
一次排查某某云上的redis读超时经历
一次排查某某云上的redis读超时经历
问题背景
最近一两天线上老是偶现的redis读超时报警,我嗅到了一丝不正常的味道,但由于业务繁忙,只是暂时将超时时间从200ms调制500ms,超时情况减少了,不过还是有发生。趁业务空闲期,于是开始着手排查。
排查思路
查阅 redis 慢查询日志
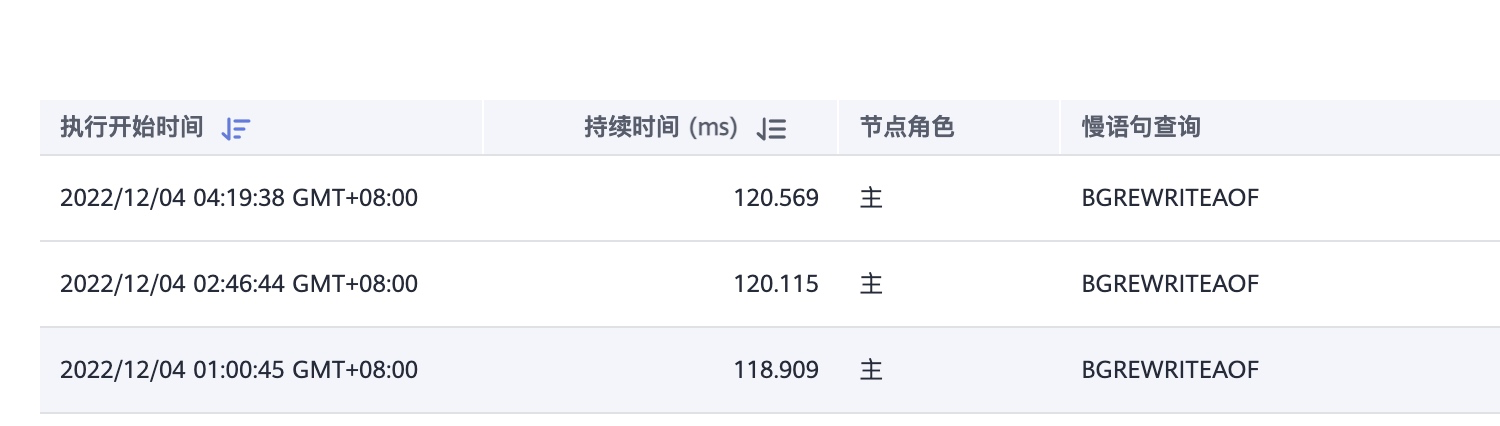
redis的慢查询阀值是10ms,唯一的慢查询是备份时的bgrewriteaof语句,慢查询很正常。
检查 报警期间 redis 各项负载指标
由于超时报警时,刚好也是我们业务低峰期,看了下各项监控指标,cpu,内存,qps等等,毫无意外的正常。
检查报警期间 ecs服务器的各项指标数据
cpu,内存,带宽等等也是正常且处于较低水平。
排查到这里,重新思考慢查询日志究竟是什么?
慢查询记录的真的是redis命令执行的所有时间吗?redis命令完整的执行过程究竟是怎样的?
慢查询日志仅仅是记录了命令的执行时间,而整个redis命令的生命周期是这样。
客户端命令发送->redis服务器接收到命令,放入队列排队执行->命令执行->返回给客户端结果
那么有没有办法监控到redis的延迟呢?如何才能知道redis的命令慢不是因为执行慢,而是这个过程当中的其他流程慢导致的呢?
redis 提供了监控延迟的工具
开启延迟,设置延迟阀值
CONFIG SET latency-monitor-threshold 100
查阅延迟原因
latency latest
但是这个工具真正实践起来的效果并不能让我满意,因为似乎他并不能把网络因素考虑其中,实践起来的效果它应该是只能将命令执行过程中可能导致延迟的原因分析出来,但是执行前以及执行后的命令生命周期的阶段并没有考虑进去。
当我开启这个工具监控线上redis情况,当又有读超时出现时,latency latest 并没有返回任何延迟异常。
再思考究竟读超时是个什么问题?
客户端发出去了命令,然后阻塞等待redis服务端读的结果,如果没有结果返回,就会触发读超时发生。在go里面代码是如何实现的。
func (c *baseClient) pipelineProcessCmds(cn *pool.Conn, cmds []Cmder) (bool, error) {
err := cn.WithWriter(c.opt.WriteTimeout, func(wr *proto.Writer) error {
return writeCmd(wr, cmds...)
})
if err != nil {
setCmdsErr(cmds, err)
return true, err
}
// 看到将读取操作用WithReader装饰了一下
err = cn.WithReader(c.opt.ReadTimeout, func(rd *proto.Reader) error {
return pipelineReadCmds(rd, cmds)
})
return true, err
}
// 读取之前设置了超时时间
_ = cn.setReadTimeout(timeout)
return fn(cn.rd)
可以看到,如果在规定时间内,结果没有全部返回也会导致读超时的发生,那么会不会是由于返回结果过多导致读取耗时验证呢?
具体的分析了下报警出错的命令,有些命令比如set命令不需要返回结果都有超时的情况,所以排除掉了返回结果过大的问题。
再次深入思考golang 里的读超时触发过程
go协程在碰到网络读取时,协程会挂起,等待网络包到达后,由go runtime唤醒,继续处理,当唤醒时会检查超时时间,如果到达了超时限制,那么将直接报读超时。(这部分可看源码自行验证)
从唤醒到协程被调度执行的这个时间称为协程的调度延迟,如果这个延迟过高,那么是有可能发生读超时的。
如何验证?
线上用了一个即使看最多最近15min的go协程调度延迟的工具包,github.com/arl/statsviz 可看15分钟前的go进程cpu,内存,协程调度延迟,gc stw造成的延迟时间。
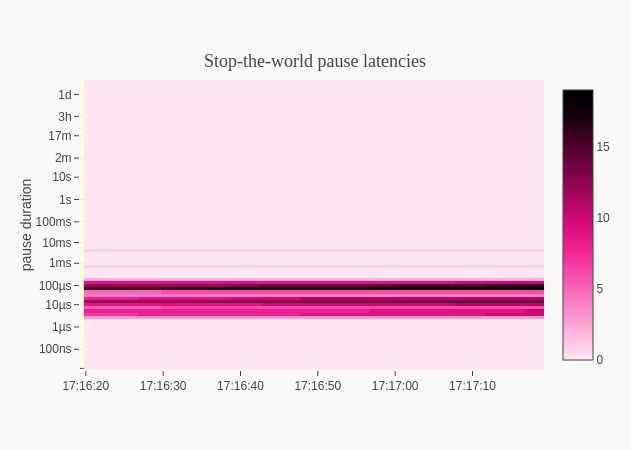
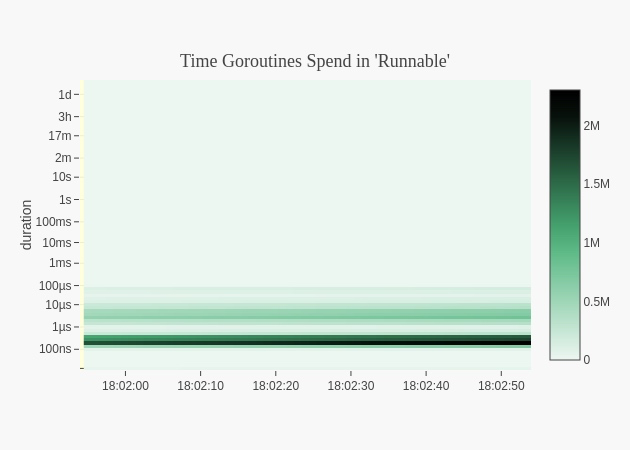 当超时发生时,我看了延迟时间,都在几ms以内,比起超时设定的500ms,远远没有达到,显然也不是程序协程调度延迟导致的。
当超时发生时,我看了延迟时间,都在几ms以内,比起超时设定的500ms,远远没有达到,显然也不是程序协程调度延迟导致的。
用上终极武器-抓包
以上的思路都行不通了,所以最后我抓包了,为了看看超时究竟是哪些包没有到达。
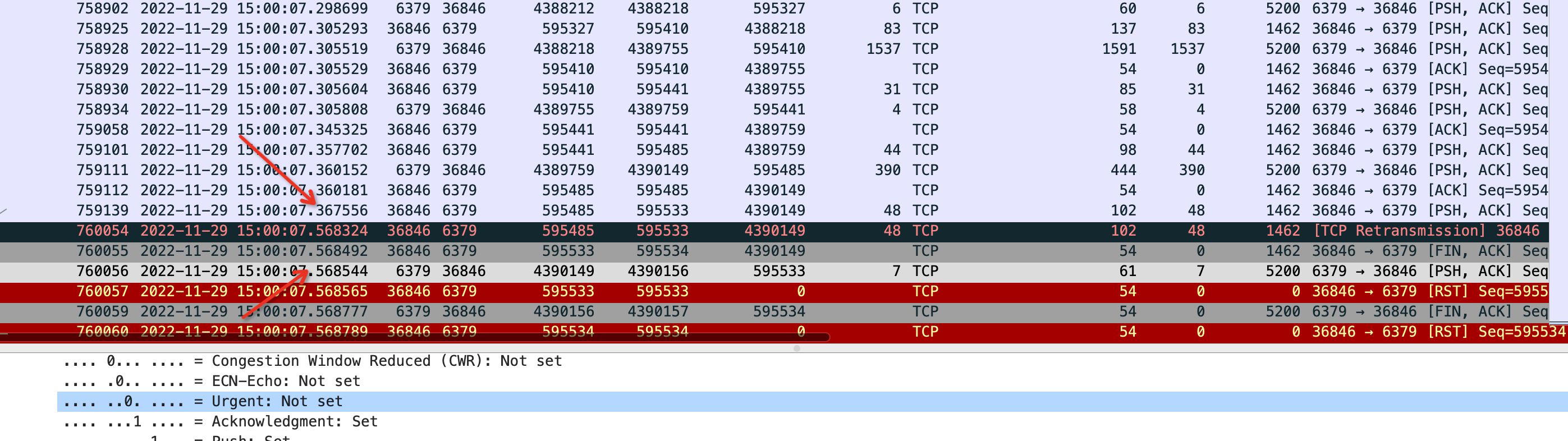
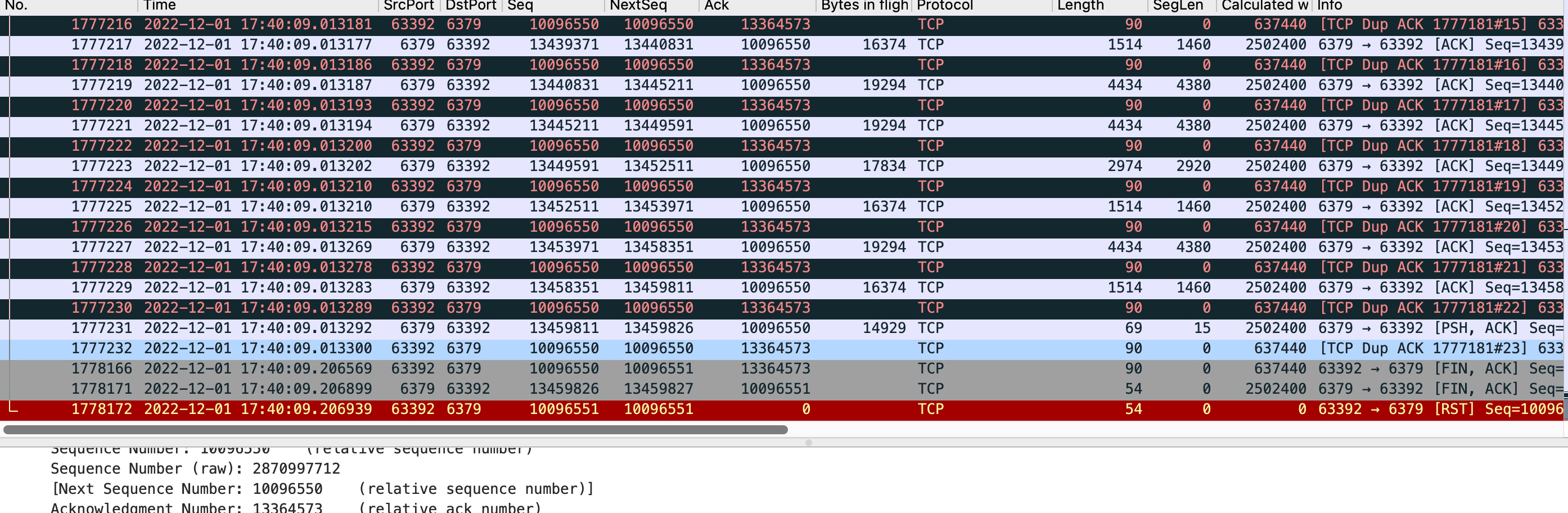
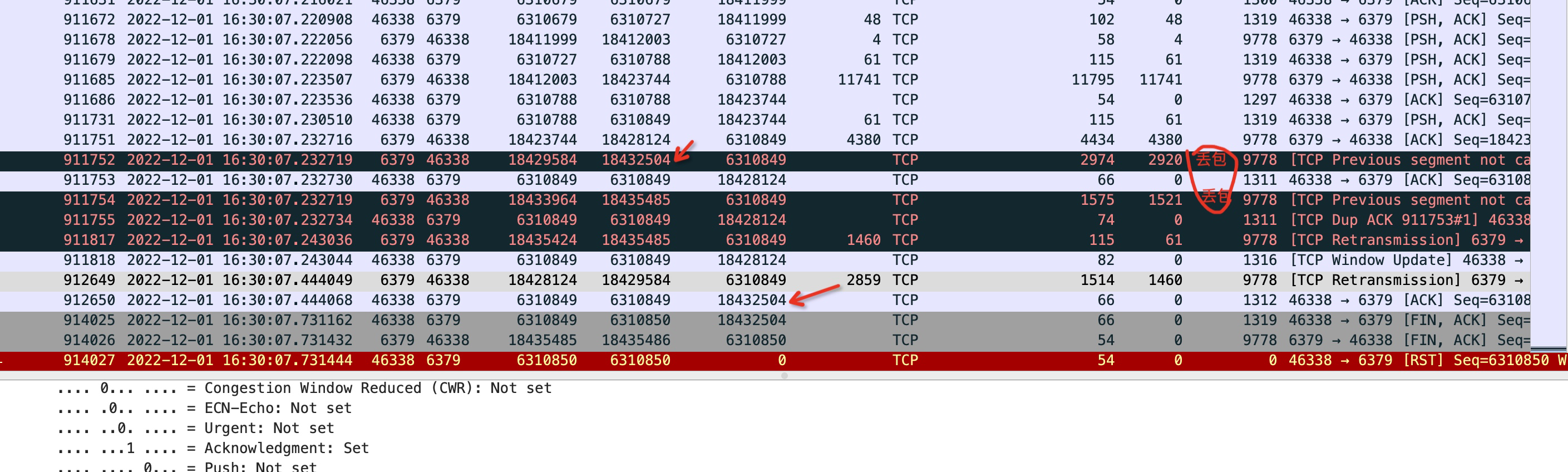
看到现在,我有了充足的理由相信,是云服务提供商那边的问题,中间由于网络丢包的原因,且延迟较大导致了redis的读超时。拿着这些证据也说服了他们,并最终圆满解决。
提工单,云服务商的排查支持
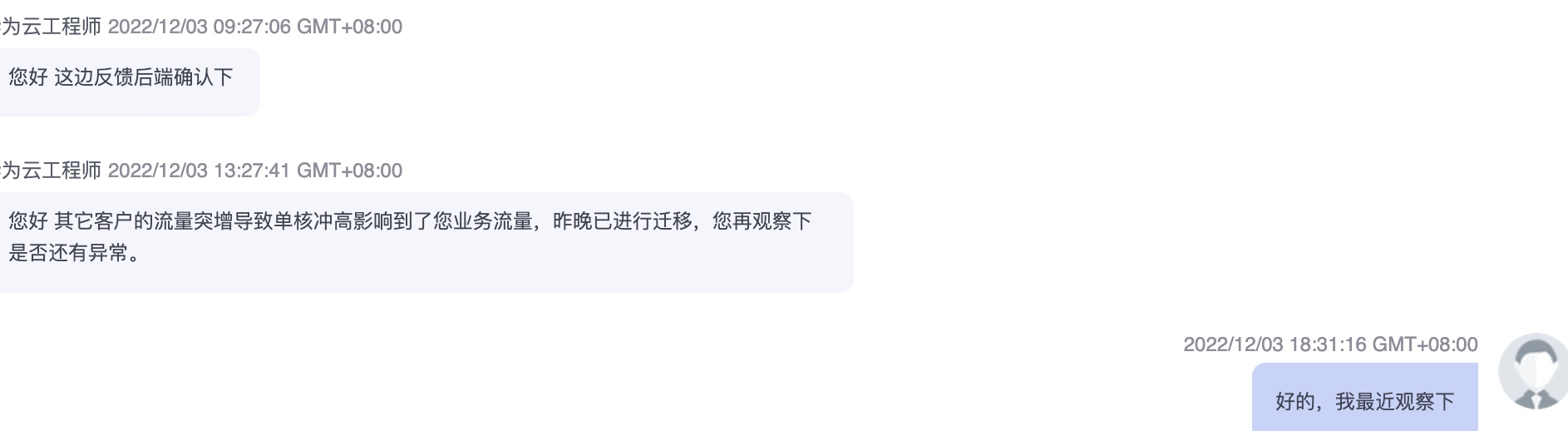
圆满解决