有2种常见的多维度查询场景,分别是:
普通的数据库查询,很难实现上述需求场景,更不用提模糊查询、全文检索了。
下面结合楼主的经验和知识,介绍初级方案、进阶方案(上ElasticSearch),大部分情况下推荐使用ElasticSearch来实现多维度查询,赶时间的读者可以直接跳到“进阶方案:将ElasticSearch添加到现有系统中”。
这个是为了实现带多个筛选条件的列表查询的。
于是就出现了经典的一幕:产品提需求说要支持某个新字段的筛选查询,开发反馈说做不了、或者成本很高,于是不了了之 :)
更加优雅的方式,是异构出多份数据。
例如,C端按用户维度查询,B端按店铺维度查询,如果还有供应商,按供应商维度查询。一个数据库只能按一种维度来分库。
优点是:非常简单。
通过Canal同步数据,异构出多个维度的数据源。详见之前写的这篇文章:架构师必备:巧用Canal实现异步、解耦的架构

优点是:更加优雅,无需改动程序主流程。
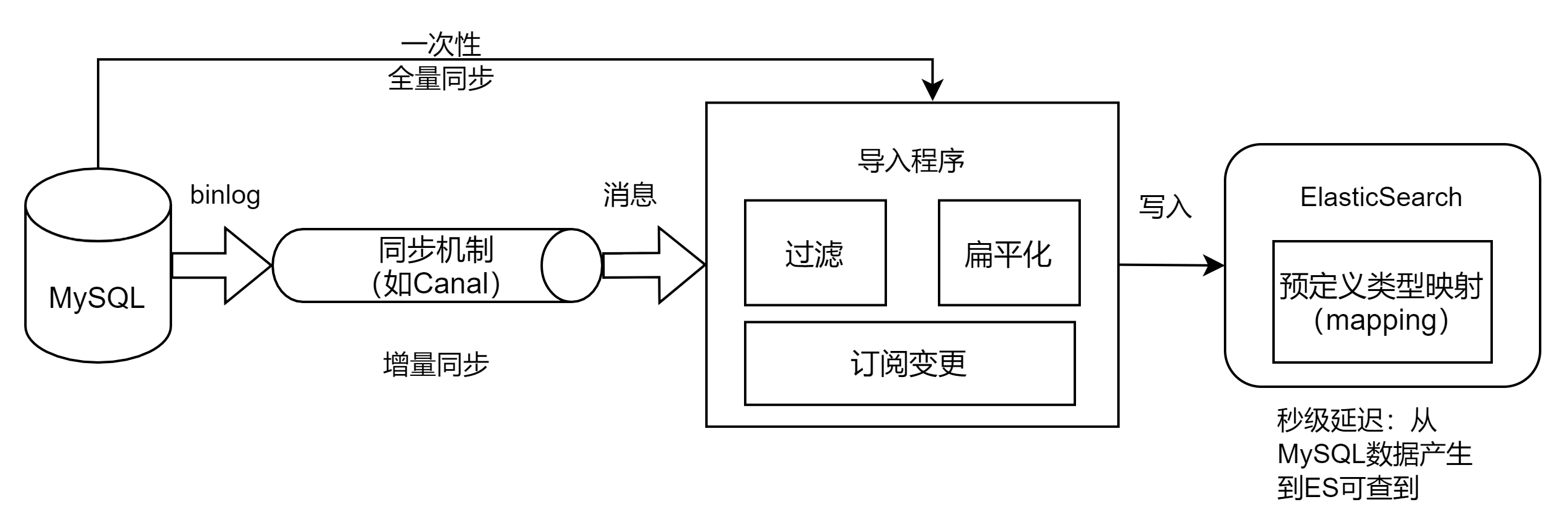
现有系统一般都会用到MySQL数据库,需要引入ES,为系统增强多维度查询的功能。
MySQL继续承担业务的实时读写请求、事务操作,ES承担近实时的多维度查询请求,ES可支撑十万级别qps(取决于节点数、分片数、副本数)。
需要注意的是:同步数据至ES是秒级延迟(主要耗费在索引refresh),而查询已进入索引的文档,是在数毫秒到数百毫秒级别。

需要同步机制,来把MySQL中的数据导入到ES中,主要流程如下:
从ES 8.x版本开始,建议使用Java api client,并且要Java 8及以上环境,因为可使用各种lambda函数,来提高代码可读性
ES 7.x版本及以下,或使用Java 7及以下,建议升级,否则就只能继续用high level rest client。
代码示例如下(含详细注释):
public class EsClientDemo { // demo演示:创建client,然后搜索 public void createClientAndSearch() throws Exception { // 创建底层的low level rest client,连接ES节点的9200端口 RestClient restClient = RestClient.builder( new HttpHost("localhost", 9200)).build(); // 创建transport类,传入底层的low level rest client,和json解析器 ElasticsearchTransport transport = new RestClientTransport( restClient, new JacksonJsonpMapper()); // 创建核心client类,后续操作都围绕此对象 ElasticsearchClient esClient = new ElasticsearchClient(transport); // 多条件搜索 // fluent API风格,并且使用lambda函数提高代码可读性,可以看出Java api client的语法,同http json请求体非常相似 String searchText = "bike"; String brand = "brandNew"; double maxPrice = 1000; // 根据商品名称,做match全文检索查询 Query byName = MatchQuery.of(m -> m .field("name") .query(searchText) )._toQuery(); // 根据品牌,做term精确查询 Query byBrand = new Query.Builder() .term(t -> t .field("brand") .value(v -> v.stringValue(brand)) ).build(); // 根据价格,做range范围查询 Query byMaxPrice = RangeQuery.of(r -> r .field("price") .lte(JsonData.of(maxPrice)) )._toQuery(); // 调用核心client,做查询 SearchResponse<Product> response = esClient.search(s -> s .index("products") // 指定ES索引 .query(q -> q // 指定查询DSL .bool(b -> b // 多条件must组合,必须同时满足 .must(byName) .must(byBrand) .must(byMaxPrice) ) ), Product.class ); // 遍历命中结果 List<Hit<Product>> hits = response.hits().hits(); for (Hit<Product> hit: hits) { Product product = hit.source(); // 通过source获取结果 logger.info("Found product " + product.getName() + ", score " + hit.score()); } }}可参阅:https://www.elastic.co/guide/en/elasticsearch/client/index.html
因为既有MySQL,又有ES,所以有2种异构的数据模型。需要在代码中定义2种数据模型,并且实现类型互相转换的工具类。
ES之所以比MySQL,能胜任多维度查询、全文检索,是因为底层数据结构不同:
另外简要回顾一下ES的架构要点:
前面提到ES超高并发下存在瓶颈,极端情况下可能遇到OOM,因此超高并发下需要C++实现的专用搜索引擎
例如:
