
基于深度强化学习(DQN)的迷宫寻路算法
QLearning方法有着明显的局限性,当状态和动作空间是离散的且维数不高时可使用Q-Table存储每个状态动作的Q值,而当状态和动作时高维连续时,该方法便不太适用。可以将Q-Table的更新问题变成一个函数拟合问题,通过更新参数θ使得Q函数逼近最优Q值。DL是解决参数学习的有效方法,可以通过引进DL来解决强化学习RL中拟合Q值函数问题,但是要先解决一系列问题:
- DL需要大量带标签的样本进行监督学习,但RL只有reward返回值
- DL样本独立,但RL前后State状态有关
- DL目标分布固定,但RL的分布一直变化
- 使用非线性网络表示值函数时会不稳定
QLearning实现:https://www.cnblogs.com/N3ptune/p/17341434.html
Deep Q-Network
此处将使用DQN来解决上述问题,其算法流程包括:
- 首先初始化深度神经网络,它将作为 Q 函数的近似值函数
- 初始化经验回放缓冲区,用于存储智能体的经验,其中包括状态、动作、奖励、下一状态等信息
- 智能体在环境中采取行动,根据行动获得奖励,得到下一个状态,并将这些经验添加到经验回放缓冲区中
- 从经验回放缓冲区中采样一批经验,用于训练神经网络
- 根据神经网络计算每个动作的 Q 值
- 选择一个动作,可以使用 ε-greedy 策略或者 softmax 策略等
- 根据选择的动作与环境互动,得到奖励和下一个状态,将经验添加到经验回放缓冲区中
- 使用经验回放缓冲区中的数据对神经网络进行训练,目标是最小化 Q 值函数的平均误差
- 将神经网络中的参数复制到目标网络中,每隔一段时间更新目标网络,以提高稳定性和收敛性
- 重复执行步骤3-9,直到达到指定的训练轮数或者 Q 值函数收敛
此处要说明的是,DQN要使用Reward来构造标签,通过经验回放来解决相关性以及非静态分布问题,使用一个CNN(Policy-Net)产生当前Q值,使用另外一个CNN(Target-Net)产生Target Q值
在本问题中,动作空间依然是上下左右四个方向,以整个迷宫为状态,用0来标记道路、-1表示障碍、1表示起点和终点,2表示已经走过的路径
损失函数
Q的目标值:
Q的预测值:
因此损失函数为:
经验回放
经验回放机制,不断地将智能体与环境交互产生的经验存储到一个经验池中,然后从这个经验池中随机抽取一定数量的经验,用于训练神经网络,避免了数据的相关性和非静态分布性。
经验回放机制的优点在于可以将不同时间点收集到的经验混合在一起,使得训练的样本具有更大的多样性,避免了训练样本的相关性,从而提高了训练的稳定性和效率。此外,经验回放机制还可以减少因为样本分布的改变而造成的训练不稳定问题。
在DQN中,经验回放机制的具体实现方式是将智能体与环境的交互序列(state, action, reward, next state)存储在一个经验池中,当神经网络进行训练时,从经验池中随机抽取一定数量的经验序列,用于训练网络。这种方法可以减少数据的相关性,同时还可以重复利用之前的经验,提高数据的利用率。
代码实现
首先实现一个神经网络,如上述分析,该网络用于拟合Q函数,接收一个状态作为输入,然后在其隐藏层中执行一系列非线性转换,最终输出状态下所有可能动作的Q值。这些Q值可以被用来选择下一步要执行的动作。
# Deep Q Network
class DQNet(nn.Module):
def __init__(self):
super(DQNet,self).__init__()
self.conv1 = nn.Conv2d(1,32,kernel_size=3,stride=1,padding=1)
self.conv2 = nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1)
self.fc1 = nn.Linear(64*8*8,256)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(256,4)
def forward(self,x):
x = x.view(-1,1,8,8)
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(-1,64*8*8)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
定义经验回放缓冲
class ReplayBuffer:
# 初始化缓冲区
def __init__(self,capacity):
self.capacity = capacity
self.buffer = []
# 将一条经验数据添加到缓冲区中
def push(self,state,action,reward,next_state,done):
if len(self.buffer) >= self.capacity:
self.buffer.pop(0)
self.buffer.append((state,action,reward,next_state,done))
# 随机从缓冲区抽取batch_size大小的经验数据
def sample(self,batch_size):
states,actions,rewards,next_states,dones = zip(*random.sample(self.buffer,batch_size))
return states,actions,rewards,next_states,dones
def __len__(self):
return len(self.buffer)
定义智能体:
class DQNAgent:
def __init__(self,state_size,action_size):
self.state_size = state_size # 状态空间
self.action_size = action_size # 动作空间
self.q_net = DQNet() # 估计动作价值 神经网络
self.target_q_net = DQNet() # 计算目标值 神经网络
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.optimizer = optim.Adam(self.q_net.parameters(),lr=0.001) # 初始化Adam优化器
self.memory = ReplayBuffer(capacity=10000) # 经验回放缓冲区
self.gamma = 0.99 # 折扣因子
self.epsilon = 1.0 # 探索率
self.epsilon_decay = 0.99995 # 衰减因子
self.epsilon_min = 0.01 # 探索率最小值
self.batch_size = 64 # 经验回放每个批次大小
self.update_rate = 200 # 网络更新频率
self.steps = 0 # 总步数
# 探索策略 在给定状态下采取动作
def get_action(self,state):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size) # 随机选择动作
state = torch.from_numpy(state).float().unsqueeze(0)
q_values = self.q_net(state)
return torch.argmax(q_values,dim=1).item()
# 将状态转移元组存储到经验回放缓冲区
def remember(self,state,action,reward,next_state,done):
self.memory.push(state,action,reward,next_state,done)
# 从经验回放缓冲区抽取一个批次的转移样本
def relay(self):
if len(self.memory) < self.batch_size:
return
# 从回放经验中抽取数据
states,actions,rewards,next_states,dones = self.memory.sample(self.batch_size)
states = torch.from_numpy(np.array(states)).float()
actions = torch.from_numpy(np.array(actions)).long()
rewards = torch.from_numpy(np.array(rewards)).float()
next_states = torch.from_numpy(np.array(next_states)).float()
dones = torch.from_numpy(np.array(dones)).long()
q_targets = self.target_q_net(next_states).detach() # 计算下一状态Q值
q_targets[dones] = 0.0 # 对于已完成状态 将Q值设置为0
# 计算目标Q值
q_targets = rewards.unsqueeze(1) + self.gamma * torch.max(q_targets,dim=1)[0].unsqueeze(1)
q_expected = self.q_net(states).gather(1,actions.unsqueeze(1)) # 计算当前状态Q值
# 计算损失值
loss = F.mse_loss(q_expected,q_targets)
# 通过反向传播更新神经网络的参数
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.steps += 1
# 隔一定步数 更新目标网络
if self.steps % self.update_rate == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
# 更新epsilon值 使得探索时间衰减
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def train(self,env,episodes):
steps = []
for episode in range(episodes):
env.reset(complete=False)
step = 0
while True:
step += 1
action = self.get_action(env.state) # 获取动作
next_state,reward,done = env.step(action) # 执行动作
agent.remember(env.state,action,reward,next_state,done)
agent.relay()
env.state = next_state # 更新地图状态
if done or step > 200:
break
steps.append(step)
return steps
def test(self,env):
step = 0
while True:
step += 1
action = self.get_action(env.state)
next_state,reward,done = env.step(action)
env.state = next_state
if done or step > 1000:
break
def save(self,path):
torch.save(self.q_net.state_dict(),path+"/value_model.pt")
torch.save(self.target_q_net.state_dict(),path+"/target_model.pt")
def load(self,path):
self.q_net.load_state_dict(torch.load(path+"/value_model.pt"))
self.target_q_net.load_state_dict(torch.load(path+"/target_model.pt"))
在定义中,init函数用于初始化对象:
def __init__(self,state_size,action_size):
self.state_size = state_size # 状态空间
self.action_size = action_size # 动作空间
self.q_net = DQNet() # 估计动作价值 神经网络
self.target_q_net = DQNet() # 计算目标值 神经网络
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.optimizer = optim.Adam(self.q_net.parameters(),lr=0.001) # 初始化Adam优化器
self.memory = ReplayBuffer(capacity=10000) # 经验回放缓冲区
self.gamma = 0.99 # 折扣因子
self.epsilon = 1.0 # 探索率
self.epsilon_decay = 0.99995 # 衰减因子
self.epsilon_min = 0.01 # 探索率最小值
self.batch_size = 64 # 经验回放每个批次大小
self.update_rate = 200 # 网络更新频率
self.steps = 0 # 总步数
上述包含了一些DQN的重要参数
在智能体选取动作时,依然使用QL中的贪婪策略
# 探索策略 在给定状态下采取动作
def get_action(self,state):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size) # 随机选择动作
state = torch.from_numpy(state).float().unsqueeze(0)
q_values = self.q_net(state)
return torch.argmax(q_values,dim=1).item()
与QL不同的是,Q值由神经网络求得
下述函数用于将五元组存储到经验回放缓冲区
# 将状态转移元组存储到经验回放缓冲区
def remember(self,state,action,reward,next_state,done):
self.memory.push(state,action,reward,next_state,done)
经验回放:
# 从经验回放缓冲区抽取一个批次的转移样本
def relay(self):
if len(self.memory) < self.batch_size:
return
# 从回放经验中抽取数据
states,actions,rewards,next_states,dones = self.memory.sample(self.batch_size)
states = torch.from_numpy(np.array(states)).float()
actions = torch.from_numpy(np.array(actions)).long()
rewards = torch.from_numpy(np.array(rewards)).float()
next_states = torch.from_numpy(np.array(next_states)).float()
dones = torch.from_numpy(np.array(dones)).long()
q_targets = self.target_q_net(next_states).detach() # 计算下一状态Q值
q_targets[dones] = 0.0 # 对于已完成状态 将Q值设置为0
# 计算目标Q值
q_targets = rewards.unsqueeze(1) + self.gamma * torch.max(q_targets,dim=1)[0].unsqueeze(1)
q_expected = self.q_net(states).gather(1,actions.unsqueeze(1)) # 计算当前状态Q值
# 计算损失值
loss = F.mse_loss(q_expected,q_targets)
# 通过反向传播更新神经网络的参数
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.steps += 1
# 隔一定步数 更新目标网络
if self.steps % self.update_rate == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
# 更新epsilon值 使得探索时间衰减
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
在每个时间步,从经验回放池中随机选择一批先前观察到的状态和动作,然后计算它们的Q值。之后可以使用这些Q值来计算一个损失函数,该函数衡量当前的Q函数与理论上的Q函数之间的差距。最后使用反向传播算法来更新神经网络的权重,以最小化损失函数。
训练函数:
def train(self,env,episodes):
steps = []
for episode in range(episodes):
env.reset(complete=False)
step = 0
while True:
step += 1
action = self.get_action(env.state) # 获取动作
next_state,reward,done = env.step(action) # 执行动作
agent.remember(env.state,action,reward,next_state,done)
agent.relay()
env.state = next_state # 更新地图状态
if done or step > 200:
break
steps.append(step)
return steps
在该函数中会让智能体进行数次游戏,每次游戏开始时会重置状态,但不重置迷宫,并且设置一个阈值,让智能体步数达到这个值时终止游戏,否则智能体有概率不断滞留。在智能体每次选择动作并执行后,会将这次的状态和动作以及奖赏储存到经验池中,之后进行经验回放,训练网络。
定义环境
定义一个迷宫环境,和智能体进行交互:
class MazeEnv:
def __init__(self,size):
self.size = size
self.actions = [0,1,2,3]
self.maze,self.start,self.end = self.generate(size)
self.state = np.expand_dims(self.maze,axis=2).copy()
def reset(self,complete=False):
if complete:
# 重置迷宫
self.maze,self.start,self.end = self.generate(self.size)
self.state = np.expand_dims(self.maze,axis=2)
self.position = self.start
self.goal = self.end
self.path = [self.start]
return self.state
def step(self, action):
# 执行动作
next_position = None
if action == 0 and self.position[0] > 0:
next_position = (self.position[0]-1, self.position[1])
elif action == 1 and self.position[0] < self.size-1:
next_position = (self.position[0]+1, self.position[1])
elif action == 2 and self.position[1] > 0:
next_position = (self.position[0], self.position[1]-1)
elif action == 3 and self.position[1] < self.size-1:
next_position = (self.position[0], self.position[1]+1)
else:
next_position = self.position
if next_position == self.goal:
reward = 500
elif self.maze[next_position] == -1:
reward = -300
else:
reward = -10
self.position = next_position # 更新位置
self.path.append(self.position) # 加入路径
next_state = self.state.copy()
next_state[self.position] = 2 # 标记路径
done = (self.position == self.goal) # 判断是否结束
return next_state, reward, done
@staticmethod
# 生成迷宫图像
def generate(size):
maze = np.zeros((size, size))
# Start and end points
start = (random.randint(0, size-1), 0)
end = (random.randint(0, size-1), size-1)
maze[start] = 1
maze[end] = 1
# Generate maze walls
for i in range(size * size):
x, y = random.randint(0, size-1), random.randint(0, size-1)
if (x, y) == start or (x, y) == end:
continue
if random.random() < 0.2:
maze[x, y] = -1
if np.sum(np.abs(maze)) == size*size - 2:
break
return maze, start, end
@staticmethod
# BFS求出路径
def solve_maze(maze, start, end):
size = maze.shape[0]
visited = np.zeros((size, size))
solve = np.zeros((size,size))
queue = [start]
visited[start[0],start[1]] = 1
while queue:
x, y = queue.pop(0)
if (x, y) == end:
break
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] or maze[nx, ny] == -1:
continue
queue.append((nx, ny))
visited[nx, ny] = visited[x, y] + 1
if visited[end[0],end[1]] == 0:
return solve,[]
path = [end]
x, y = end
while (x, y) != start:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] != visited[x, y] - 1:
continue
path.append((nx, ny))
x, y = nx, ny
break
points = path[::-1] # 倒序
for point in points:
solve[point[0]][point[1]] = 1
return solve, points
模型训练
初始化,这里针对8*8迷宫
maze_size = 8
input_shape = (maze_size,maze_size,1)
num_actions = 4
agent = DQNAgent(input_shape,num_actions)
env = MazeEnv(maze_size)
定义一个函数,用于绘制迷宫:
from PIL import Image
def maze_to_image(maze, path):
size = maze.shape[0]
img = Image.new('RGB', (size, size), (255, 255, 255))
pixels = img.load()
for i in range(size):
for j in range(size):
if maze[i, j] == -1:
pixels[j, i] = (0, 0, 0)
elif maze[i, j] == 1:
pixels[j, i] = (0, 255, 0)
for x, y in path:
pixels[y, x] = (255, 0, 0)
return np.array(img)
执行训练:
for epoch in range(100):
steps = agent.train(env,50)
plt.imshow(maze_to_image(env.maze,[]))
plt.savefig(f"mazes/{epoch+1}.png") # 保存迷宫原始图像
plt.clf()
plt.plot(steps)
plt.xlabel('Episode')
plt.ylabel('Steps')
plt.title('Training Steps')
plt.savefig(f"train/{epoch+1}.png") # 保存训练图像
plt.clf()
solve = maze_to_image(env.maze,env.path)
plt.imshow(solve)
plt.savefig(f"solves/{epoch+1}.png") # 保存最后一次路线
plt.clf()
env.reset(complete=True) # 完全重置环境
agent.save("model")
抽取一些训练时的图片:
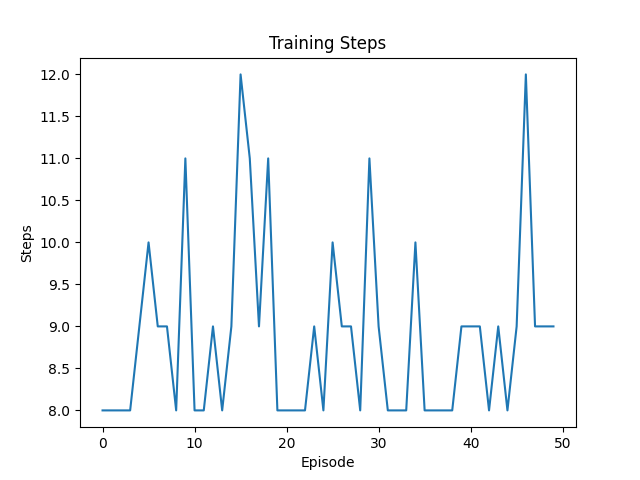
第1次训练:
迷宫图像:
最后一次路线图:
训练图像:
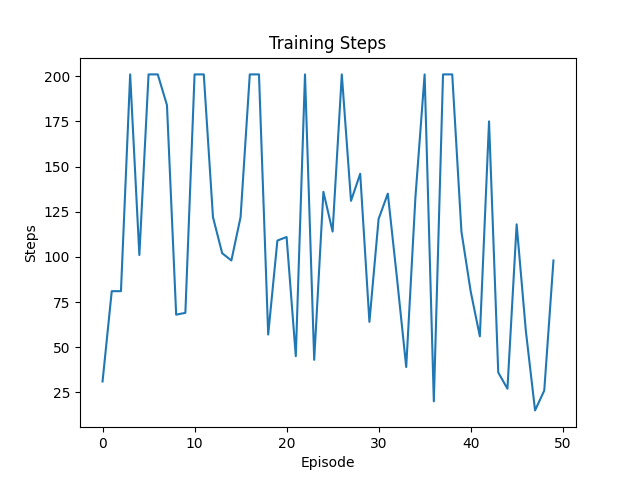
执行步数不稳定,有多次超出阈值
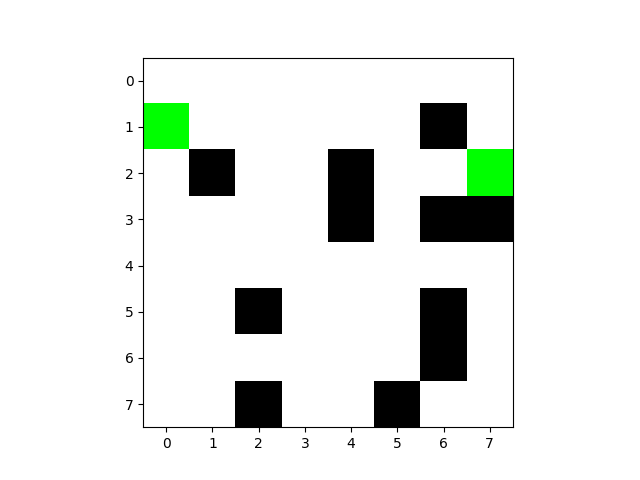
第10次:
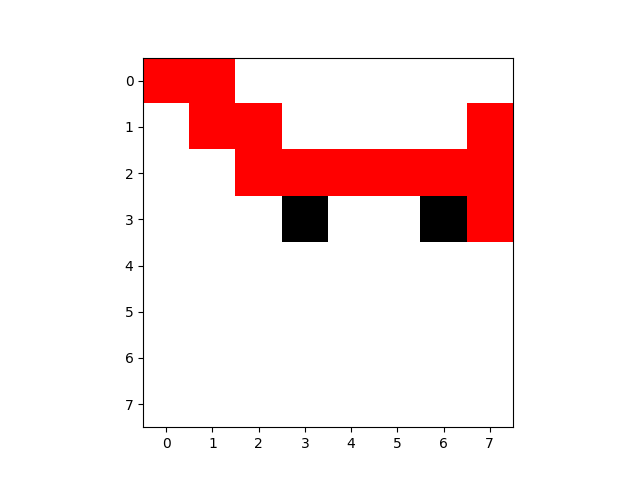
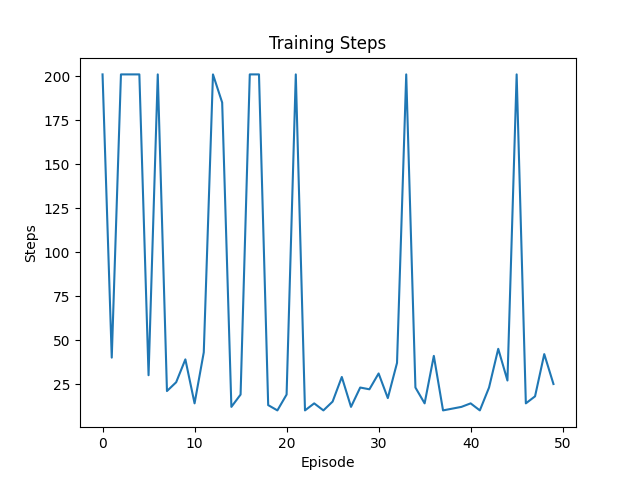
第50次:
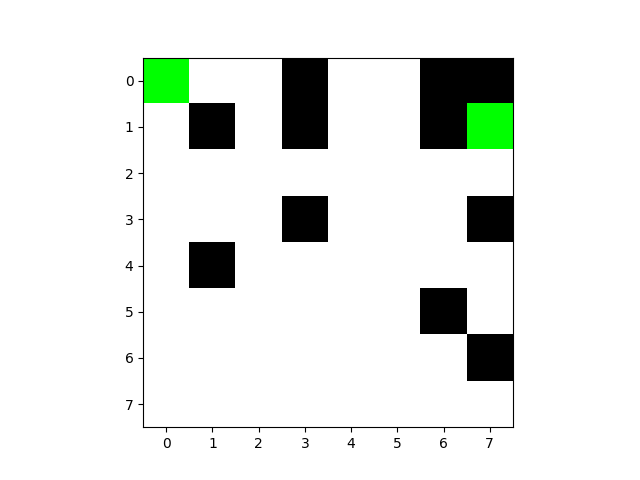
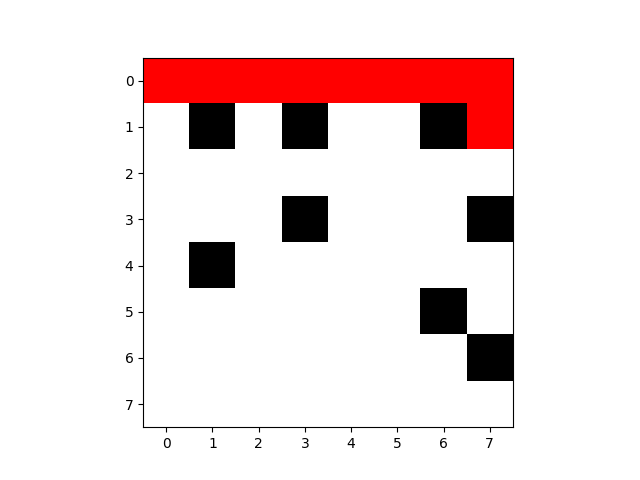
尽管效率很高,但依然触碰了障碍物
第100次:
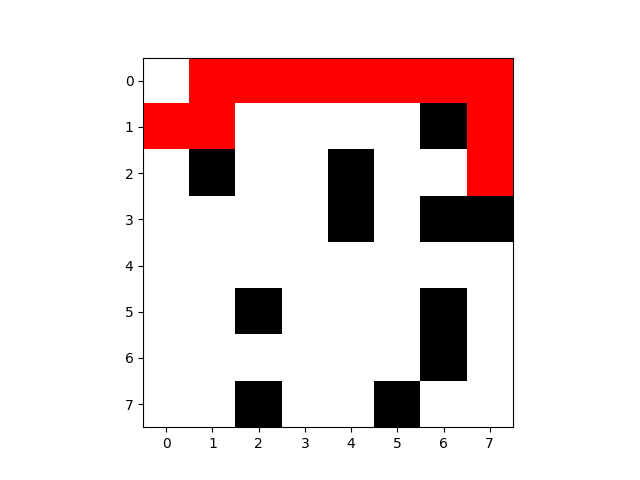
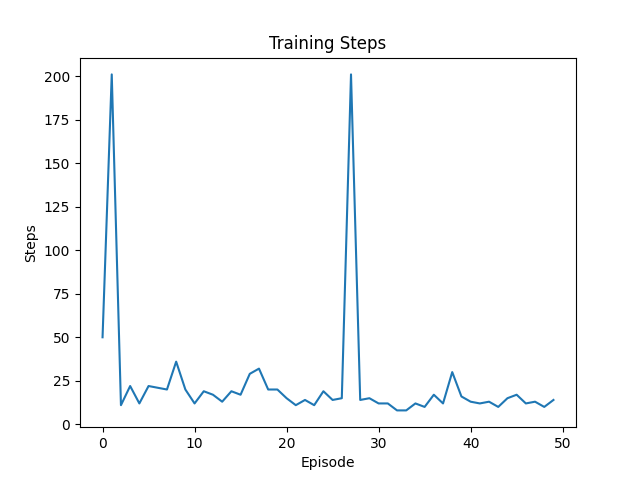
这次不仅没有触碰障碍物,并且非常接近最优解