
一篇文章告诉你什么是Java内存模型
在上篇 并发编程Bug起源:可见性、有序性和原子性问题,介绍了操作系统为了提示运行速度,做了各种优化,同时也带来数据的并发问题,
定义
在单线程系统中,代码按照顺序从上往下顺序执行,执行不会出现问题。比如一下代码:
int a = 1;
int b = 2;
int c = a + b;
程序从上往下执行,最终c的结果一定会是3。
但是在多线程环境中,代码就不一定会顺序执行了。代码的运行结果也有不确定性。在开发中,自己本地没问题,一行行查看代码也没有问题,但是在高并发的生产环境就会出现违背常理的问题。
多线程系统提升性能有如下几个优化:
- 单核的
cpu改成多核的cpu,每个cpu都有自己的缓存。 - 多个线程可以在
cpu线程切换。 - 代码可能根据编译优化,更新代码的位置。
这些优化会导致可见性、原子性以及有序性问题,为了解决上述问题,Java内存模型应运而生。
Java内存模型是定义了Java程序在多线程环境中,访问共享内存和内存同步的规范,规定了线程之间的交互方式,以及线程与主内存、工作内存的的数据交换。
Java内存模型解决并发
导致可见性的原因的是缓存,导致有序性的问题是编译优化,那解决可见性、有序性问题就是禁用缓存和编译优化。这样虽然解决了并发问题,但是性能却下降了。
合理的方案就是按需求禁用缓存和编译优化,在需要的地方添加对应的编码即可。Java内存模型规范了JVM如何按需禁用缓存和编译优化,具体包括volatile、synchronized、final这几个关键字,以及Happens-Before规则。
可见性问题
在多核cpu操作系统中每次cpu都有自己的缓存,cpu先从内存获取数据,再进行运算。比如下图中线程A和线程B,分别运行自己的cpu,然后从内存获取变量到自己的cpu缓存中,并进行计算。
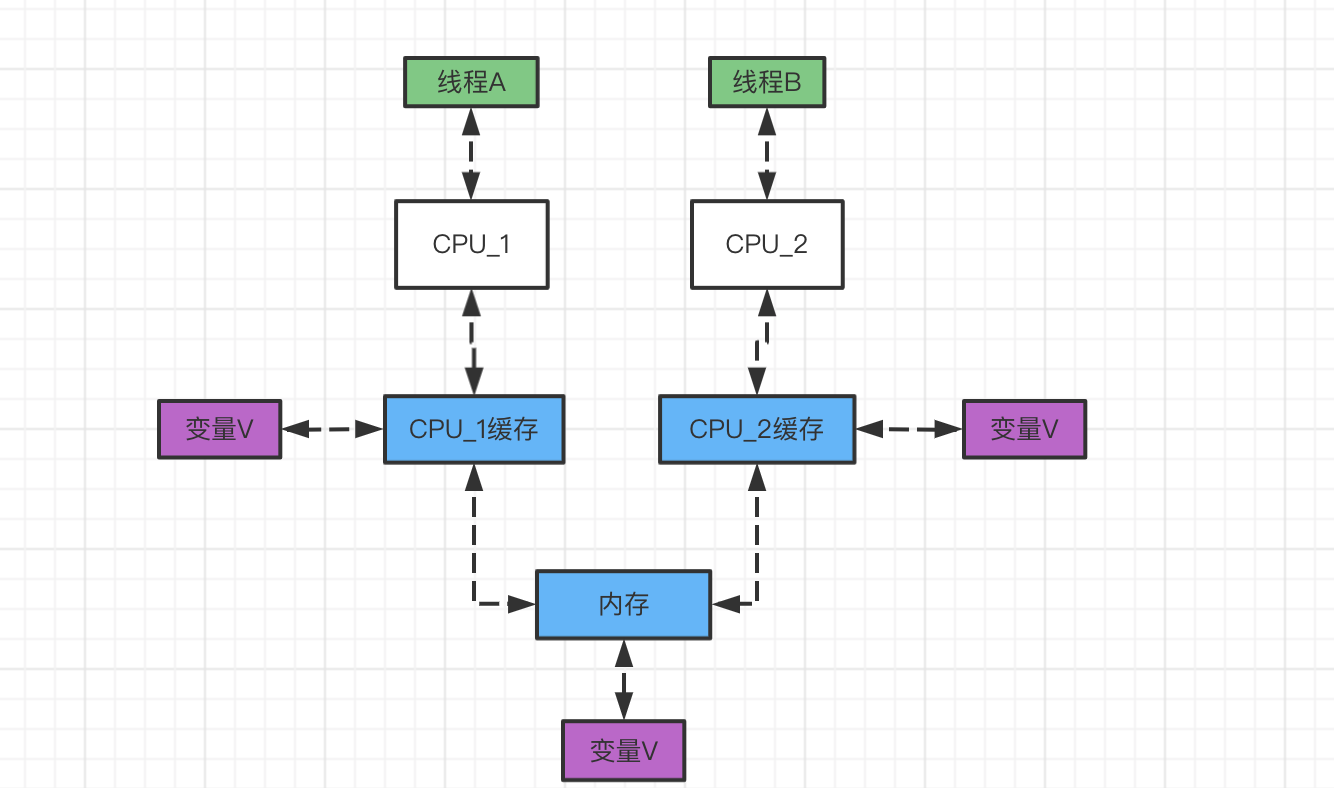
线程B改变了变量之后,线程A是无法获取到最新的值。以下代码中,启动两个线程,线程启动完线程A,循环获取变量,如果是true,一直执行循环,直到被改成false才跳出循环,然后再延迟1s启动线程B,线程修改变量值为true:
private static boolean flag = true;
// 线程A一直读取变量flag,直到变量为false,才跳出循环
class ThreadA extends Thread {
@Override
public void run() {
while (flag) {
// flag 为 true,一直读取flag字段,flag 为 false 时跳出来。
//System.out.println("一直在读------" + flag);
}
System.out.println("thread - 1 跳出来了");
}
}
// 1s 后线程B将变量改成 false
class ThreadB extends Thread {
@Override
public void run() {
System.out.println("thread-2 run");
flag = false;
System.out.println("flag 改成 false");
}
}
@Test
public void test2() throws InterruptedException {
new Thread1().start();
// 暂停一秒,保证线程1 启动并运行
Thread.sleep(1000);
new Thread2().start();
}
运行结果:
thread-2 run
flag 改成 false
线程A一直处于运行中,说明线程B修改后的变量,线程A并未知道。
将flag变量添加volatile声明,修改成:
private static volatile boolean flag = true;
再运行程序,运行结果:
thread-2 run
flag 改成 false
thread - 1 跳出来了
线程B运行完后,线程A也跳出了循环。说明修改了变量后,其他线程也能获取最新的值。
一个未声明
volatile的变量,都是从各自的cpu缓存获取数据,线程更新数据之后,其他线程无法获取最新的值。而使用volatile声明的变量,表明禁用缓存,更新数据直接更新到内存中,每次获取数据都是直接内存获取最新的数据。线程之间的数据都是相互可见的。
可见性来自happens-before规则,happens-before用来描述两个操作的内存可见性,如操作Ahappens-before操作B,那么A的结果对于B是可见的,前面的一个操作结果对后续操作是可见的。happens-before定义了以下几个规则:
- 解锁操作
happens-before同一把锁的加锁操作。 - volatile 字段的写操作
happens-before同一字段的读操作。 - 线程的启动操作
happens-before该线程的第一个操作。 - A
happens-beforeB,且Bhappens-beforeC,那么Ahappens-beforeC。happens-before具有传递性。
有序性问题
先看一个反常识的例子:
int a=0, b=0;
public void method1() {
b = 1;
int r2 = a;
}
public void method2() {
a = 2;
int r1 = b;
}
定义了两个共享变量a和b,以及两个方法。第一个方法将共享变量b赋值为1 ,然后将局部变量r2赋值为a。第二个方法将共享变量a赋值为2,然后将局部变量r1赋值为b。
在单线程环境下,我们可以先调用第一个方法method1,再调用method2方法,最终得到r1、r2的值分别为1,0。也可以先调用method2,最后得到r1、r2的值分别为0,2。
如果代码没有依赖关系,JVM编译优化可以对他们随意的重排序,比如method1方法没有依赖关系,进行重排序:
int a=0, b=0;
public void method1() {
int r2 = a;
b = 1;
}
public void method2() {
int r1 = b;
a = 2;
}
此时在多线程环境下,两个线程交替运行method1和method2方法:
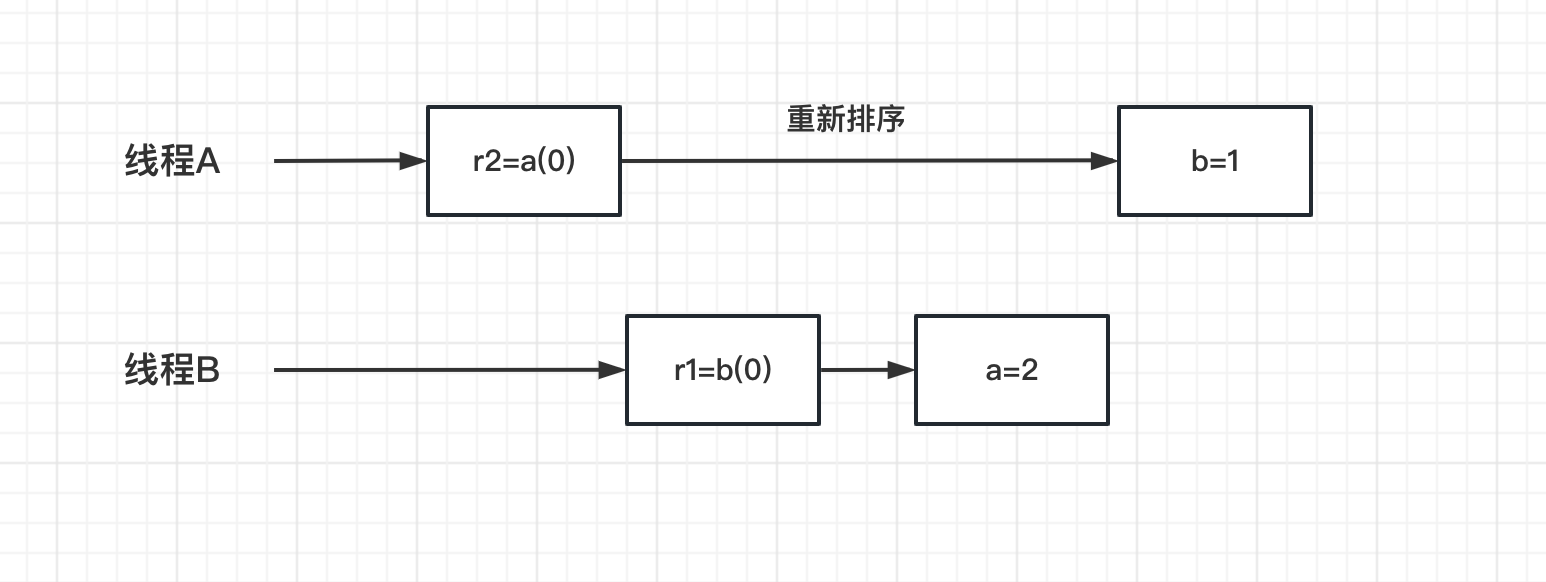
重排序后r1、r2分别是0,0。
那如何解决重排序的问题呢?答案就是将变量声明为volatile,比如a或者b变量声明volatile。比如b声明为volatile,此时b的赋值操作要happens-before r1的赋值操作。
int a=0;
volatile int b=0;
public void method1() {
int r2 = a;
b = 1;
}
public void method2() {
int r1 = b;
a = 2;
}
同一个线程顺序也满足happens-before关系以及传递性,可以得到r2的赋值happens-before a的赋值。也就表明对a赋值时,r2已经完成赋值了。也就不可能出现r1、r2为0、0的结果。
内存模型的底层实现
Java内存模型是通过内存屏障来实现禁用缓存和和禁用重排序。
内存屏障会禁用缓存,在内存写操作时,强制刷新写缓存,将数据同步到内存中,数据的读取直从内存中读取。
内存屏障会限制重排序操作,当一个变量声明volatile,它就插入了一个内存屏障,volatile字段之前的代码只能在之前进行重排序,它之后的代码只能在之后进行重排序。
总结
Java内存模型(Java Memory Model,JMM)定义了Java程序中多线程之间共享变量的访问规则,以及线程之间的交互行为。它规定了线程如何与主内存和工作内存交互,以确保多线程程序的可见性、有序性和一致性。
-
可见性:使用
volatile声明变量,数据读取直接从内存中读取,更新也是强制刷新缓存,并同步到主内存中。 -
有序性:使用
volatile声明变量,确保编译优化不会重排序该字段。 -
Happens-Before: 前面一个操作的结果对后续操作是可见的,