
一文了解清楚kafka消息丢失问题和解决方案
前言
今天分享一下kafka的消息丢失问题,kafka的消息丢失是一个很值得关注的问题,根据消息的重要性,消息丢失的严重性也会进行放大,如何从最大程度上保证消息不丢失,要从生产者,消费者,broker几个端来说。
消息发送和接收流程
kafka生产者生产好消息后,会将消息发送到broker节点,broker对数据进行存储,kafka的消息是顺序存储在磁盘上,以主题(topic),分区(partition)的逻辑进行划分,消息最终存储在日志文件中,消费者会循环从broker拉取消息。
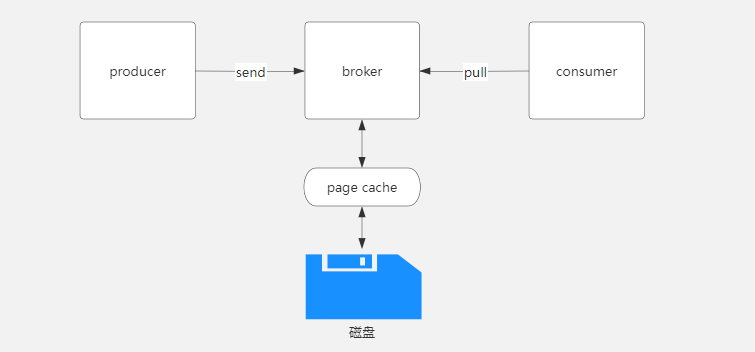
那么从上图的图中可以看出kafka丢消息可能存在的三个地方分别为:
- 生产者到broker
- broker到磁盘
- 消费者
生产者到broker消息丢失
生产者发送消息到broker是会存在消息丢失的,大多可能是由于网络原因引起的,消息中间件中一般都是通过ack来解决这个问题的,kafka中可以通过设置ack来解决这个问题。
acks有三种类型:
- 0
- 1
- -1(all)
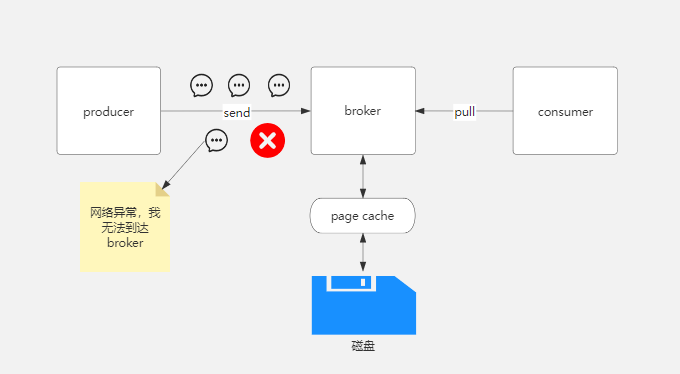
acks为0
acks设置为0,代表生产者发送消息后就不管不顾了,不用等待broker的任何响应,那么可能网络异常或者其他原因导致broker没有处理到到这条消息,那么消息就丢失了。
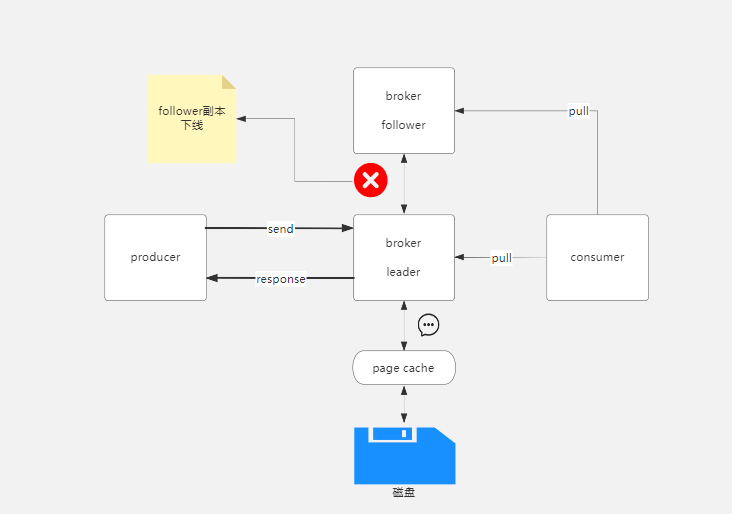
acks为1
acks设置为1,代表生产者发送消息到broker后,只需要broker的leader副本确认收到后就成功响应,不需要follower副本响应,就算follower副本崩溃了,也会成功响应。
acks为-1(all)
acks设置为-1,或者为all,那么生产者发送消息需要leader和follower都收到并写入消息才成功响应生产者,也就是ISR集合要全部写入,当ISR集合中只要有一个没有写入成功,那么就收到失败响应,所以acks=-1能够在最大程度上保证消息的不丢失,但是也是有条件的,需要ISR集合中有两个以上副本才能保证,如果只有一个副本,那么就是就只有一个leader,没有follower,如果leader挂掉,就不能选举出一个eader,消息自然也就丢失,这和acks=1是一样的。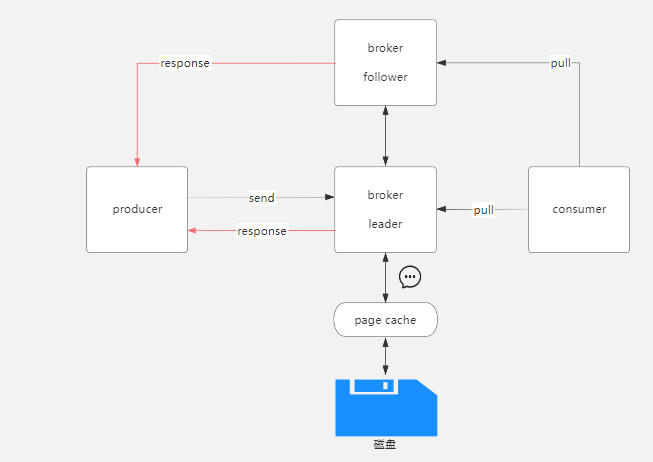
解决消息丢失
从上面三种类型的acks中我们可以看出,acks=-1是保证消息从生产者到broker不丢失的最佳设置方式,不过我们也能想到,它需要ISR每个副本都成功应答,所以它的效率自然没有前面两个高,不过此篇我们讨论的是保证消息不丢失问题,所以一切从不丢失层面区说。
如果消息发送失败,那么生产者可以重试发送消息,可以手动在代码中编写消息重发逻辑,也可以配置重试参数。
- retries
- retry.backoff.ms
retries表示重试次数,retry.backoff.ms表示重试时间间隔,比如第一次重试依旧没成功,那么隔多久再进行重试,kafka重试的底层逻辑是将没发送成功的消息重新入队,因为kafka的生产者生产消息后,消息并非就直接发送到broker,而是保存在生产者端的收集器(RecordAccumulator),然后由Sender线程去获取RecordAccumulator中的消息,然后再发送给broker,当消息发送失败后,会将消息重新放入RecordAccumulator中,具体逻辑可以看kafka的生产者端Sender的源码。

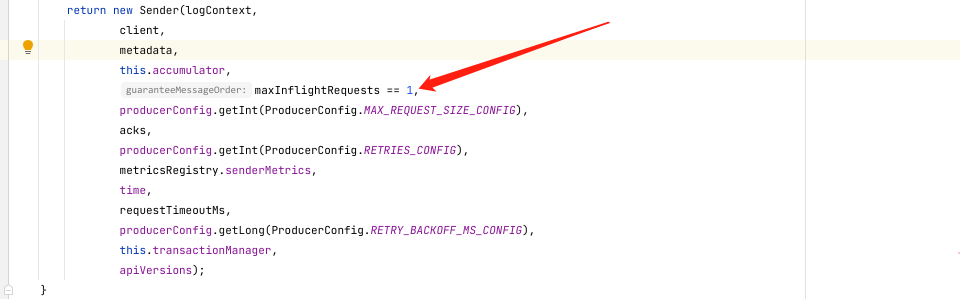
消息重发引起的消息顺序性问题
要注意,消息发送失败进行重发不能保证消息发送的顺序性,这里的顺序性是单分区顺序性,如果服务对于消息的顺序性有严格的要求,那么我们可以通过设置属性max.in.flight.requests.per.connection=1来保证消息的顺序性,这个配置对应的是kafka中InFlightRequests,max.in.flight.requests.per.connection代表请求的个数,kafka在创建Sender的时候会判断,如果maxInflightRequests为1,那么guaranteeMessageOrder就为true,就能保证消息的顺序性。
broker到磁盘丢消息
broker收到消息后,需要将消息写入磁盘的log文件中,但是并不是马上写,因为我们知道,生产者发送消息后,消费者那边需要马上获取,如果broker要写入磁盘,那么消费者拉取消息,broker还要从log文件中获取消息,这显然是不合理的,所以kafka引入了(page cache)页缓存。
page cache是磁盘和broker之间的消息映射关系,它是基于内存的,当broker收到消息后,会将消息写入page cache,然后由操作系统进行刷盘,将page cache中的数据写入磁盘。
如果broker发生故障,那么此时page cache的数据就会丢失,broker端可以设置刷盘的参数,比如多久刷盘一次,不过这个参数不建议去修改,最好的方案还是设置多副本,一个分区设置几个副本,当broker故障的时候,如果还有其他副本,那么数据就不会丢失。
消费者丢消息
kafka的消费模式是拉模式,需要不断地向broker拉取消息,拉取的消息消费了以后需要提交offset,也就是提交offset这里可能会出现丢消息,kafka中提供了和offset相关的几个配置项。
- enable.auto.commit
- auto.commit.interval.ms
- auto.offset.reset
下面我们先了解一下kafka offset的提交和参数详解。
enable.auto.commit代表是否自动提交offset,默认为true,auto.commit.interval.ms代表多久提交一次offset,默认为5秒。
如下图,当前消费者消费到了分区中为3的消息。
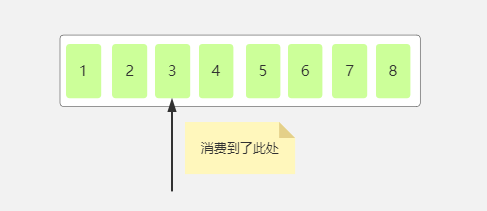
那么下次当消费者读取消息的时候是从哪里读取呢,当然从4开始读取,因为是从上次读取的offset的下一位开始读取,所以我们就说当前消费组的offset为4,,因为下次是从4开始消费,如果5秒之内又消费了两条消息然后自动提交了offset,那么此时的offset如下:
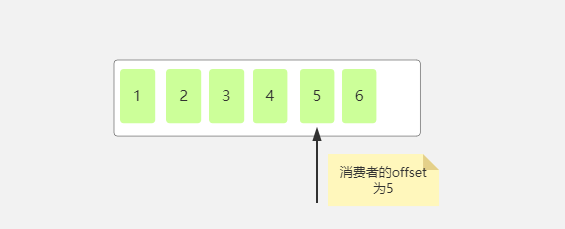
enable.auto.commit如果为false,就代表不会自动提交offset。
auto.offset.reset=latest代表从分区中最新的offset处开始读取消息,比如某个消费者组上次提交的偏移量为5,然后后面又生产了2条消息,再次读取消息时,读取到的是6,7,8这个三个消息,如果enable.auto.commit设置为false,那么不管往分区中写入多少消息,都是从6开始读取消息。
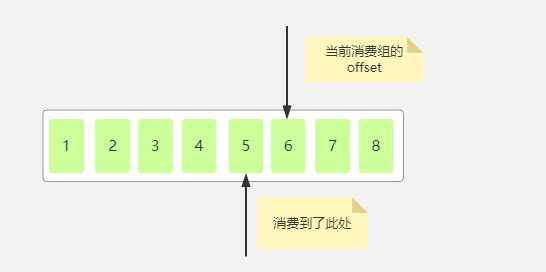
此时如果一个新的的消费组订阅了这个分区,因为这个消费者组没有在这个分区提交过offset,所以它获取消息并不是从6开始获取,而是从1开始获取。
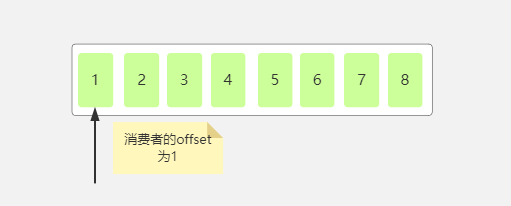
所以可知每个消费者组在分区中的offset是独立的。
auto.offset.reset还可以设置为earliest和none,使用earliest,如果此消费组从来没有提交过offset,那么就从头开始消费,如果提交过offset,那么就从最新的offset处消费,就和latest一样了,使用none,如果消费组没有提交过offset,在分区中找不到任何offset,那么就会抛出异常。
org.apache.kafka.clients.consumer.NoOffsetForPartitionException: Undefined offset with no reset policy for partitions: [stock1-0]
上面我们初步了解了offset的一些知识,对offset的提交和和读取有一些了解,因为上面我们只提及offset的自动提交,而自动提交的主动权在kafka,而不在我们,所以可能因为一些原因而导致消息丢失。
消息处理异常
当我们收到消息后对消息进行处理,如果在处理的过程中发生异常,而又设置为自动提交offset,那么消息没有处理成功,offset已经提交了,当下次获取消息的时候,由于已经提交过ofset,所以之前的消息就获取不到了,所以应该改为手动提交offset,当消息处理成功后,再进行手动提交offset。
总结
关于kafka的消息丢失问题和解决方案就说到这里,我们分别从生产者到broker,broker到磁盘以及消费者端进行说明,也引申出一些知识点,可能平时没有遇到消息丢失的情况,那是因为网络比较可靠,数据量可能不大,但是如果要真的实现高可用,高可靠,那么就需要对其进行设计。
今天的分享就到这里,感谢你的观看,我们下期见,如果文中有说得不合理或者不正确的地方,希望你能进行指点
