
Prompt learning 教学[技巧篇]:通过增加示例、引导词、特殊符号指令等方式让chatgpt输出更好的答案
Prompt learning 教学[技巧篇]:通过增加示例、引导词、特殊符号指令等方式让chatgpt输出更好的答案
技巧1:To Do and Not To Do
在问答场景里,为了让 AI 回答更加准确,一般会在问题里加条件。比如让 AI 推荐一部电影给你 Recommend a movie to me 。但这个 prompt 太空泛了,AI 无法直接回答,接着它会问你想要什么类型的电影,但这样你就需要跟 AI 聊很多轮,效率比较低。
所以,为了提高效率,一般会在 prompt 里看到类似这样的话(意思是不要询问我对什么感兴趣,或者问我的个人信息):
DO NOT ASK FOR INTERESTS. DO NOT ASK FOR PERSONAL INFORMATION.
如果你在 ChatGPT 里这样提问,或者使用 ChatGPT 最新的 API ,它就不会问你问题,而是直接推荐一部电影给你,它的 Output 是这样的:
Certainly! If you're in the mood for an action-packed movie, you might enjoy "John Wick" (2014), directed by Chad Stahelski and starring Keanu Reeves. The movie follows a retired hitman named John Wick who seeks vengeance against the people who wronged him. It's a fast-paced and stylish film with lots of thrilling action sequences and an engaging story. If you're looking for something that will keep you on the edge of your seat, "John Wick" is definitely worth a watch!
但如果你使用的是如 Davinci-003 这样的模型,它的 Output 很可能是这样的,它还会问你的兴趣爱好:
Sure, I can recommend a movie based on your interests. What kind of movie would you like to watch? Do you prefer action, comedy, romance, or something else?
所以 OpenAI 的 API 最佳实践文档里,提到了一个这样的最佳实践:
Instead of just saying what not to do, say what to do instead. 与其告知模型不能干什么,不妨告诉模型能干什么。
我自己的实践是,虽然现在最新的模型已经理解什么是 Not Todo ,但如果你想要的是明确的答案,加入更多限定词,告知模型能干什么,回答的效率会更高,且预期会更明确。还是电影推荐这个案例,你可以加入一个限定词:
Recommend a movie from the top global trending movies to me.
当然并不是 Not Todo 就不能用,如果:
- 你已经告知模型很明确的点,然后你想缩小范围,那增加一些 Not Todo 会提高不少效率。
- 你是在做一些探索,比如你不知道如何做精准限定,你只知道不要什么。那可以先加入 Not Todo ,让 AI 先发散给你答案,当探索完成后,再去优化 prompt。
以下是一些场景案例,我整理了两个 Less Effective(不太有效的) 和 Better(更好的) prompt,你可以自己尝试下这些案例:
| 场景 | Less Effective | Better | 原因 |
|---|---|---|---|
| 推荐雅思必背英文单词 | Please suggest me some essential words for IELTS | Please suggest me 10 essential words for IELTS | 后者 prompt 会更加明确,前者会给大概 20 个单词。这个仍然有提升的空间,比如增加更多的限定词语,像字母 A 开头的词语。 |
| 推荐香港值得游玩的地方 | Please recommend me some places to visit in Hong Kong. Do not recommend museums. | Please recommend me some places to visit in Hong Kong including amusement parks. | 后者的推荐会更准确高效一些,但如果你想进行一些探索,那前者也能用。 |
技巧2:增加示例
直接告知 AI 什么能做,什么不能做外。在某些场景下,我们能比较简单地向 AI 描述出什么能做,什么不能做。但有些场景,有些需求很难通过文字指令传递给 AI,即使描述出来了,AI 也不能很好地理解。
比如给宠物起英文名,里面会夹杂着一些所谓的名字风格。此时你就可以在 prompt里增加一些例子,我们看看这个例子:
Suggest three names for a horse that is a superhero.
Output 是这样的,第一个感觉还行,第二个 Captain 有 hero 的感觉,但 Canter 就像是说这匹马跑得很慢,而且三个都比较一般,不够酷。
Thunder Hooves, Captain Canter, Mighty Gallop
此时你就可以在 prompt 里增加一些案例:
Suggest three names for an animal that is a superhero.
Animal: Cat
Names: Captain Sharpclaw, Agent Fluffball, The Incredible Feline
Animal: Dog
Names: Ruff the Protector, Wonder Canine, Sir Barks-a-Lot
Animal: Horse
Names:
增加例子后,输出的结果就更酷一些,或者说是我想要的那种风格的名字。
Gallop Guardian, Equine Avenger, The Mighty Stallion
以下是一些场景案例,我整理了两个 Less Effective(不太有效的) 和 Better(更好的) prompt,你可以自己尝试下这些案例:
| 场景 | Less Effective | Better | 原因 |
|---|---|---|---|
| 起英文名 | Suggest three English names for a boy. | Suggest three English names for a boy. Here are some examples: Jimmy、Jason、James |
可以在下方运行这个案例,在不给示例的情况下 AI 会给你什么答案。 |
| 将电影名称转为 emoji | Convert Star Wars into emoji. | Convert movie titles into emoji. Back to the Future: ???????? Batman: ???? Transformers: ???? Star Wars: |
可以在下方运行这个案例,在不给示例的情况下 AI 会给你什么答案。 |
技巧3:使用引导词,引导模型输出特定内容
在代码生成场景里,有一个小技巧,上面提到的案例,其 prompt 还可以继续优化,在 prompt 最后,增加一个代码的引导,告知 AI 我已经将条件描述完了,你可以写代码了。
Better:
Create a MySQL query for all students in the Computer Science Department:
Table departments, columns = [DepartmentId, DepartmentName]
Table students, columns = [DepartmentId, StudentId, StudentName]
SELECT
在 prompt 的最后增加 SELECT 可以很好地提示 AI 可以写 SQL 代码了。
同样的道理,如果你想让 AI 写 Python 代码,那 import 会是比较好的提示。但需要注意,这个只是告知 AI 可以写代码了,并不能告知 AI 写何种代码,你仍然需要在 prompt 里增加提示,告知 AI 要生成何种语言的代码。
在吴恩达的 ChatGPT Prompt Engineering 课程中,也提到这个技巧,只是在课程中,引导词并不是放在最后,而是在 prompt 里直接说明,让 AI 生成一个 JSON 格式的内容。课程中的例子是这样的(注意这个是 python 代码):
prompt = f"""
Generate a list of three made-up book titles along \
with their authors and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
"""
我简单解释下,其关键是在 prompt 里跟 AI 说明,需要 AI 按照 JSON 格式输出内容。
技巧4:增加 Role(角色)或人物
前面提到的改写例子,我在 prompt 里加了 Role 让其更易于阅读,这个优化方法是 OK 的。也很常用,比如你想将你写的 Email 改得更商务,则只需要加 business 相关的词即可。
我再介绍一个更有效的技巧,就是在 prompt 里增加一些 role(角色)相关的内容,让 AI 生成的内容更符合你的需求。
比如还是上面那个 rewrite 的例子,我在例子前加入这样的一段话,我让 AI 假设自己是一个小学老师,并且很擅长将复杂的内容转变成 7、8岁小朋友也能听懂的话,然后再改写这段话:
You are a primary school teacher who can explain complex content to a level that a 7 or 8 year old child can understand. Please rewrite the following sentences to make them easier to understand:
Output 就变成了下面这样。不管是用词,还是语法,看起来都更容易懂了。
OpenAI is a place where people work on making computers really smart. It's like a lab where they do research to make computers do amazing things! They want the computers to be really friendly and helpful to people. They use one of the most powerful computers in the world to do this research. A bunch of really rich and smart people gave money to start this lab. One of them is Elon Musk, but he left in 2018. Another really big company, Microsoft, gave them a lot of money too.
另外除了增加角色外,还能让 AI 模拟某个人,比如让 AI 以 David Foster Wallace 的风格改写上述那段话:
Imagine you are the famous writer David Foster Wallace, please rewrite this sentences.
Output 是这样的:
As David Foster Wallace, I might rewrite these sentences to sound more like this:
OpenAI is a lab that studies something called artificial intelligence, which is like when computers can do things that normally only humans can do. They have a big computer that's one of the most powerful in the world, and they're trying to make sure the AI they create is friendly and helpful. The lab was started in 2015 in a city called San Francisco, and a bunch of important people gave them a lot of money to do their research. One of those people was Elon Musk, who stopped working there but still gives them money, and Microsoft also gave them a lot of money recently.
关于这个技巧的应用,以及如何更好地使用 AI 提升写作能力,建议各位阅读 Nat Eliason 的 Using ChatGPT as a Writing Coach,他使用 ChatGPT 辅助其写作,就用到了上述的技巧。
技巧5:使用特殊符号指令和需要处理的文本分开
不管是信息总结,还是信息提取,你一定会输入大段文字,甚至多段文字,此时有个小技巧。
可以用“”“将指令和文本分开。根据我的测试,如果你的文本有多段,增加”“”会提升 AI 反馈的准确性(这个技巧来自于 OpenAI 的 API 最佳实践文档)
:::info
感谢 CraneHuang6 的提醒,这里还能用 ### 符号区隔,不过我一般会用“”“ ,因为我有的时候会用 # 作为格式示例,太多 # 的话 prompt 会看起来比较晕
:::
像我们之前写的 prompt 就属于 Less effective prompt。为什么呢?据我的测试,主要还是 AI 不知道什么是指令,什么是待处理的内容,用符号分隔开来会更利于 AI 区分。
Please summarize the following sentences to make them easier to understand.
OpenAI is an American artificial intelligence (AI) research laboratory consisting of the non-profit OpenAI Incorporated (OpenAI Inc.) and its for-profit subsidiary corporation OpenAI Limited Partnership (OpenAI LP). OpenAI conducts AI research with the declared intention of promoting and developing a friendly AI. OpenAI systems run on the fifth most powerful supercomputer in the world.[5][6][7] The organization was founded in San Francisco in 2015 by Sam Altman, Reid Hoffman, Jessica Livingston, Elon Musk, Ilya Sutskever, Peter Thiel and others,[8][1][9] who collectively pledged US$1 billion. Musk resigned from the board in 2018 but remained a donor. Microsoft provided OpenAI LP with a $1 billion investment in 2019 and a second multi-year investment in January 2023, reported to be $10 billion.[10]
Better prompt:
Please summarize the following sentences to make them easier to understand.
Text: """
OpenAI is an American artificial intelligence (AI) research laboratory consisting of the non-profit OpenAI Incorporated (OpenAI Inc.) and its for-profit subsidiary corporation OpenAI Limited Partnership (OpenAI LP). OpenAI conducts AI research with the declared intention of promoting and developing a friendly AI. OpenAI systems run on the fifth most powerful supercomputer in the world.[5][6][7] The organization was founded in San Francisco in 2015 by Sam Altman, Reid Hoffman, Jessica Livingston, Elon Musk, Ilya Sutskever, Peter Thiel and others,[8][1][9] who collectively pledged US$1 billion. Musk resigned from the board in 2018 but remained a donor. Microsoft provided OpenAI LP with a $1 billion investment in 2019 and a second multi-year investment in January 2023, reported to be $10 billion.[10]
"""
另外,在吴恩达的 ChatGPT Prompt Engineering 课程中,还提到,你可以使用其他特殊符号来分割文本和 prompt,比如<>,<tag></tag> 等,课程中的案例是这样的(注意这个是 python 代码,需要关注的是 prompt 里的 text):
text = f"""
You should express what you want a model to do by \
providing instructions that are as clear and \
specific as you can possibly make them. \
This will guide the model towards the desired output, \
and reduce the chances of receiving irrelevant \
or incorrect responses. Don't confuse writing a \
clear prompt with writing a short prompt. \
In many cases, longer prompts provide more clarity \
and context for the model, which can lead to \
more detailed and relevant outputs.
"""
prompt = f"""
Summarize the text delimited by triple backticks \
into a single sentence.
`{text}`
"""
如果你是在开发一款允许用户输入内容,并对内容进行总结的 AI 产品,那你就可以使用到这个技巧。
技巧6:通过格式词阐述需要输出的格式
这个技巧是技巧 2 的变种,比较常用于生成文本场景。其实在场景 7 中,你也可以用到这个技巧。
假设你想让 AI 总结一篇非常非常长的文章,并且按照特定格式给你总结,那你可以在文章前面明确输出的格式(为了不占用太多显示空间,我省略了正文内容,你可以在 OpenAI 的 Playground 看到完整案例)。它的意思其实是让 ChatGPT 按 Topic 总结,每个 Topic 里按照无序列表(就是里面那个 -)将每个 Topic 的主要观点罗列出来。
Summarize the main points of the following speech
Use the following format:
Topic 1: <topic_name_1>
- <point_1>
..
Topic 2: <topic_name_2>
- <point_1>
..
Topic 10: ..
Text: """
Thank you so much, Fred, for that lovely introduction. And thanks to the Atlantic Council for hosting me today.
The course of the global economy over the past two years has been shaped by COVID-19 and our efforts to fight the pandemic. It’s now evident, though, that the war between Russia and Ukraine has redrawn the contours of the world economic outlook. Vladimir Putin’s unprovoked attack on Ukraine and its people is taking a devastating human toll, with lives tragically lost, families internally displaced or becoming refugees, and communities and cities destroyed.
...
"""
Output 是这样的:
Topic 1: The war in Ukraine
- The war is taking a human toll with lives lost, families displaced, and communities destroyed
- The Biden administration is committed to holding Russia accountable
- The war has violated international law and is a challenge to the international order
Topic 2: The global economy
- The war is having negative impacts on the global economy, including higher commodity prices and inflation
- The IMF and World Bank will be focused on helping developing countries weather the impacts of the war
- The ultimate outcome for the global economy depends on the path of the war
关于这个场景和技巧,我想再解释一下为什么潜力很大。
根据我使用各种 Summary 或者信息提取的产品,我发现 AI 并不知道什么是重点,所以在总结的过程中,会丢失很多内容。如何引导 AI 进行总结,就变得非常重要,且具有一定的可玩性。
使用此技巧可以使输出更结构化。比如针对一篇文章进行问答,你不仅想要得到一个答案,也希望 ChatGPT 的答案符合特定的格式,方便你下一步进行自动化。
比如问 "这里的债券 duration 是多少?". 正常 GPT 模型的答案可能是 "债券 duration 是 4 年" 或 "duration 4 年"。
ChatGPT 的回答不稳定,且不方便继续处理。
解法:
我们可以通过这个技巧,让模型理解我们预期的格式。并在此基础上,为了方便自动化,让模型输出特定的结构化答案 (比如 JSON/Markdown 等)。
也可以方便集成更多的额外要求,比如增加一个"confidence level", 并通过 prompt 的形式指定这些数值的格式。
比如:
{context}
Question: What is bond duration mentioned here.
Answer template (Valid JSON format):
{{
"duration": $duration_numeric_value_in_year,
"confidence_level": $answer_confidence_level_high_modrate_or_low,
}}
Answer:
在吴恩达的 ChatGPT Prompt Engineering 课程中,有提到一个这个技巧的高级用法,在让 AI 按照特定格式输出内容的同时,还让 AI 根据内容是否满足特定条件,来判断应该输出什么结果,下面课程中的案例的 prompt(注意这个是 python 代码,有一些转义字符,可以不用管):
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.\"
\"\"\"{text}\"\"\"
简单解释下,这个 prompt 分成两步:
让 AI 将输入的 text 转为步骤(就是 prompt 里的 Step 1、2)
然后还增加了一个判断,如果输入的 text 里没有 step 的内容,那么就输出 No Step
假如输入的 text 是一个泡茶的步骤介绍:
Making a cup of tea is easy! First, you need to get some \
water boiling. While that's happening, \
grab a cup and put a tea bag in it. Once the water is \
hot enough, just pour it over the tea bag. \
Let it sit for a bit so the tea can steep. After a \
few minutes, take out the tea bag. If you \
like, you can add some sugar or milk to taste. \
And that's it! You've got yourself a delicious \
cup of tea to enjoy.
那么 AI 输出的内容是这样的(因为内容中包含了步骤式的内容):
Step 1 - Get some water boiling.
Step 2 - Grab a cup and put a tea bag in it.
Step 3 - Once the water is hot enough, pour it over the tea bag.
Step 4 - Let it sit for a bit so the tea can steep.
Step 5 - After a few minutes, take out the tea bag.
Step 6 - Add some sugar or milk to taste.
Step 7 - Enjoy your delicious cup of tea!
但如果我们输入的是这样的 text:
The sun is shining brightly today, and the birds are \
singing. It's a beautiful day to go for a \
walk in the park. The flowers are blooming, and the \
trees are swaying gently in the breeze. People \
are out and about, enjoying the lovely weather. \
Some are having picnics, while others are playing \
games or simply relaxing on the grass. It's a \
perfect day to spend time outdoors and appreciate the \
beauty of nature.
从内容上看,这段话,没有任何步骤式的内容,所以 AI 的输出是这样的:
No steps provided.
技巧7:Zero-Shot Chain of Thought
基于上述的第三点缺点,研究人员就找到了一个叫 Chain of Thought 的技巧。
这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准确。
这个技巧来自于 Kojima 等人 2022 年的论文 Large Language Models are Zero-Shot Reasoners。在论文里提到,当我们向模型提一个逻辑推理问题时,模型返回了一个错误的答案,但如果我们在问题最后加入 Let‘s think step by step 这句话之后,模型就生成了正确的答案:

论文里有讲到原因,感兴趣的朋友可以去看看,我简单解释下为什么(?? 如果你有更好的解释,不妨反馈给我):
- 首先各位要清楚像 ChatGPT 这类产品,它是一个统计语言模型,本质上是基于过去看到过的所有数据,用统计学意义上的预测结果进行下一步的输出(这也就是为什么你在使用 ChatGPT 的时候,它的答案是一个字一个字地吐出来,而不是直接给你的原因,因为答案是一个字一个字算出来的)。
- 当它拿到的数据里有逻辑,它就会通过统计学的方法将这些逻辑找出来,并将这些逻辑呈现给你,让你感觉到它的回答很有逻辑。
- 在计算的过程中,模型会进行很多假设运算(不过暂时不知道它是怎么算的)。比如解决某个问题是从 A 到 B 再到 C,中间有很多假设。
- 它第一次算出来的答案错误的原因,只是因为它在中间跳过了一些步骤(B)。而让模型一步步地思考,则有助于其按照完整的逻辑链(A > B > C)去运算,而不会跳过某些假设,最后算出正确的答案。
按照论文里的解释,零样本思维链涉及两个补全结果,左侧气泡表示基于提示输出的第一次的结果,右侧气泡表示其收到了第一次结果后,将最开始的提示一起拿去运算,最后得出了正确的答案:
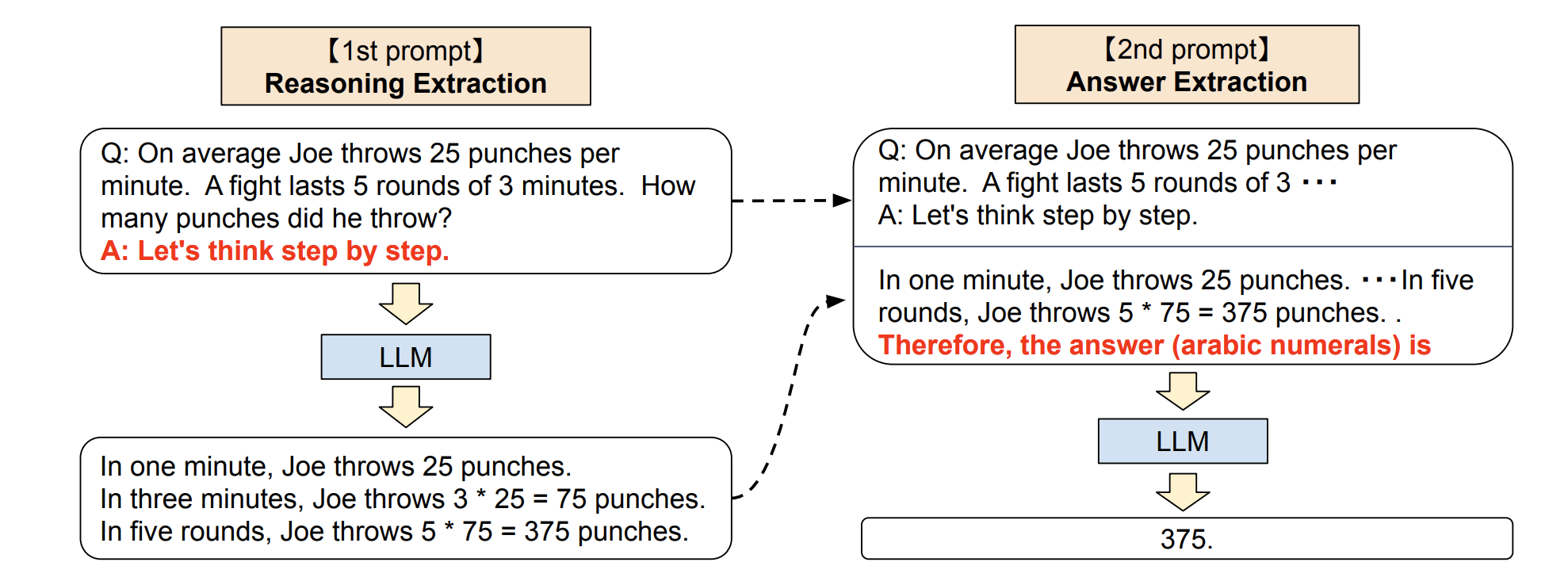
这个技巧,用于解复杂问题有用外,还适合生成一些连贯主题的内容,比如写长篇文章、电影剧本等。
但需要注意其缺点,连贯不代表它就一定不会算错,如果其中某一步骤算错了,错误会因为逻辑链,逐步将错误积累,导致生成的文本可能出现与预期不符的内容。
另外,根据 Wei 等人在 2022 年的论文表明,还有它仅在大于等于 100B 参数的模型中使用才会有效。如果你使用的是小样本模型,这个方法不会生效。
根据 Yongchao Zhou 等人的最新论文,更好的 prompt 是:
Let's work this out in a step by step way to be sure we have the right answer.
在吴恩达的 ChatGPT Prompt Engineering 课程中,有提到一个这个技巧的另一种用法,不仅仅只是让 AI 按步骤行事,还会告知 AI 每一步要做什么。比如这个案例(注意这个是 python 代码):
prompt_2 = f"""
Your task is to perform the following actions:
1 - Summarize the following text delimited by
<> with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the
following keys: french_summary, num_names.
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <list of names in Italian summary>
Output JSON: <json with summary and num_names>
Text: <{text}>
"""
简单解释下这个代码:
- 开头是让 AI 按照 1 ~ 4 步运行
- 然后再让 AI 根据特定格式输出内容
最后 AI 的输出是这样的:
Summary: Jack and Jill go on a quest to fetch water, but misfortune strikes and they tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed.
Translation: Jack et Jill partent en quête d'eau, mais la malchance frappe et ils dégringolent la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.
Names: Jack, Jill
Output JSON: {"french_summary": "Jack et Jill partent en quête d'eau, mais la malchance frappe et ils dégringolent la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.", "num_names": 2}
上述的案例只是将任务拆解,能让 AI 生成的结果更加符合要求,这个方法同样能提升 AI 的回答准确性,比如这个案例:
Determine if the student's solution is correct or not.
Question:
I'm building a solar power installation and I need help working out the financials.
Land costs $100 / square foot
I can buy solar panels for $250 / square foot
I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
Land cost: 100x
Solar panel cost: 250x
Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
AI 的回答是「The student's solution is correct」。但其实学生的答案是错误的,应该 360x + 100,000,我们将 prompt 调整成这样:
prompt = f"""
Your task is to determine if the student's solution \
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
###
question here
###
Student's solution:
###
student's solution here
###
Actual solution:
###
steps to work out the solution and your solution here
###
Is the student's solution the same as actual solution \
just calculated:
###
yes or no
###
Student grade:
###
correct or incorrect
###
Question:
###
I'm building a solar power installation and I need help \
working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations \
as a function of the number of square feet.
###
Student's solution:
###
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
###
Actual solution:
"""
本质上,也是将任务分拆成多步,这次 AI 输出的结果是这样的(结果就是正确的了):
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 10x
Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000
Is the student's solution the same as actual solution just calculated:
No
Student grade:
Incorrect
技巧8:Few-Shot Chain of Thought
要解决这个缺陷,就要使用到新的技巧,Few-Shot Chain of Thought。
根据 Wei 他们团队在 2022 年的研究表明:
通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
下面是论文里的案例,使用方法很简单,在技巧 2 的基础上,再将逻辑过程告知给模型即可。从下面这个案例里,你可以看到加入解释后,输出的结果就正确了。
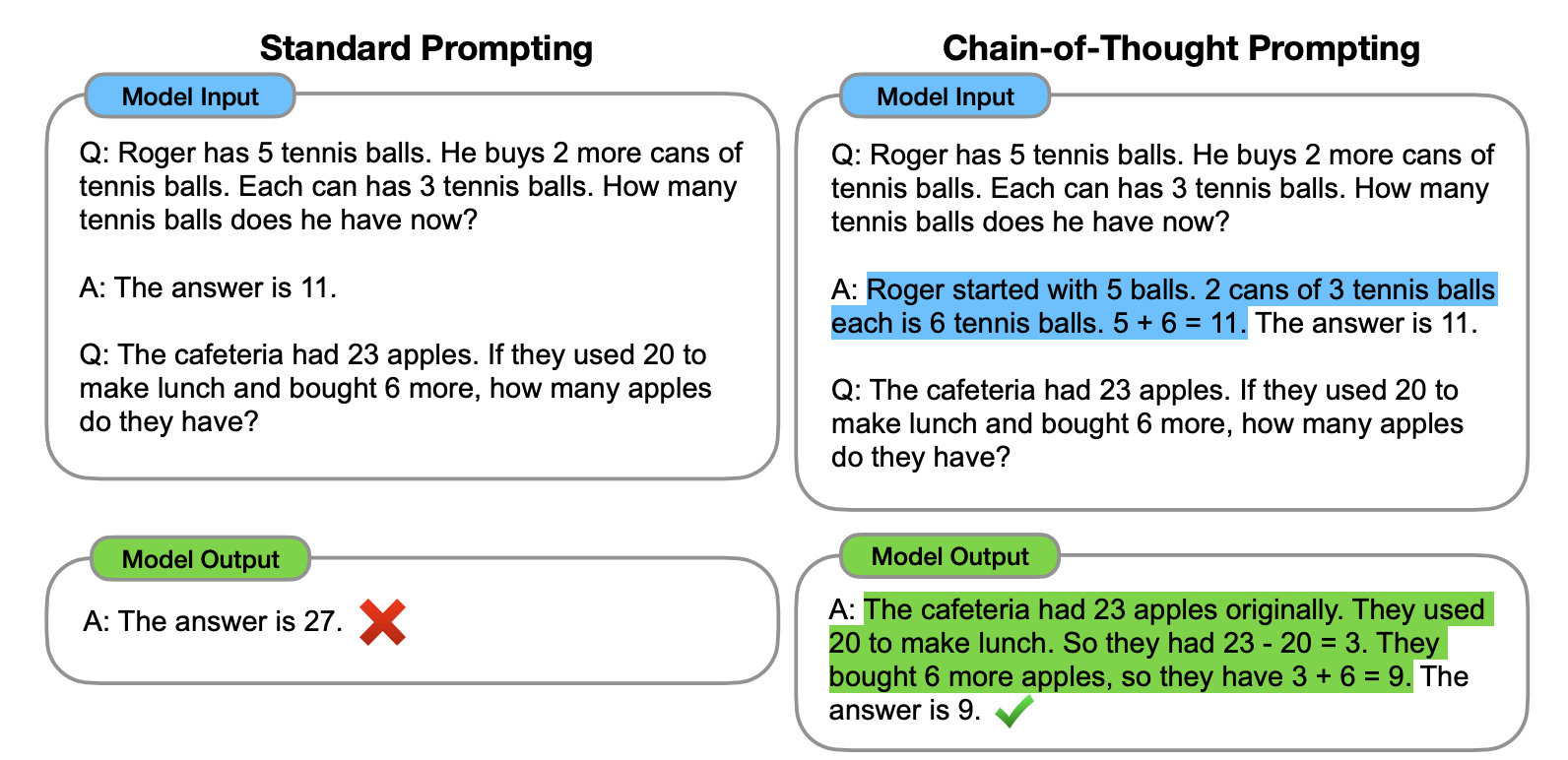
那本章开头提的例子就应该是这样的(注:本例子同样来自 Wei 团队论文):
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
聊完技巧,我们再结合前面的 Zero-Shot Chain of Thought,来聊聊 Chain of Thought 的关键知识。根据 Sewon Min 等人在 2022 年的研究 表明,思维链有以下特点:
- "the label space and the distribution of the input text specified by the demonstrations are both key (regardless of whether the labels are correct for individual inputs)" 标签空间和输入文本的分布都是关键因素(无论这些标签是否正确)。
- the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all. 即使只是使用随机标签,使用适当的格式也能提高性能。
理解起来有点难,我一个 prompt 案例给大家解释。我给 ChatGPT 一些不一定准确的例子:
I loved the new Batman movie! // Negative
This is bad // Positive
This is good // Negative
What a good show! //
Output 是这样的:
Positive
在上述的案例里,每一行,我都写了一句话和一个情感词,并用 // 分开,但我给这些句子都标记了错误的答案,比如第一句其实应该是 Positive 才对。但:
- 即使我给内容打的标签是错误的(比如第一句话,其实应该是 Positive),对于模型来说,它仍然会知道需要输出什么东西。换句话说,模型知道 // 划线后要输出一个衡量该句子表达何种感情的词(Positive or Negative)。这就是前面论文里 #1 提到的,即使我给的标签是错误的,或者换句话说,是否基于事实,并不重要。标签和输入的文本,以及格式才是关键因素。
- 只要给了示例,即使随机的标签,对于模型生成结果来说,都是有帮助的。这就是前面论文里 #2 提到的内容。
最后,需要记住,思维链仅在使用大于等于 100B 参数的模型时,才会生效。
BTW,如果你想要了解更多相关信息,可以看看斯坦福大学的讲义:Natural Language Processing with Deep Learning
技巧9:其他小trips汇总
一些小的技巧,我会统一放在这里。
在示例里加入特定符号,让模型知道如何处理特殊情况
这个解释起来有点复杂,以下是 OpenAI 的官方 prompt,在一些奇怪的问题上比如 What is Devz9 的回答,你可以用 ? 代替答案,让模型知道当遇到超出回答范围时,需要如何处理(注意:此方法在 playground 上有效,但在 ChatGPT 上无效)。
Q: Who is Batman?
A: Batman is a fictional comic book character.
Q: What is torsalplexity?
A: ?
Q: What is Devz9?
A: ?
Q: Who is George Lucas?
A: George Lucas is American film director and producer famous for creating Star Wars.
Q: What is the capital of California?
A: Sacramento.
Q: What is Kozar-09?
A:
它的 Output 是这样的:
?