106
k#107 l#108 m#109 n#110 o#111 p#112 q#113 r#114 s#115 t#116
u#117 v#118 w#119 x#120 y#121 z#122
{#123 |#124 }#125 ~#126
\u20 !\u21 "\u22 #\u23 $\u24 %\u25 &\u26 '\u27
(\u28 )\u29 *\u2A +\u2B ,\u2C -\u2D .\u2E /\u2F
0\u30 1\u31 2\u32 3\u33 4\u34 5\u35 6\u36 7\u37 8\u38 9\u39
:\u3A ;\u3B <\u3C =\u3D >\u3E ?\u3F @\u40
A\u41 B\u42 C\u43 D\u44 E\u45 F\u46 G\u47 H\u48 I\u49 J\u4A
K\u4B L\u4C M\u4D N\u4E O\u4F P\u50 Q\u51 R\u52 S\u53 T\u54
U\u55 V\u56 W\u57 X\u58 Y\u59 Z\u5A
[\u5B \\u5C ]\u5D ^\u5E _\u5F `\u60
a\u61 b\u62 c\u63 d\u64 e\u65 f\u66 g\u67 h\u68 i\u69 j\u6A
k\u6B l\u6C m\u6D n\u6E o\u6F p\u70 q\u71 r\u72 s\u73 t\u74
u\u75 v\u76 w\u77 x\u78 y\u79 z\u7A
{\u7B |\u7C }\u7D ~\u7E
! " # $ % & '
( ) * + , - . /
0 1 2 3 4 5 6 7 8 9
: ; < = > ? @
A B C D E F G H I J K L M
N O P Q R S T U V W X Y Z
[ \ ] ^ _ `
a b c d e f g h i j k l m
n o p q r s t u v w x y z
{ | } ~
总结
近期有其他事务要处理,不得不暂停。目前还有这几个问题没有写完:
-
把词法分析过程、语法分析过程、语义分析过程、分析表生成过程都导出为更生动的gif动图。
-
在文法中增加对注释
Token的支持,免去手动添加识别注释的麻烦。 -
修改
Grammar的设定,让多个%%xxx%%指向同一个Vt。这才更接近lex的功能。 -
优化识别关键字的代码:不将关键字纳入
Automaton,减少啰嗦的状态。 -
使用特殊边,避免遇到
[a-z]{min, max}时批量复制子regex。 -
支持错误处理功能。
如果读者想认真学本文介绍的算法,但耐心不足,可以看看(https://www.cnblogs.com/bitzhuwei/p/explore-compiling.html)。
(微信捐赠不显示捐赠者的个人信息,如需要,请注明您的联系方式(微信留言只显示10个汉字))
Thank you for your kindly donation!
|
微信捐赠二维码:
Donate by microMsg: 
|