2023-05-20:go语言的slice和rust语言的Vec的扩容流程是什么?
2023-05-20:go语言的slice和rust语言的Vec的扩容流程是什么?
答案2023-05-20:
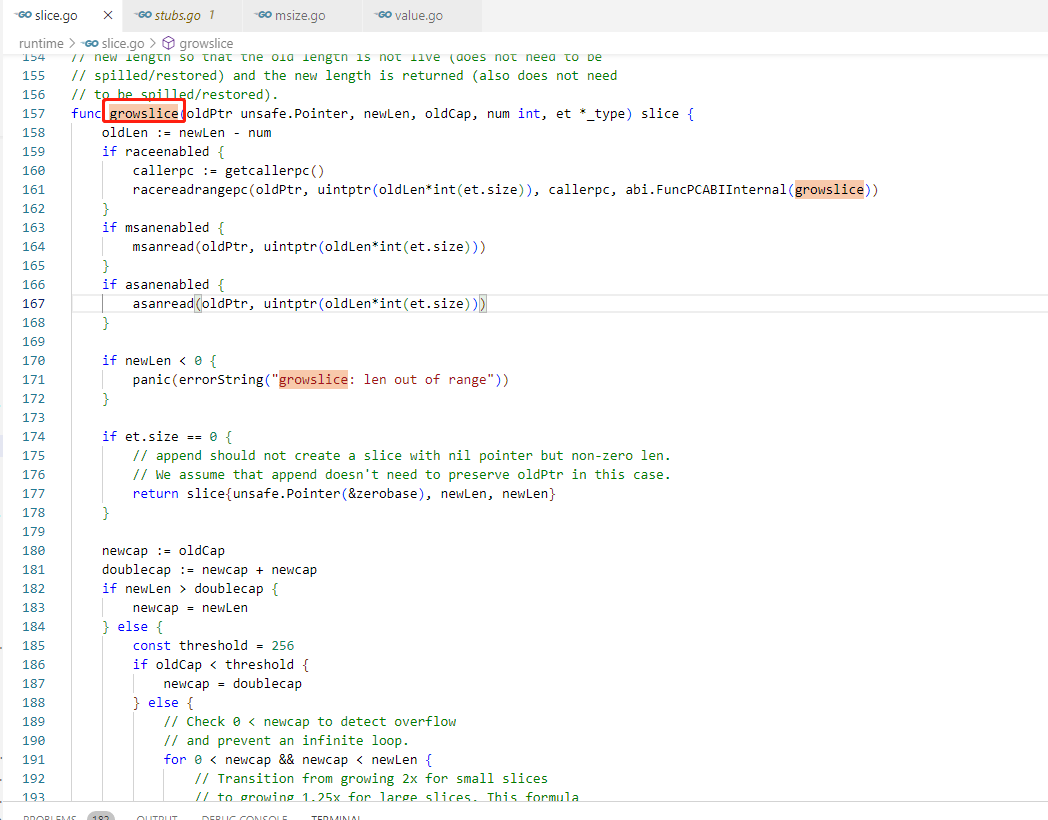
go语言的slice扩容流程
go版本是1.20.4。
扩容流程见源码见runtime/slice.go文件中的growslice 函数。
growslice 函数的大致过程如下:
1.如果元素类型的大小为零,则返回具有 nil 指针但非零长度的切片。否则,下一步。
2.计算新切片的容量。如果新长度大于旧容量的两倍,则将新容量设置为新长度。否则,如果旧容量小于 256,则将新容量设置为旧容量的两倍,这是翻倍扩容。否则,使用一种算法计算新容量,该算法从将增长因子从 2 倍转变为 1.25 倍的小切片开始,平滑地过渡到大切片,新容量=旧长度+(旧长度+3*256)/4,这比1.25倍略大,但很近似。近似1.25倍扩容不一定会大于等于新长度,所以必须循环多次扩容,一直到大于等于新长度。如果新容量计算溢出,则将则将新容量设置为新长度。
3.根据对象大小的67种规格,计算新切片的内存占用量,并且会重新调整新切片的容量,一般会改大。
以下描述可以不看:
3.1.根据元素类型的大小进行特化处理。对于大小为 1 的元素类型,不需要任何除法/乘法。
3.2.对于大小等于 goarch.PtrSize 的元素类型,编译器会将除法/乘法优化为一个常量的移位操作。
3.3.对于大小为 2 的幂的元素类型,使用可变移位量进行处理。
3.4.对于其他大小的元素类型,计算所需内存,并将其舍入到页大小的倍数。
4.调用mallocgc函数,分配内存,产生新指针。
这段描述可以不看,根据元素类型的指针数据大小(即元素类型中指向堆上分配的内存的指针字段的大小),使用 mallocgc() 分配新的后备存储器。如果指针数据大小为零,则直接调用 mallocgc() 分配内存,并在分配的内存中清除将被覆盖的部分。否则,使用 GC 兼容内存分配器 mallocgc() 分配内存,并根据需要启用写屏障。
5.调用memmove函数,旧指针数据填充到新指针数据里。
6.返回新切片,其中包含指向新指针、新长度和新容量。
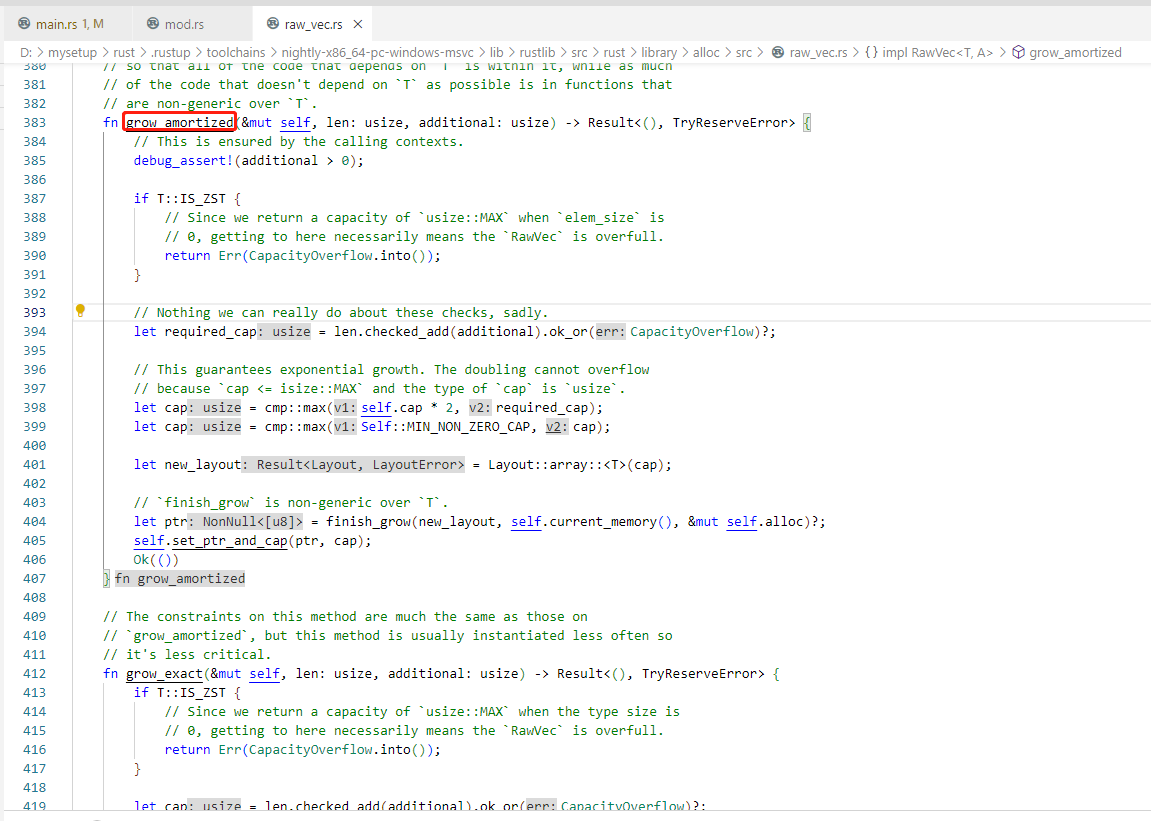
rust语言的Vec的扩容流程
rust版本:cargo 1.71.0-nightly (09276c703 2023-05-16)
扩容流程见raw_vec.rs文件里的grow_amortized 方法。
grow_amortized 方法的大体过程如下:
1.如果 T 是零大小类型(ZST),则直接返回一个错误,因为对于 ZST 的 Vec 实例来说,它们的容量总是 usize::MAX,不能再增加更多的容量。
2.计算新容量 。新容量 = MAX(当前长度+新增元素的长度,2倍的旧容量, Self::MIN_NON_ZERO_CAP)。
以下是对 Self::MIN_NON_ZERO_CAP 的描述可以不看:
MIN_NON_ZERO_CAP 是最小非零容量。该值表示在进行内存分配时, Vec 最少需要分配的非零容量大小,以避免出现过多的内存浪费和碎片化。
具体来说,这个常量定义采用了一个简单的策略,根据 T 类型元素的大小,分别设置不同的最小非零容量值:
-
如果
T类型元素大小为 1 字节,则将最小非零容量设置为 8; -
如果
T类型元素大小小于等于 1024 字节,则将最小非零容量设置为 4; -
否则,将最小非零容量设置为 1。
其中,如果 T 类型元素大小为 1 字节,则将最小非零容量设置为 8 是因为大部分堆分配器(heap allocator)会将小于 8 字节的内存请求自动对齐到 8 字节边界,因此设置最小容量为 8 可以避免出现内存浪费。
对于大小在 1 字节到 1024 字节之间的类型元素,将最小非零容量设置为 4,可以在保证一定的内存利用率的同时,避免出现过多的内存浪费和碎片化。
而对于大于 1024 字节的类型元素,将最小非零容量设置为 1,则可以避免出现过多的内存浪费,同时保证了内存分配时的性能和效率。
总之,这个常量定义是 Vec 在进行内存分配时所采用的一种策略,旨在尽可能地减少内存浪费和碎片化,同时保证了内存分配的性能和效率。
3.基于新的容量使用 Layout::array::<T> 方法创建一个新的布局 new_layout,new_layout 并不是已经分配了内存空间的对象,它只是一个描述所需内存块大小和对齐方式的布局对象。
4.调用 finish_grow() 方法进行内存分配,会获得一个新指针。这个方法是非泛型的,不依赖于 T 类型。
5.调用 set_ptr_and_cap 将分配得到的新指针和容量设置为 RawVec 实例的新值。
6.成功扩容,返回一个 Ok(()) 值。
需要注意的是,在上述过程中,除了第一步和第三步涉及到具体的类型 T 外,其他过程都是非泛型的。这样做是为了尽可能减小 grow_amortized() 方法的大小,同时提高其静态计算能力,从而使生成的代码运行更快。