手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(一) - 介绍
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(二) - 数据库设计
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(三) - 项目初始化
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(四) - 日志 & 跨域配置
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(五) - MyBatis-Plus & 代码生成器集成与配置
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(六) - 本地缓存 Caffeine 和 分布式缓存 Redis 集成与配置
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(七) - Elasticsearch 8.2 集成与配置
XXL-JOB 是一个开箱即用的开源分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。由调度模块和执行模块构成:
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;接收“调度中心”的执行请求、终止请求和日志请求等。

XXL-JOB 将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求;将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性。
调度数据库:## XXL-JOB v2.4.0-SNAPSHOT# Copyright (c) 2015-present, xuxueli.CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;use `xxl_job`;SET NAMES utf8mb4;CREATE TABLE `xxl_job_info` ( `id` int(11) NOT NULL AUTO_INCREMENT, `job_group` int(11) NOT NULL COMMENT '执行器主键ID', `job_desc` varchar(255) NOT NULL, `add_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, `author` varchar(64) DEFAULT NULL COMMENT '作者', `alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件', `schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型', `schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型', `misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略', `executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略', `executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler', `executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数', `executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略', `executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒', `executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数', `glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型', `glue_source` mediumtext COMMENT 'GLUE源代码', `glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注', `glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间', `child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔', `trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行', `trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间', `trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `job_group` int(11) NOT NULL COMMENT '执行器主键ID', `job_id` int(11) NOT NULL COMMENT '任务,主键ID', `executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址', `executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler', `executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数', `executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2', `executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数', `trigger_time` datetime DEFAULT NULL COMMENT '调度-时间', `trigger_code` int(11) NOT NULL COMMENT '调度-结果', `trigger_msg` text COMMENT '调度-日志', `handle_time` datetime DEFAULT NULL COMMENT '执行-时间', `handle_code` int(11) NOT NULL COMMENT '执行-状态', `handle_msg` text COMMENT '执行-日志', `alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败', PRIMARY KEY (`id`), KEY `I_trigger_time` (`trigger_time`), KEY `I_handle_code` (`handle_code`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_log_report` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trigger_day` datetime DEFAULT NULL COMMENT '调度-时间', `running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量', `suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量', `fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量', `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_logglue` ( `id` int(11) NOT NULL AUTO_INCREMENT, `job_id` int(11) NOT NULL COMMENT '任务,主键ID', `glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型', `glue_source` mediumtext COMMENT 'GLUE源代码', `glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注', `add_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_registry` ( `id` int(11) NOT NULL AUTO_INCREMENT, `registry_group` varchar(50) NOT NULL, `registry_key` varchar(255) NOT NULL, `registry_value` varchar(255) NOT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_group` ( `id` int(11) NOT NULL AUTO_INCREMENT, `app_name` varchar(64) NOT NULL COMMENT '执行器AppName', `title` varchar(12) NOT NULL COMMENT '执行器名称', `address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入', `address_list` text COMMENT '执行器地址列表,多地址逗号分隔', `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(50) NOT NULL COMMENT '账号', `password` varchar(50) NOT NULL COMMENT '密码', `role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员', `permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割', PRIMARY KEY (`id`), UNIQUE KEY `i_username` (`username`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_lock` ( `lock_name` varchar(50) NOT NULL COMMENT '锁名称', PRIMARY KEY (`lock_name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');commit;注:调度中心支持集群部署,集群情况下各节点务必连接同一个 mysql 实例,如果 mysql 做主从,调度中心集群节点务必强制走主库。
/*** 如需自定义 mysql 等配置,可通过 "-e PARAMS" 指定,参数格式 PARAMS="--key=value --key2=value2" ;* 如需自定义 JVM 内存参数 等配置,可通过 "-e JAVA_OPTS" 指定,参数格式 JAVA_OPTS="-Xmx512m" ;*/docker run \ -e PARAMS=' \ --spring.datasource.url=jdbc:mysql://47.106.243.172:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai \ --spring.datasource.username=test \ --spring.datasource.password=test!1234 \ --xxl.job.accessToken=123' \ -p 8080:8080 \ -v /tmp:/data/applogs \ --name xxl-job-admin \ -d xuxueli/xxl-job-admin:{指定版本} 注:如上所示,数据库密码中如果包含特殊字符(例如,& 或 !),需要对特殊字符进行转义,PARAMS 参数值一定要使用使用单引号而不能使用双引号。
| 常用转义字符 | 作用 |
|---|---|
| 反斜杠(\) | 使反斜杠后面的一个变量变为单纯的字符串,如果放在引号里面,是不起作用的 |
| 单引号(’’) | 转义其中所有的变量为单纯的字符串 |
| 双引号("") | 保留其中的变量属性,不进行转义处理 |
调度中心访问地址:http://ip:8080/xxl-job-admin (该地址执行器将会使用到,作为回调地址)
默认登录账号 “admin/123456”,登录后如下图所示:
xxl-job-core的 maven 依赖:<dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>2.3.1</version></dependency># XXL-JOB 配置xxl: job: admin: ### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册; addresses: http://127.0.0.1:8080/xxl-job-admin executor: ### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册 appname: xxl-job-executor-novel ### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径; logpath: logs/xxl-job/jobhandler ### xxl-job, access token accessToken: 123io.github.xxyopen.novel.core.config包下创建 XXL-JOB 配置类配置执行器组件:/** * XXL-JOB 配置类 * * @author xiongxiaoyang * @date 2022/5/31 */@Configuration@Slf4jpublic class XxlJobConfig { @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.accessToken}") private String accessToken; @Value("${xxl.job.executor.appname}") private String appname; @Value("${xxl.job.executor.logpath}") private String logPath; @Bean public XxlJobSpringExecutor xxlJobExecutor() { log.info(">>>>>>>>>>> xxl-job config init."); XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAccessToken(accessToken); xxlJobSpringExecutor.setAppname(appname); xxlJobSpringExecutor.setLogPath(logPath); return xxlJobSpringExecutor; }}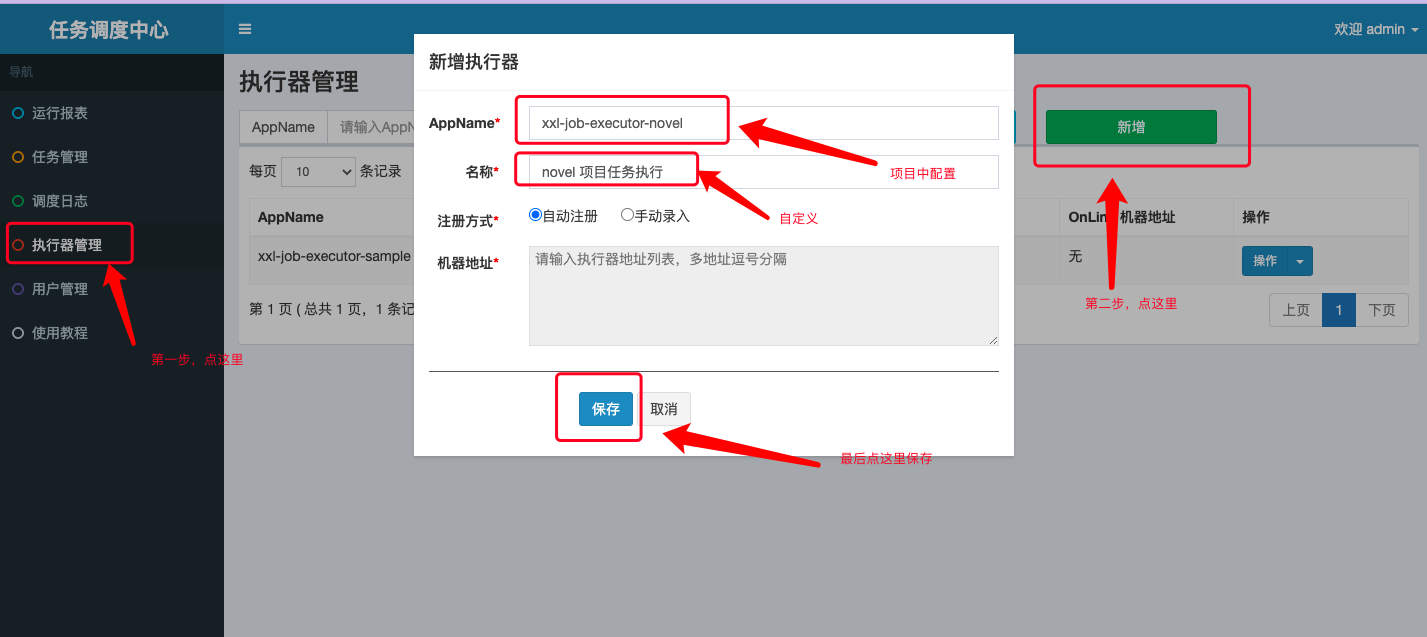
注:AppName 的值需要和 novel 项目 application.yml 配置文件中配置的值保持一致。
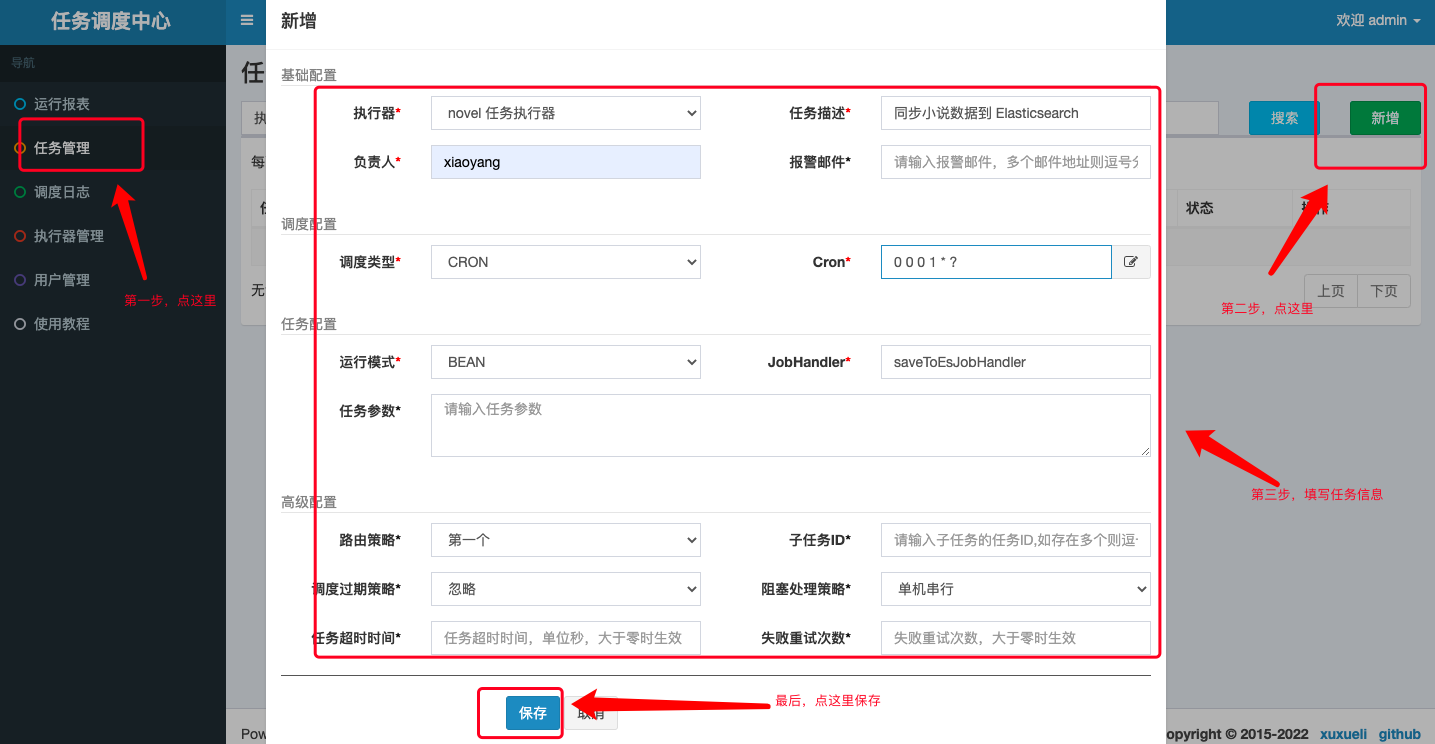
io.github.xxyopen.novel.core.task包下增加 Elasticsearch 数据同步任务:/** * 小说数据同步到 Elasticsearch 任务 * * @author xiongxiaoyang * @date 2022/5/23 */@ConditionalOnProperty(prefix = "spring.elasticsearch", name = "enable", havingValue = "true")@Component@RequiredArgsConstructor@Slf4jpublic class BookToEsTask { private final BookInfoMapper bookInfoMapper; private final ElasticsearchClient elasticsearchClient; @SneakyThrows @XxlJob("saveToEsJobHandler") // 此处需要和调度中心创建任务时填写的 JobHandler 值保持一致 public ReturnT<String> saveToEs() { try { QueryWrapper<BookInfo> queryWrapper = new QueryWrapper<>(); List<BookInfo> bookInfos; long maxId = 0; for (; ; ) { queryWrapper.clear(); queryWrapper .orderByAsc(DatabaseConsts.CommonColumnEnum.ID.getName()) .gt(DatabaseConsts.CommonColumnEnum.ID.getName(), maxId) .last(DatabaseConsts.SqlEnum.LIMIT_30.getSql()); bookInfos = bookInfoMapper.selectList(queryWrapper); if (bookInfos.isEmpty()) { break; } BulkRequest.Builder br = new BulkRequest.Builder(); for (BookInfo book : bookInfos) { br.operations(op -> op .index(idx -> idx .index(EsConsts.BookIndex.INDEX_NAME) .id(book.getId().toString()) .document(EsBookDto.build(book)) ) ).timeout(Time.of(t -> t.time("10s"))); maxId = book.getId(); } BulkResponse result = elasticsearchClient.bulk(br.build()); // Log errors, if any if (result.errors()) { log.error("Bulk had errors"); for (BulkResponseItem item : result.items()) { if (item.error() != null) { log.error(item.error().reason()); } } } } return ReturnT.SUCCESS; } catch (Exception e) { log.error(e.getMessage(), e); return ReturnT.FAIL; } }}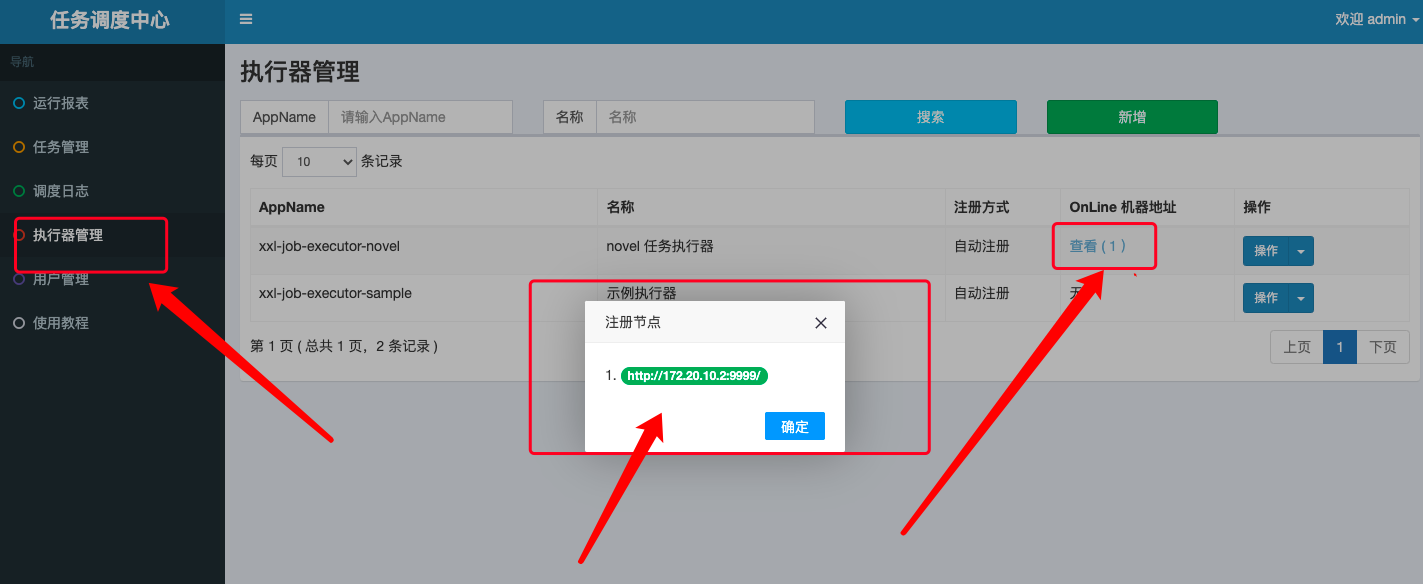
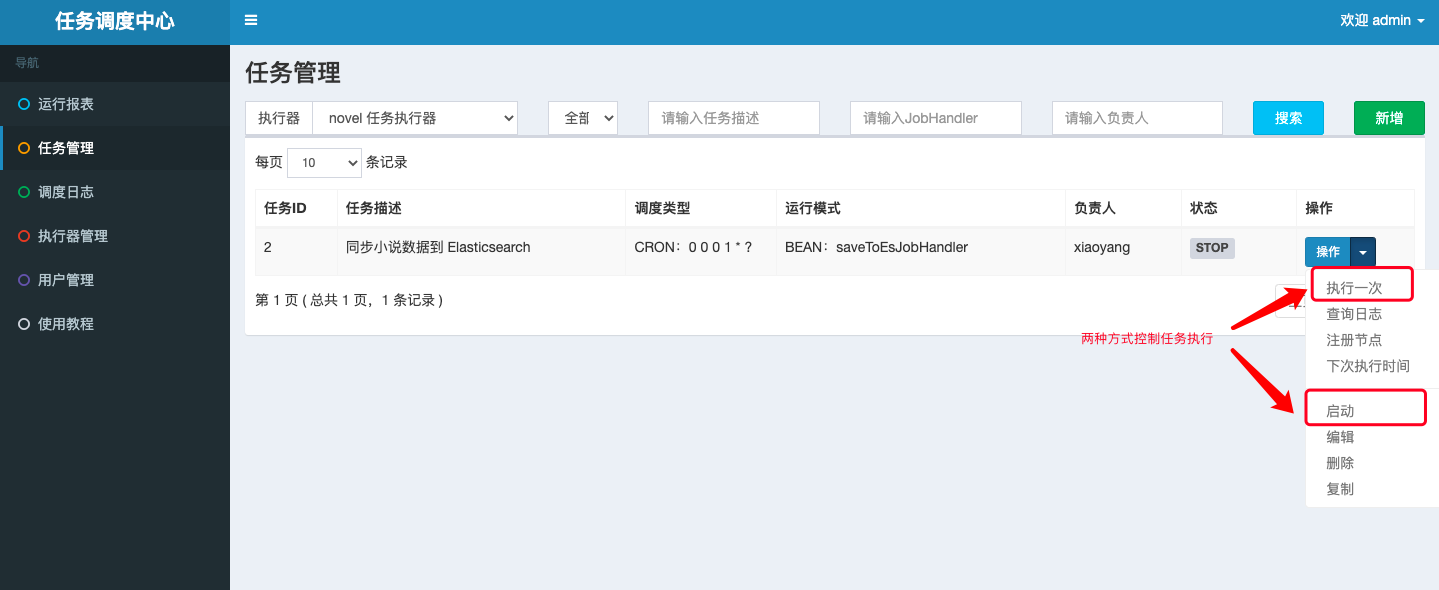
此时,我们可以在任意时刻手动同步数据库的小说数据到 Elasticsearch 搜索引擎中,极大的方便了我们的开发测试工作。
