
深入Scikit-learn:掌握Python最强大的机器学习库
本篇博客详细介绍了Python机器学习库Scikit-learn的使用方法和主要特性。内容涵盖了如何安装和配置Scikit-learn,Scikit-learn的主要特性,如何进行数据预处理,如何使用监督学习和无监督学习算法,以及如何评估模型和进行参数调优。本文旨在帮助读者深入理解Scikit-learn,并有效地应用在实际的机器学习任务中。

引言
在人工智能大潮的推动下,机器学习作为一项核心技术,其重要性无需过多强调。然而,如何快速高效地开展机器学习实验与开发,则是许多科研工作者和工程师们面临的挑战。Python作为一种简洁易读、拥有丰富科学计算库的编程语言,已广泛应用于机器学习领域。而在Python的众多机器学习库中,Scikit-learn以其全面的功能、优良的性能和易用性,赢得了众多用户的喜爱。在本篇文章中,我们将深入探讨Scikit-learn的使用方法和内部机制,帮助读者更好地利用这一工具进行机器学习实验。
机器学习与Scikit-learn的重要性

机器学习作为一种能够从数据中自动分析获得模型,然后利用模型对未知数据进行预测的技术,正越来越广泛地应用于生活中的各个方面,包括搜索引擎、自动驾驶、人脸识别、语音识别等领域。在众多的机器学习工具中,Scikit-learn以其丰富的算法库、优雅的API设计、出色的性能表现,以及活跃的社区支持,使得它在科研界和工业界都得到了广泛的应用。
Scikit-learn的基本概述
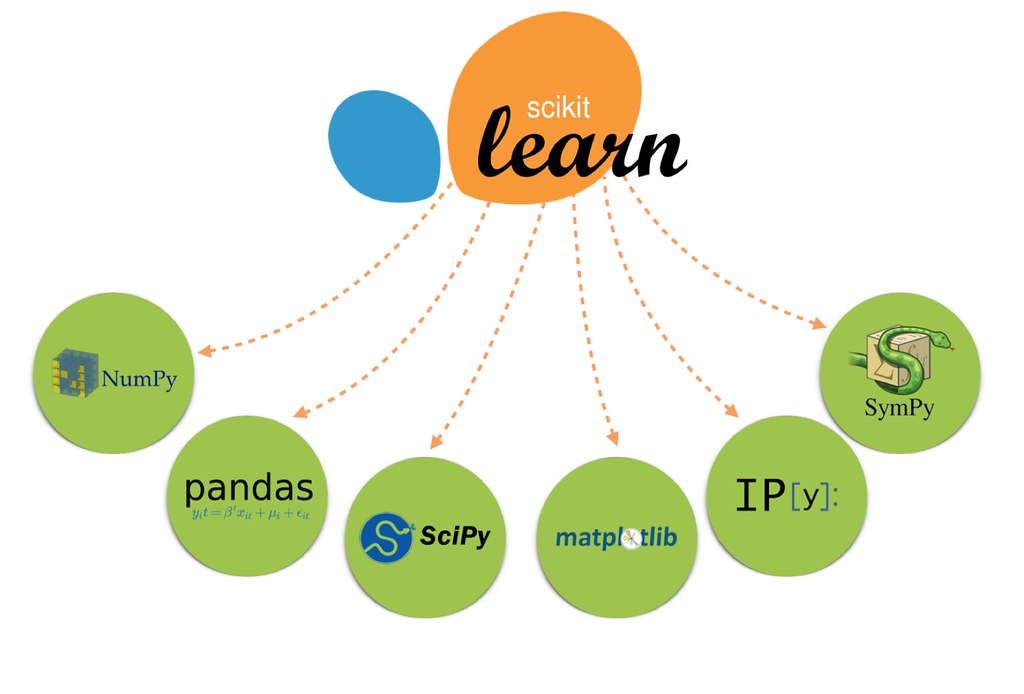
Scikit-learn是一个基于Python的开源机器学习库,它基于NumPy、SciPy和matplotlib,支持各种机器学习模型,包括分类、回归、聚类和降维等。除了提供大量的机器学习算法外,Scikit-learn还包括了一整套模型评估和选择的工具,以及数据预处理和数据分析的功能。简单易用却功能强大,是Scikit-learn受欢迎的重要原因。在接下来的文章中,我们将详细介绍如何使用Scikit-learn进行机器学习开发。
这部分将为读者提供机器学习和Scikit-learn的基础概念,以及它们在现代技术领域中的应用和重要性。随后,我们将详细探索Scikit-learn库的主要特性和功能,以及如何使用它进行数据处理和机器学习模型的构建,优化和评估。
安装和配置
在开始使用Scikit-learn之前,我们需要先进行安装和配置。在这个部分,我们将详细介绍如何在Python环境中安装Scikit-learn,以及如何安装必要的依赖库。
如何安装Scikit-learn
Scikit-learn可以很方便地通过Python的包管理器pip进行安装。打开终端或命令行界面,输入以下命令:
pip install -U scikit-learn
这条命令会安装或者升级Scikit-learn到最新版本。如果你正在使用特定的Python环境,例如Anaconda,你也可以通过conda进行安装:
conda install scikit-learn
安装必要的依赖库
Scikit-learn的运行需要依赖一些Python库,包括NumPy和SciPy。这些库一般来说在安装Scikit-learn的时候会自动安装。如果没有自动安装,或者需要更新到最新版本,可以使用以下命令:
pip install -U numpy scipy
此外,为了进行数据处理和可视化,我们通常还需要安装pandas和matplotlib。同样,可以通过以下命令进行安装:
pip install -U pandas matplotlib
以上的安装过程适用于大部分情况。如果你在安装过程中遇到任何问题,可以参考Scikit-learn的官方文档,或者在相关的论坛和社区寻求帮助。安装完成后,你就可以开始使用Scikit-learn进行机器学习的学习和开发了。
Scikit-learn的主要特性
Scikit-learn作为一个功能强大的Python机器学习库,其设计理念着重于易用性和统一性。接下来,我们将逐一介绍Scikit-learn的主要特性。
强大的预处理功能
在机器学习的流程中,数据预处理是必不可少的一步。Scikit-learn提供了丰富的数据预处理功能,包括数据清洗、编码、标准化、特征提取和特征选择等。
from sklearn import preprocessing
# 以数据标准化为例,以下是使用Scikit-learn进行标准化的代码
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
scaler = preprocessing.StandardScaler().fit(X)
print(scaler.transform(X))
众多的机器学习算法

Scikit-learn提供了各种常用的监督学习和无监督学习算法,包括回归、分类、聚类、降维等。这些算法的API设计统一且一致,使得在不同的算法间切换变得非常简单。
from sklearn import svm
# 以SVM为例,以下是使用Scikit-learn进行模型训练和预测的代码
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
print(clf.predict([[2., 2.]]))
效果评估和模型选择
Scikit-learn也提供了一套完善的模型评估和选择工具,包括交叉验证、网格搜索和多种评估指标。
from sklearn import metrics
from sklearn.model_selection import cross_val_score
# 以交叉验证为例,以下是使用Scikit-learn进行交叉验证的代码
scores = cross_val_score(clf, X, y, cv=5)
print(scores)
可视化工具
尽管Scikit-learn本身不提供绘图功能,但是它可以很好地与matplotlib等Python绘图库配合使用,以实现数据和模型效果的可视化。
import matplotlib.pyplot as plt
from sklearn import datasets
# 以下是一个简单的Scikit-learn数据可视化示例
iris = datasets.load_iris()
X = iris.data[:, :2] # 我们只取前两个特征
y = iris.target
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
以上就是Scikit-learn的主要特性。在接下来的部分,我们将详细介绍如何利用这些特性进行机器学习的各个阶段的工作。
Scikit-learn的数据预处理
在机器学习任务中,数据预处理是一项非常重要的工作。预处理包括数据清洗、数据转换、特征提取等步骤,以将原始数据转化为适合机器学习模型使用的格式。Scikit-learn提供了一套强大的数据预处理工具,以满足这些需求。
数据清洗
数据清洗主要包括处理缺失值和异常值。Scikit-learn提供了Imputer类,用于处理缺失值。以下是使用Imputer的一个简单示例:
from sklearn.impute import SimpleImputer
# 假设我们的数据集中有缺失值NaN
import numpy as np
X = [[1, 2], [np.nan, 3], [7, 6]]
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
print(imp.fit_transform(X))
数据转换
数据转换主要包括标准化、归一化、二值化等步骤。Scikit-learn提供了preprocessing模块,用于完成这些任务。
from sklearn import preprocessing
# 数据标准化示例
X = [[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]]
scaler = preprocessing.StandardScaler().fit(X)
print(scaler.transform(X))
# 数据归一化示例
X_normalized = preprocessing.normalize(X, norm='l2')
print(X_normalized)
特征提取和特征选择
Scikit-learn提供了一系列的方法用于特征提取和特征选择。特征提取主要用于将原始数据转换为特征向量,特征选择则用于从原始特征中选择最有价值的特征。
from sklearn.feature_extraction.text import CountVectorizer
# 特征提取示例:文本数据转换为词频向量
corpus = ['This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
# 特征选择示例:使用卡方检验选择最好的特征
from sklearn.feature_selection import SelectKBest, chi2
X, y = [[1, 2], [3, 4], [5, 6], [7, 8]], [0, 0, 1, 1]
X_new = SelectKBest(chi2, k=1).fit_transform(X, y)
print(X_new)
通过上述的预处理工作,我们可以将原始数据转换为适合机器学习模型使用的格式,这是进行机器学习的基础。在下一部分,我们将讨论如何使用Scikit-learn的API进行机器学习模型的构建和训练。
Scikit-learn中的监督学习算法
监督学习是机器学习中最常见的任务之一,包括分类和回归两种类型。Scikit-learn提供了一系列的监督学习算法,包括常见的线性模型、决策树、支持向量机等。以下将为大家展示如何在Scikit-learn中使用这些算法。
线性模型
线性模型是一种常见的监督学习算法,用于解决回归和分类问题。Scikit-learn中的linear_model模块提供了一系列的线性模型,包括线性回归、逻辑回归、岭回归等。
from sklearn.linear_model import LinearRegression
# 创建数据
X = [[1, 1], [1, 2], [2, 2], [2, 3]]
y = [1, 1, 2, 2]
# 创建线性回归模型并训练
reg = LinearRegression().fit(X, y)
# 进行预测
print(reg.predict([[3, 5]]))
决策树
决策树是一种简单而有效的分类和回归方法。Scikit-learn中的tree模块提供了决策树的实现。
from sklearn import tree
# 创建数据
X = [[0, 0], [1, 1]]
Y = [0, 1]
# 创建决策树模型并训练
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
# 进行预测
print(clf.predict([[2., 2.]]))
支持向量机
支持向量机(SVM)是一种强大的分类方法,同时也可以用于解决回归问题。Scikit-learn中的svm模块提供了SVM的实现。
from sklearn import svm
# 创建数据
X = [[0, 0], [1, 1]]
y = [0, 1]
# 创建SVM模型并训练
clf = svm.SVC()
clf.fit(X, y)
# 进行预测
print(clf.predict([[2., 2.]]))
Scikit-learn中还包括了许多其他的监督学习算法,如神经网络、集成方法等。这些方法的使用方式与上述类似,都遵循了Scikit-learn的统一API设计。在实际使用中,我们可以根据数据的特性和问题的需要,选择合适的算法进行学习。
Scikit-learn中的无监督学习算法
无监督学习是指在没有标签的情况下对数据集进行学习,主要包括聚类和降维等任务。Scikit-learn提供了丰富的无监督学习算法。接下来,我们将介绍其中的一部分。
聚类
聚类是无监督学习的一种常见任务,其目标是将相似的样本聚集在一起。Scikit-learn提供了多种聚类算法,如K-means,谱聚类,DBSCAN等。
from sklearn.cluster import KMeans
# 创建数据
X = [[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]
# 创建KMeans模型并训练
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# 查看聚类结果
print(kmeans.labels_)
降维
降维是无监督学习的另一种常见任务,其目标是将高维数据映射到低维空间,以便于数据的理解和可视化。Scikit-learn提供了多种降维算法,如PCA,t-SNE,等。
from sklearn.decomposition import PCA
# 创建数据
X = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 创建PCA模型并训练
pca = PCA(n_components=2)
pca.fit(X)
# 查看降维结果
print(pca.transform(X))
Scikit-learn还提供了许多其他的无监督学习算法,如关联规则学习,异常检测等。这些算法在处理特定问题时可以发挥巨大的作用,使得Scikit-learn在处理各种机器学习任务时具有很强的灵活性。
评估模型和参数调优
创建并训练了机器学习模型后,我们需要对其性能进行评估,并对模型参数进行调优,以达到最佳的学习效果。Scikit-learn提供了一系列的工具用于模型评估和参数调优。
模型评估
Scikit-learn提供了多种用于模型评估的方法,包括交叉验证、计算精度、召回率、F1分数等。
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 创建模型
clf = RandomForestClassifier(random_state=7)
# 交叉验证
scores = cross_val_score(clf, X, y, cv=5)
print("Cross-validation scores: ", scores)
# 训练模型
clf.fit(X, y)
# 预测结果
y_pred = clf.predict(X)
# 计算各项评价指标
print(classification_report(y, y_pred))
参数调优
Scikit-learn提供了GridSearchCV和RandomizedSearchCV等工具用于进行参数调优。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 参数空间
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf']}
# 创建SVC模型
svc = SVC()
# 创建GridSearchCV对象并训练
grid = GridSearchCV(svc, param_grid, refit=True, verbose=2)
grid.fit(X, y)
# 输出最优参数
print(grid.best_params_)
通过上述的评估和调优,我们可以得到最优的模型和参数。在实际的机器学习任务中,模型评估和参数调优是非常重要的步骤,它们能够显著提高模型的性能和准确率。
结论
Scikit-learn是一个强大且易用的Python库,它为我们提供了一整套的机器学习工具,可以用于解决从数据预处理,到模型训练,再到模型评估和参数调优的全流程任务。Scikit-learn的广泛应用,不仅仅因为它的功能强大,更因为它的设计理念——统一的API,使得我们可以快速地切换不同的模型和算法,而不需要对代码进行大的修改。这种灵活性和易用性,使得Scikit-learn成为了Python机器学习库的首选。
但是,我们也需要注意,虽然Scikit-learn提供了一系列的工具,但是每个工具都有其适用的场景和条件。我们在使用Scikit-learn的过程中,需要深入理解每个工具的原理和特性,才能在不同的任务和数据上,选择合适的工具,得到最好的效果。
希望通过这篇博客,你对Scikit-learn有了更深入的了解,对如何使用Scikit-learn有了更清晰的认识。如果你对机器学习有兴趣,那么Scikit-learn将是你的必备工具。
如有帮助,请多关注
个人微信公众号:【TechLead】分享AI与云服务研发的全维度知识,谈谈我作为TechLead对技术的独特洞察。
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。