ClickHouse的由来和应用场景
docker run -d --name ybchen_clickhouse --ulimit nofile=262144:262144 \-p 8123:8123 -p 9000:9000 -p 9009:9009 --privileged=true \-v /mydata/docker/clickhouse/log:/var/log/clickhouse-server \-v /mydata/docker/clickhouse/data:/var/lib/clickhouse clickhouse/clickhouse-server:22.2.3.5默认http端口是8123,tcp端口是9000, 同步端口9009
进入容器内部查看
web可视化界面:http://ip:8123/play
命令
默认数据库最初为空,用于执行未指定数据库的命令
CREATE DATABASE shop
CREATE TABLE shop.clickstream ( customer_id String, time_stamp Date, click_event_type String, page_code FixedString(20), source_id UInt64) ENGINE = MergeTree()ORDER BY (time_stamp)
INSERT INTO shop.clickstreamVALUES ('customer1', '2021-10-02', 'add_to_cart', 'home_enter', 568239 )
SELECT * FROM shop.clickstream
SELECT * FROM shop.clickstream WHERE time_stamp >= '2001-11-01'
有符号整型范围Int8 — [-128 : 127]Int16 — [-32768 : 32767]Int32 — [-2147483648 : 2147483647]Int64 — [-9223372036854775808 : 9223372036854775807]Int128 — [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727]Int256 — [-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967]无符号整型范围UInt8 — [0 : 255]UInt16 — [0 : 65535]UInt32 — [0 : 4294967295]UInt64 — [0 : 18446744073709551615]UInt128 — [0 : 340282366920938463463374607431768211455]UInt256 — [0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]需要要求更高的精度的数值运算,则需要使用定点数
一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal
Clickhouse提供了Decimal32,Decimal64,Decimal128三种精度的定点数
用Decimal(P,S)来定义:
例子:Decimal(10,2) 小数部分2位,整数部分 8位(10-2)
也可以使用Decimal32(S)、Decimal64(S)和Decimal128(S)的方式来表示
CREATE TABLE shop.clickstream1 ( customer_id String, time_stamp Date, click_event_type String, page_code FixedString(20), source_id UInt64, money Decimal(2,1)) ENGINE = MergeTree()ORDER BY (time_stamp)INSERT INTO shop.clickstream1VALUES ('customer1', '2021-10-02', 'add_to_cart', 'home_enter', 568239,2.11 )61f0c404-5cb3-11e7-907b-a6006ad3dba0
要生成UUID值,ClickHouse提供了 generateuidv4 函数。
如果在插入新记录时未指定UUID列的值,则UUID值将用零填充
00000000-0000-0000-0000-000000000000
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLogINSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1'类似MySQL的Char类型,属于定长字符,固定长度 N 的字符串(N 必须是严格的正自然数)
如果字符串包含的字节数少于`N’,将对字符串末尾进行空字节填充。
如果字符串包含的字节数大于N,将抛出Too large value for FixedString(N)异常。
当数据的长度恰好为N个字节时,FixedString类型是高效的,在其他情况下,这可能会降低效率
应用场景
Date
DateTime
DateTime64
包括 Enum8 和 Enum16 类型,Enum 保存 'string'= integer 的对应关系
在 ClickHouse 中,尽管用户使用的是字符串常量,但所有含有 Enum 数据类型的操作都是按照包含整数的值来执行。这在性能方面比使用 String 数据类型更有效。
Enum8 用 'String'= Int8 对描述。Enum16 用 'String'= Int16 对描述。创建一个带有一个枚举 Enum8('home' = 1, 'detail' = 2, 'pay'=3) 类型的列
CREATE TABLE t_enum( page_code Enum8('home' = 1, 'detail' = 2,'pay'=3))ENGINE = TinyLog'home'或`'detail' 或 'pay'。如果您尝试保存任何其他值,ClickHouse 抛出异常#插入成功INSERT INTO t_enum VALUES ('home'), ('detail')#插入报错INSERT INTO t_enum VALUES ('home1')#查询SELECT * FROM t_enumCREATE TABLE shop.clickstream2 ( customer_id String, time_stamp Date, click_event_type String, page_code FixedString(20), source_id UInt64, money Decimal(2,1), is_new Bool) ENGINE = MergeTree()ORDER BY (time_stamp)DESCRIBE shop.clickstream2INSERT INTO shop.clickstream2VALUES ('customer1', '2021-10-02', 'add_to_cart', 'home_enter', 568239, 3.8,1)select * from system.data_type_families

| ClickHouse | Mysql | 说明 |
|---|---|---|
| UInt8 | UNSIGNED TINYINT | |
| Int8 | TINYINT | |
| UInt16 | UNSIGNED SMALLINT | |
| Int16 | SMALLINT | |
| UInt32 | UNSIGNED INT, UNSIGNED MEDIUMINT | |
| Int32 | INT, MEDIUMINT | |
| UInt64 | UNSIGNED BIGINT | |
| Int64 | BIGINT | |
| Float32 | FLOAT | |
| Float64 | DOUBLE | |
| Date | DATE | |
| DateTime | DATETIME, TIMESTAMP | |
| FixedString | BINARY |
https://clickhouse.com/docs/zh
ClickHouse语法和常规SQL语法类似,多数都是支持的
CREATE TABLE shop.clickstream3 ( customer_id String, time_stamp Date, click_event_type String, page_code FixedString(20), source_id UInt64, money Decimal(2,1), is_new Bool) ENGINE = MergeTree()ORDER BY (time_stamp)DESCRIBE shop.clickstream3
SELECT * FROM shop.clickstream3
INSERT INTO shop.clickstream3VALUES ('customer2', '2021-10-02', 'add_to_cart', 'home_enter', 568239,2.1, False ) 在OLAP数据库中,可变数据(Mutable data)通常是不被欢迎的,早期ClickHouse是不支持,后来版本才有
不支持事务,建议批量操作,不要高频率小数据量更新删除
删除和更新是一个异步操作的过程,语句提交立刻返回,但不一定已经完成了
SELECT database, table, command, create_time, is_done FROM system.mutations LIMIT 20

ALTER TABLE shop.clickstream3 UPDATE click_event_type = 'pay' where customer_id = 'customer2';
ALTER TABLE shop.clickstream3 delete where customer_id = 'customer2';
分区是表的分区,把一张表的数据分成N多个区块,分区后的表还是一张表,数据处理还是由自己来完成
PARTITION BY,指的是一个表按照某一列数据(比如日期)进行分区,不同分区的数据会写入不同的文件中
建表时加入partition概念,可以按照对应的分区字段,允许查询在指定了分区键的条件下,尽可能的少读取数据
create table shop.order_merge_tree( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =MergeTree() partition by toYYYYMMDD(create_time) order by (id,sku_id) primary key (id);最小功能的轻量级引擎,当需要快速写入许多小表并在以后整体读取它们时效果最佳,一次写入多次查询
种类
CLickhouse最强大的表引擎,有多个不同的种类
适用于高负载任务的最通用和功能最强大的表引擎,可以快速插入数据并进行后续的后台数据处理
支持主键索引、数据分区、数据副本等功能特性和一些其他引擎不支持的其他功能
种类
能够直接从其它的存储系统读取数据,例如直接读取 HDFS 的文件或者 MySQL 数据库的表,这些表引擎只负责元数据管理和数据查询
种类
Memory
Distributed
File
Merge
Set、Buffer、Dictionary等
ClickHouse 不要求主键唯一,所以可以插入多条具有相同主键的行。
如果指定了【分区键】则可以使用【分区】,可以通过PARTITION 语句指定分区字段,合理使用数据分区,可以有效减少查询时数据文件的扫描范围
在相同数据集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快,查询中指定了分区键时 ClickHouse 会自动截取分区数据,这也有效增加了查询性能
支持数据副本和数据采样
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2) ENGINE = MergeTree()ORDER BY expr[PARTITION BY expr][PRIMARY KEY expr][SAMPLE BY expr][TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...][SETTINGS name=value, ...]ENGINE - 引擎名和参数。 ENGINE = MergeTree(). MergeTree 引擎没有参数 【必填】ORDER BY — 排序键,可以是一组列的元组或任意的表达式
ORDER BY (CounterID, EventDate) 。如果没有使用 PRIMARY KEY 显式指定的主键,ClickHouse 会使用排序键作为主键ORDER BY tuple()【选填】PARTITION BY — 分区键 ,可选项
toYYYYMM(date_column) ,这里的 date_column 是一个 Date 类型的列, 分区名的格式会是 "YYYYMM"【选填】PRIMARY KEY -主键,作为数据的一级索引,但是不是唯一约束,和其他数据库区分
ORDER BY 子句指定)相同。PRIMARY KEYPRIMARY KEY 主键必须是 order by 字段的前缀字段。
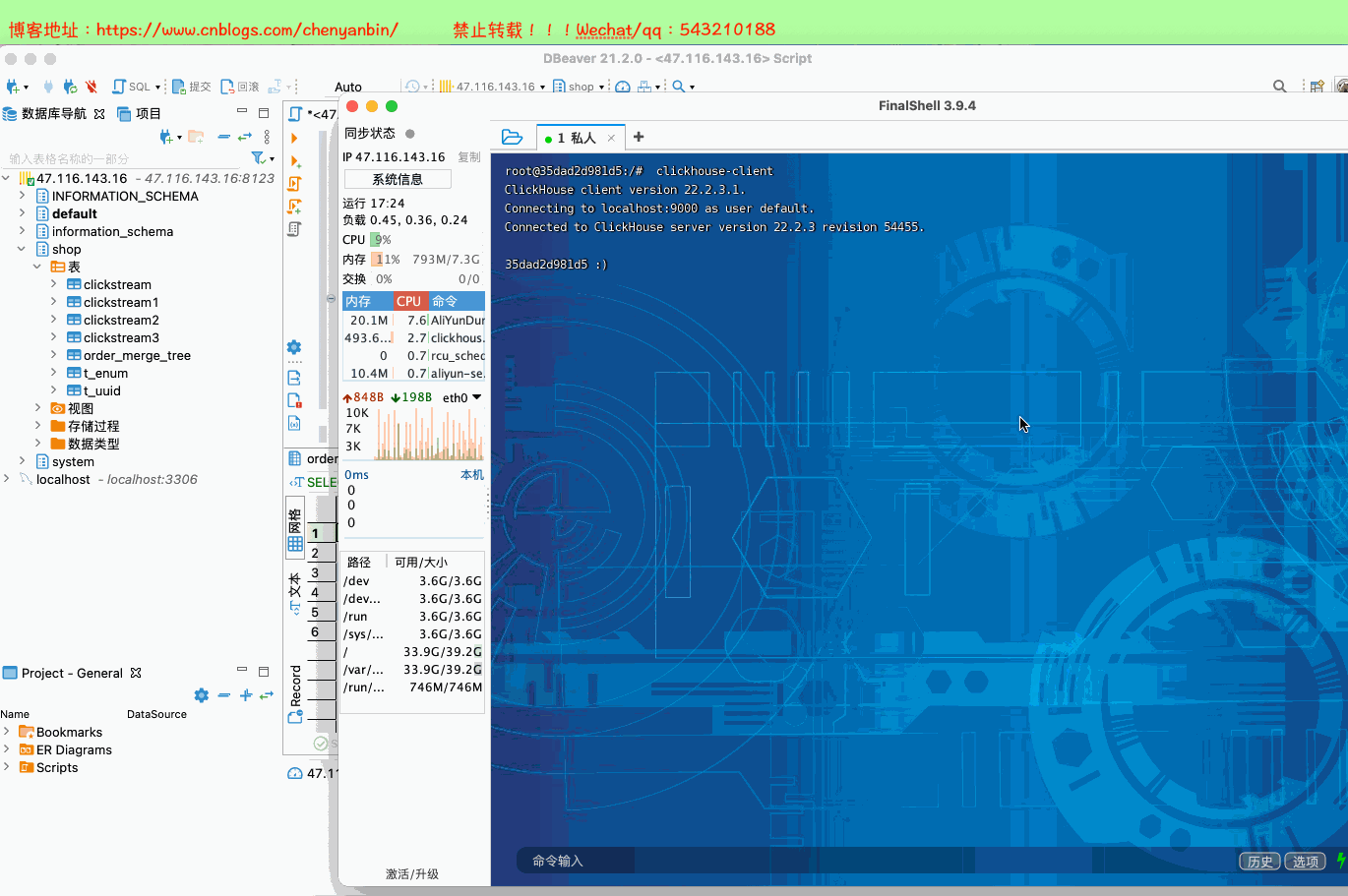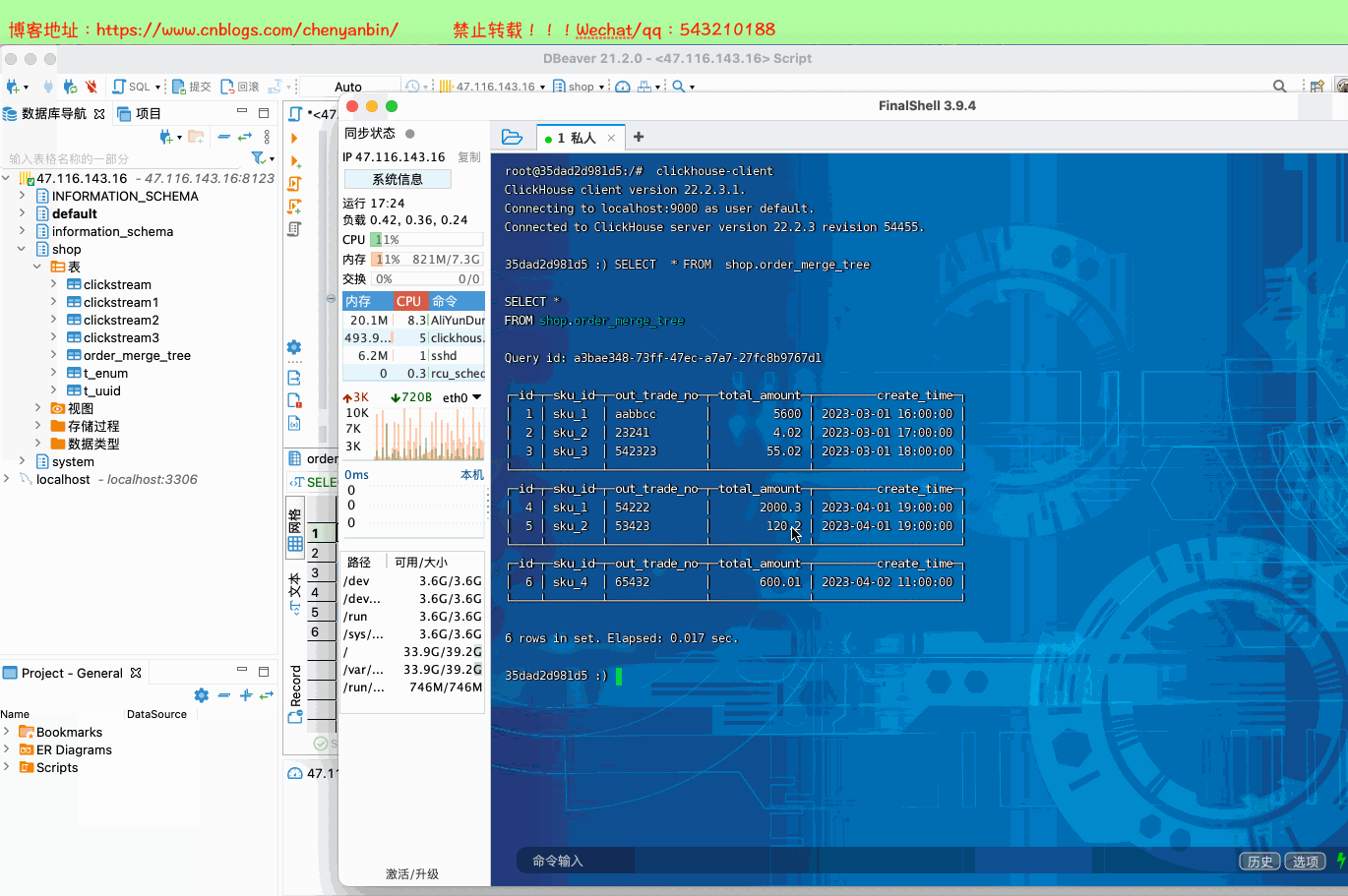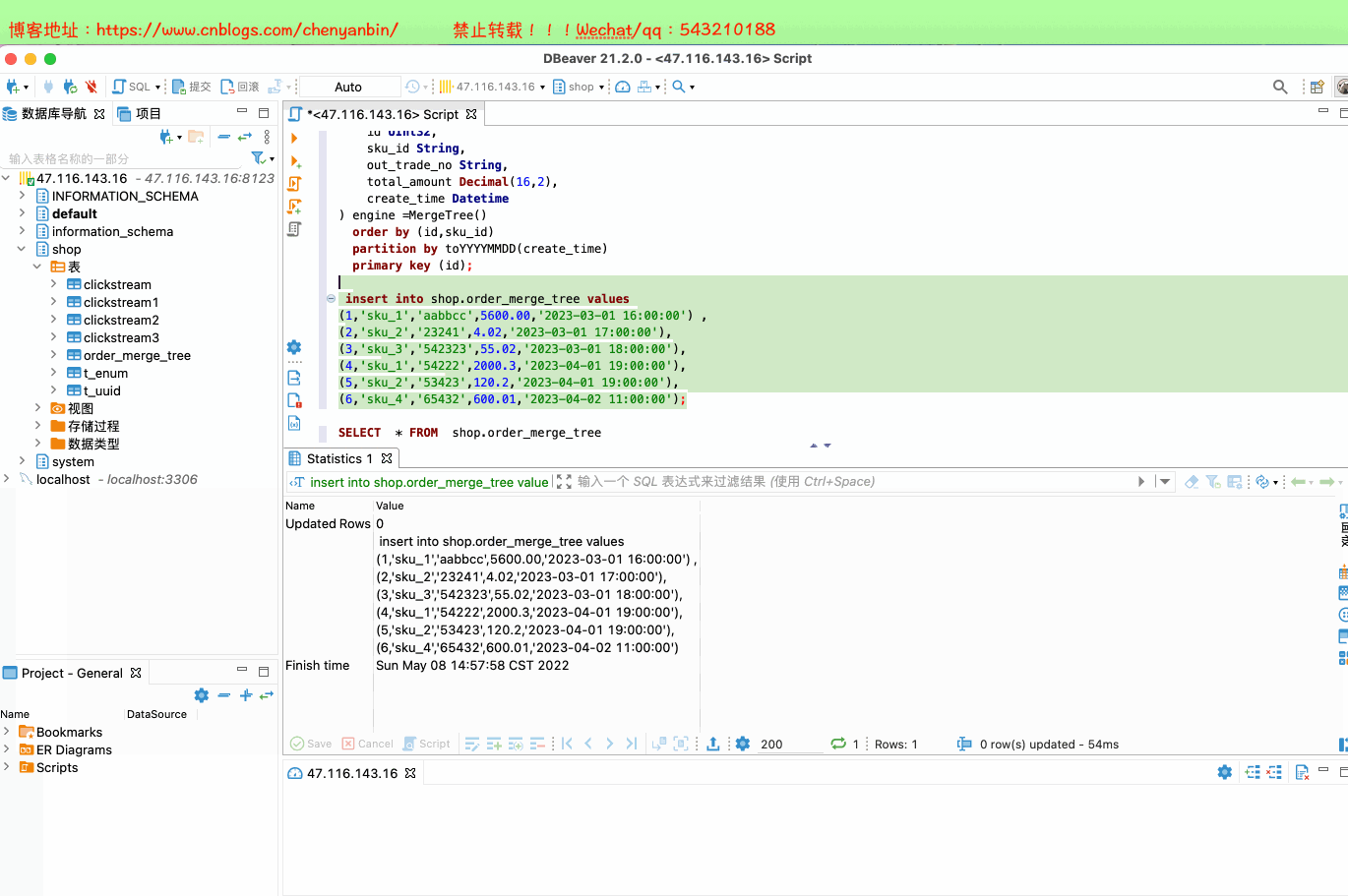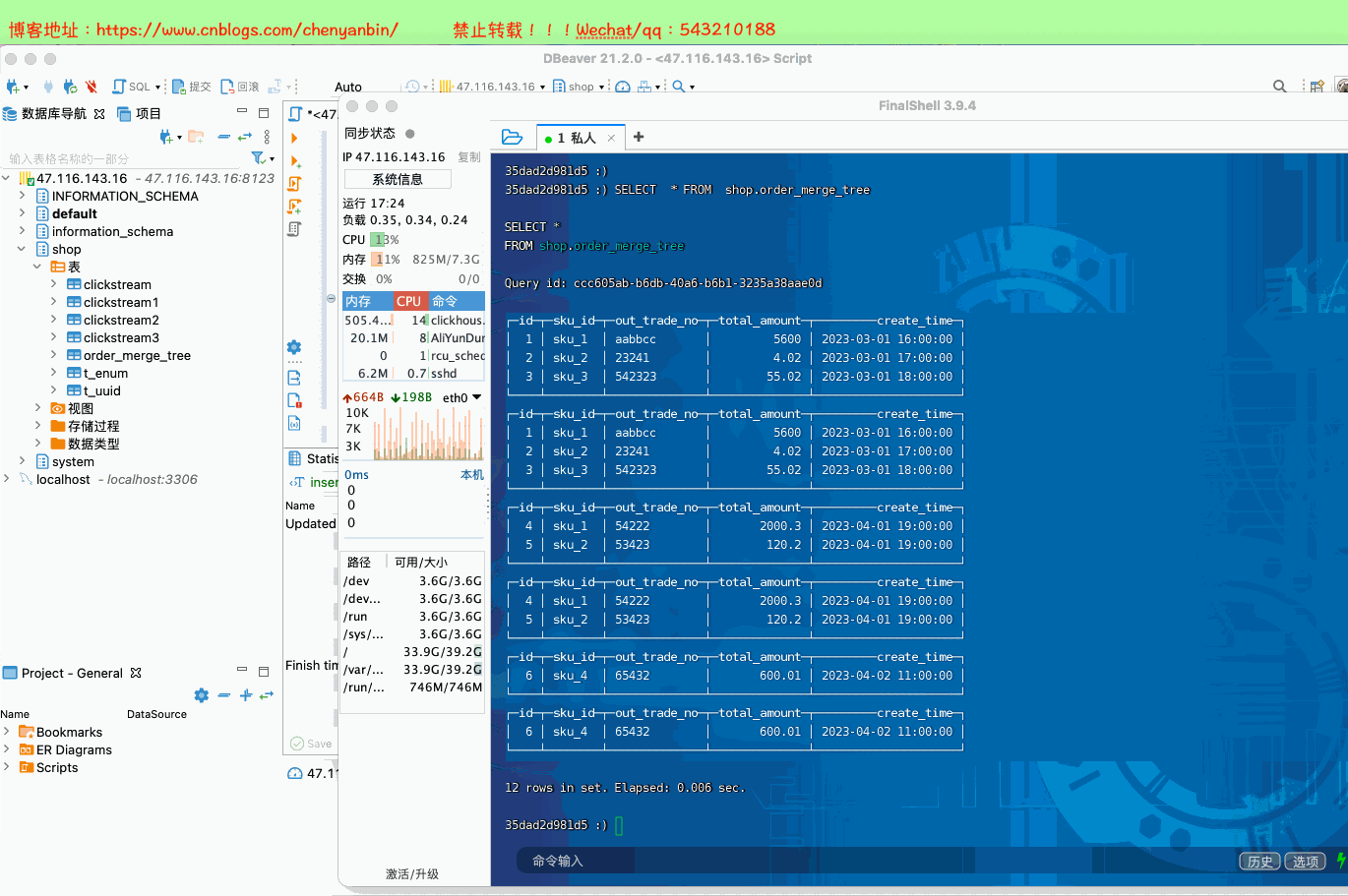
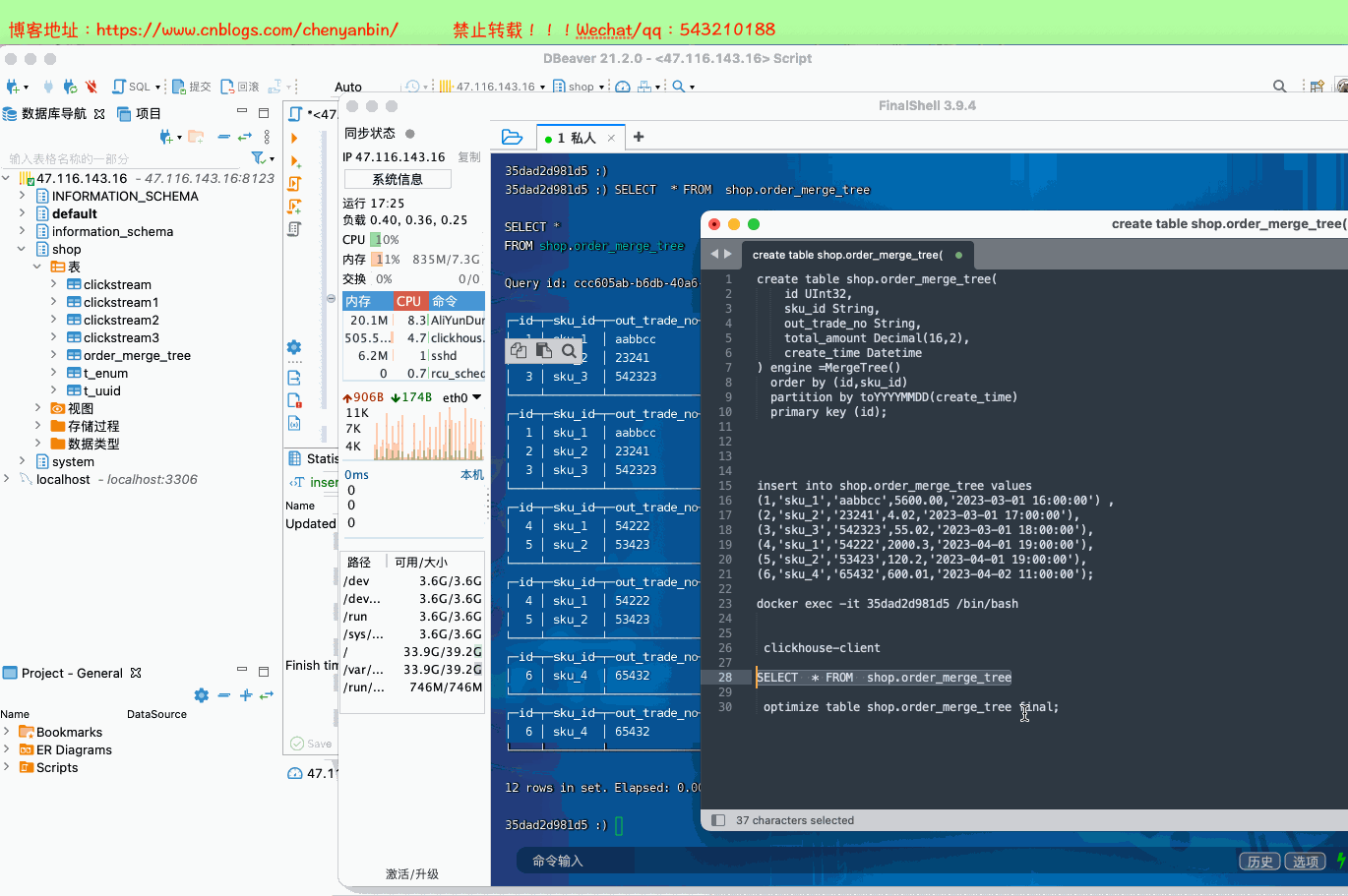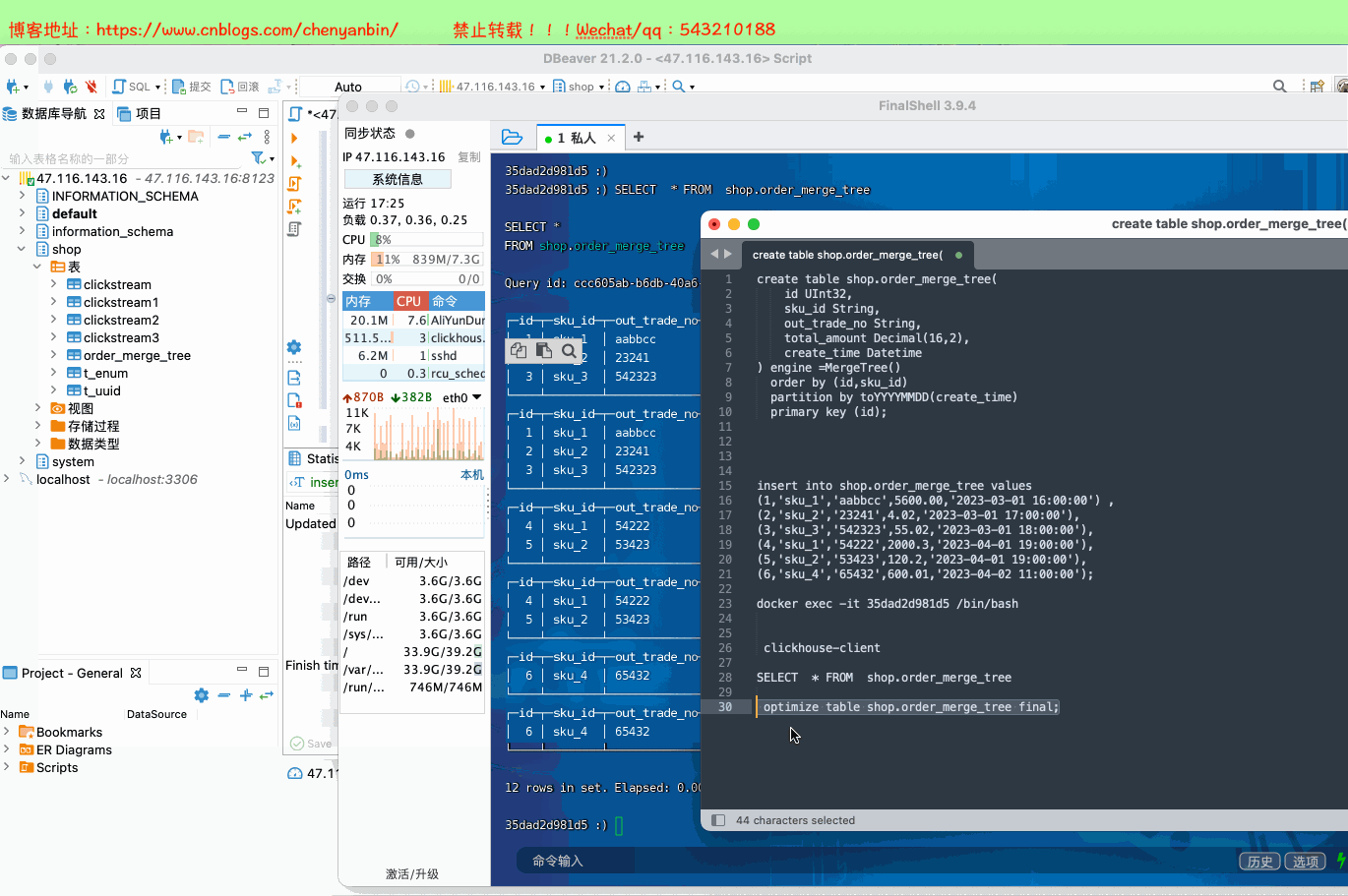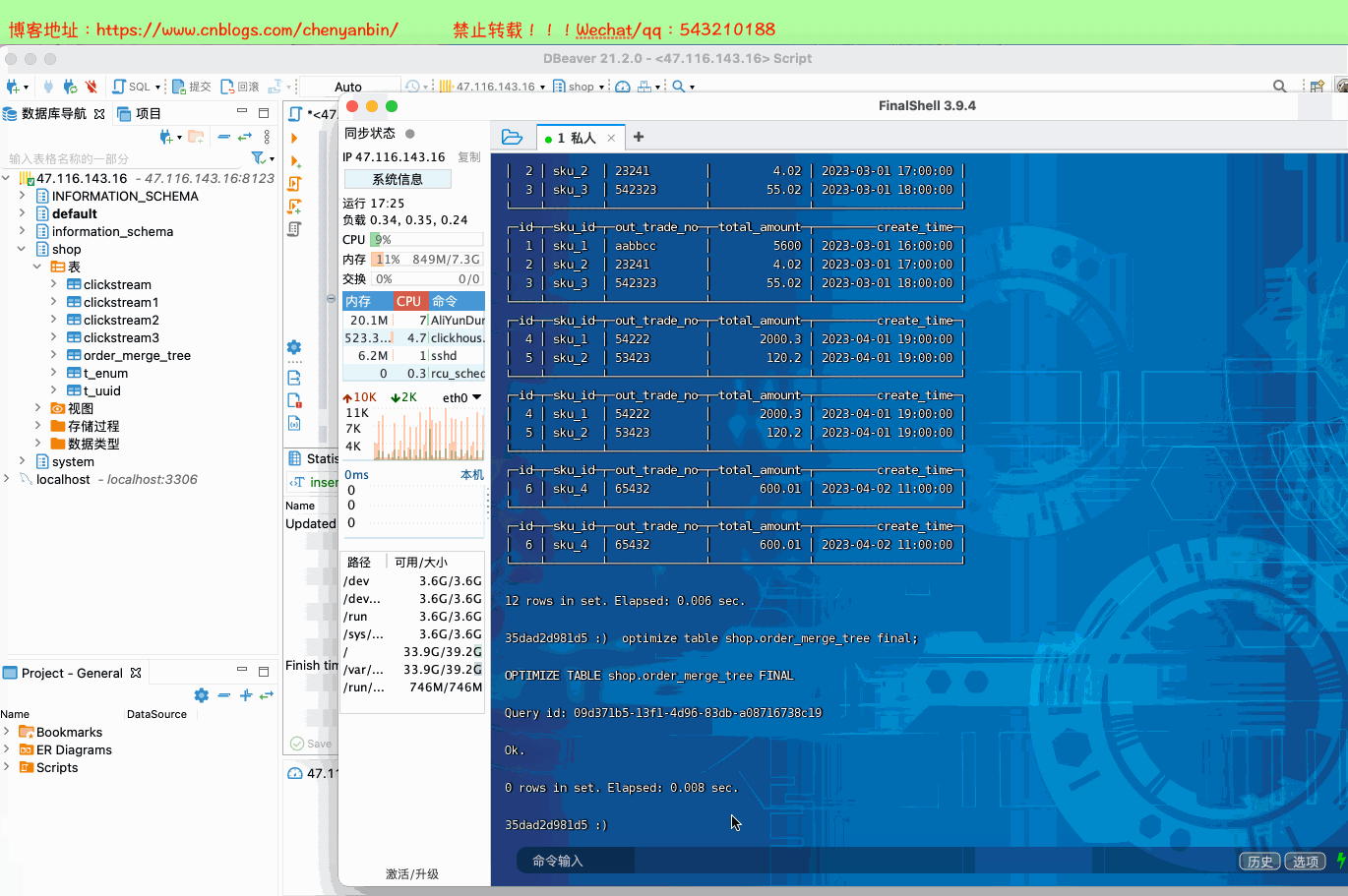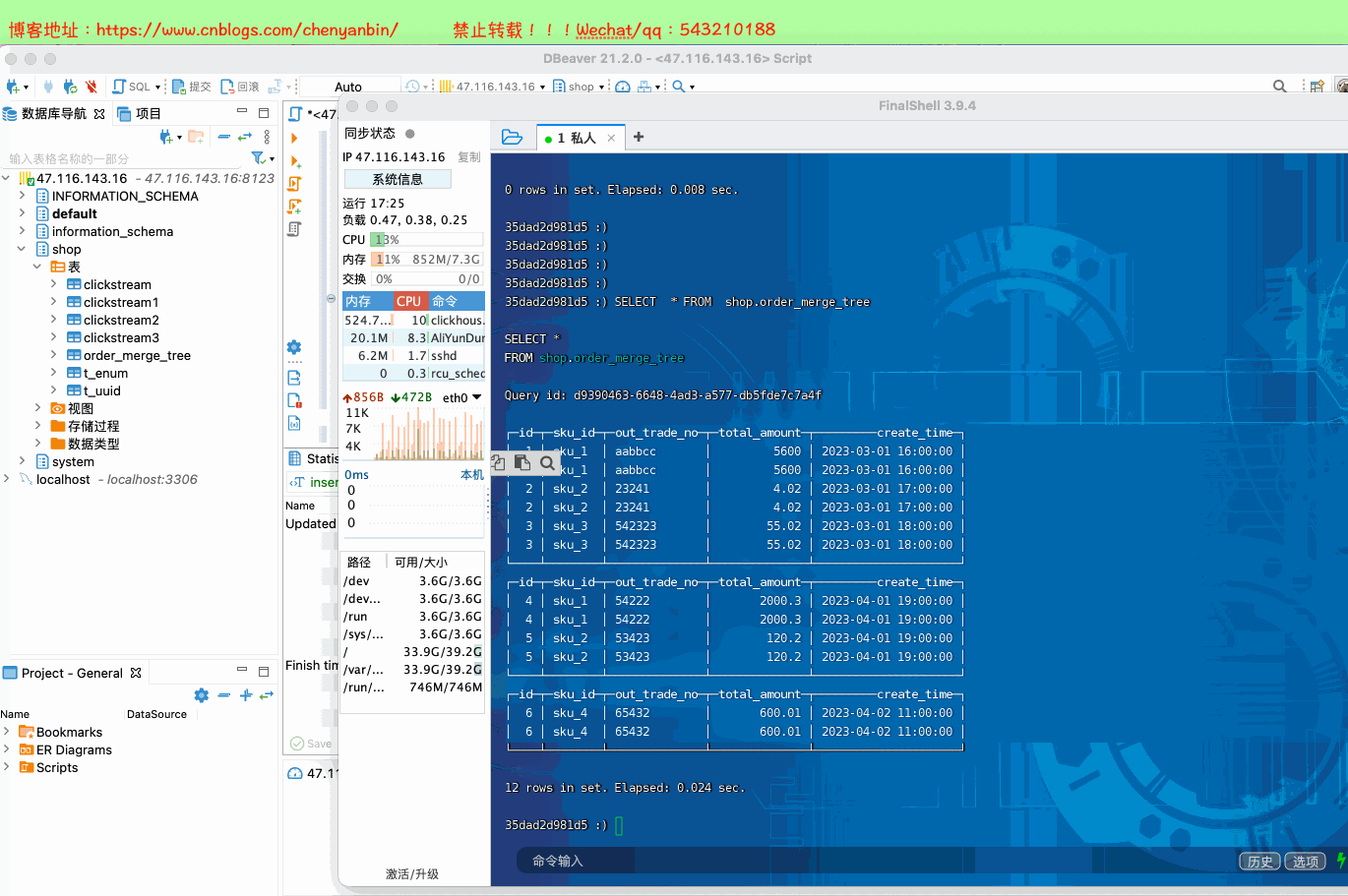
create table shop.order_merge_tree( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =MergeTree() order by (id,sku_id) partition by toYYYYMMDD(create_time) primary key (id);insert into shop.order_merge_tree values (1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (4,'sku_1','54222',2000.3,'2023-04-01 19:00:00'), (5,'sku_2','53423',120.2,'2023-04-01 19:00:00'), (6,'sku_4','65432',600.01,'2023-04-02 11:00:00');docker exec -it 35dad2d981d5 /bin/bash
新的数据写入会有临时分区产生,不之间加入已有分区写入完成后经过一定时间(10到15分钟),ClickHouse会自动化执行合并操作,将临时分区的数据合并到已有分区当中optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行通过手工合并( optimize table xxx final; ) 在数据量比较大的情况,尽量不要使用该命令,执行optimize要消耗大量时间create table shop.order_merge_tree( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =MergeTree() order by (id,sku_id) partition by toYYYYMMDD(create_time) primary key (id);insert into shop.order_merge_tree values (1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (4,'sku_1','54222',2000.3,'2023-04-01 19:00:00'), (5,'sku_2','53423',120.2,'2023-04-01 19:00:00'), (6,'sku_4','65432',600.01,'2023-04-02 11:00:00');docker exec -it 35dad2d981d5 /bin/bash clickhouse-client optimize table shop.order_merge_tree final;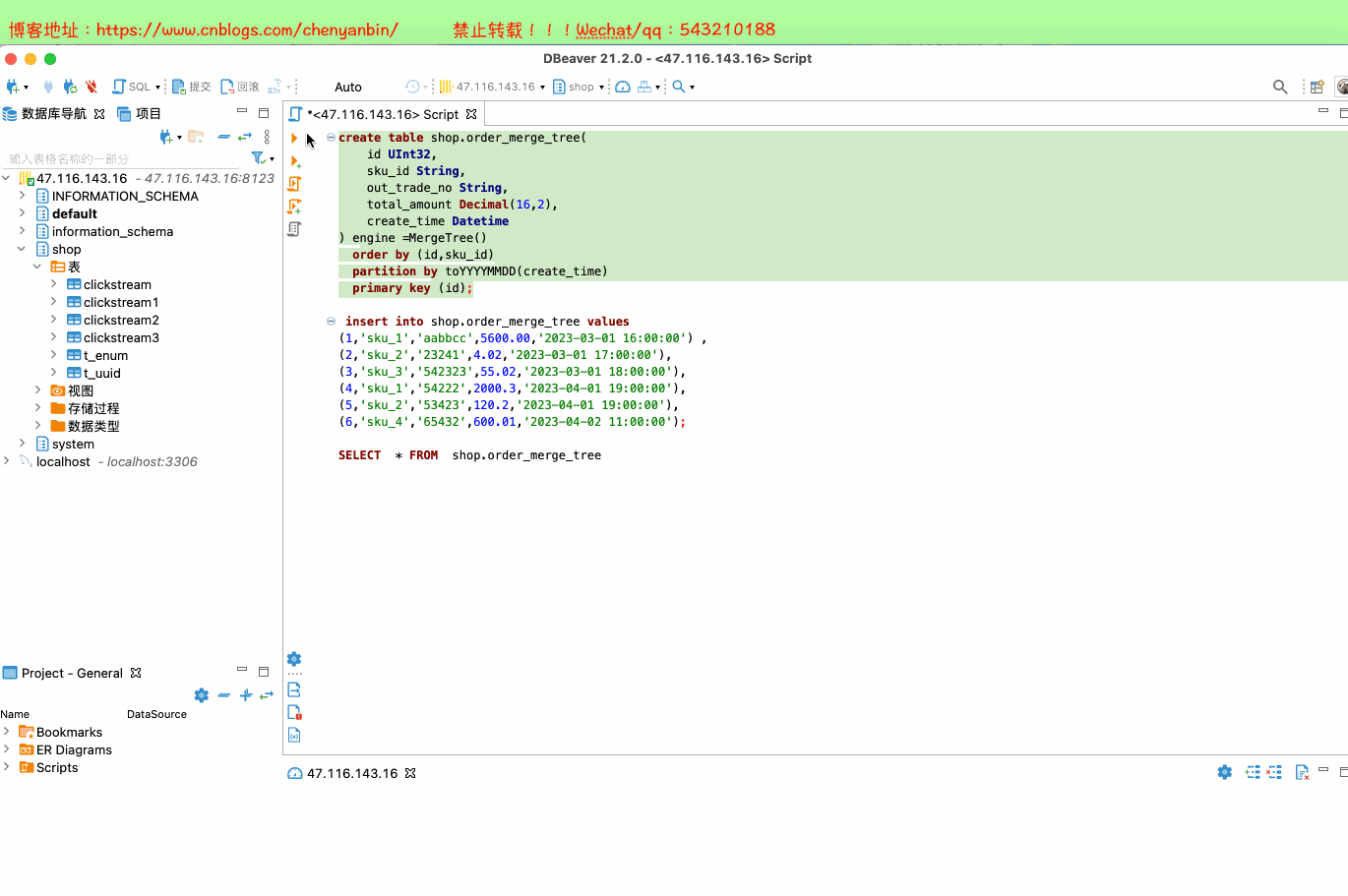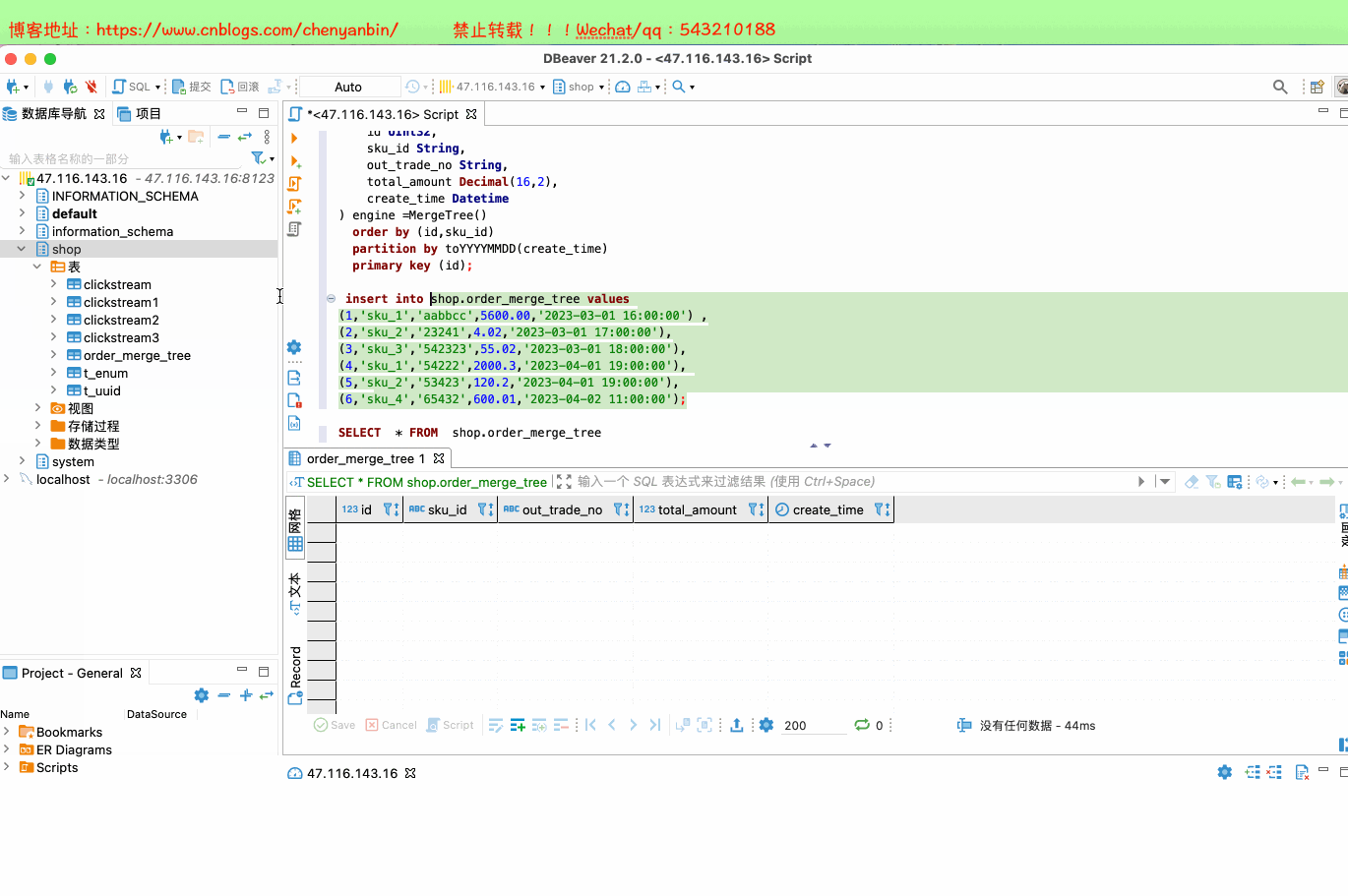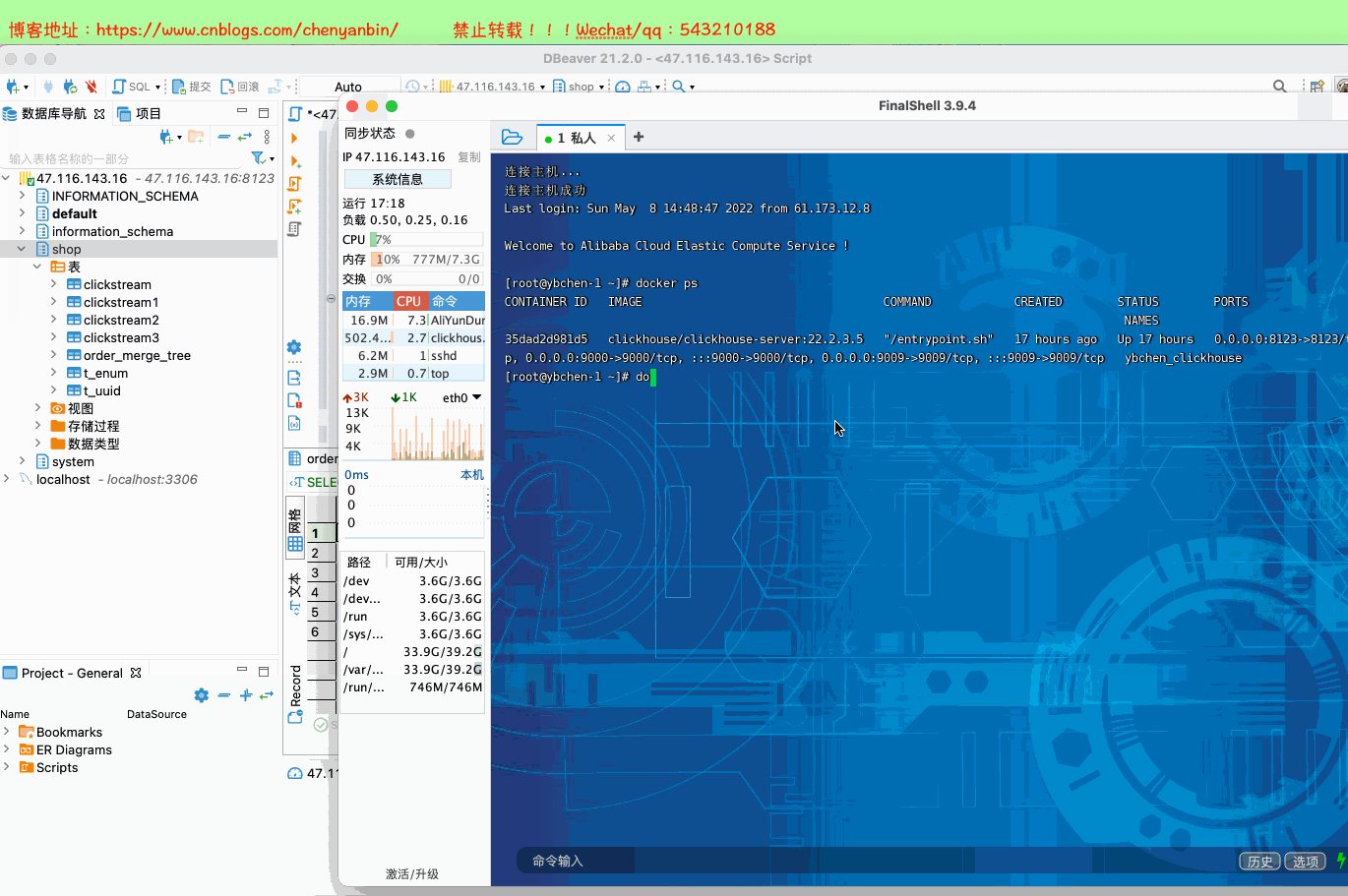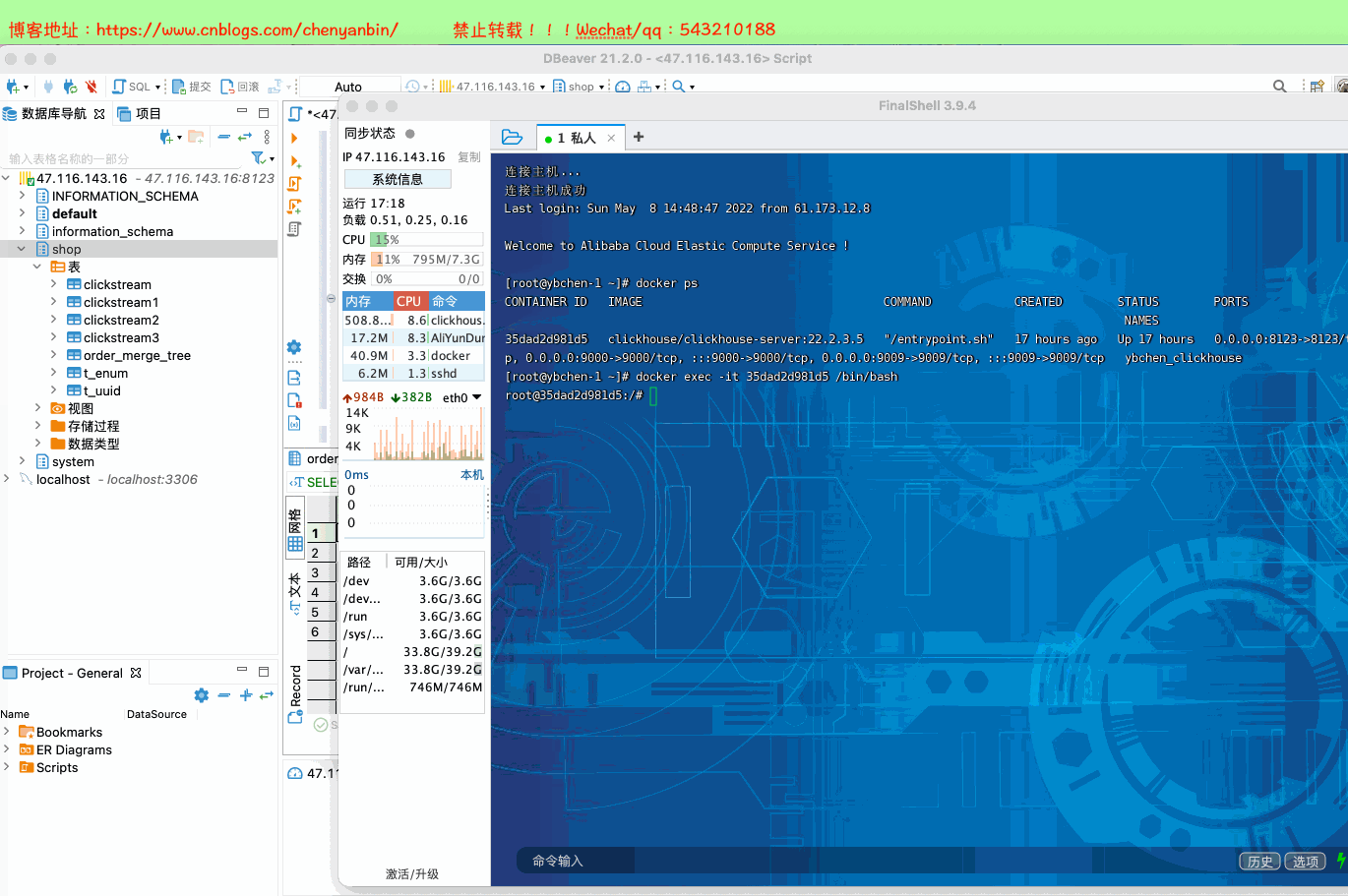

create table shop.order_merge_tree22( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =MergeTree() order by (id,sku_id) primary key (id); insert into shop.order_merge_tree22 values (1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (4,'sku_1','54222',2000.3,'2023-04-01 19:00:00'), (5,'sku_2','53423',120.2,'2023-04-01 19:00:00'), (6,'sku_4','65432',600.01,'2023-04-02 11:00:00');
MergeTree的拓展,该引擎和 MergeTree 的不同之处在它会删除【排序键值】相同重复项,根据OrderBy字段
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。
有一些数据可能仍未被处理,尽管可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写
因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现
注意去重访问
如果是有多个分区表,只在分区内部进行去重,不会跨分区
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ...) ENGINE = ReplacingMergeTree([ver])[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]ver — 版本列。类型为 UInt*, Date 或 DateTime。可选参数。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
ver 列未指定,保留最后一条。ver 列已指定,保留 ver 值最大的版本如何判断数据重复
何时删除重复数据
不同分区的重复数据不会被去重
删除策略
ver表示的列只能是UInt*,Date和DateTime 类型
删除策略
create table shop.order_relace_merge_tree( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =ReplacingMergeTree(id) order by (sku_id) partition by toYYYYMMDD(create_time) primary key (sku_id);insert into shop.order_relace_merge_tree values (1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'), (5,'sku_6','53423',120.2,'2023-04-01 19:00:00'), (6,'sku_7','65432',600.01,'2023-04-02 11:00:00');insert into shop.order_relace_merge_tree values (11,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(21,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(31,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (41,'sku_5','54222',2000.3,'2023-04-01 19:00:00'), (51,'sku_8','53423',120.2,'2023-04-01 19:00:00'), (61,'sku_9','65432',600.01,'2023-04-02 11:00:00');docker exec -it 35dad2d981d5 /bin/bash clickhouse-clientSELECT * FROM shop.order_relace_merge_tree optimize table shop.order_relace_merge_tree final;
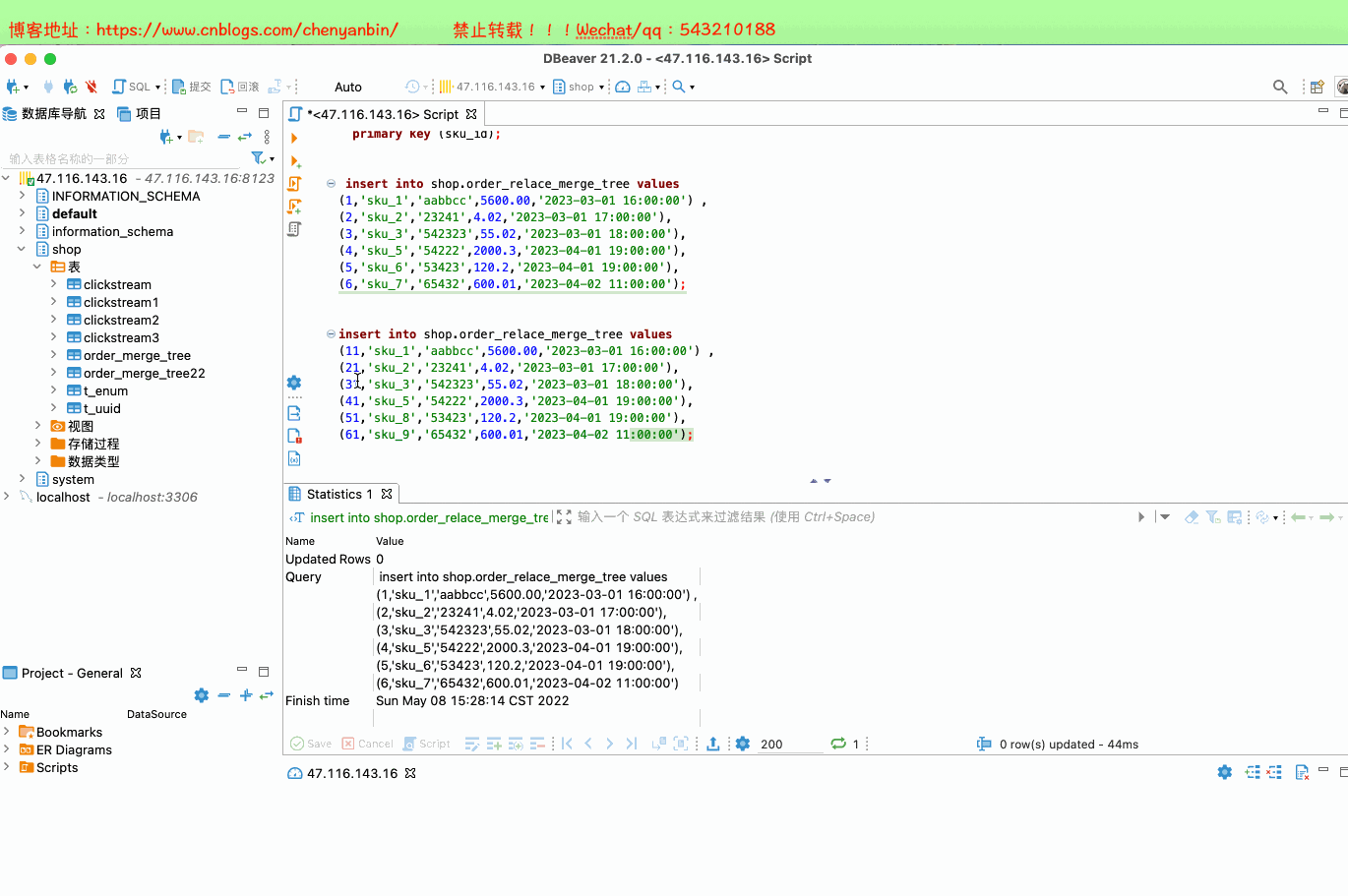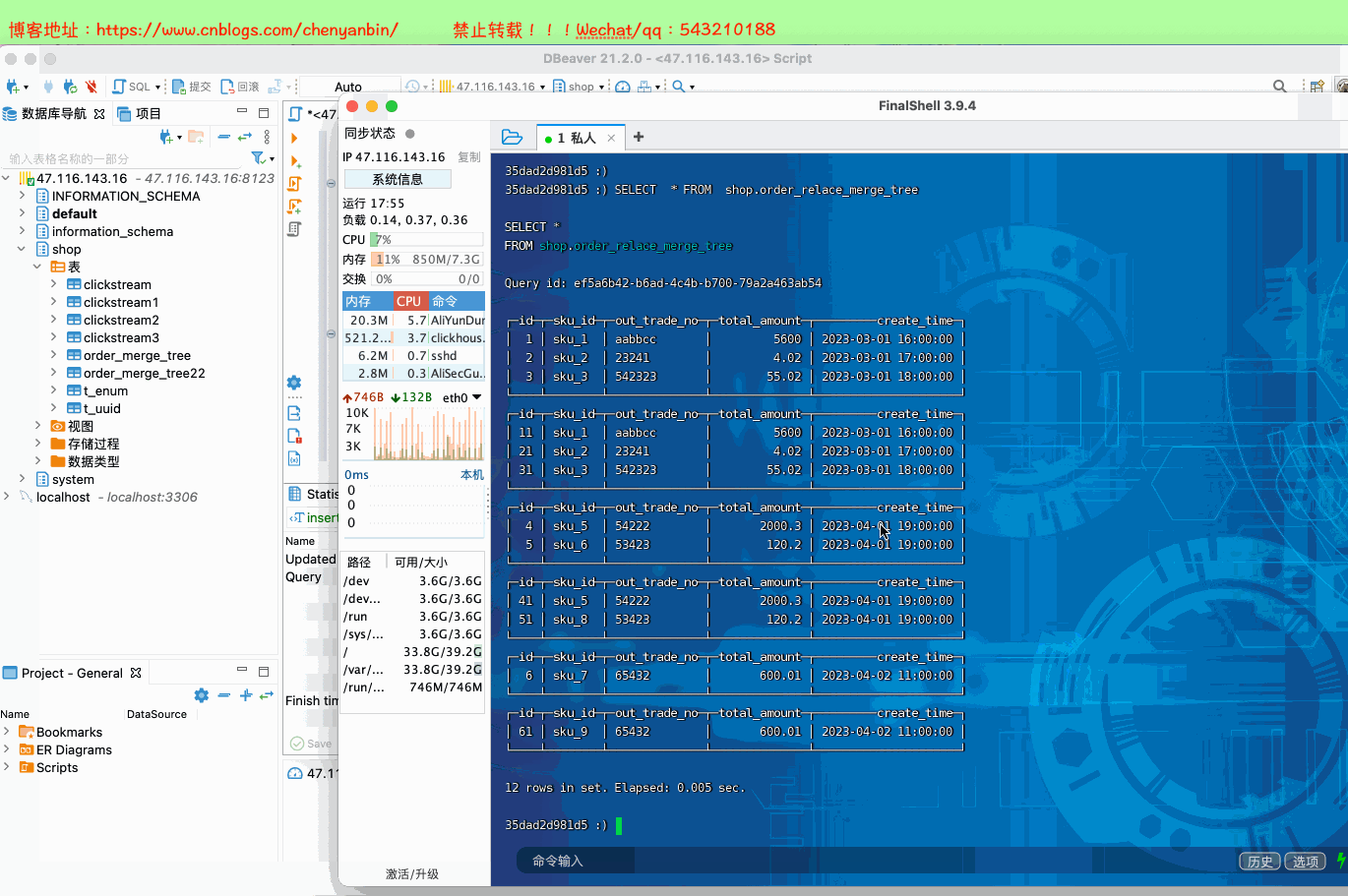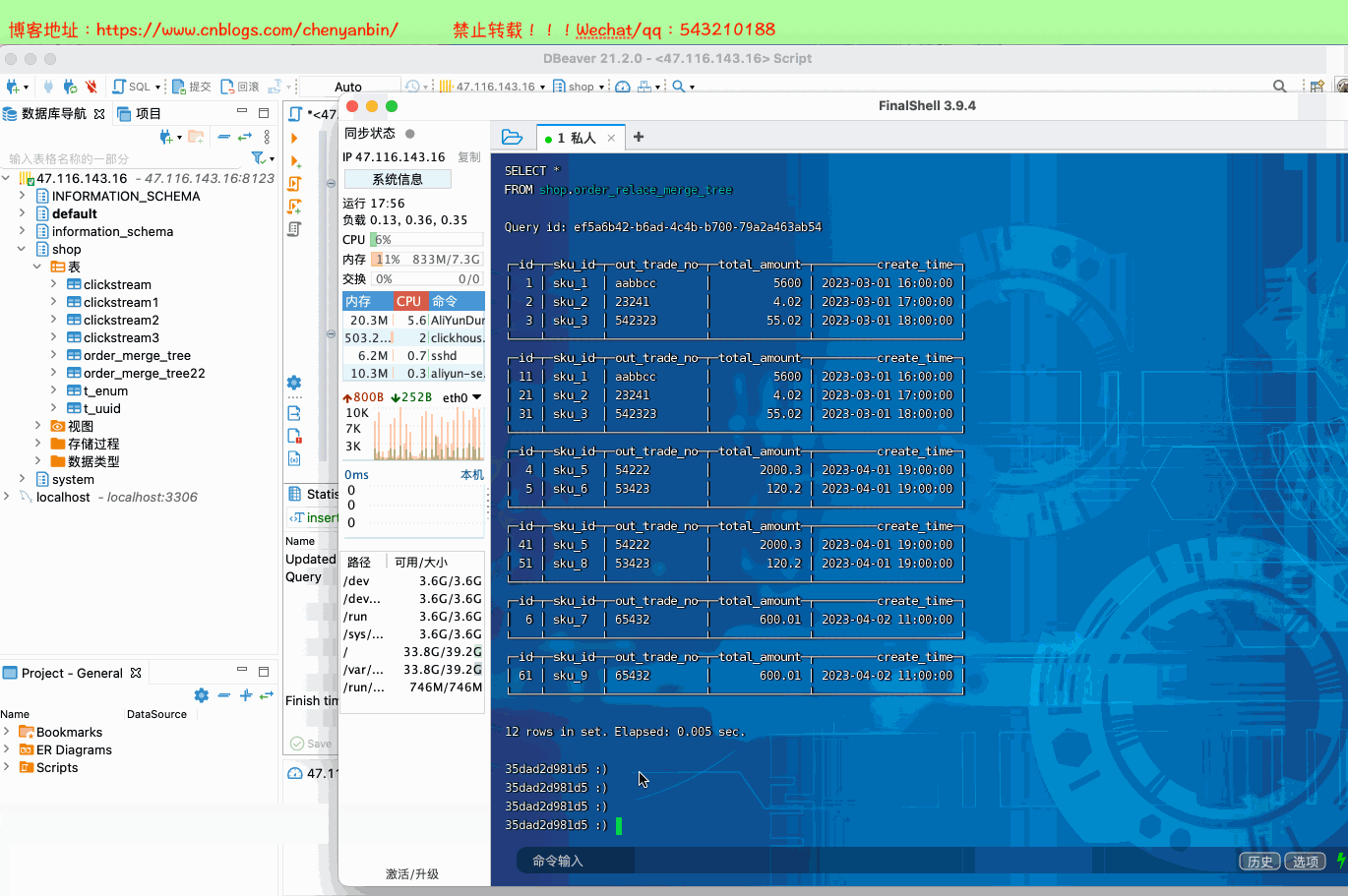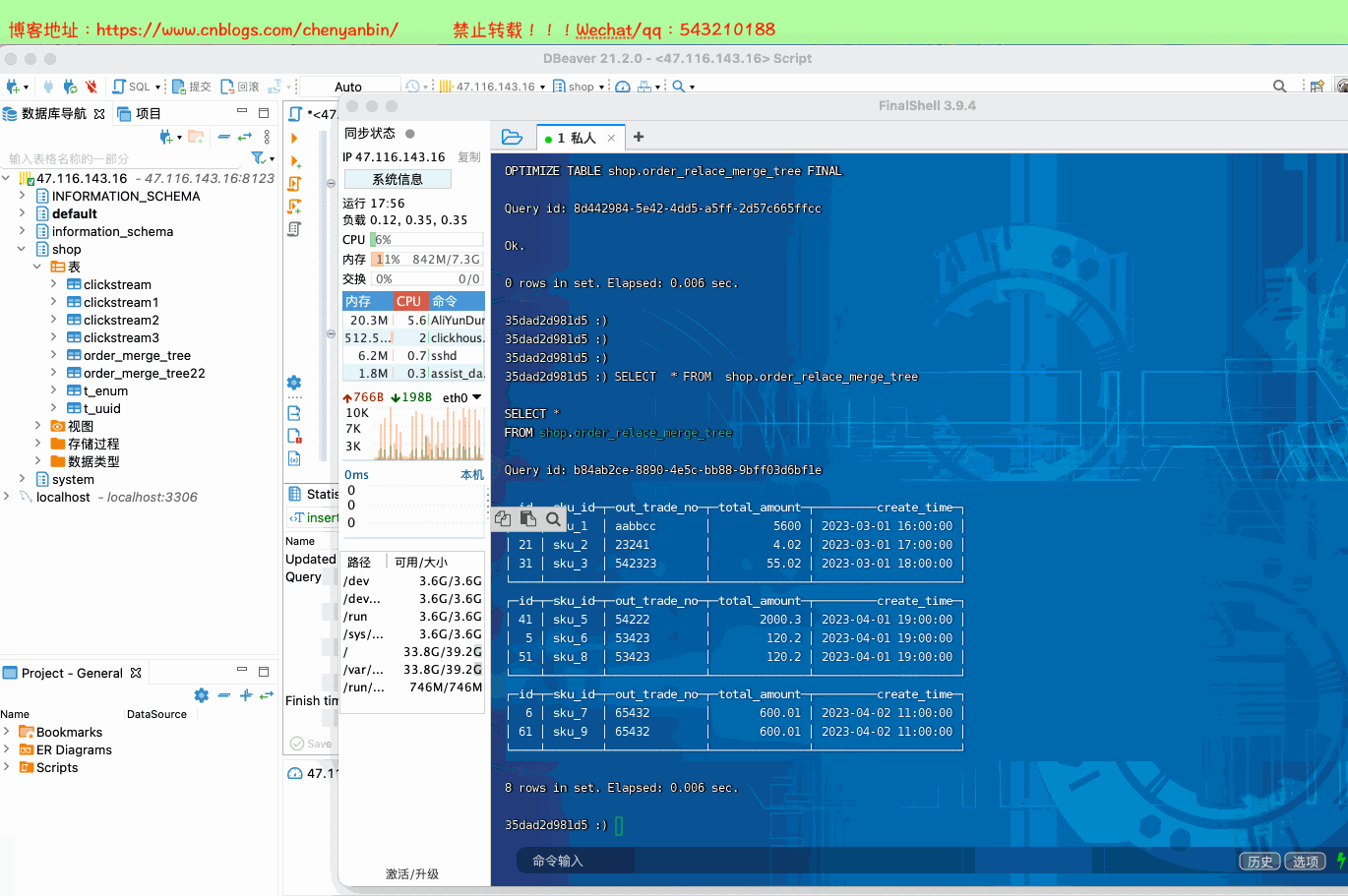
create table shop.order_relace_merge_tree( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =ReplacingMergeTree(id) order by (sku_id) partition by toYYYYMMDD(create_time) primary key (sku_id);insert into shop.order_relace_merge_tree values (1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'), (5,'sku_6','53423',120.2,'2023-04-01 19:00:00'), (6,'sku_7','65432',600.01,'2023-04-02 11:00:00');insert into shop.order_relace_merge_tree values (11,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(21,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(31,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (41,'sku_5','54222',2000.3,'2023-04-01 19:00:00'), (51,'sku_8','53423',120.2,'2023-04-01 19:00:00'), (61,'sku_9','65432',600.01,'2023-04-02 11:00:00');docker exec -it 35dad2d981d5 /bin/bash clickhouse-clientSELECT * FROM shop.order_relace_merge_tree optimize table shop.order_relace_merge_tree final;
该引擎继承自 MergeTree,区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有 相同OrderBy排序键 的行合并为一行,该行包含了被合并的行中具有数值类型的列的汇总值。
类似group by的效果,这个可以显著的减少存储空间并加快数据查询的速度
推荐将该引擎和 MergeTree 一起使用。例如在准备做数据报表的时候,将完整的数据存储在 MergeTree 表中,并且使用 SummingMergeTree 来存储聚合数据,可以使避免因为使用不正确的 排序健组合方式而丢失有价值的数据
只需要查询汇总结果,不关心明细数据
设计聚合统计表,字段全部是维度、度量或者时间戳即可,非相关的字段可以不添加
获取汇总值,不能直接 select 对应的字段,而需要使用 sum 进行聚合,因为自动合并的部分可能没进行,会导致一些还没来得及聚合的临时明细数据少
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ...) ENGINE = SummingMergeTree([columns])[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]columns,ClickHouse 会把非维度列且是【数值类型的列】都进行汇总create table shop.order_summing_merge_tree( id UInt32, sku_id String, out_trade_no String, total_amount Decimal(16,2), create_time Datetime) engine =SummingMergeTree(total_amount) order by (id,sku_id) partition by toYYYYMMDD(create_time) primary key (id);insert into shop.order_summing_merge_tree values (1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'), (4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'), (5,'sku_6','53423',120.2,'2023-04-01 19:00:00'), (6,'sku_7','65432',600.01,'2023-04-02 11:00:00');insert into shop.order_summing_merge_tree values (1,'sku_1','aabbccbb',5600.00,'2023-03-01 23:09:00')select sku_id,sum(total_amount) from shop.order_summing_merge_tree group by sku_id
optimize table shop.order_summing_merge_tree final;
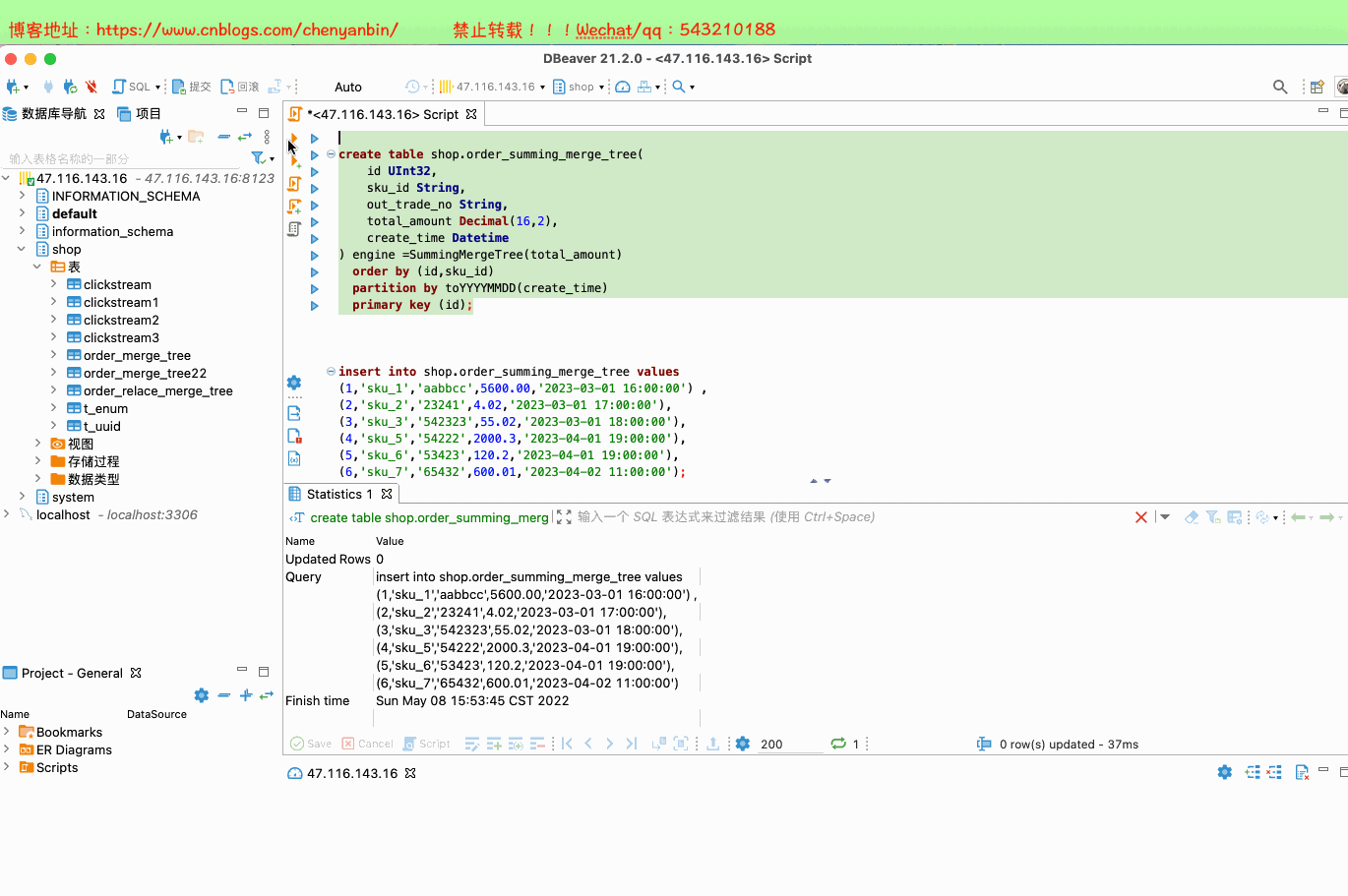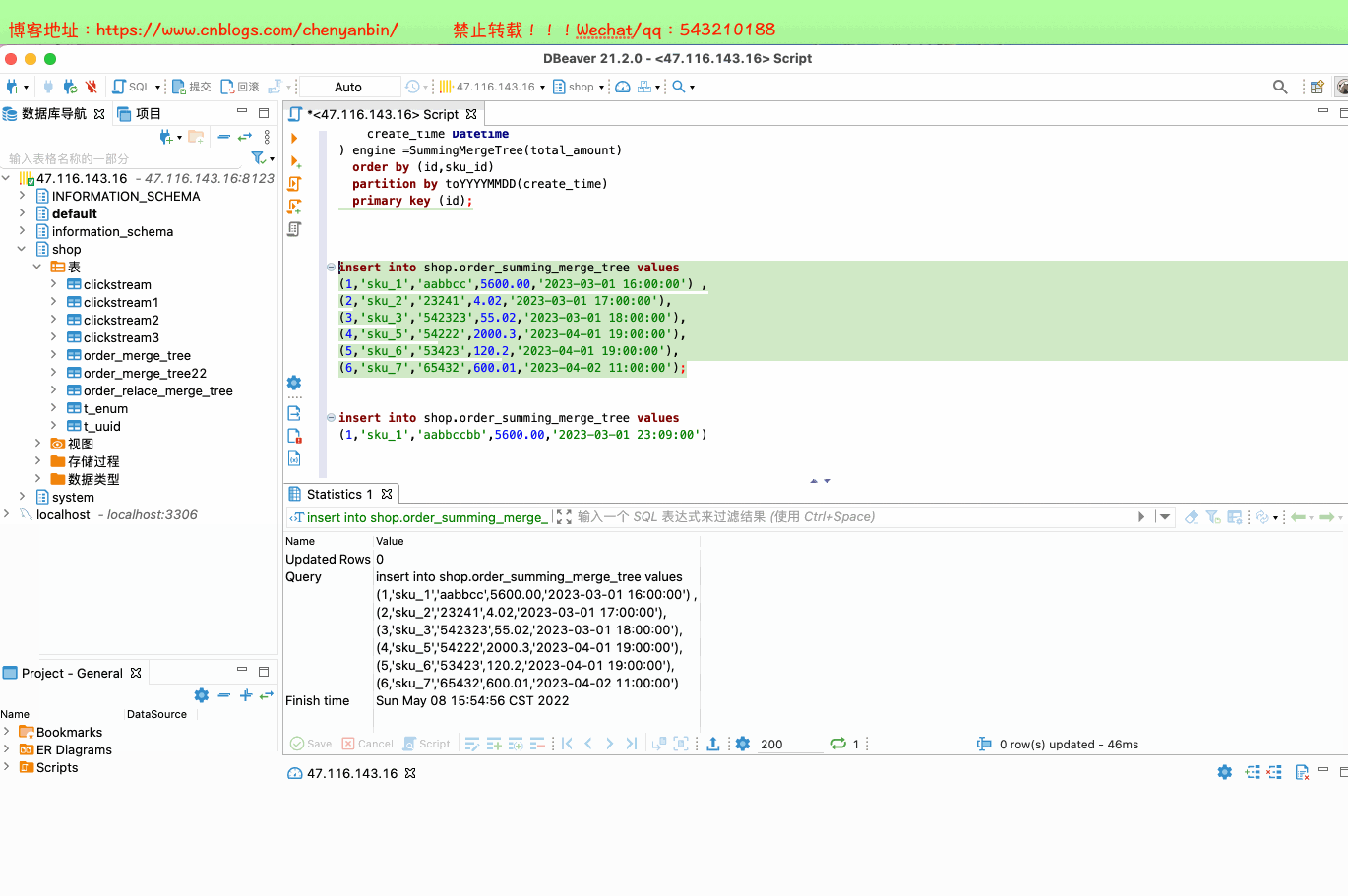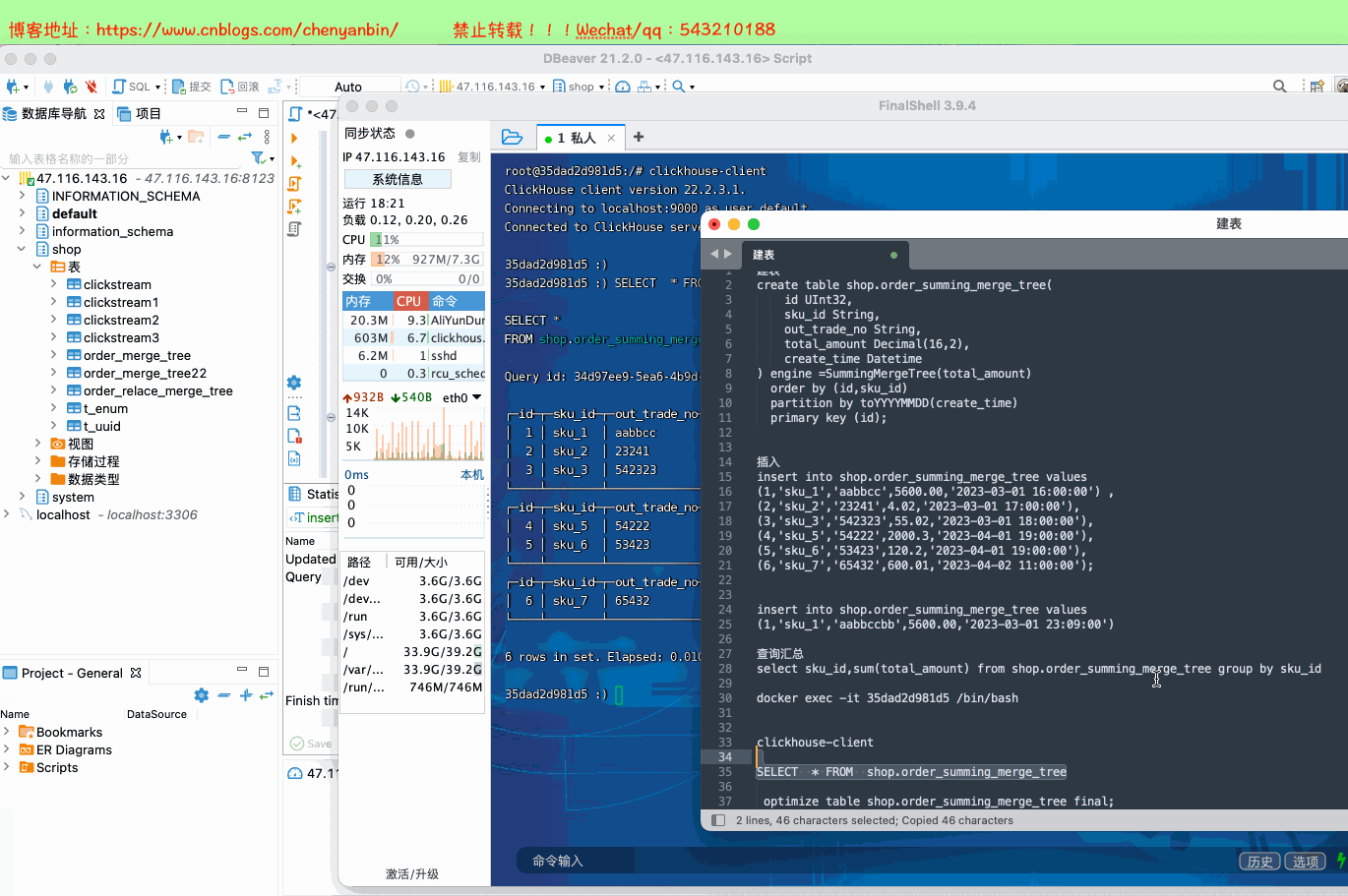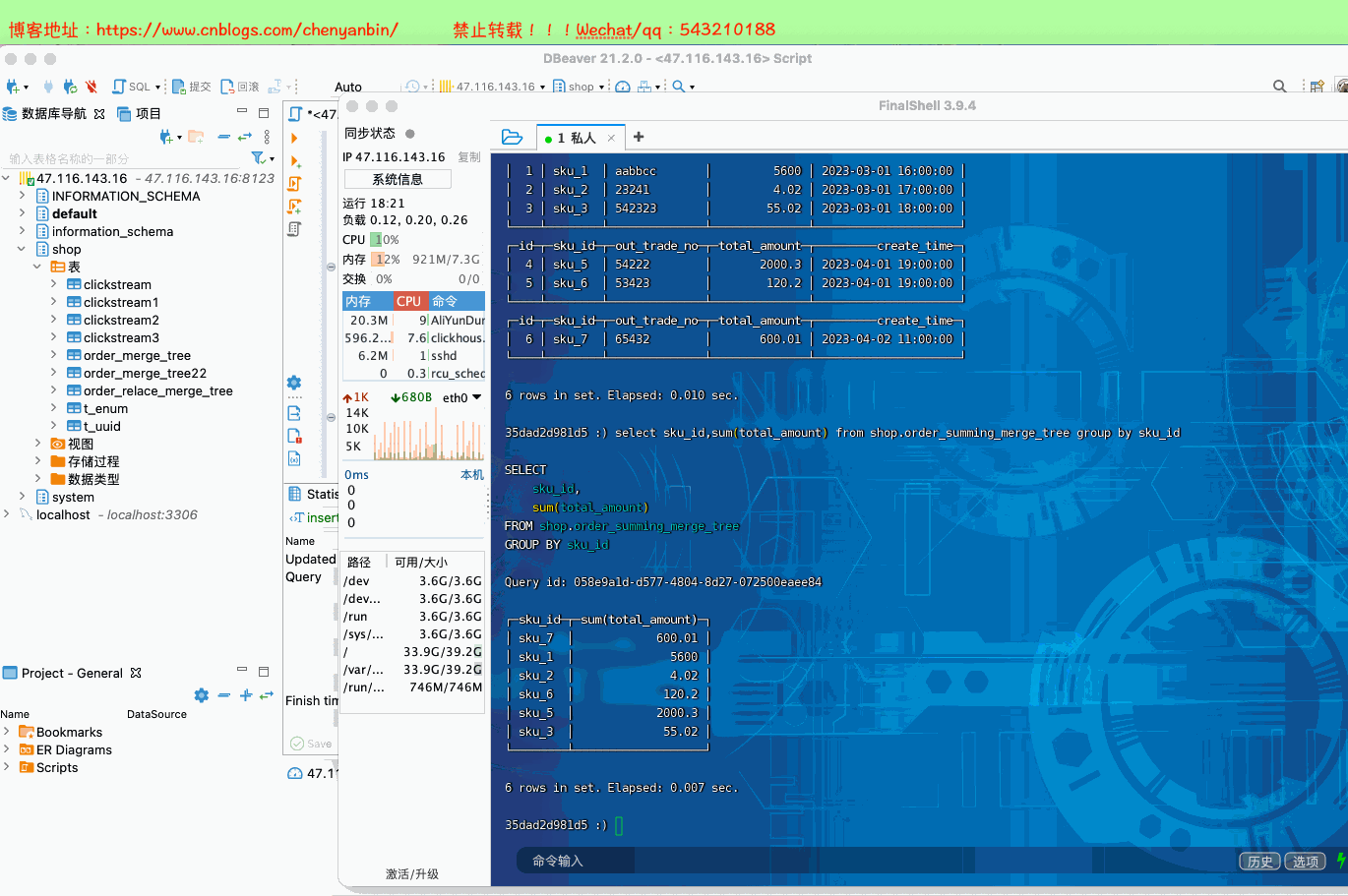

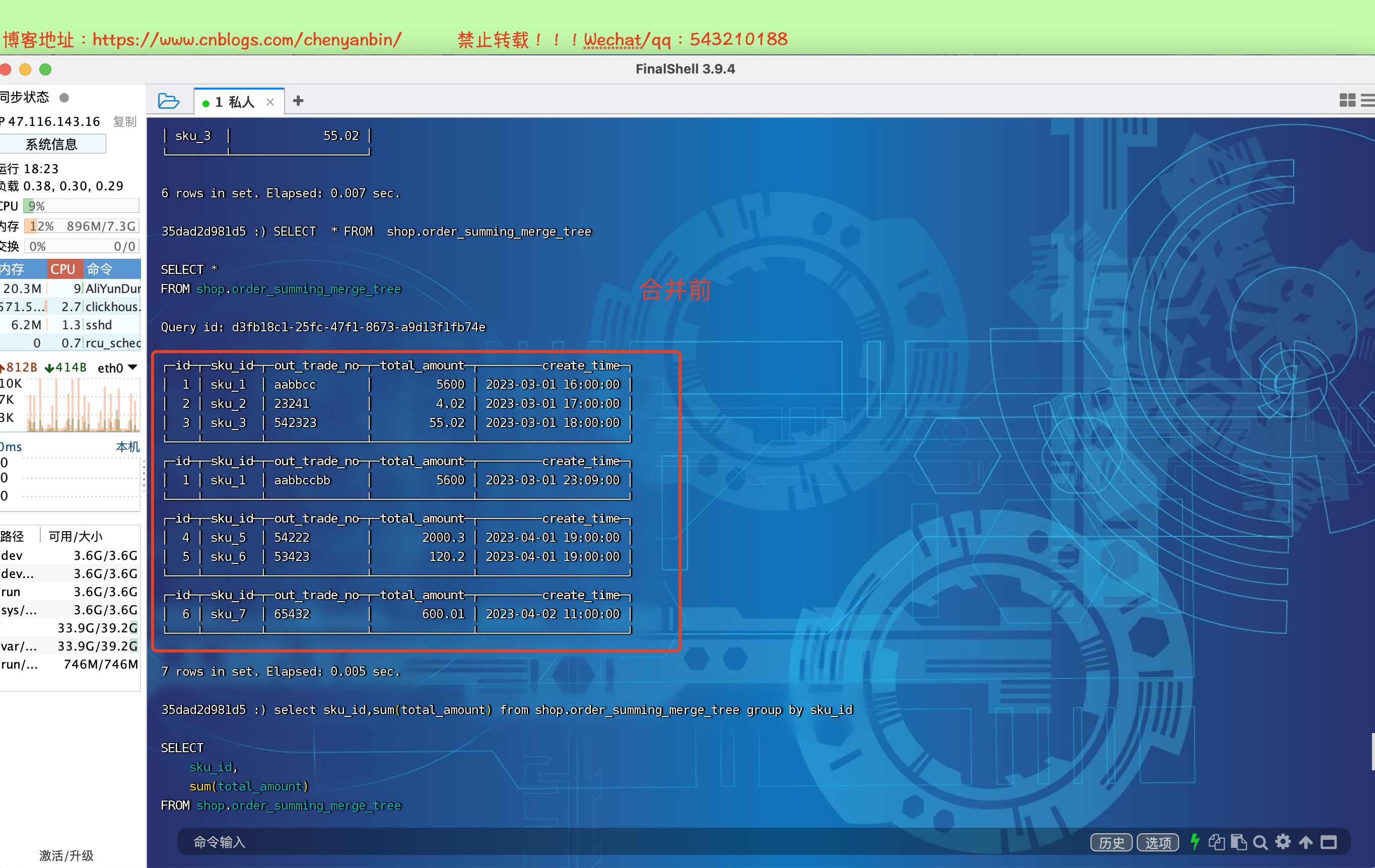

SummingMergeTree是根据什么对数据进行合并的
** 跨分区内的相同排序key的数据是否会进行合并**
如果没有指定聚合字段,会怎么聚合
对于非汇总字段的数据,该保留哪一条
在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分区下的【相同排序】的多行数据汇总合并成一行,既减少了数据行节省空间,又降低了后续汇总查询的开销
docker run -d --name ybchen_zookeeper -p 2181:2181 -t zookeeper:3.7.0
| 机器 | 公网 | 私网 | hostname |
| 机器-1 | 47.116.143.16 | 172.16.0.103 | ybchen-1 |
| 机器-2 | 101.132.27.2 | 172.16.0.108 | ybchen-2 |
Linux机器安装ClickHouse,版本:ClickHouse 22.1.2.2-2
文档地址:https://clickhouse.com/docs/zh/getting-started/install

#各个节点上传到新建文件夹/usr/local/software/*#安装sudo rpm -ivh *.rpm#启动systemctl start clickhouse-server#停止systemctl stop clickhouse-server#重启systemctl restart clickhouse-server#状态查看sudo systemctl status clickhouse-server#查看端口占用,如果命令不存在 yum install -y lsoflsof -i :8123#查看日志 tail -f /var/log/clickhouse-server/clickhouse-server.logtail -f /var/log/clickhouse-server/clickhouse-server.err.log#开启远程访问,取消下面的注释vim /etc/clickhouse-server/config.xml#编辑配置文件<listen_host>0.0.0.0</listen_host>#重启systemctl restart clickhouse-server# 增加dns解析sudo vim /etc/hosts172.16.0.103 ybchen-1172.16.0.108 ybchen-2
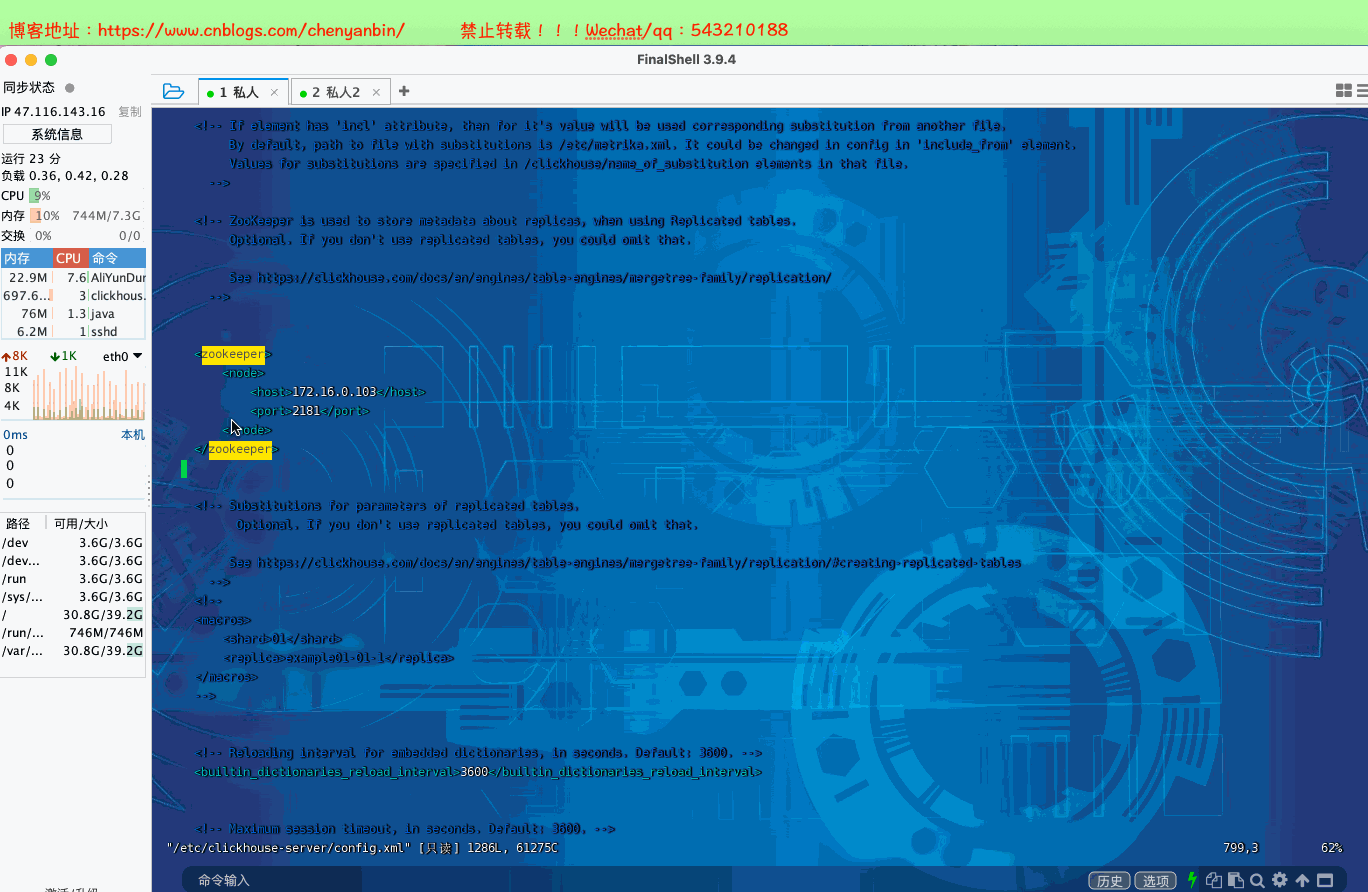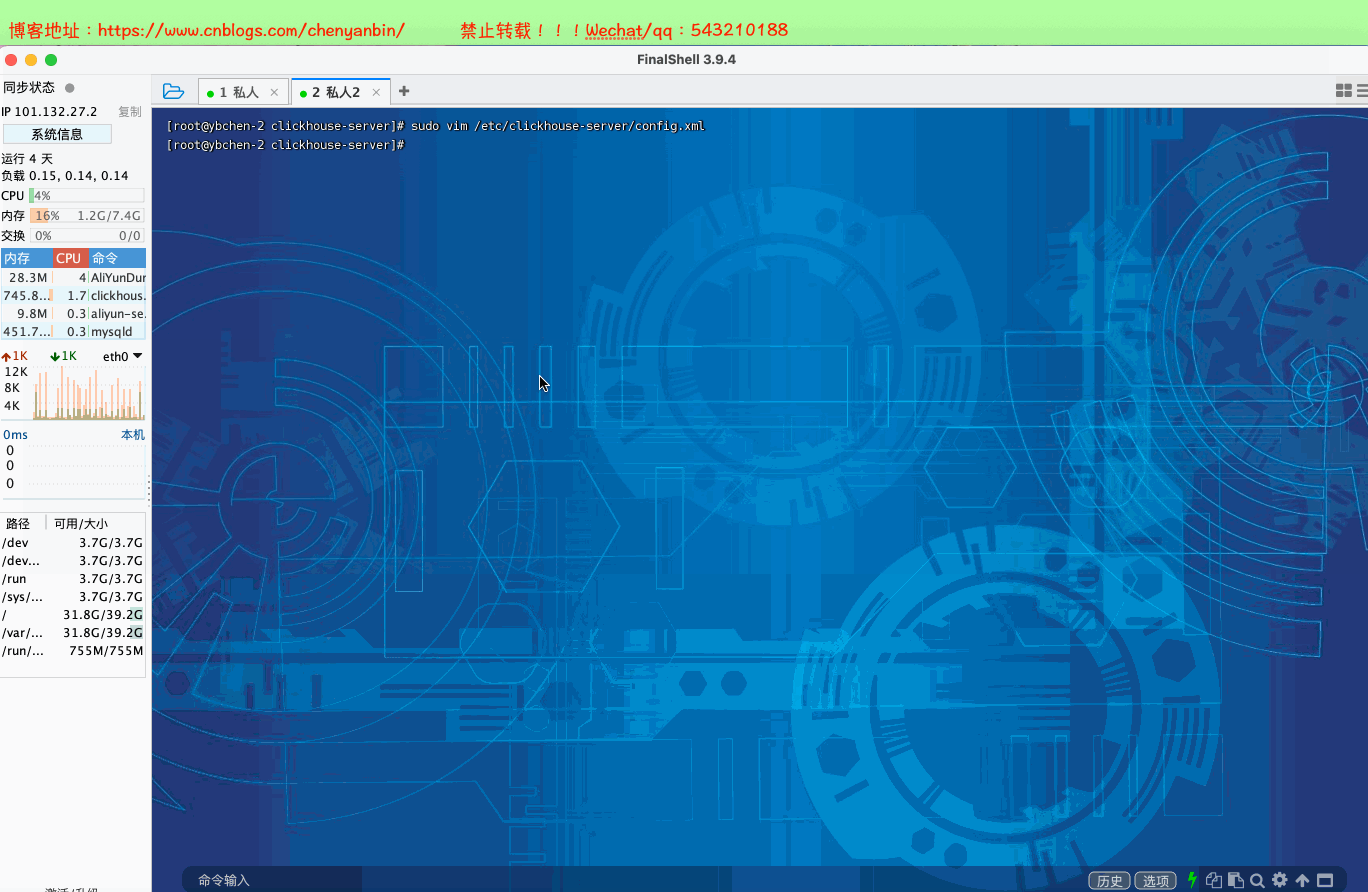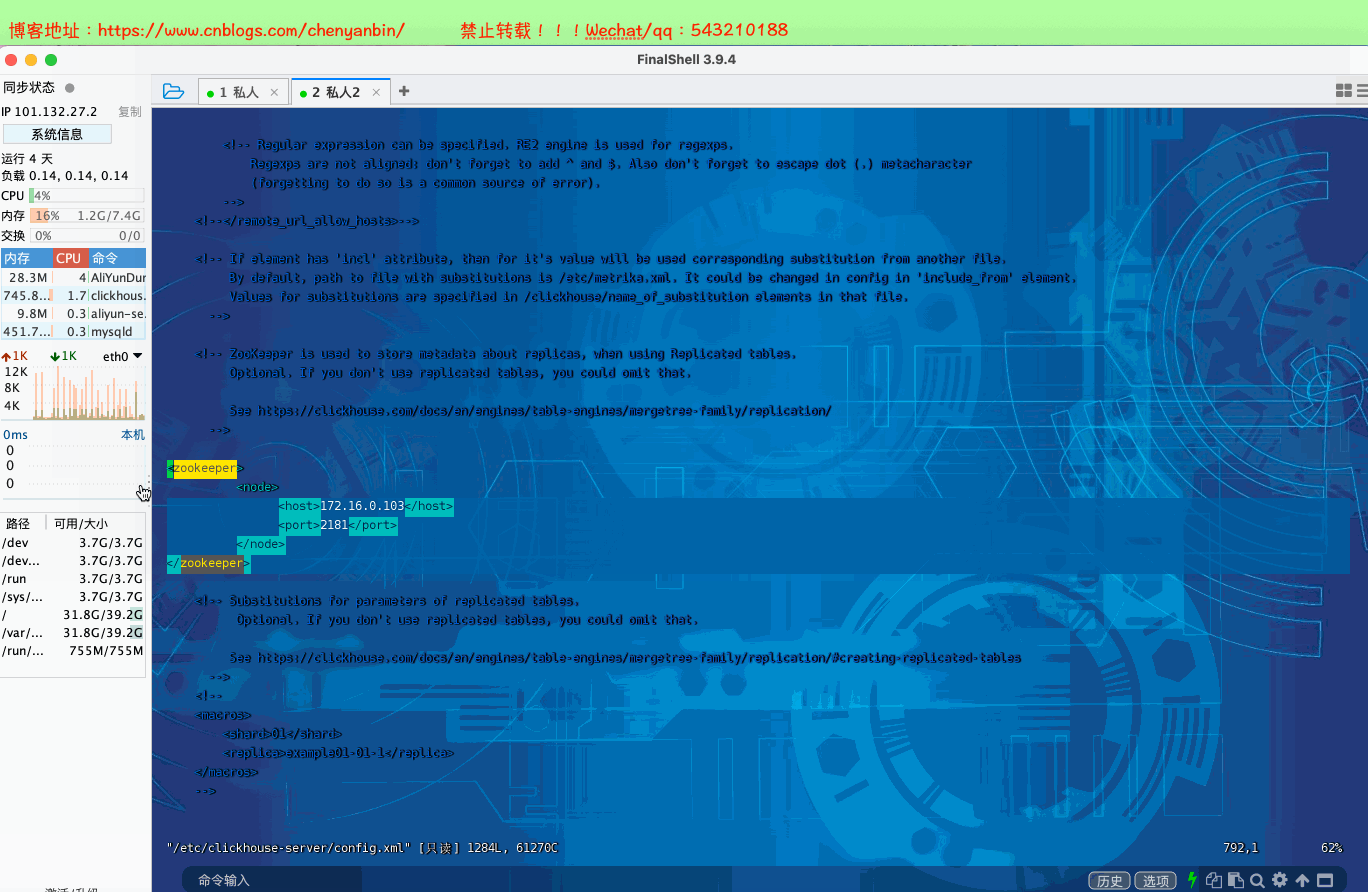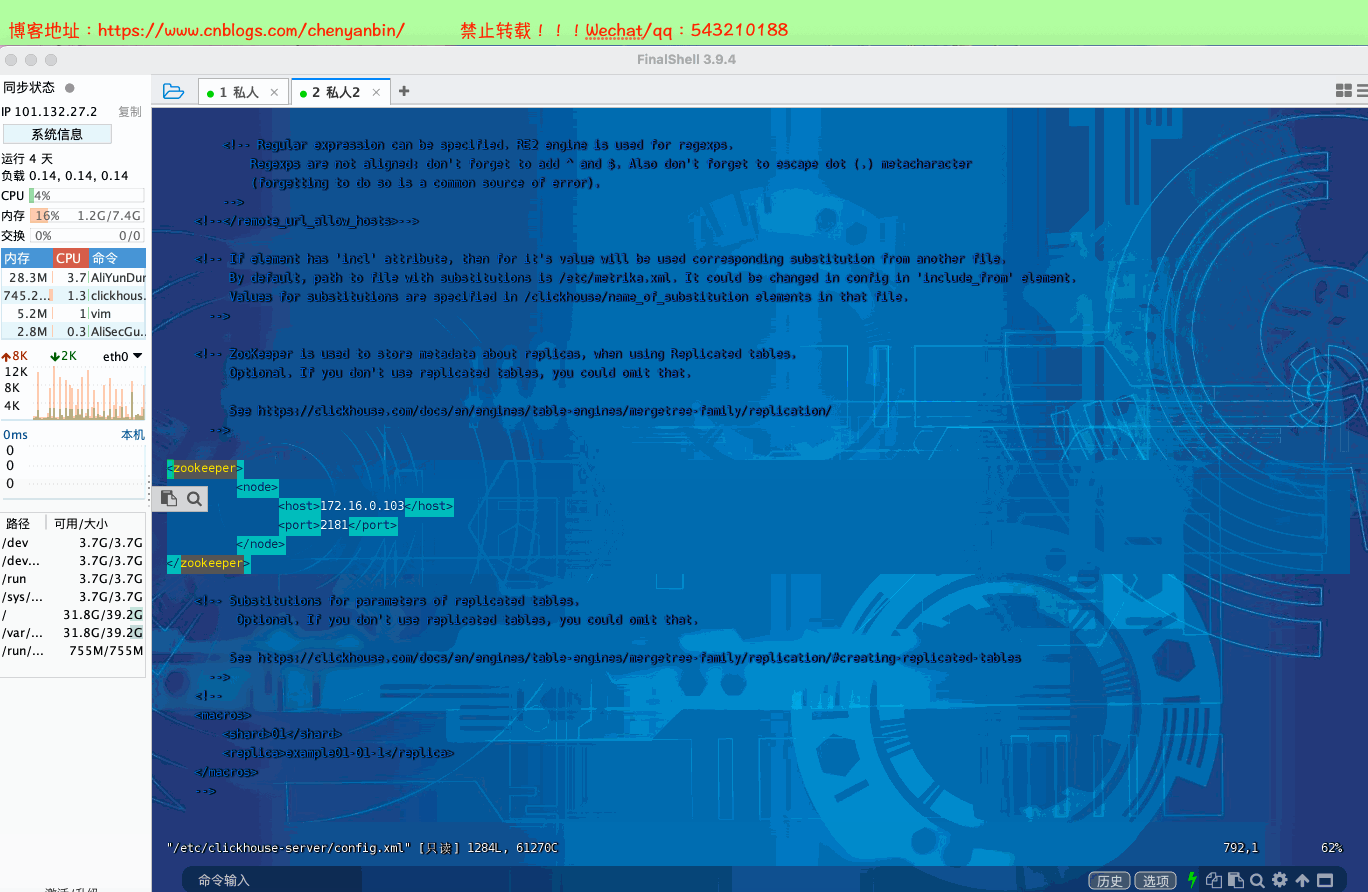
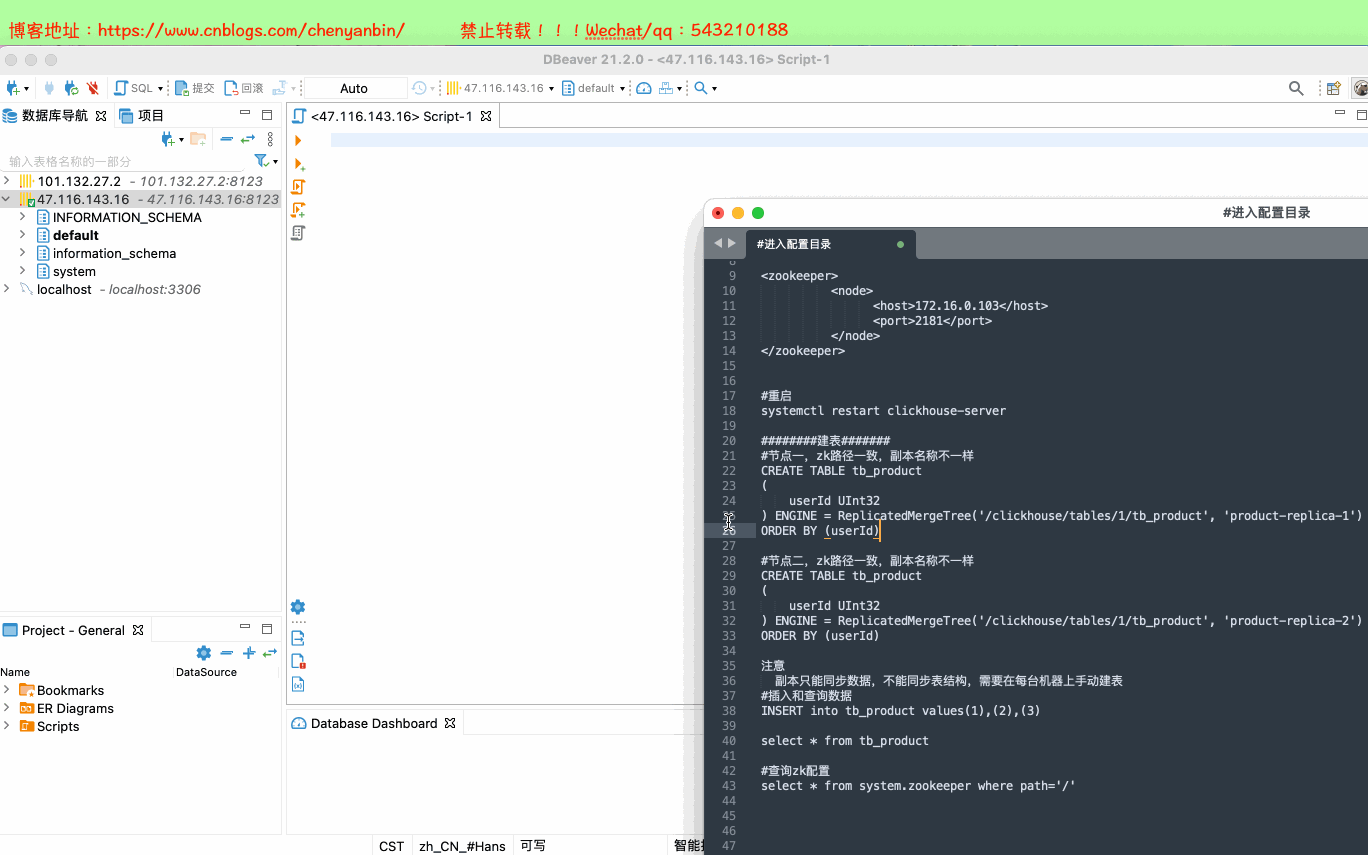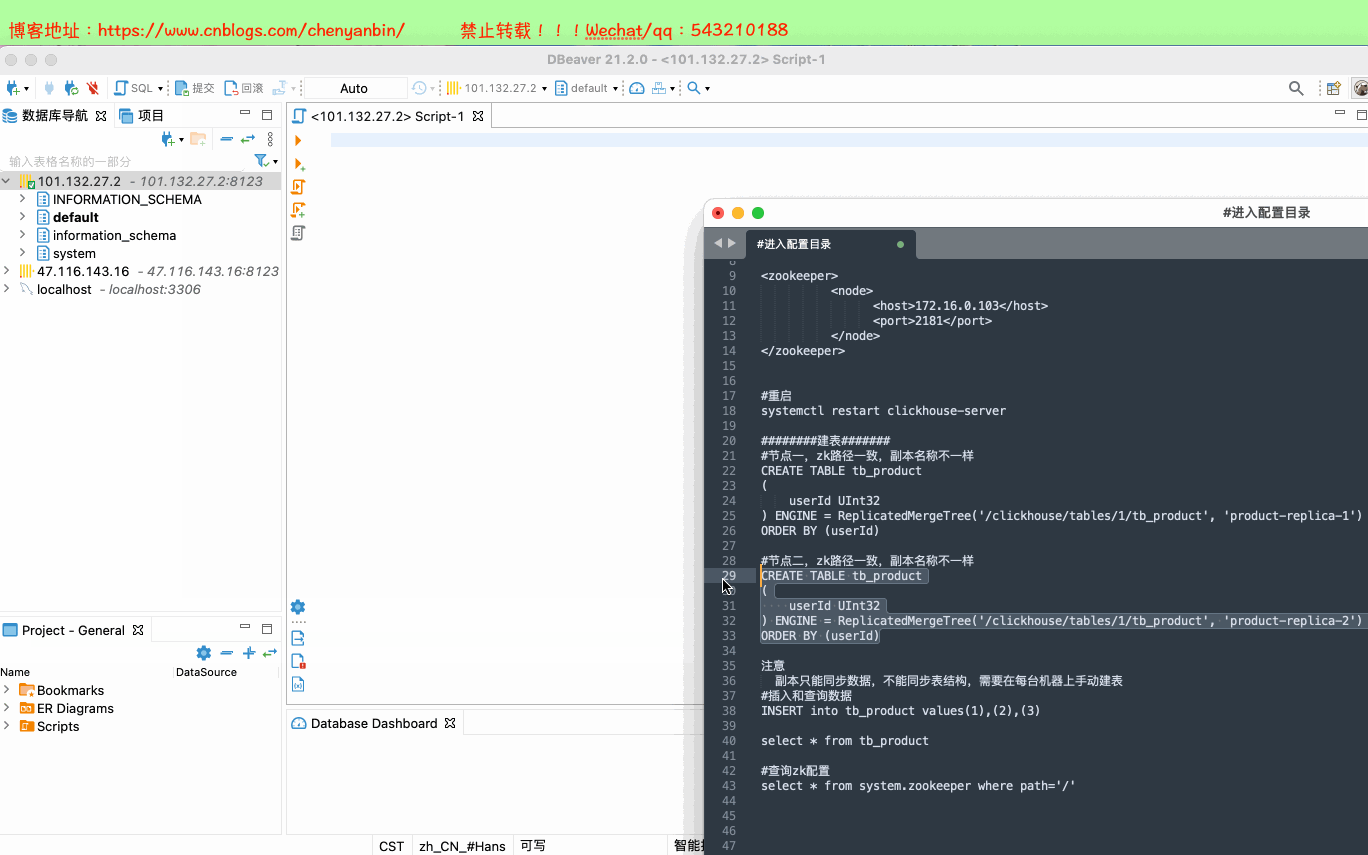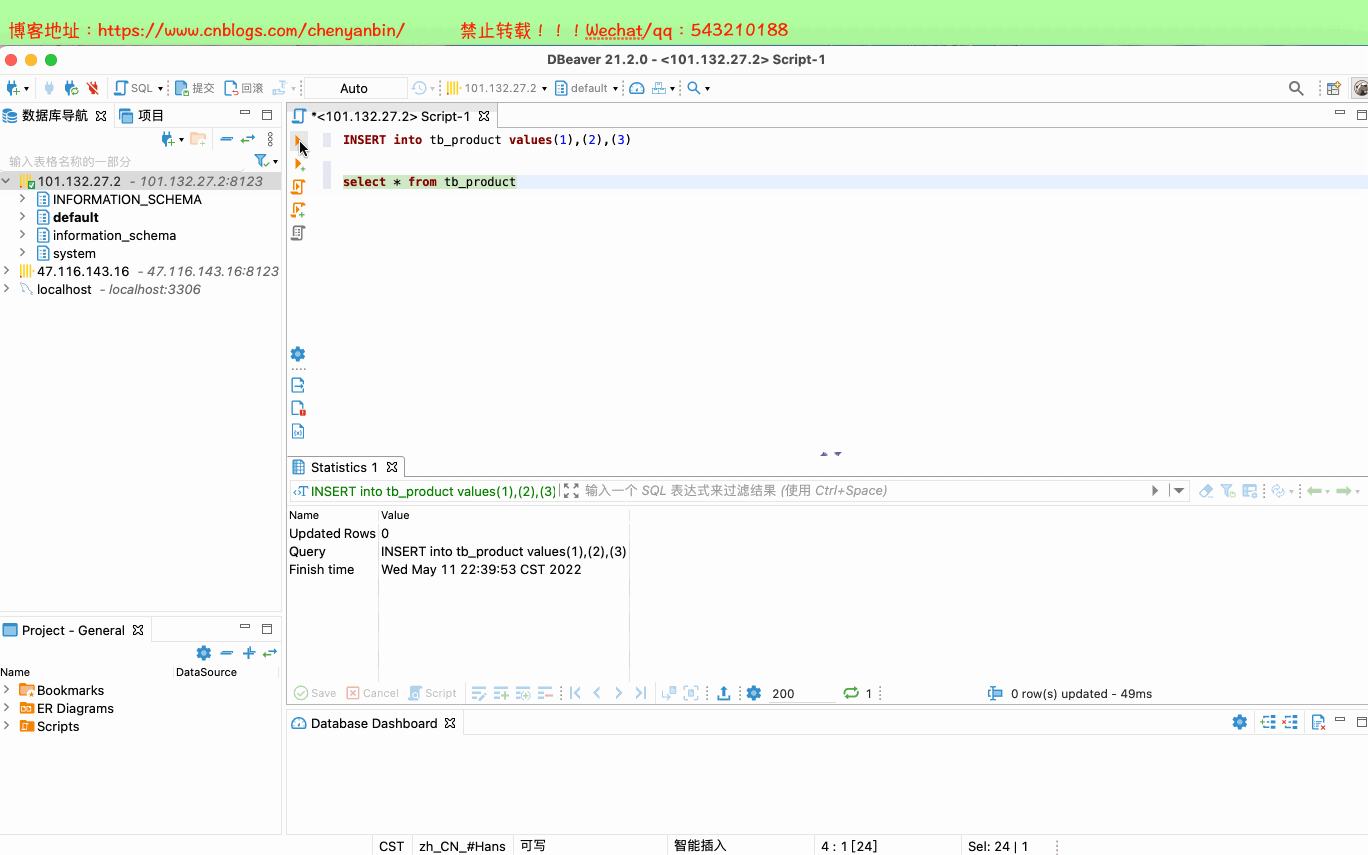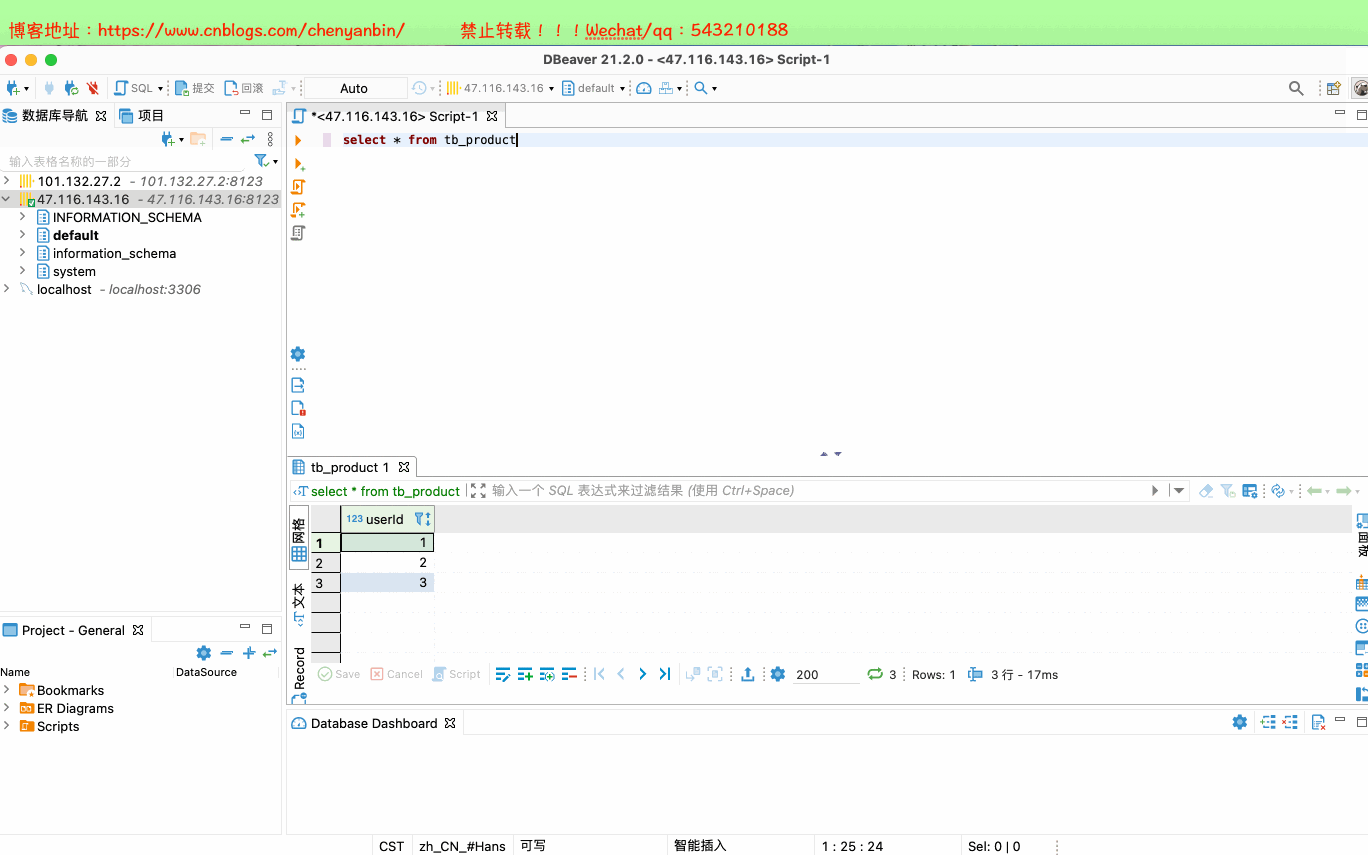
#进入配置目录cd /etc/clickhouse-server#编辑配置文件sudo vim config.xml#找到zookeeper节点,增加下面的,如果有多个zk则按照顺序加即可<zookeeper> <node> <host>172.16.0.103</host> <port>2181</port> </node></zookeeper>#重启systemctl restart clickhouse-server########建表########节点一,zk路径一致,副本名称不一样CREATE TABLE tb_product( userId UInt32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-1')ORDER BY (userId)#节点二,zk路径一致,副本名称不一样CREATE TABLE tb_product( userId UInt32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-2')ORDER BY (userId)注意 副本只能同步数据,不能同步表结构,需要在每台机器上手动建表#插入和查询数据INSERT into tb_product values(1),(2),(3)select * from tb_product#查询zk配置select * from system.zookeeper where path='/'
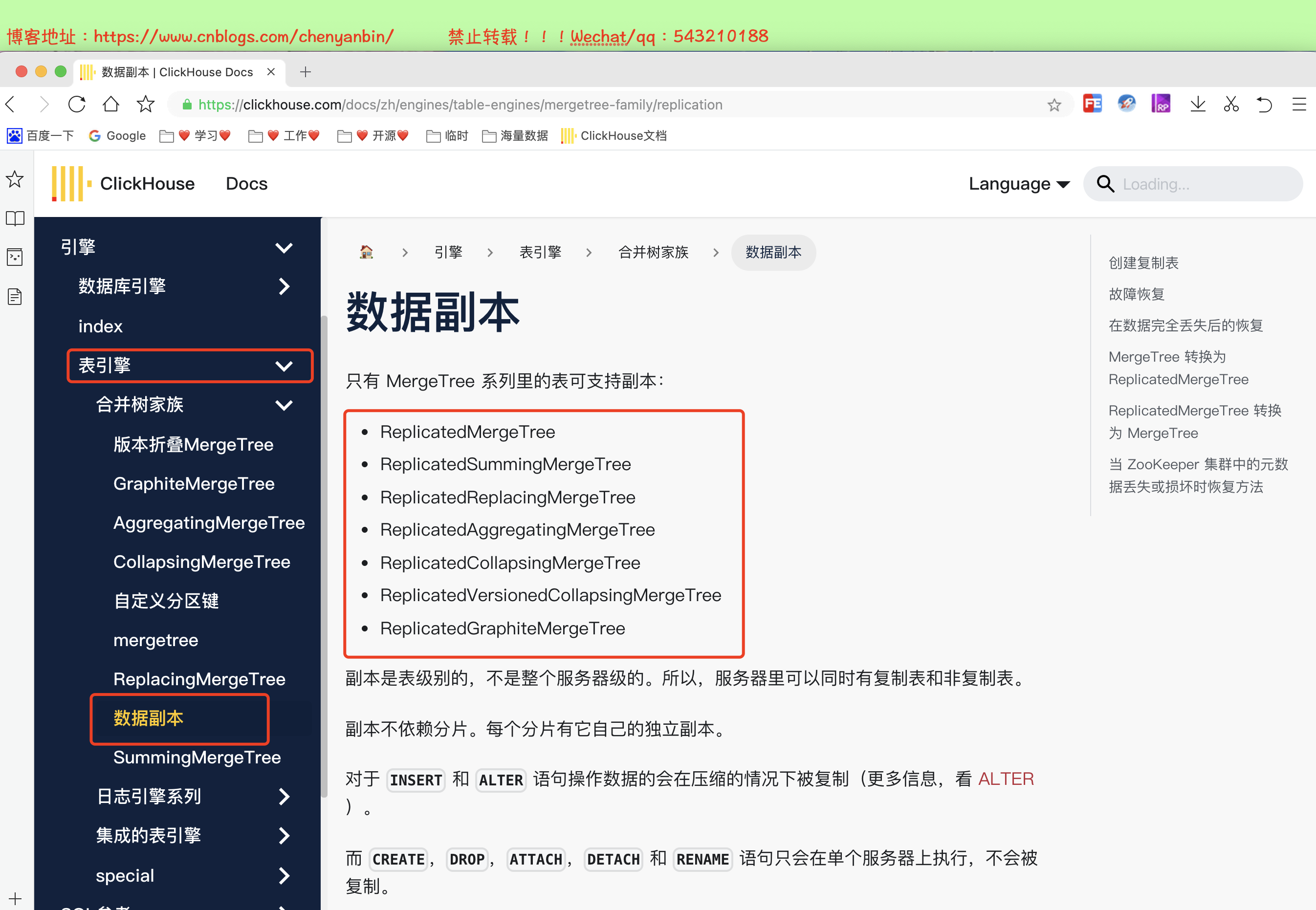
zoo_path — zk 中该表的路径,可自定义名称,同一张表的同一分片的不同副本,要定义相同的路径replica_name — zk 中的该表的副本名称,同一张表的同一分片的不同副本,要定义不同的名称CREATE TABLE tb_order( EventDate DateTime, CounterID UInt32, UserID UInt32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/tb_order', 'tb_order_01')PARTITION BY toYYYYMM(EventDate)ORDER BY (CounterID, EventDate, intHash32(UserID))SAMPLE BY intHash32(UserID)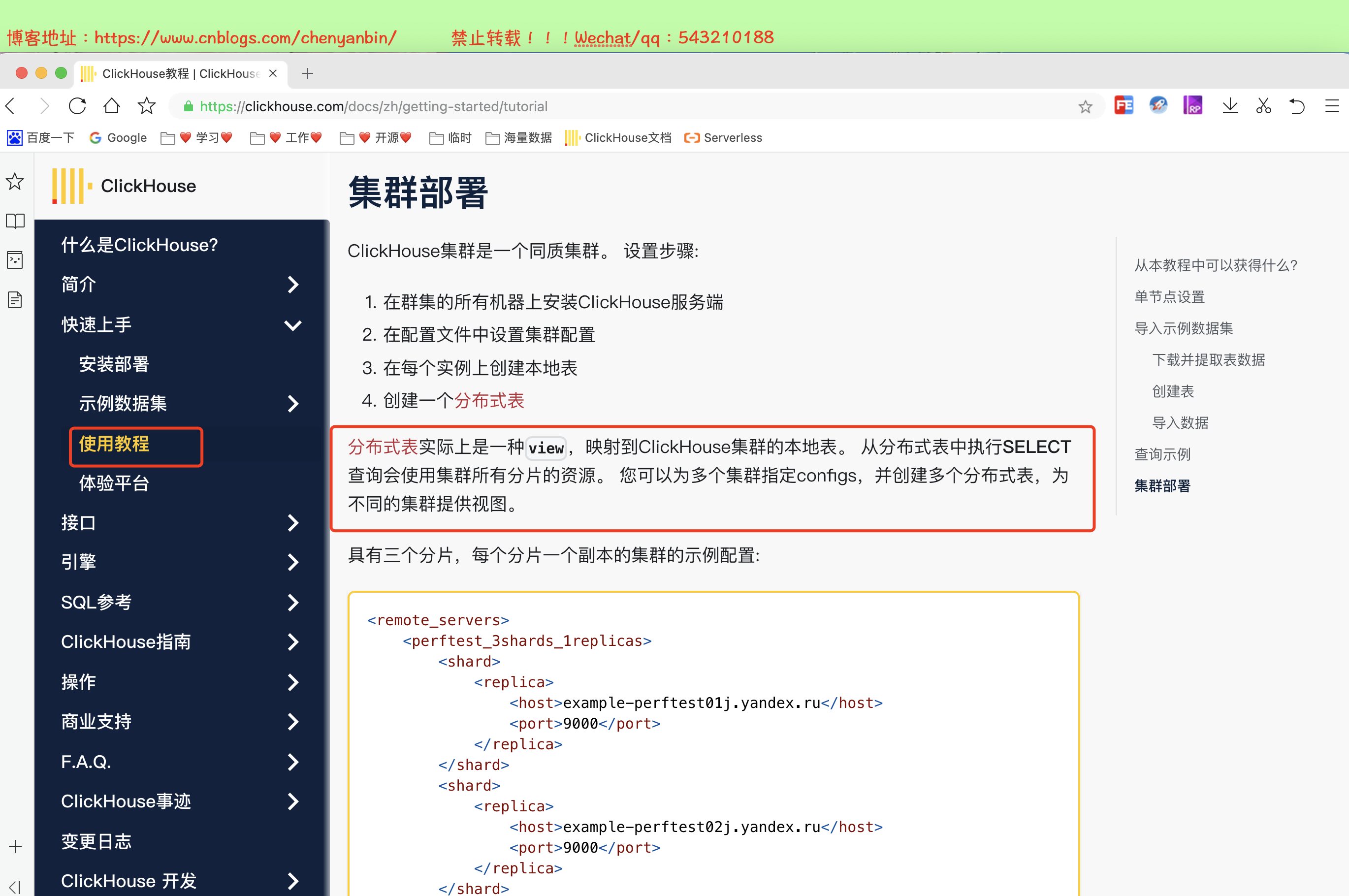

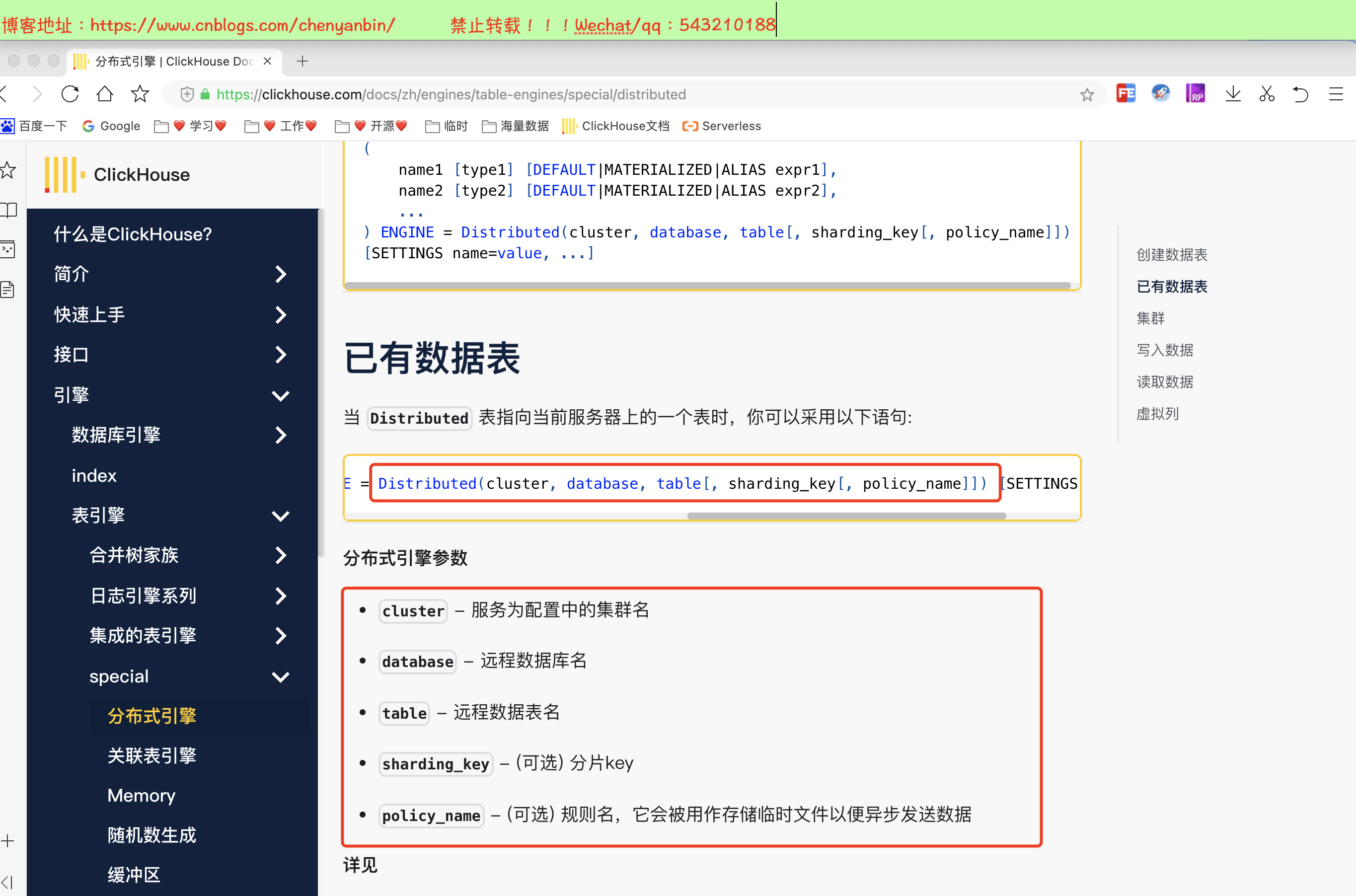
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ...) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])[SETTINGS name=value, ...]cluster:集群名称,与集群配置中的自定义名称相对应,比如 xdclass_shard。
database:数据库名称
table:本地表名称
sharding_key:可选参数,用于分片的key值,在写入的数据Distributed表引擎会依据分片key的规则,将数据分布到各个节点的本地表
<remote_servers> <logs> <!-- 分布式查询的服务器间集群密码 默认值:无密码(将不执行身份验证) 如果设置了,那么分布式查询将在分片上验证,所以至少: - 这样的集群应该存在于shard上 - 这样的集群应该有相同的密码。 而且(这是更重要的),initial_user将作为查询的当前用户使用。 --> <!-- <secret></secret> --> <shard> <!-- 可选的。写数据时分片权重。 默认: 1. --> <weight>1</weight> <!-- 可选的。是否只将数据写入其中一个副本。默认值:false(将数据写入所有副本)。 --> <internal_replication>false</internal_replication> <replica> <!-- 可选的。负载均衡副本的优先级,请参见(load_balancing 设置)。默认值:1(值越小优先级越高)。 --> <priority>1</priority> <host>example01-01-1</host> <port>9000</port> </replica> <replica> <host>example01-01-2</host> <port>9000</port> </replica> </shard> <shard> <weight>2</weight> <internal_replication>false</internal_replication> <replica> <host>example01-02-1</host> <port>9000</port> </replica> <replica> <host>example01-02-2</host> <secure>1</secure> <port>9440</port> </replica> </shard> </logs></remote_servers>
这里定义了一个名为’logs’的集群,它由两个分片组成,每个分片包含两个副本。 分片是指包含数据不同部分的服务器(要读取所有数据,必须访问所有分片)。 副本是存储复制数据的服务器(要读取所有数据,访问任一副本上的数据即可)。
集群名称不能包含点号。
每个服务器需要指定 host,port,和可选的 user,password,secure,compression 的参数:
host – 远程服务器地址。可以域名、IPv4或IPv6。如果指定域名,则服务在启动时发起一个 DNS 请求,并且请求结果会在服务器运行期间一直被记录。如果 DNS 请求失败,则服务不会启动。如果你修改了 DNS 记录,则需要重启服务。port – 消息传递的 TCP 端口(「tcp_port」配置通常设为 9000)。不要跟 http_port 混淆。user – 用于连接远程服务器的用户名。默认值:default。该用户必须有权限访问该远程服务器。访问权限配置在 users.xml 文件中。更多信息,请查看?访问权限?部分。password – 用于连接远程服务器的密码。默认值:空字符串。secure – 是否使用ssl进行连接,设为true时,通常也应该设置 port = 9440。服务器也要监听 <tcp_port_secure>9440</tcp_port_secure> 并有正确的证书。compression - 是否使用数据压缩。默认值:true。| 服务类型 | 公网 | 私网 | hostname |
| clickhouse-1 | 47.116.143.16 | 172.16.0.103 | ybchen-1 |
| clickhouse-2 | 101.132.27.2 | 172.16.0.108 | ybchen-2 |
| zookeeper | 47.116.143.16 | 172.16.0.103 | ybchen-1 |
#进入配置目录cd /etc/clickhouse-server#编辑配置文件sudo vim config.xml<!-- 2shard 1replica --> <cluster_2shards_1replicas> <!-- shard1 --> <shard> <replica> <host>172.16.0.103</host> <port>9000</port> </replica> </shard> <!-- shard2 --> <shard> <replica> <host>172.16.0.108</host> <port> 9000</port> </replica> </shard> </cluster_2shards_1replicas> <zookeeper> <node > <host>172.16.0.103</host> <port>2181</port> </node> </zookeeper>
systemctl restart clickhouse-server
select * from system.clusters

#【选一个节点】创建好本地表后,在1个节点创建,会在其他节点都存在create table default.ybchen_order on cluster cluster_2shards_1replicas(id Int8,name String) engine =MergeTree order by id;#【选一个节点】创建分布式表名 ybchen_order_all,在1个节点创建,会在其他节点都存在create table ybchen_order_all on cluster cluster_2shards_1replicas (id Int8,name String)engine = Distributed(cluster_2shards_1replicas,default, ybchen_order,hiveHash(id));#分布式表插入insert into ybchen_order_all values(1,'老陈'),(2,'老王'),(3,'老李'),(4,'老赵');#【任意节点查询-分布式,全部数据】SELECT * from ybchen_order_all#【任意本地节点查询,部分数据】SELECT * from ybchen_order
CREATE TABLE default.visit_stats( `product_id` UInt64, `is_new` UInt16, `province` String, `city` String, `pv` UInt32, `visit_time` DateTime)ENGINE = MergeTree()PARTITION BY toYYYYMMDD(visit_time)ORDER BY ( product_id, is_new, province, city );
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.5.13</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.ybchen</groupId> <artifactId>ybchen-clickhouse</artifactId> <version>0.0.1-SNAPSHOT</version> <name>ybchen-clickhouse</name> <description>SpringBoot整合Clickhouse</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!-- lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!-- clickhouse --> <dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.3.2</version> </dependency> <!--mybatis plus--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.1</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build></project>
server.port=8888spring.datasource.driver-class-name=ru.yandex.clickhouse.ClickHouseDriverspring.datasource.url=jdbc:clickhouse://47.116.143.16:8123/default# 账号#spring.datasource.username=# 密码#spring.datasource.password=mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpllogging.level.root=INFOpackage com.ybchen.model;import com.baomidou.mybatisplus.annotation.TableName;import lombok.Data;/** * @Description: * @Author:chenyanbin * @CreateTime: 2022-05-14 21:51 * @Version:1.0.0 */@Data@TableName("visit_stats")public class VisitStatsDO { /** * 商品 */ private Long productId; /** * 1是新访客,0是老访客 */ private Integer isNew; /** * 省份 */ private String province; /** * 城市 */ private String city; /** * 访问量 */ private Integer pv; /** * 访问时间 */ private String visitTime;}
package com.ybchen.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.ybchen.model.VisitStatsDO;public interface VisitStatsMapper extends BaseMapper<VisitStatsDO> {}
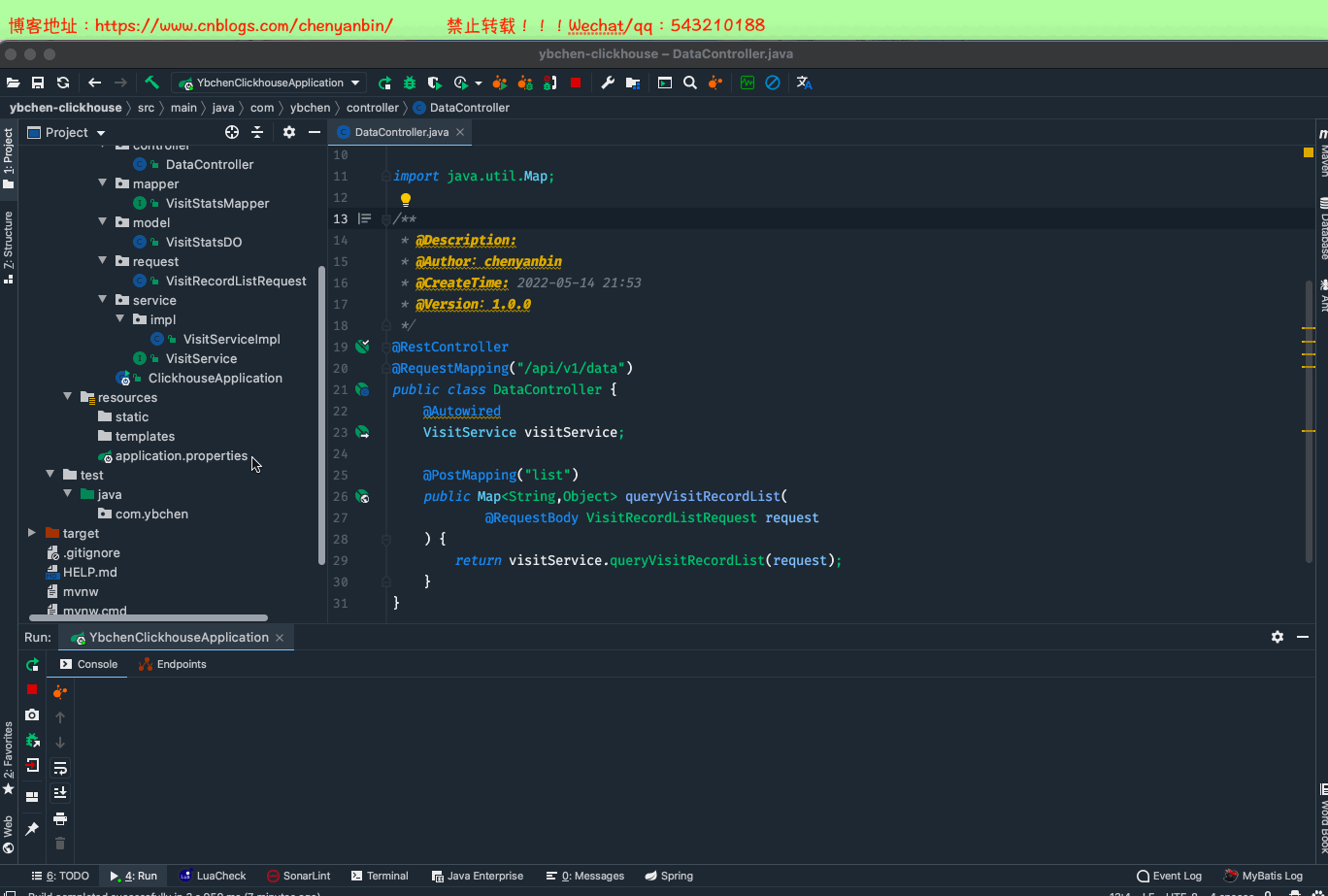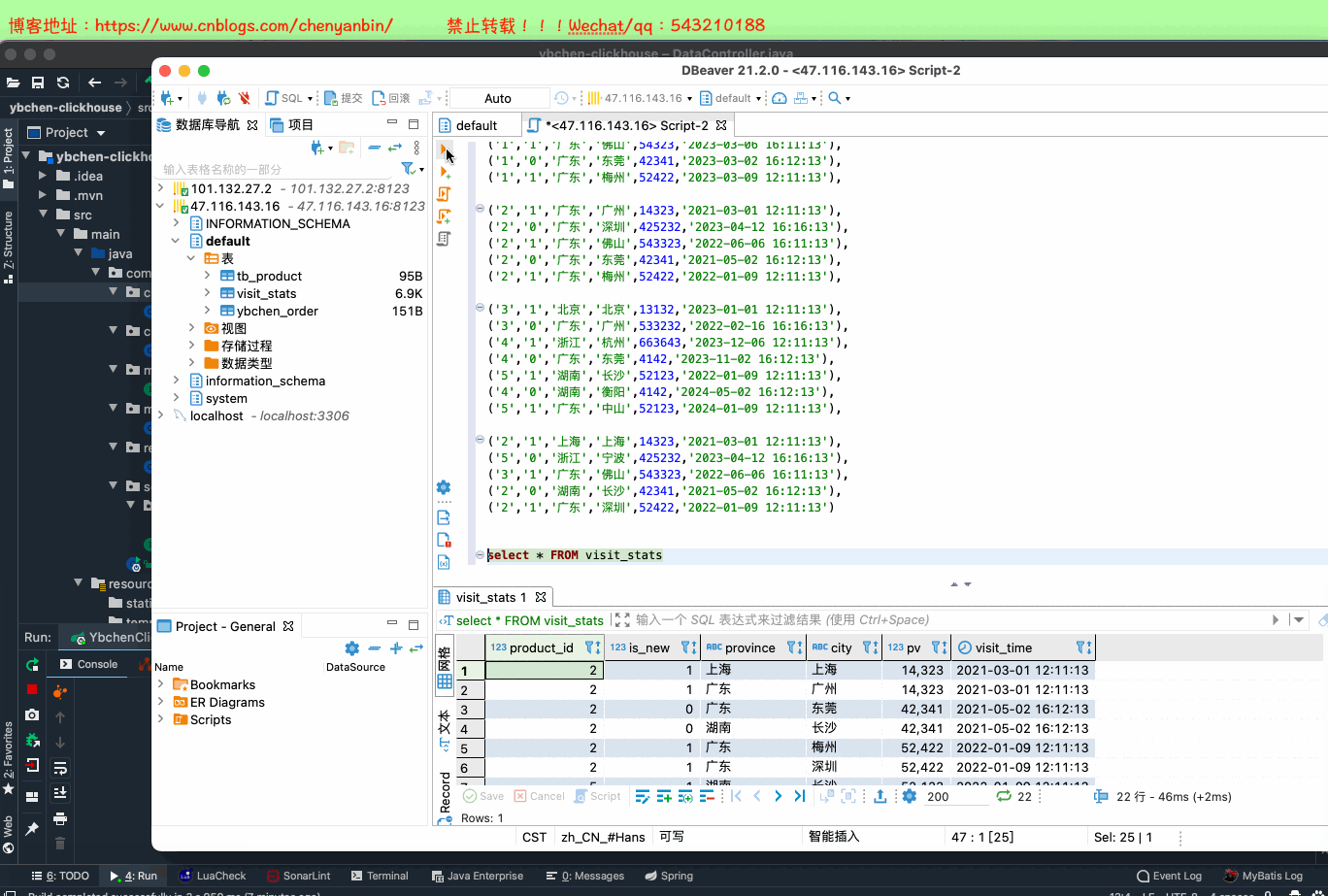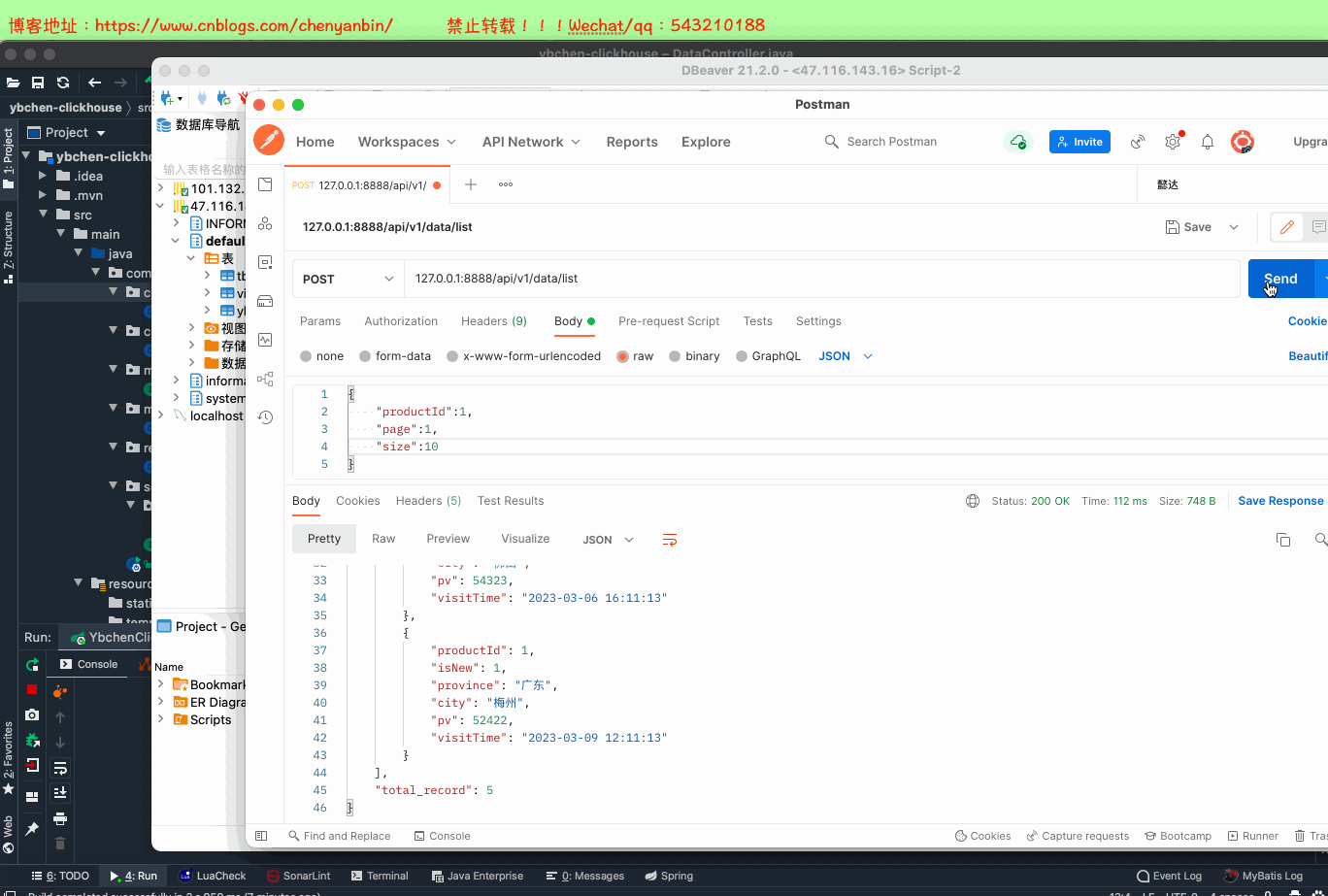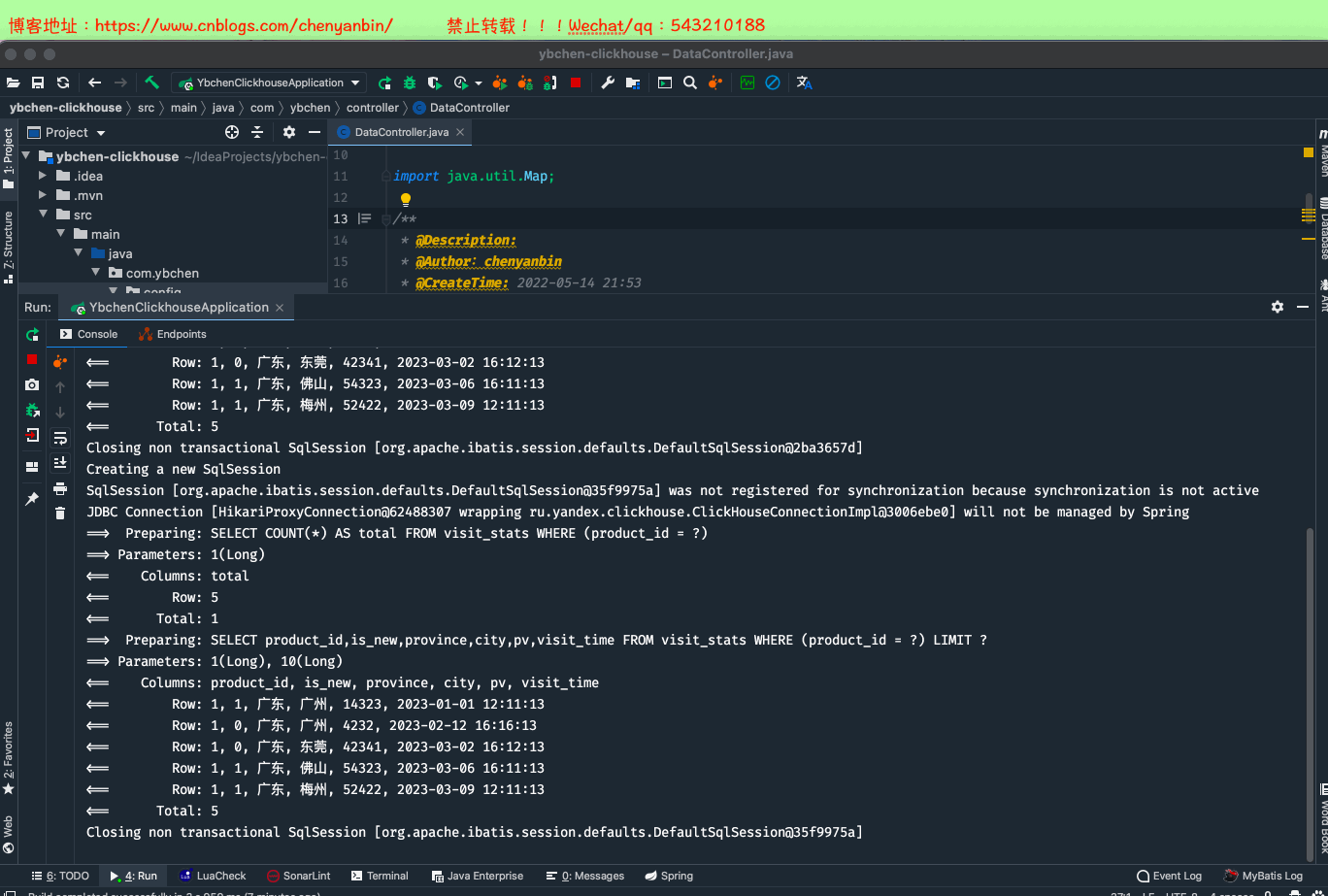
package com.ybchen.controller;import com.ybchen.request.VisitRecordListRequest;import com.ybchen.service.VisitService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestBody;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;import java.util.Map;/** * @Description: * @Author:chenyanbin * @CreateTime: 2022-05-14 21:53 * @Version:1.0.0 */@RestController@RequestMapping("/api/v1/data")public class DataController { @Autowired VisitService visitService; @PostMapping("list") public Map<String,Object> queryVisitRecordList( @RequestBody VisitRecordListRequest request ) { return visitService.queryVisitRecordList(request); }}
package com.ybchen.request;import lombok.Data;/** * @Description: * @Author:chenyanbin * @CreateTime: 2022-05-14 21:54 * @Version:1.0.0 */@Datapublic class VisitRecordListRequest { private Long productId; private int page; private int size;}
package com.ybchen.service;import com.ybchen.request.VisitRecordListRequest;import java.util.Map;public interface VisitService { /** * 查询访问记录 * @param request * @return */ Map<String, Object> queryVisitRecordList(VisitRecordListRequest request);}
package com.ybchen.service.impl;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;import com.baomidou.mybatisplus.core.metadata.IPage;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;import com.ybchen.mapper.VisitStatsMapper;import com.ybchen.model.VisitStatsDO;import com.ybchen.request.VisitRecordListRequest;import com.ybchen.service.VisitService;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.HashMap;import java.util.Map;/** * @Description: * @Author:chenyanbin * @CreateTime: 2022-05-14 21:55 * @Version:1.0.0 */@Service@Slf4jpublic class VisitServiceImpl implements VisitService { @Autowired VisitStatsMapper visitStatsMapper; @Override public Map<String, Object> queryVisitRecordList(VisitRecordListRequest request) { Map<String, Object> dataMap = new HashMap<>(3); IPage<VisitStatsDO> pageInfo = new Page<>(request.getPage(), request.getSize()); IPage<VisitStatsDO> visitStatsDOIPage = visitStatsMapper.selectPage( pageInfo, new LambdaQueryWrapper<VisitStatsDO>() .eq(VisitStatsDO::getProductId, request.getProductId()) ); /** * 分页记录列表 */ dataMap.put("current_data",visitStatsDOIPage.getRecords()); /** * 当前分页总页数 */ dataMap.put("total_page",visitStatsDOIPage.getPages()); /** * 总记录数 */ dataMap.put("total_record",visitStatsDOIPage.getTotal()); return dataMap; }}
Clickhouse语法和mysql差不多,只不过Clickhouse提供了更加丰富的函数,具体请查阅官网文档:点我直达

