 遍历文档树&搜索文档树&CSS选择器??
遍历文档树&搜索文档树&CSS选择器?? 
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM(Document Object Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
安装:pip install bs4
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
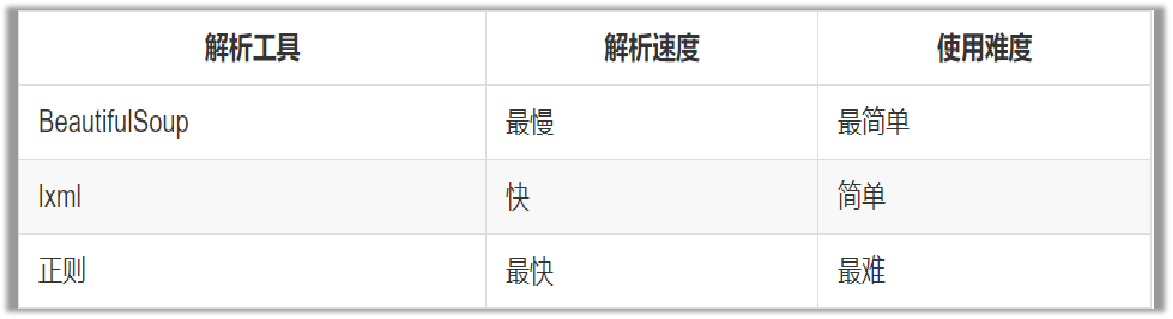
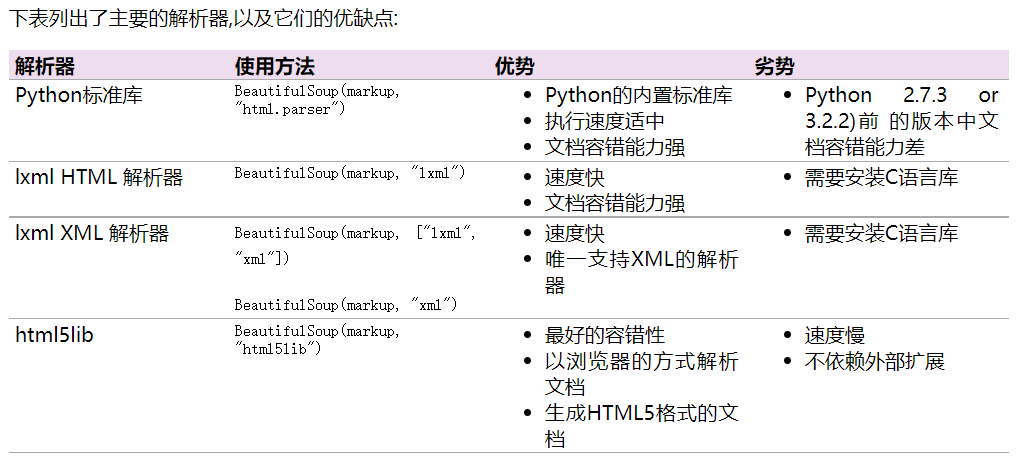
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
提示: 如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的,查看 解析器之间的区别 了解更多细节
from bs4 import BeautifulSouphtml = """<html><head><title>The Dormouse's story</title></head><body><p name="dromouse"><b>The Dormouse's story</b></p><p >Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" id="link2">Lacie</a> and<a href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p >...</p>"""soup = BeautifulSoup(html,'lxml')print(soup.prettify())Tag 通俗点讲就是 HTML 中的一个个标签。我们可以利用 soup 加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.Tag。但是注意,它查找的是在所有内容中的第一个符合要求的标签。
如果拿到标签后,还想获取标签中的内容。那么可以通过tag.string获取标签中的文字,底层继承了str对象,可以当作字符串来使用
from bs4.element import NavigableStringBeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,因为底层继承了Tag对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
from bs4 import BeautifulSoupTag , NavigableString , BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象.容易让人担心的内容是文档的注释部分
Comment 对象是一个特殊类型的 NavigableString 对象,底层继承了NavigableString ;
from bs4.element import Commentcontents和children:
异同:返回某个标签下的直接子元素,其中也包括字符串。他们两的区别是:contents返回来的是一个列表,children返回的是一个迭代器。
strings 和 stripped_strings
.strings 来循环获取 .stripped_strings 可以去除多余空白内容from bs4 import BeautifulSouphtml = """<html><head><title>The Dormouse's story</title></head><body><p name="dromouse"><b>The Dormouse's story</b></p><p >Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" id="link2">Lacie</a> and<a href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p >...</p><footer><!--注释内容--></footer> """# 实例化# soup=BeautifulSoup(html,'html.parser')soup = BeautifulSoup(html,'lxml')# print(soup) # 自动补全# print(soup.prettify()) # 美化输出'''Tag对象'''# print(type(soup.p)) # <class 'bs4.element.Tag'> ---> Tag对象# print(soup.p) # 返回第一个p标签# print(soup.p.text) # The Dormouse's story# print(soup.p.name) # 输出p标签的名字 ---> p# print(soup.title.name) # 输出title标签的名字 --->title# print(soup.p.attrs) # 输出p标签属性 -----> {'class': ['title'], 'name': 'dromouse'}# print(soup.p.get('class')) # 因为class可能有多个,所以是列表# print(soup.p['class']) # 输出p标签的属性值 ----> ['title']'''NavigableString对象,如果p标签内套了标签需要注意'''# print(type(soup.p.string)) # <class 'bs4.element.NavigableString'># print(soup.p.string) # 获取标签内容,当标签只有文本或者只有一个子文本才返回,如果有多个文本或标签返回None----->None# print(soup.p.text) # 当前标签和子子孙的文本内容拼到一起 ----->HammerZeThe Dormouse's story# print(soup.p.strings) # 把子子孙孙的文本内容放到generator -----><generator object _all_strings at 0x0000028DDAE8FA40># print(list(soup.p.strings)) # --> ['HammerZe', "The Dormouse's story"]'''BeautifulSoup对象'''# print(type(soup)) # <class 'bs4.BeautifulSoup'>'''Comment对象'''from bs4.element import Comment# print(soup.footer.string) # --->注释内容# print(type(soup.footer.string)) # <class 'bs4.element.Comment'># 嵌套选择# print(soup.head.title.string) # The Dormouse's story# 子节点、子孙节点# head_tag = soup.head# print(head_tag.contents) # 返回子节点---->[<title>The Dormouse's story</title>]# print(soup.p.contents) # p下所有子节点,放到列表中 --->[<b>The Dormouse's story</b>]# print(list(soup.p.children)) # 得到一个迭代器,包含p下所有子节点,跟contents本质一样,只是节约内存 ---> [<b>The Dormouse's story</b>]# print(list(soup.p.descendants)) # 获取子孙节点,p下所有的标签都会选择出来 子子孙孙 ---> [<b>The Dormouse's story</b>, "The Dormouse's story"]# for i,child in enumerate(soup.p.children):# print(i,child)# for i,child in enumerate(soup.p.descendants):# print(i,child)# 父节点、祖先节点# print(soup.a.parent) # 获取a标签的父节点# print(soup.a.parents) # <generator object parents at 0x000002042AD6FA40># print(list(soup.a.parents)) # 找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...# 兄弟节点print(soup.a.next_sibling) # 下一个兄弟print(soup.a.previous_sibling) # 上一个兄弟print(list(soup.a.next_siblings)) # 下面的兄弟们=>生成器对象print(soup.a.previous_siblings) # 上面的兄弟们=>生成器对象find和find_all方法:
搜索文档树,一般用得比较多的就是两个方法,一个是find,一个是find_all。
find方法是找到第一个满足条件的标签后就立即返回,只返回一个元素。
find_all方法是把所有满足条件的标签都选到,然后返回回去。
通过下标获取:通过标签的下标的方式。
href = a['href']通过attrs属性获取:示例代码:
href = a.attrs['href']demo1
#--coding:utf-8--from bs4 import BeautifulSouphtml = """<table cellpadding="0" cellspacing="0"> <tbody> <tr > <td width="374">职位名称</td> <td>职位类别</td> <td>人数</td> <td>地点</td> <td>发布时间</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td> <td>技术类</td> <td>2</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td> <td>技术类</td> <td>2</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-25</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td> <td>技术类</td> <td>4</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr > <td ><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> <tr > <td ><a id="test" target='_blank' href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td> <td>技术类</td> <td>1</td> <td>深圳</td> <td>2017-11-24</td> </tr> </tbody></table>"""soup = BeautifulSoup(html,'lxml')# 1. 获取所有tr标签# trs = soup.find_all('tr') # 列表# for tr in trs:# print(tr)# print('-'*50)# 2. 获取第2个tr标签# print(soup.find_all('tr', limit=2)[1])# 3. 获取所有class等于even的tr标签# trs = soup.find_all('tr',class_ = 'even')# trs = soup.find_all('tr',attrs={'class':'even'})# for tr in trs:# print(tr)# print('-'*50)# 4. 将所有id等于test,class也等于test的a标签提取出来。# list = soup.find_all('a',id= 'test',class_='test')# for a in list:# print(a)# 5. 获取所有a标签的href属性# alist = soup.find_all('a')# for a in alist:# #1.# # href = a['href']# # print(href)# #2.# href = a.attrs['href']# print(href)# 6. 获取所有的职位信息(纯文本)trs = soup.find_all('tr')[1:]# print(trs)lists = []for tr in trs: info = {} tds = tr.find_all('td') # print(tds) name = tds[0].string category = tds[1].string info['name']=name info['category']=category # infos = list(tr.stripped_strings) infos =tr.get_text() print(infos) lists.append(info)print(lists)demo2
from bs4 import BeautifulSouphtml_doc = """<html><head><title>The Dormouse's story</title></head><body><p id="id_p">lqz<b>The Dormouse's story</b></p><p >Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" id="link1">Elsie</a>,<a href="http://example.com/lacie" id="link2">Lacie</a> and<a href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p >...</p>"""soup = BeautifulSoup(html_doc, 'lxml')# 1、五种过滤器: 字符串、正则表达式、列表、True、方法# find:找到第一个 find_all:找所有# 字符串 --->value值是字符串# res=soup.find_all(name='p')# res=soup.find(id='id_p')# res=soup.find_all(class_='story')# res=soup.find_all(name='p',class_='story') # and条件# res=soup.find(name='a',id='link2').text# res=soup.find(name='a',id='link2').attrs.get('href')# res=soup.find(attrs={'id':'link2','class':'sister'}).attrs.get('href')# print(res)# 正则表达式--->value是正则表达式# import re## # res=soup.find_all(name=re.compile('^b'))# # res=soup.find_all(href=re.compile('^http'))# res=soup.find_all(class_=re.compile('^s'))# print(res)# 列表 value值是列表# res=soup.find_all(name=['body','a'])# res=soup.find_all(class_=['sister','story'])# res=soup.find_all(id=['link2','link3'])# print(res)# True value值是True# res=soup.find_all(name=True)# res=soup.find_all(id=True)# res=soup.find_all(href=True)# print(res)# 方法# def has_class_but_no_id(tag):# return tag.has_attr('class') and not tag.has_attr('id')## print(soup.find_all(name=has_class_but_no_id)) # 有class但是没有id的标签#1 html页面中,只要有的东西,通过bs4都可以解析出来#2 遍历文档树+搜索文档树混用# def has_class_but_no_id(tag):# return tag.has_attr('class') and not tag.has_attr('id')# print(soup.find(name=has_class_but_no_id).a.text)# 3 find_all的其他参数limit:限制取几条 recursive:是否递归查找# def has_class_but_no_id(tag):# return tag.has_attr('class') and not tag.has_attr('id')# res=soup.find_all(name=has_class_but_no_id,limit=1)## print(res)## res=soup.find_all(name='a',recursive=False) #不递归查找,速度快,只找一层# print(res)使用以上方法可以方便的找出元素。但有时候使用css选择器的方式可以更加的方便。使用css选择器的语法,应该使用select方法。以下列出几种常用的css选择器方法:
print(soup.select('a'))通过类名,则应该在类的前面加一个.。比如要查找class=sister的标签。示例代码如下:
print(soup.select('.sister'))通过id查找,应该在id的名字前面加一个#号。示例代码如下:
print(soup.select("#link1"))组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开:
print(soup.select("p #link1"))直接子标签查找,则使用 > 分隔:
print(soup.select("head > title"))查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。示例代码如下:
print(soup.select('a[href="http://example.com/elsie"]'))以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')print(type(soup.select('title')))print(soup.select('title')[0].get_text())for title in soup.select('title'): print(title.get_text())# 终极大招import requestsresponse=requests.get('https://www.runoob.com/cssref/css-selectors.html')soup=BeautifulSoup(response.text,'lxml')res=soup.select_one('#content > table > tbody > tr:nth-child(2) > td:nth-child(3)').textprint(res)