
python-爬虫-css提取-写入csv-爬取猫眼电影榜单
猫眼有一个电影榜单top100,我们将他的榜单电影数据(电影名、主演、上映时间、豆瓣评分)抓下来保存到本地的excle中
本案例使用css方式提取页面数据,所以会用到以下库
import time import requests import parsel 解析库,解析css import csv 爬取的数据写入csv
创建csv文件标头信息,也就是表格第一排内容
f = open('book.csv',mode='a',encoding='utf-8',newline='') 表头 csv_writer = csv.DictWriter(f,fieldnames=['电影名字','主演','上映时间','评分']) csv_writer.writeheader()

分析地址,每一页地址的区别在最后一个“=”号后面的数字,第一页是“10“,第二页是”20“,以此类推到”90“,所以写个循环翻页
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset=10
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset=20
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset=90
for page in range(0,10): time.sleep(2) page = page *10 url = 'https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset={}'.format(page) print(url)
分析页面,找到需要的数据
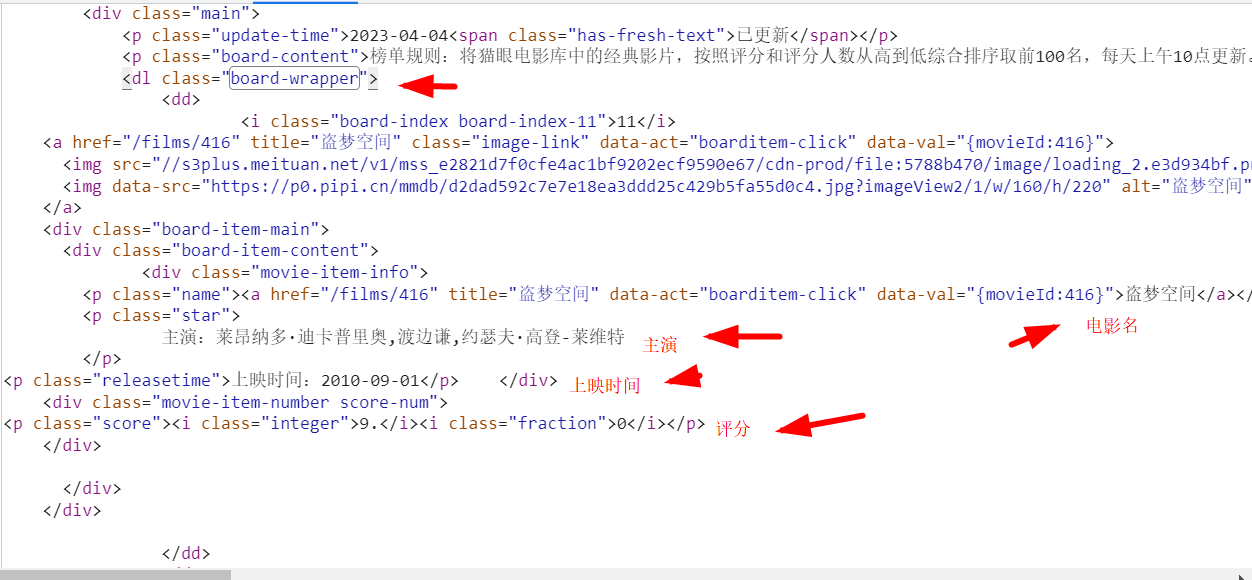
提取数据脚本如下
response = requests.get(url, headers=headers) selector = parsel.Selector(response.text) li_s = selector.css('.board-wrapper dd') for li in li_s: name = li.css('.name a::text').get() 电影名称 star = li.css('.star::text').get() 主演 star_string = star.strip() strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列 releasetime = li.css('.releasetime::text').get() 上映时间 data_time = releasetime.strip() follow = li.css('.score i::text').getall() score = ''.join(follow) join函数将列表内的值连串显示,参考“https://blog.csdn.net/weixin_50853979/article/details/125119368”
最后将获取到的数据字典化后存到csv文件中
dit = { '电影名字': name, '主演': star_string, '上映时间': data_time, '评分': score, } csv_writer.writerow(dit)
执行后csv文件的内容

全部代码
import time import requests import parsel 解析库,解析css import csv 爬取的数据写入csv f = open('book.csv',mode='a',encoding='utf-8',newline='') 表头 csv_writer = csv.DictWriter(f,fieldnames=['电影名字','主演','上映时间','评分']) csv_writer.writeheader() for page in range(0,10): time.sleep(2) page = page *10 url = 'https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset={}'.format(page) print(url) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36', 'Cookie': '__mta=20345351.1670903159717.1670903413872.1670903436333.5; uuid_n_v=v1; uuid=A8065B807A9811ED82C293D7E110319C9B09821067E1411AB6F4EC82889E1869; _csrf=916b8446658bd722f56f2c092eaae35ea3cd3689ef950542e202b39ddfe7c91e; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1670903160; _lxsdk_cuid=1850996db5dc8-07670e36da28-26021151-1fa400-1850996db5d67; _lxsdk=A8065B807A9811ED82C293D7E110319C9B09821067E1411AB6F4EC82889E1869; __mta=213622443.1670903327420.1670903417327.1670903424017.4; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1670903436; _lxsdk_s=1850996db5e-8b2-284-88a%7C%7C18', 'Host': 'www.maoyan.com', 'Referer': 'https://www.maoyan.com/films/1200486' } response = requests.get(url, headers=headers) selector = parsel.Selector(response.text) li_s = selector.css('.board-wrapper dd') for li in li_s: name = li.css('.name a::text').get() 电影名称 star = li.css('.star::text').get() 主演 star_string = star.strip() strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列 releasetime = li.css('.releasetime::text').get() 上映时间 data_time = releasetime.strip() follow = li.css('.score i::text').getall() score = ''.join(follow) join函数将列表内的值连串显示,参考“https://blog.csdn.net/weixin_50853979/article/details/125119368” dit = { '电影名字': name, '主演': star_string, '上映时间': data_time, '评分': score, } csv_writer.writerow(dit)