 首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce。Hadoop为每个分片创建一个map任务,由它来运行用户自定义的map函数以分析每个分片中的记录。在我们的单词计数例子中,输入是多个文件,一般一个文件对应一个分片,如果文件太大则会划分为多个分片。map函数的输入以
首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce。Hadoop为每个分片创建一个map任务,由它来运行用户自定义的map函数以分析每个分片中的记录。在我们的单词计数例子中,输入是多个文件,一般一个文件对应一个分片,如果文件太大则会划分为多个分片。map函数的输入以 首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce。Hadoop为每个分片创建一个map任务,由它来运行用户自定义的map函数以分析每个分片中的记录。在我们的单词计数例子中,输入是多个文件,一般一个文件对应一个分片,如果文件太大则会划分为多个分片。map函数的输入以<key, value>形式做为输入,value为文件的每一行,key为该行在文件中的偏移量(一般我们会忽视)。这里map函数起到的作用为将每一行进行分词为多个word,并在context中写入<word, 1>以代表该单词出现一次。
map过程的示意图如下:

mapper代码编写如下:
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { //每次处理一行,一个mapper里的value为一行,key为该行在文件中的偏移量 StringTokenizer iter = new StringTokenizer(value.toString()); while (iter.hasMoreTokens()) { word.set(iter.nextToken()); // 向context中写入<word, 1> context.write(word, one); System.out.println(word); } }}如果我们能够并行处理分片(不一定是完全并行),且分片是小块的数据,那么处理过程将会有一个好的负载平衡。但是如果分片太小,那么管理分片与map任务创建将会耗费太多时间。对于大多数作业,理想分片大小为一个HDFS块的大小,默认是64MB。
map任务的执行节点和输入数据的存储节点相同时,Hadoop的性能能达到最佳,这就是计算机系统中所谓的data locality optimization(数据局部性优化)。而最佳分片大小与块大小相同的原因就在于,它能够保证一个分片存储在单个节点上,再大就不能了。
接下来我们看reducer的编写。reduce任务的多少并不是由输入大小来决定,而是需要人工单独指定的(默认为1个)。和上面map不同的是,reduce任务不再具有本地读取的优势————一个reduce任务的输入往往来自于所有mapper的输出,因此map和reduce之间的数据流被称为 shuffle(洗牌) 。Hadoop会先按照key-value对进行排序,然后将排序好的map的输出通过网络传输到reduce任务运行的节点,并在那里进行合并,然后传递到用户定义的reduce函数中。
reduce 函数示意图如下: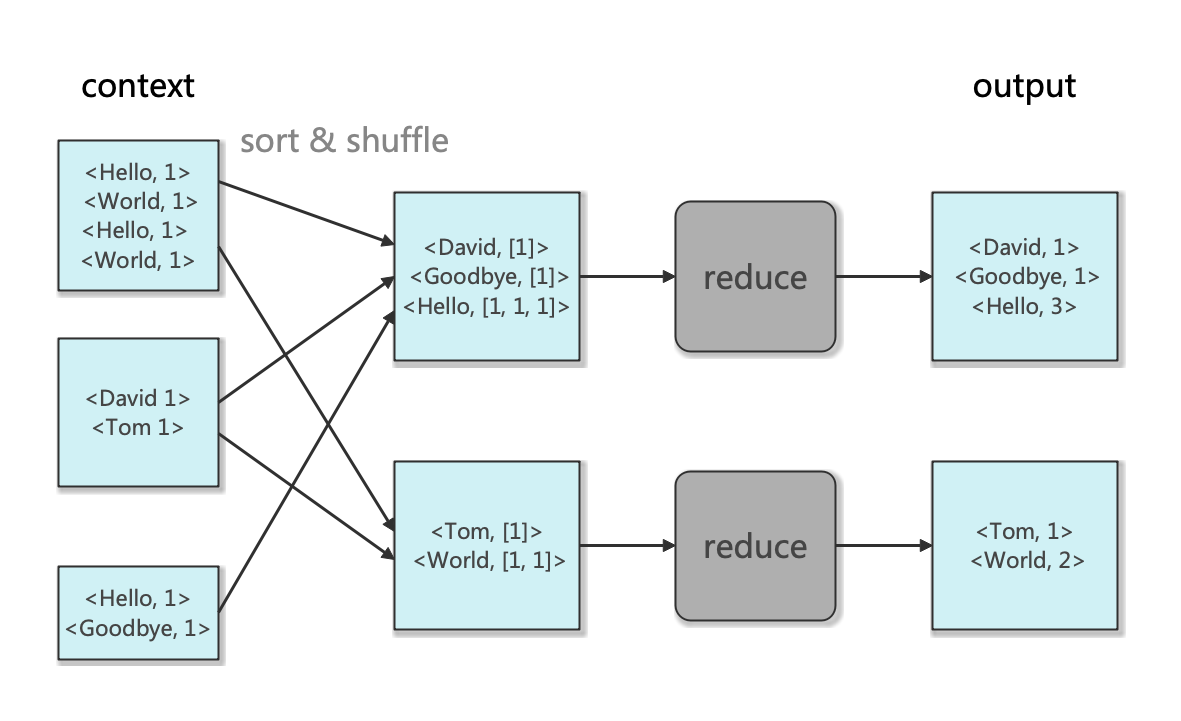
reducer代码编写如下:
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }关于VSCode+Java+Maven+Hadoop开发环境搭建,可以参见我的博客《VSCode+Maven+Hadoop开发环境搭建》,此处不再赘述。这里展示我们的项目架构图:
Word-Count-Hadoop├─ input│ ├─ file1│ ├─ file2│ └─ file3├─ output├─ pom.xml├─ src│ └─ main│ └─ java│ └─ WordCount.java└─ targetWordCount.java代码如下:
import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount{ public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { //每次处理一行,一个mapper里的value为一行,key为该行在文件中的偏移量 StringTokenizer iter = new StringTokenizer(value.toString()); while (iter.hasMoreTokens()) { word.set(iter.nextToken()); // 向context中写入<word, 1> context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word_count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); //此处的Combine操作意为即第每个mapper工作完了先局部reduce一下,最后再全局reduce job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //第0个参数是输入目录,第1个参数是输出目录 //先判断output path是否存在,如果存在则删除 Path path = new Path(args[1]);// FileSystem fileSystem = path.getFileSystem(conf); if (fileSystem.exists(path)) { fileSystem.delete(path, true); } //设置输入目录和输出目录 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1); }}pom.xml中记得配置Hadoop的依赖环境:
... <!-- 集中定义版本号 --> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <hadoop.version>3.3.1</hadoop.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <!-- 导入hadoop依赖环境 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-api</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> ...</project>此外,因为我们的程序自带输入参数,我们还需要在VSCode的launch.json中配置输入参数intput(代表输入目录)和output(代表输出目录):
..."args": [ "input", "output"],...编译运行完毕后,可以查看output文件夹下的part-r-00000文件:
David 1Goodbye 1Hello 3Tom 1World 2可见我们的程序正确地完成了单词计数的功能。
