
ElasticSearch 实现分词全文检索 - 概述
需求
做一个类似百度的全文搜索功能

所用的技术如下:
- ElasticSearch
- Kibana 管理界面
- IK Analysis 分词器
- SpringBoot
ElasticSearch 简介
ES 是一个使用Java语言并且基于Lucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于Restful风格的WEB接口,官方客户端也对多种语言都提供了相应的API。
Lucene:Lucene本身就是一个搜索引擎的底层
分布式:ES主要是为了突出他的横向扩展能力。
全文检索:将一段词语进行分词,并且将分出来的单个词语统一放到一个分词库中,在搜索时,根据关键字去分词库中检查,找到匹配的内容。(倒排索引)
Restful 风格的WEB接口:操作ES很简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数,执行相应的功能。
应用广泛:Github, wiki, gold man 用ES每天维护将近10TB的数据。
ES 结构

索引
ES的服务中,可以创建多个索引,每个索引默认被分成5个分片存储(提高查询效率、存储容量),每个分片至少有一个备份分片
备份分片默认不会分担查询效率,当ES检索压力特别大的时候,备份分片才会帮助检索数据
备份的分片必须放在不同的服务器中(集群)

类型
索引可以分多个分版 ,每个分片中有多个type,ES版本不同,类型的创建也不同
7.x 默认不再支持自定投索引类型(默认类型为_doc)

文档
一个type又可以分多个 document 文档 (一个个文档,相当于RDB中的一行行数据),每个文档中有多个field属性
一个MySQL有多个数据库,一个库中有多个表,一张表中存放着多行数据,每行数据中分多个列

列
一个文档包括多个属性,相当于RDB中的字段

ES和Slor
Slor 在查询死数据时(不能改变的数据,不增加、不减少),速度相对ES更快一些。但是数据如果是实时改变时,Solr的查询速度会降低很多,ES的查询效率基本没有变化。
Solr搭建集群时,需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入
Solr针对国内的中文文档不多,ES社区火爆,文档健全
ES 对现在云计算和大数据支持特别好
倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
当用户去查询数据时,会将用户的查询关键字进行分词
然后去分词库中匹配内容,最终得到数据的ID标识
根据ID标识去存放数据的位置拉取到指定的数据
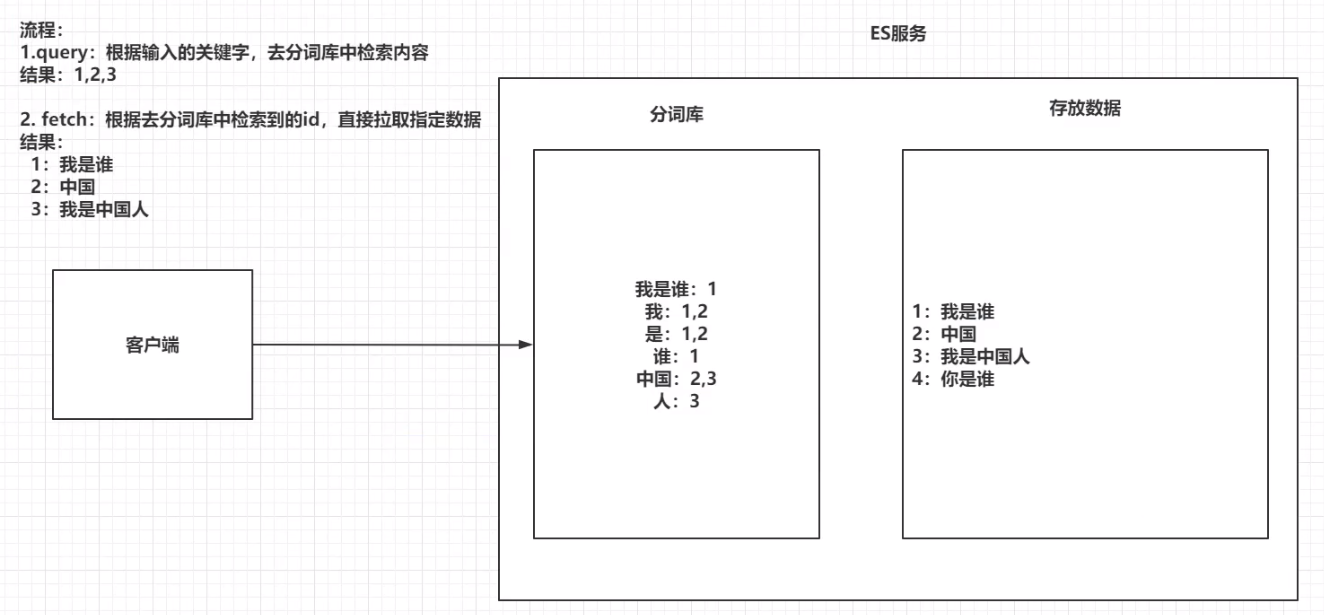
全文检索流程

- 创建ES索引、设置需要分词查询的 field
- 可以通过 canal 对 MySQL binlog 进行数据同步,或者 flink 或者 SpringBoot 直接往ES里添加数据
- 根据业务需求,通过 SpringBoot 进行查询