
文献精读1:SpikTransformer
Spikformer
code source(pku):GitHub - ZK-Zhou/spikformer: ICLR 2023, Spikformer: When Spiking Neural Network Meets Transformer
摘要
本文结合了两种生物学上的合理结构(biologically plausible structures),尖峰神经网络(spiking neural network,snn)和自注意力机制(self-attention mechanism)。
SNN:提供节能和事件驱动(event-driven)的范式AT:捕获特征依赖关系,实现更好的性能
基于两种特性的结合,提出了尖峰自注意力(Spiking Self Attention,SSA)为基础的框架即尖峰神经网络(Spiking Transformer,Spikformer),通过使用spike-form查询/键/值(代替softmax)来对稀疏视觉特征进行建模。由于计算系数,避免了乘法,SSA是高效的,具有低计算能耗。
实验结果表明,Spikformer在神经形态和静态数据集上的图像分类由于先进的SNNs-like框架。
名词解释
SOPs:突触运算(synaptic operations)

介绍
尖峰自注意力(Spiking Self Attention,SSA)机制通过引入尖峰序列建模相互依赖性(interdependence)。
在SSA中,尖峰自注意力机制主要有以下特点:
- 输入和值均为二值化形式,仅包含0和1(二进制)。与
VSA的浮点输入和值相比包含较少的细粒度特征,浮点QKV对尖峰序列的建模是冗余的。 - 非负特性。解耦了
SOFTMAX的影响。【softmax的作用可能仅仅是保证非负的意义,先前的TRM变体如Performer采用随机正特征来逼近softmax,cosformer使用RELU和cos-func代替了softmax。】
基于上述特性,可以使用与门(AND)和加法器来实现乘法。Spikformer的架构如下图所示,其提高了在静态数据集和神经形态数据集上训练的性能。这是首次探索SNN中的自注意力机制和直接训练的TRM,本文的贡献体现如下方面:
- 我们设计了一个新的尖峰形式的自我注意命名为尖峰自我注意(
SSA)的SNNs的属性。使用稀疏尖峰形式的QKV而不使用softmax,SSA的计算避免了乘法运算,效率很高。 - 基于
SSA,提出了尖峰TRANSFORMER,并且使用直接训练的SNN模型在ImageNet上以4个时间步长实现了超过74%的准确率。所提出的架构优于静态和神经形态数据集上最先进的SNN。
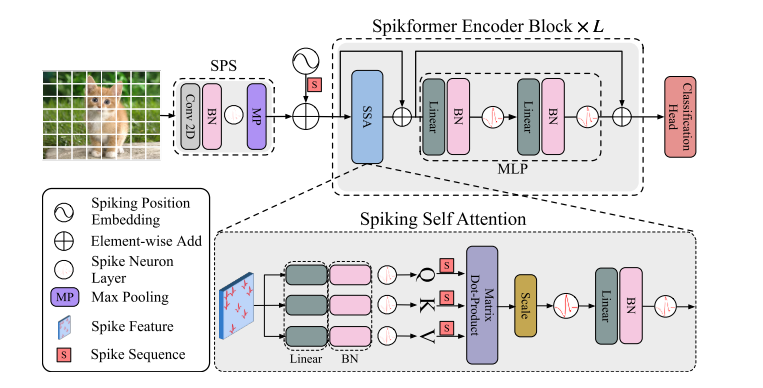
【架构中包括了Spiking patchspliting(SPS)模块,Spikformer编码器和线性分类头(Linear classification head)组成。LayerNorm(LN)不适合用于SNN,采用了BN代替】
方法
相关工作
SNN:
区别于传统使用连续十进制数据(continuous decimal values)传递信息的深度学习模型,SNN使用离散尖峰序列来计算和传输信息。尖峰神经网络可以接收连续值(continuous values),并将其转换为尖峰序列(spike sequences)。【相关工作有Leaky Integrate-and-Fire,LIF neuron和PLIF】
有两种方法可以获得深度SNN模型:ANN-TO-SNN转换和直接训练(direct training)。
ANN-TO-SNN:可以通过使用尖峰神经元(sping neurous)替换RELU激活层,将高性能预训练的ANN转换为SNN。转换后的SNN需要很大的时间步来准确近似RELU激活,这会造成很大的延迟。- 直接训练:
SNN在仿真时间步长上展开(unfold),并以时间反向传播的方式训练?【尖峰神经元的事件触发机制是不可微的,代理梯度(surrogate gradient)可用于反向传播、并采用隐式微分的平衡状态(implicit differentiation on the equailibrium state)来训练SNN】
目前人工神经网络的各类模型已被移植到SNN上,但现前自注意力在SNN上的研究仍为空白。有以下尝试性工作:
- 使用时间注意力(
temporal)来减少冗余的时间步长。 - 使用
ANN-TRM来处理尖峰数据(spike data),尽管方法标题中提到了spiking trm。 ANN-SNN转换TRM,仍然保持了原始的自注意力)—未证实SNN的特性。
SNN基本单元,即尖峰神经元(spike neuron)会接收所得到的电流并累计模电位(membrane potential),该膜电位用于和阈值比较以确定是否生成尖峰。本文使用了LIF尖峰神经元,描述如下:
其中,\(\tau\)是膜时间常数(membrane time constant),\(X[t]\)为时间步\(t\)的输入电流。当膜电位\(H(t)\)超过激发阈值(firing threshold,\(V_{th}\)),尖峰神经元将触发尖峰\(S[t]\)。\(\Theta(v)\)是Heaviside阶跃函数(\(v\ge0\)时为1,否则为0);\(V[t]\)表示触发事件之后的膜电位,如果不产生尖峰,则其等于\(H[t]\),否则会等于复位电位\(V_{reset}\)。
架构解释
总体框架
给定二维图像序列\(I\in \mathbb R^{T\times C\times H\times W}\),Spiking Patch Spliting(SPS)模块将其线性投影到一个D维尖峰状特征向量上,并将其分割为\(N\)个展开的尖峰形状块(flattened spike-form patches)\(x\)。
浮点形式的位置嵌入(position embedding)不可用于SNN中,我们采用了条件位置嵌入生成器(conditional position embedding generator)来生成尖峰形式的相对位置嵌入(relative position embedding,RPE),并将RPE添加到块序列\(x\)来得到\(X_0\)。条件位置编码生成器包含内核大小为\(3\)的二维卷积层(Conv2D)、批归一化层(BN)和尖峰神经元层(SN)。
将\(X_0\)传递到\(L\)块Spikformer编码器中,该编码器由尖峰自注意力(SSA)和MLP块组成,在SSA和MLP中应用了残差连接。
作为Spikformer编码器块中的主要组件,SSA提供了一种有效的方法来使用Spike-form的QKV,对图像的局部-全局信息进行建模,而无需softmax。全局平均池化(global average pooling)被用于从Spikformer编码器处理的特征中输出D维特征,该D维特征会被送入全连接层分类头(classification head,CH)来输出预测值Y。
SPS
尖峰块分离模块(SPS)用于将图像线性投影到\(D\)维度的尖峰形式特征(spike-form feature),并将特征拆分为固定大小的块(patches)。与Vision TRM中的卷积骨干(convolution stem)类似,本文在每个SPS块中应用了卷积层来引入归纳偏置到Spikformer中。给定图像序列\(I\in \mathbb R ^{T\times C\times H\times W}\):
其中,Conv2D和MP表示步长1、核大小3的二维卷积层和最大池化,SPS的数目可以大于1。当使用多个SPS块时,卷积层的输出通道数目增加,并最终匹配块的嵌入维度(embedding dimension)。给定嵌入维度D和四块SPS模块,四个卷积层中的输出通道数目为\(D/8,D/4,D/2,D\)。二维最大池化层被应用于在具有固定大小的SPS块后对特征大小进行下采样。在SPS处理后,I被分割为图像块序列\(x\in \mathbb R^{T\times N \times D}\)。
尖峰自注意力机制
Vanllia Self-attention难以应用于SNNs中,主要存在以下两个原因:浮点矩阵乘法\(Q_F,K_F\)和softmax函数(包含指数计算和除法运算,不符合SNN的计算规则);VSA序列长度的二次空间复杂度和时间复杂度不满足SNN的高效计算要求。
首先通过可学习矩阵计算查询、键和值,然后通过不同的尖峰神经元层来成为尖峰序列(spikin sequences):
其中,\(Q,K,V\in \mathbb R^{T\times N \times D}\),本文认为注意力矩阵的计算过程应使用纯尖峰形式的Q和K(只包含0和1)。受原始自注意力启发,我们加入了缩放因子\(s\)来控制矩阵乘法结果的大值,\(s\)不影响SSA的属性。spike-friendly SSA定义如下:
在上式由尖峰神经元输出的\(Q,K,V\)为非负的,因此会生成非负注意力图。SSA只聚合这些相关的特征,而忽略不相干的信息。因此,SSA不需要通过softmax来保证注意力图的非负性。此外,SSN中输入\(X\)和自注意力值\(V\)为尖峰形式,包含有限信息;浮点形式的\(QK\)和注意力softmax对于建模尖峰形式的\(X,V\)时冗余的,不能从\(X,V\)中获得更多信息,即SSA比VSA更适合于SNN。
实验
实验数据集:使用静态数据集CIFAR,ImageNet和神经形态数据集(neuromorphic datasets)如CIFAR10-DVS,DVS128 Gesture来评估Spikformer。
静态数据集
ImageNet:使用130万张1000类的图像用于训练,5万张图像用于验证。我们在ImageNet上的模型的输入大小被设置为默认的224×224。优化器是AdamW,在310个训练阶段中,批量大小设置为128或256,余弦衰减学习率的初始值为0.0005。在ImageNet和CIFAR上训练时,缩放因子为0.125。四块SPS将图像分割为196个16×16的块。【训练实验中使用了标准数据增广方法,如随机增强,混合和剪切混合等。
CIFAR:提供50,000张训练图像和10,000张测试图像,分辨率为32×32。批量大小设置为128。四块SPS(前两个块不包含最大池化层)将图像分割为64个4 × 4块。