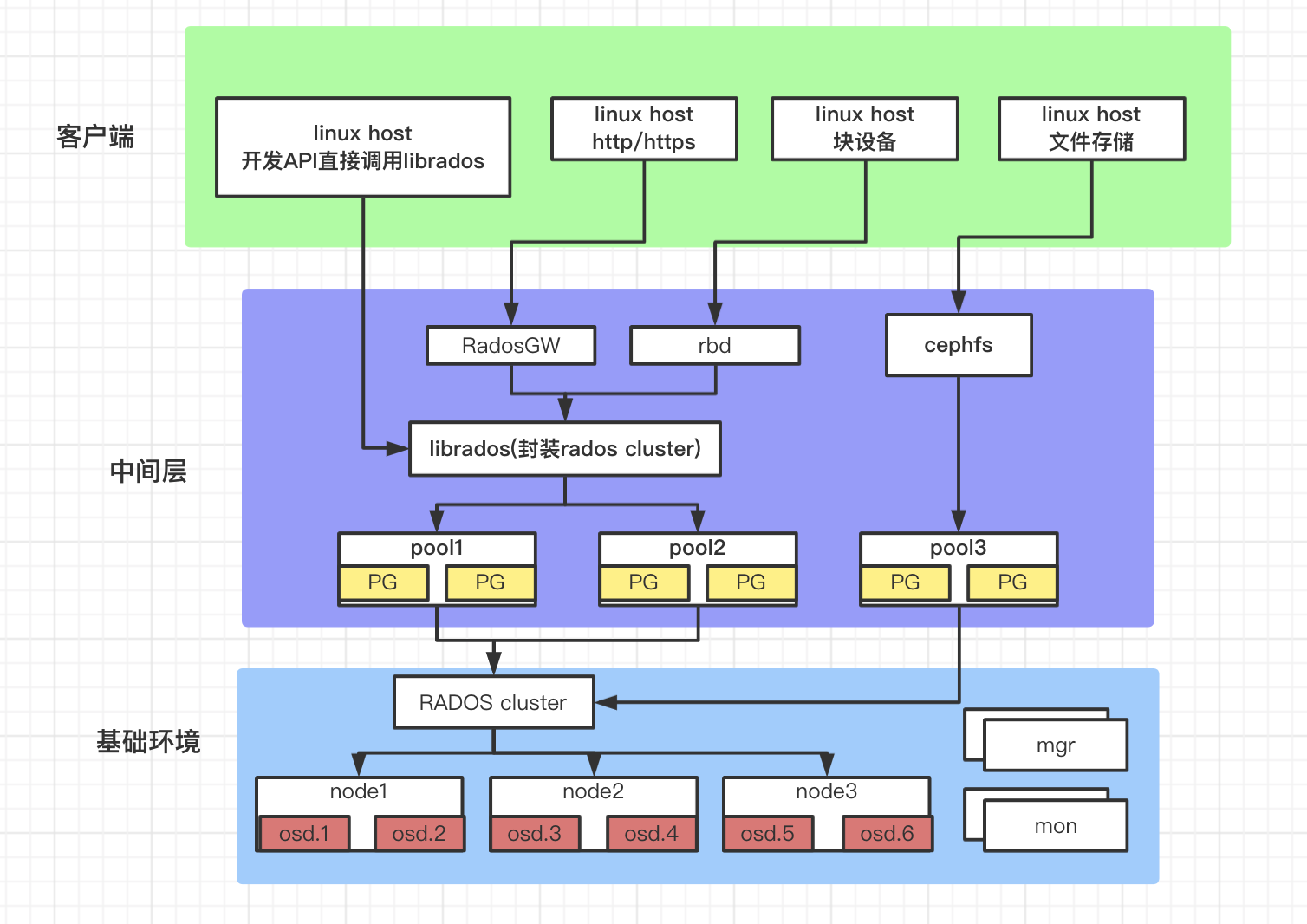
| 名称 | 作用 |
|---|---|
| osd | 全称Object Storage Device,主要功能是存储数据、复制数据、平衡数据、恢复数据等。每个OSD间会进行心跳检查,并将一些变化情况上报给Ceph Monitor。 |
| mon | 全称Monitor,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,根据Map图和object id等计算出数据最终存储的位置。 |
| mgr | 全称Manager,负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。 |
| mds | 全称是MetaData Server,主要保存的文件系统服务的元数据,如果使用cephfs功能才会启用它,对象存储和块存储设备是不需要使用该服务。 |
| rgw | 全称radosgw,是一套基于当前流行的RESTFUL协议的网关,ceph对象存储的入口,内嵌civetweb服务,不启用对象存储,则不需要安装。 |
ceph配置文件
标准位置:/etc/ceph/ceph.conf
组成部分:
## 全局配置,全局生效[global]fsid = 537175bb-51de-4cc4-9ee3-b5ba8842bff2public_network = 10.0.0.0/8cluster_network = 10.0.0.0/8mon_initial_members = ceph-node1mon_host = 10.153.204.xx:6789,10.130.22.xx:6789,10.153.204.xx:6789auth_cluster_required = cephxauth_service_required = cephxauth_client_required = cephx## osd专用配置,可以使用osd.num 来表示具体的哪一个osd[osd][osd.1]## monitor专用配置,可以使用mon.A 来表示具体的哪一个monitor,其中A表示该节点的名称,使用ceph mon dump可以查看。[mon][mon.a]## 客户端专用配置[client] ceph配置文件的加载顺序:
存储池类型
如何查看某个存储池为什么类型:
$ ceph osd pool get test crush_rulecrush_rule: erasure-code副本池IO
读写数据:
## 读数据1.客户端发送读请求,RADOS 将请求发送到主 OSD。2.主 OSD 从本地磁盘读取数据并返回数据,最终完成读请求。## 写数据1.客户端APP请求写入数据,RADOS发送数据到主OSD。2.主OSD写入完毕后将完成信号给客户端APP,并发送数据到各副本OSD。3.副本OSD写入数据,并发送写入完成信号给主OSD。纠删码池 IO
读写数据:
## 读数据1.从相应的 OSDs 中获取数据后进行解码2.如果此时有数据丢失,Ceph 会自动从存放校验码的 OSD 中读取数据进行解码3.完成数据解码后返回数据## 写数据1.数据将在主 OSD 进行编码然后分发到相应的 OSDs 上去2.计算合适的数据块并进行编码3.对每个数据块进行编码并写入OSDPG与PGP
归置组(placement group)是用于跨越多osd将数据存储在每个存储池中的内部数据结构。 pg 在 osd 守护进程和 ceph 客户端之间的一个中间层,hash 算法负责将每个对象动态映射到一个pg中,此pg即为主pg,按照存储池的副本数量(例如3个)会再将每个主pg再复制出两个副本pg,CRUSH 算法负责将 三个 pg 动态映射到三个不同的 OSD 守护进程中,此三个pg组成一个pgp,从而在 osd 中达到多副本高可用。
文件寻址流程大致如下图所示:
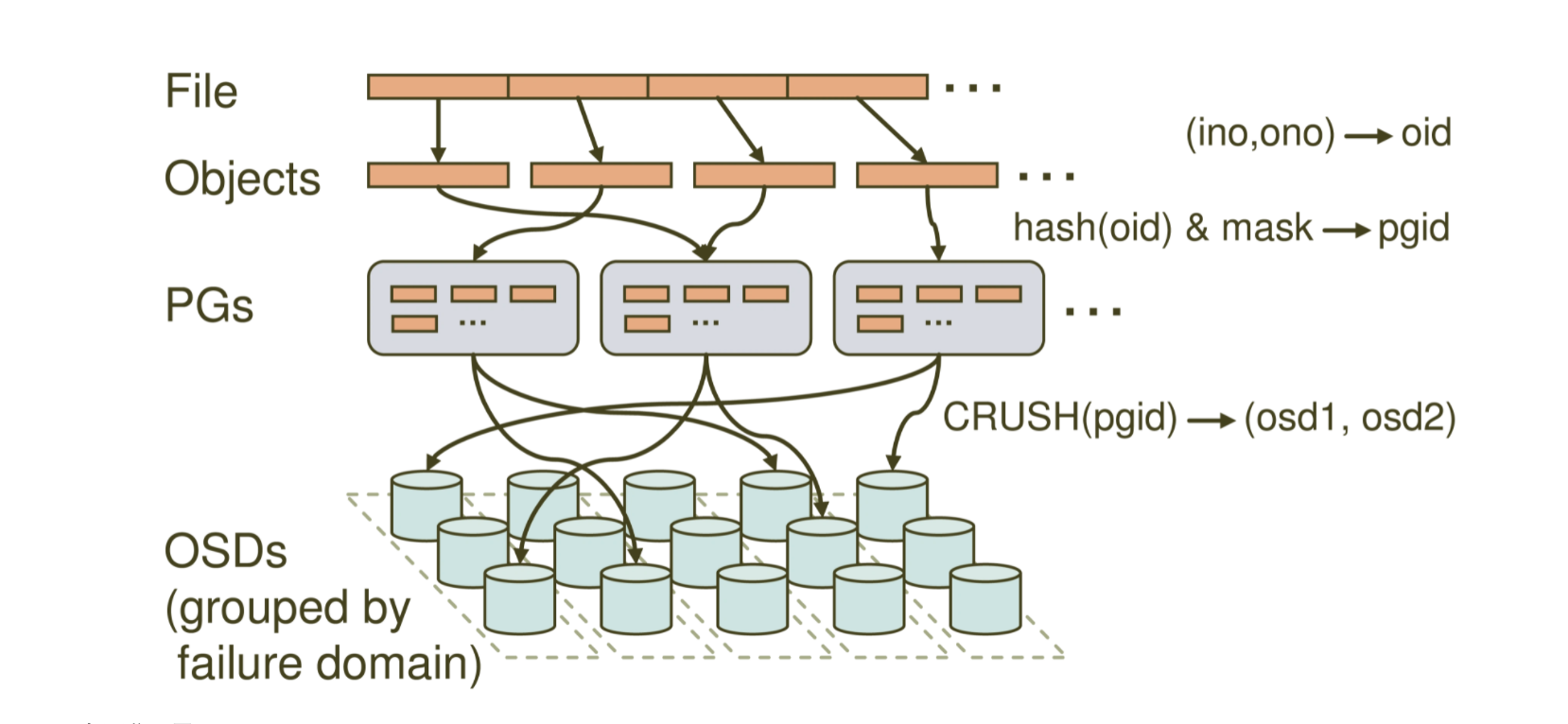
File->Objects->PGs->OSDs。
需要注意的几个点:
PG的分配计算:
官方建议:每个osd中的pg数量最好不要超过100个,公式:Total PGS = (Total_number_of _osd * 100) / max_replication_count
具体算法:举例现在有12台osd机器,我需要创建20个存储池。
此时pg总数为:12 * 100 / 3 = 400
平均每个存储池分配pg数量为:400 / 20 = 20
这里计算出,平均每个存储池可以分配20个pg,但每个存储池pg的个数推荐为2的N次幂,故2、4、8、16、32、64、128等,这时要结合具体的pool是来存储什么,大概能存储多少数据来进行一个简单的转换,如果此pool只存储一些元数据,则分配4即可,反之数据量比较大的,可以分配16、32等。
另外pool中pg个数是推荐用2的整数次幂,也可以不用,但会有警告提示。
PG与PGP组合:
查看replicapool池的pg、pgp数量
$ ceph osd pool get replicapool pg_num pg_num: 32$ ceph osd pool get replicapool pgp_num pgp_num: 32查看replicapool池的pg、pgp分布
$ ceph pg ls-by-pool replicapool | awk '{print $1,$2,$15}'PG OBJECTS ACTING2.0 596 [3,1,0]p32.1 623 [3,4,0]p32.2 570 [3,4,0]p32.3 560 [3,4,0]p32.4 630 [0,3,4]p02.5 574 [4,0,3]p42.6 572 [4,3,0]p42.7 572 [3,4,0]p32.8 622 [3,4,0]p32.9 555 [0,3,4]p02.a 523 [1,3,0]p12.b 574 [4,3,0]p42.c 620 [4,3,0]p42.d 637 [1,3,0]p12.e 522 [0,3,4]p02.f 599 [4,3,0]p42.10 645 [4,3,0]p42.11 534 [3,4,0]p32.12 622 [4,3,0]p42.13 577 [1,3,0]p12.14 661 [3,4,0]p32.15 626 [1,3,0]p12.16 585 [2,4,0]p22.17 610 [3,4,0]p32.18 610 [4,2,0]p42.19 560 [4,3,0]p42.1a 599 [3,4,0]p32.1b 614 [1,2,0]p12.1c 581 [4,3,0]p42.1d 614 [4,3,0]p42.1e 595 [0,3,1]p02.1f 572 [3,4,0]p3 * NOTE: afterwardsPG的状态解释:
在osd扩缩容或者一些特殊情况的时候,ceph会以pg为整体进行rebalancing数据重平衡,此时pg会出现很多不同的状态,例如:
$ ceph -s cluster: id: 537175bb-51de-4cc4-9ee3-b5ba8842bff2 health: HEALTH_WARN Degraded data redundancy: 152/813 objects degraded (18.696%), 43 pgs degraded, 141 pgs undersized services: mon: 2 daemons, quorum yq01-aip-aikefu10,bjkjy-feed-superpage-gpu-04 (age 111s) mgr: yq01-aip-aikefu10(active, since 11d), standbys: bjkjy-feed-superpage-gpu-04 mds: mycephfs:1 {0=ceph-node2=up:active} 1 up:standby osd: 8 osds: 8 up (since 3d), 8 in (since 3d); 124 remapped pgs rgw: 2 daemons active (ceph-node1, ceph-node2) task status: data: pools: 8 pools, 265 pgs objects: 271 objects, 14 MiB usage: 8.1 GiB used, 792 GiB / 800 GiB avail pgs: 152/813 objects degraded (18.696%) 114/813 objects misplaced (14.022%) 111 active+clean+remapped 98 active+undersized 43 active+undersized+degraded 13 active+cleannoscrub 和 nodeep-scrub
数据校验时会导致读压力增大,如果扫描出数据不一致还要进行同步写,增大写的压力,因此在做扩容等操作的时候,我们会人为去设置noscrub与nodeep-scrub,暂停数据校验。查看pool是否开启清洗:
$ ceph osd pool get replicapool noscrubnoscrub: false$ ceph osd pool get replicapool nodeep-scrubnodeep-scrub: false数据压缩
如果使用 BlueStore 存储引擎,ceph 支持称为 "实时数据压缩" 即边压缩边保存数据的功能, 该功能有助于节省磁盘空间,可以在BlueStore OSD上创建的每个存储池池上启用或禁用压缩, 以节约磁盘空间,默认没有开启压缩,需要后期配置并开启:
## 开启压缩功能$ ceph osd pool set <pool name> compression_algorithm <压缩算法> 算法介绍: sanppy:默认算法,消耗cpu较少 zstd:压缩比好,但消耗 CPU lz4:消耗cpu较少 zlib:不推荐 $ ceph osd pool set replicapool compression_algorithm snappyset pool 2 compression_algorithm to snappy## 指定压缩模式$ ceph osd pool set <pool name> compression_mode <指定模式>模式介绍: none:从不压缩数据,默认值。 passive:除非写操作具有可压缩的提示集,否则不要压缩数据。 aggressive:压缩数据,除非写操作具有不可压缩的提示集。 force:无论如何都尝试压缩数据,即使客户端暗示数据不可压缩也会压缩,也就是在所有情况下都使用压缩$ ceph osd pool set replicapool compression_mode passiveset pool 2 compression_mode to passive全局压缩选项,这些可以配置到 ceph.conf 中,作用于所有存储池:
bluestore_compression_algorithm #压缩算法bluestore_compression_mode #压缩模式bluestore_compression_required_ratio #压缩后与压缩前的压缩比,默认为.875bluestore_compression_min_blob_size #小于它的块不会被压缩,默认0bluestore_compression_max_blob_size #大于它的块在压缩前会被拆成更小的块,默认 0bluestore_compression_min_blob_size_ssd #默认 8kbluestore_compression_max_blob_size_ssd #默认 64kbluestore_compression_min_blob_size_hdd #默认 128kbluestore_compression_max_blob_size_hdd #默认 512k此功能开启会影响cpu的使用率,如果环境为生产环境,不建议开启此功能。
存储池基本管理
创建存储池,格式示例
$ ceph osd pool create <poolname> pg_num pgp_num {replicated|erasure}$ ceph osd pool create study 8 8 pool 'study' created列出存储池
$ ceph osd lspools1 .rgw.root2 study重命名存储池,格式示例
$ ceph osd pool rename old-name new-name $ ceph osd pool rename study re-studypool 'study' renamed to 're-study'显示存储池用量信息
$ rados df 或者$ ceph osd df 删除存储池
## 1、ceph为了防止存储池被误删,故设置了两个机制来保护,首先要将存储池的nodelete标志为false$ ceph osd pool set re-study nodelete falseset pool 13 nodelete to true$ ceph osd pool get re-study nodeletenodelete: false## 2、第二个机制,要将mon设置为允许删除--mon-allow-pool-delete=true$ ceph tell mon.* injectargs --mon-allow-pool-delete=true injectargs:mon_allow_pool_delete = 'true' ## 3、开始删除,要写两边存储池的名字,并加参数--yes-i-really-really-mean-it$ ceph osd pool rm re-study re-study --yes-i-really-really-mean-itpool 're-study' removed存储池配额
存储池可以设置两个配对存储的对象进行限制,一个配额是最大空间(max_bytes),另外一个 配额是对象最大数量(max_objects),默认不会限制,例如:
## 查看replicapool存储池的配额情况,N/A表示不限制$ ceph osd pool get-quota replicapool quotas for pool 'replicapool': max objects: N/A max bytes : N/A ## 限制最大对象数为1000,最大byte为1000000000$ ceph osd pool set-quota replicapool max_objects 1000set-quota max_objects = 1000 for pool replicapool$ ceph osd pool set-quota replicapool max_bytes 1000000000set-quota max_bytes = 1000000000 for pool replicapool$ ceph osd pool get-quota replicapool quotas for pool 'replicapool': max objects: 1k objects max bytes : 954 MiB ## 可以再设置为不限额$ ceph osd pool set-quota replicapool max_bytes 0存储池常用参数
查看存储池对象副本数 和 最小副本数
$ ceph osd pool get replicapool sizesize: 1$ ceph osd pool get replicapool min_size min_size: 1min_size:提供服务所需要的最小副本数,默认为2,表示如果一个3副本的存储池,其中一个副本所在的osd坏掉了,那么还剩两副本,可以正常工作,但如果再坏掉一个,只剩下一个副本,则此存储池不能正常提供服务。
查看存储池pg、pgp数量
$ ceph osd pool get replicapool pg_num pg_num: 32$ ceph osd pool get replicapool pgp_num pgp_num: 32控制是否可以更改存储池的pg、pgp、存储大小
$ ceph osd pool get replicapool nopgchangenopgchange: false$ ceph osd pool get replicapool nosizechangenosizechange: false轻量扫描和深层扫描管理
## 关闭轻量扫描和深层扫描$ ceph osd pool set replicapool noscrub true$ ceph osd pool set replicapool nodeep-scrub true## 扫描的最小与最大间隔时间,默认没设置,如果需要,则要在配置文件中指定osd_scrub_min_interval xxxosd_scrub_max_interval xxxosd_deep_scrub_interval xxxceph osd默认配置查看
$ ceph daemon osd.1 config show | grep scrub