
NSDI-2023 微软论文:解构有状态网络功能
本文通过chatgpt代理站(支持gpt4):gptschools.cn翻译整理
微软Azure对每个虚拟机进行了为期三个月的网络监控,获得了新建、并发、PPS等指标情况,发现:
1) 网络功能负载不均衡:中位数负载比峰值负载小几个数量级。当负载不均衡时,为每个主机配置足够的资源来处理峰值负载将会浪费大量的资源。
2) 负载的长尾效应:尾部小部分主机承载着大部分的负载。这意味着只有少数几个主机需要处理大量的流量和数据包,而大多数主机只需要处理相对较少的流量。这对于资源分配和规划提出了挑战,因为我们需要确保尾部主机具有足够的资源来处理高负载,同时不浪费其他主机上的资源。
然而,各个云厂家出于安全性、隔离性、计量等目的,在每个计算节点都实现了复杂的网络功能,导致软硬件笨重,可扩展性差、成本高昂。总体看,现有云厂家方案,在计算节点的虚拟交换机中实现复杂有状态网络功能,面临如下三大挑战:
- l 开销大:线速维护、访问每流状态开销大。维护与存储每虚拟机网络状态会消耗大量存储资源。目前主流的实现是将计算节点的虚拟交换机软件与智能网卡软硬协同,通过快慢路径方式均衡存储资源消耗与吞吐性能。但这种方式仍然对每个智能网卡的资源要求非常高,网卡需要实现复杂功能逻辑。
- l 成本高、部署难:计算节点上的每张卡的配置必须满足峰值使用预期,但实际使用中,各个服务器峰值差距很大,大部分时间服务器网络负载低,若使用最大峰值部署将产生大量成本浪费。此外,若有新网络功能,需要升级每个服务器上得网卡,正在使用的服务器网卡使用冷升级的方式,需要先迁移节点上的所有虚拟机,不然会产生业务中断,导致升级部署困难。
- l 尾延迟大:在三大公有云中,受限于有状态网络功能的性能瓶颈,每个虚拟机支持的每秒新连接数远低于网卡容量。再加上各个服务器负载不均、有状态网络功能实现复杂,IO消耗大等问题,导致网络尾部时延大。
因此,本文提出将网络功能的复杂部分从主机中抽出来,分解到共享资源池中,这样可以简化计算节点的网卡设计,同时在网络功能负载不均的情况下,溢出流量可以引到资源池,减少计算节点的峰值负载设计,可大幅降低成本,提升网络性能与可靠性。
本方案的核心是设计实现这个网络功能资源池。该池必须同时支持大规模状态存储与高速数据包处理(数百GB的存储空间、Tbps级处理速率)。首先能想到的是使用可编程交换机,其可以达到Tbps级处理能力。然而,其只有GB级的SRAM,无法满足需求。因此,作者使用专用3U服务器,装备6个网卡(每卡功耗为75W,100Gb*2网口)、一个可P4编程的ASIC与16GB*2的内存组合在一起,作为共享网络资源池的基本单元,解决大存储空间与高吞吐的矛盾。
使用共享资源池的另外一个挑战是可靠性。独享模式下,一个智能网卡发生故障,只影响一个主机上的虚拟机。共享资源池模式下,当共享网络功能的设备发生故障时,将会影响到分配在该设备上的所有虚拟机。通过设备间的状态同步备份可以解决这个问题,但简单地复制网络功能状态需要一个非常大的数据缓冲区。因此,本文提出一种在节点之间来回传递数据包,通过管道传输减少报文缓存的方法。下面逐一展开这些设计点。
将网络功能分离

?
作者使用一个3U服务器装备一些网卡设备,作为网络共享资源池的最小单元,一个这种设备连接两个ToR交换机,保证可靠性。同时,为了防止单点故障,导致数据丢失,设备两两之间进行网络状态同步。为避免状态同步时数据包缓存,这里使用报文传输状态同步的方式,如下图所示,以TCP建立连接为例,当SYN报文到达主卡时,建立连接状态,然后将状态与数据包都转发给备卡,备卡在其本地内存中为该连接建立状态并将数据包转发回主卡,最后主卡将数据报文发给目的地。两个网卡之间独立进行状态管理。这种带内包携带状态同步的方式,只需要对原有代码进行少量改动,就可大量减少同步过程中数据包缓存开销。

?
每组网卡对(主卡和备卡)独立进行心跳检查和故障切换。如果主卡错过了几个心跳,备卡将接收分配给该对的所有fNIC流量。为了实现这样的故障切换,两个卡都会为fNIC的虚拟IP通告BGP路由,主卡宣告较短的自治系统路径(AS path)。另外,观察到:大多数连接状态变化很快。例如,每秒有4百万个新连接和3200万个并发连接,平均连接持续时间为8秒。因此,状态同步时,稍微等待一下、批量同步将减少同步状态开销,同步实时性也在可接受范围。同时,批量同步通过可靠性传输协议实现,保证状态同步可靠性。
fNIC的出口数据包被封装在NVGRE隧道中,并发送到Sirius池中的主卡中,主卡中的网络功能对数据报文进行处理,并将其转发到目的地。反向流量也经过类似的路径,首先到达网络资源池某个特定主卡(一个设备平均可以处理超过24000个VM的网络功能负载),然后根据需要转发给服务器,服务器上的智能网卡实现了封装和解封装逻辑,将报文解封转发给虚拟机。报文出计算节点网卡时,通过散列(local IP, remote IP) mod n选择共享资源池中的不同卡,确保流量的双向在同一节点处理。开始时,可以在服务器的智能网卡上处理所有的NF负载,当总负载接近智能网卡的容量时,将多余的负载分配到Sirius池中。一个Sirius设备可以容纳更多的VM,因为只有超出fNIC负载的部分才会被引导到资源池设备上。
高速NF实现
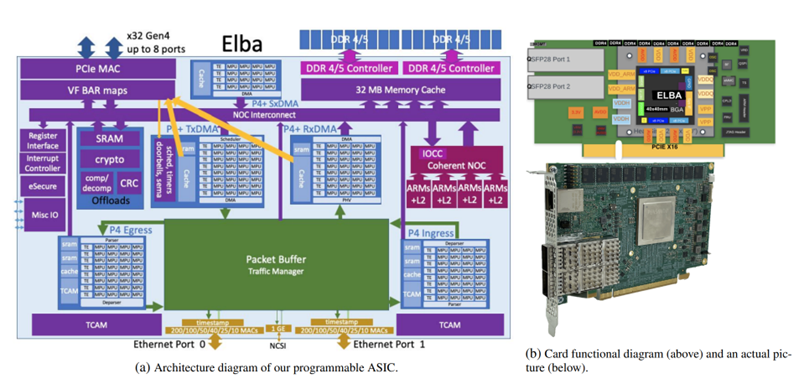
?
为了高效、高速处理有状态网络功能,设计实现了上图所示的P4可编程网卡,该卡具有两个100(或200)Gb网口、多个可编程pipeline、一致的共享内存,用于处理更复杂逻辑的ARM核,以及用于加密和压缩的专用逻辑等。
与基于FPGA的智能网卡相比,该卡将可编程匹配处理单元(MPU)与通用ARM核心相结合,在更低功耗、成本下获得更好可编程性与吞吐性能。因为该卡只在P4中暴露了处理协议和有状态NF所需的可编程性,而不是像FPGA那样暴露通用门级可编程性,所有功耗成本更低。另外,使用ARM核心处理在P4中难以实现的功能,如可靠状态同步等,又大大提高了网卡实现复杂功能的能力。
事实上,数据包通过一个或多个出入口在P4的pipeline流动,只在需要时经过ARM核心。每个pipeline有400Gbps(超过50M个数据包每秒)处理能力,确保每个网口线速处理报文。报文到达时,P4对数据包进行解析,并填充元数据用于后续阶段的数据报文处理。每个pipeline都有本地SRAM和TCAM来存储高速表项,并可一致访问共享DRAM,在开始阶段,对需要访问DRAM的操作提前发起请求,以隐藏访存延迟,避免高时延等待。
每个阶段都有多个匹配处理单元(MPU),同一阶段多个MPU并行处理,通过专用写路径将数据写回缓冲区,写操作可位级别合并,以实现多个MPU并行写入。同时,使用了一种可编程缓存管理机制来减少对内存带宽的需求,提高性能。另外MPU实现了一种新的领域特定指令集,实现位域操作和快速头部更新。使用宽指令(例如,64位宽),实现更丰富的编码和更少的指令。通过高速网络芯片(NOC)将P4 pipeline连接到SOC子系统,该子系统具有多核ARM A-72 CPU,实现ARM核和MPU的融合。 通过P4编程处理每个数据包,并决定将哪些数据、头部或元数据传递到DRAM和ARM中。为了支持链式操作,将P4控制操作与非P4操作(如加密或数据完整性校验)组合在一起,同时,将一个连接缓冲区直接附加到NOC上,以支持高带宽的多跳链接。
此外,作者实现了一个状态管理模块,用于在不同的网卡之间状态同步。此模块使用ARM核心来处理状态迁移消息和更新状态表。提出一种可重构状态机的方法,使状态表的更新能够在P4中进行,而状态表的查询则是在TCAM中进行,提高查询性能,同时保持灵活性。
在性能方面,该系统在多种基准测试中表现出色,通过在NAT、防火墙和负载均衡等场景测试发现:其具有比现有方案实更高的吞吐量和更低的延迟。通过成本分析发现:该系统比其他现有实现更具成本效益,既能够提供更好的性能,节省更多成本。
下面,以有状态负载均衡为例,说明该硬件的具体实现。
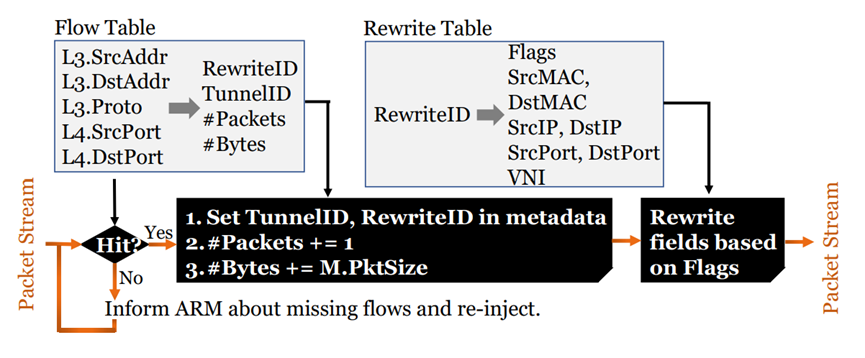
?
与基于哈希实现的无状态负载均衡不同,有状态负载均衡可以在服务器故障或其他目标变化时不中断正在进行的数据流。如上图所示,有状态负载均衡的状态(以浅色背景显示的表格)存储在网卡的DDR存中。数据面处理逻辑(以深色背景显示)在MPU pipeline中实现,而异常路径(用于没有任何状态的新流)在ARM核上实现。这种实现具有以下优势:
- 提升性能:单个芯片上集成了多个MPU,允许在多个pipeline之间,基于数据亲和性分配MPU程序(上图中黑色显示),并行处理多个数据包,可显著提高负载均衡效率,并降低延迟。
- 提升可靠性:采用高速网络芯片和DDR存储器,提高了系统的可靠性和容错性。
- 提升灵活性:采用P4编程语言,可以根据应用程序的需要自定义数据包处理逻辑。可以更好地适应各种应用场景,提高系统灵活性。如更改MAC地址。可以实现表项聚合,即一个表项处理多个NF。
与现有有状态负载均衡方案相比,本方案突破了内存的限制。测试表明,通过本方案,一张网卡可以支持超过1600万的并发连接和每秒300万新建。
性能评估

?
作者对本系统进行了一系列的性能评估。上图展示了性能测试的逻辑拓扑图。图a展示了使用一个流量生成器发送和接收数百Gbps的数据包并模拟ToR交换机、链路和网卡故障的实验环境。图b展示将虚拟机的浮动NIC卸载到了Sirius上,对虚拟机(VMs)间通信性能进行测试的环境。图c展示了将网关VM的浮动NIC卸载到Sirius上,VM通过网关VM进行通信的性能测试环境,以将有状态NFs虚拟机与将这些NFs卸载到Sirius上后的性能进行对比。
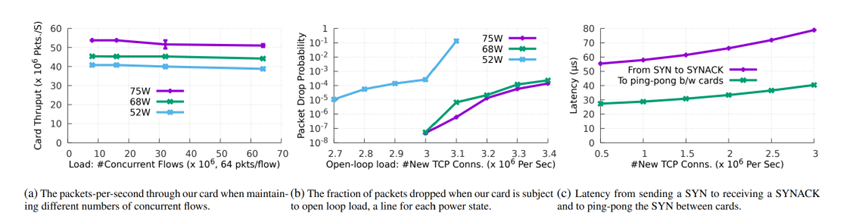
?
性能评估结果如上图所示:图a展示了当两个卡设置为状态复制模式时,其吞吐量和延迟的性能情况,可以看到,该模式下,网卡处理速率超过50 Mpps。对于64B和1500B的数据包,通过网卡的端到端延迟分别为2.36μs和3.14μs,时延没有明显增加。同时,在并发为64M(这时32 GB DRAM基本用完)时,处理速率只是稍微减少,可见,该系统有着很好的并发、吞吐、时延性能。
图b展示了每秒3M CPS时数据包丢失概率情况(y轴为对数刻度,右侧的值越低越好)。可以看到,68W功率状态对CPS几乎没有影响。最低功率(52W)下,CPS降2.5 M。
图c测量了发送TCP SYN到接收SYN-ACK之间的延迟。在较低的CPS负载下,延迟保持不变,但在较高的需求下呈超线性增长,这是由于新建由ARM处理,ARM在高负载下,数据报文处理排队造成的。
作者还评估了故障下丢包情况:设备故障时,主备切换的丢包率控制在0.01%以下,恢复时间控制在ms秒级,都有较好的表项。
总结
总体来看,有状态的网络功能是当今云架构的关键。作者将有状态网络功能解耦,分解成转发部分与其他复杂部分,复杂部分转移到一个共享池中。同时,共享资源池负责为计算节点的网卡负载兜底,计算节点的网卡溢出流量由资源池承担。这样即避免在每个服务器上部署高吞吐智能网卡,节省了成本,提高了尾部性能;又简化了网卡设计,解除了部署新网络功能时需要升级计算节点网卡的限制。此外,作者展示了一种简单高效的状态同步方案,在复制状态的同时,不需要缓存数据包,直接传输数据报文,节省了状态同步时缓存报文的存储空间。将大容量存储、P4可编程pipeline和通用ARM融合,软硬协同,实现了高吞吐与大存储空间的目标。在Azure的部署结果表明,在高新建和大并发的情况下,每个数据包都执行复杂有状态网络处理,智能网卡也可以达到线速。
读者认为:本文中的现网数据对指导网络设计非常有用。但是,将本文中每个贡献点拆开来看,都不够创新,在学术界、友商、初创公司的相关研究中都可以找到类似的研究或产品。有状态网关解耦后的最大难点:可靠性、状态一致性、健康检测、故障检测与恢复等方面,在本文中都是点到为止,没有展开,读完有种意犹未尽之感。