HA高可用集群部署
HA高可用集群部署
高可用 ZooKeeper 集群部署
zookeeper安装部署
注意:需要安装jdk,但jdk已经在第4章装过,这里直接装zookeeper
#解压并安装zookeeper
[root@master ~]# ls
anaconda-ks.cfg
apache-hive-2.0.0-bin.tar.gz
hadoop-2.7.1.tar.gz
jdk-8u152-linux-x64.tar.gz
mysql-community-client-5.7.18-1.el7.x86_64.rpm
mysql-community-common-5.7.18-1.el7.x86_64.rpm
mysql-community-devel-5.7.18-1.el7.x86_64.rpm
mysql-community-libs-5.7.18-1.el7.x86_64.rpm
mysql-community-server-5.7.18-1.el7.x86_64.rpm
mysql-connector-java-5.1.46.jar
sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
zookeeper-3.4.8.tar.gz
[root@master ~]# tar xf zookeeper-3.4.8.tar.gz -C /usr/local/src/
[root@master ~]# cd /usr/local/src/
[root@master src]# ls
hadoop hive jdk sqoop zookeeper-3.4.8
[root@master src]# mv zookeeper-3.4.8 zookeeper
[root@master src]# ls
hadoop hive jdk sqoop zookeeper
创建zookeeper数据目录
[root@master src]# mkdir /usr/local/src/zookeeper/data
[root@master src]# mkdir /usr/local/src/zookeeper/logs
配置环境变量
[root@master src]# vi /etc/profile.d/zookeeper.sh
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin
修改zoo.cfg配置文件
[root@master src]# cd /usr/local/src/zookeeper/conf/
[root@master conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
#修改
dataDir=/usr/local/src/zookeeper/data
#增加
dataLogDir=/usr/local/src/zookeeper/logs
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
创建myid配置文件
[root@master conf]# cd ..
[root@master zookeeper]# cd data/
[root@master data]# echo "1" > myid
分发Zookeeper集群配置文件
#发送环境变量文件到slave1,slave2
[root@master data]# scp -r /etc/profile.d/zookeeper.sh slave1:/etc/profile.d/
[root@master data]# scp -r /etc/profile.d/zookeeper.sh slave2:/etc/profile.d/
#发送zookeeper配置文件到slave1,slave2
[root@master ~]# scp -r /usr/local/src/zookeeper/ slave1:/usr/local/src/
[root@master ~]# scp -r /usr/local/src/zookeeper/ slave2:/usr/local/src/
修改myid配置
#slave1
[root@slave1 ~]# echo "2" > /usr/local/src/zookeeper/data/myid
#slave2
[root@slave2 ~]# echo "3" > /usr/local/src/zookeeper/data/myid
#查看3个节点
[root@master ~]# cat /usr/local/src/zookeeper/data/myid
1
[root@slave1 ~]# cat /usr/local/src/zookeeper/data/myid
2
[root@slave2 ~]# cat /usr/local/src/zookeeper/data/myid
3
修改文件所属权限
[root@master ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
查看防火墙和selinux,如果没关就关掉
#以master为例,slave1,slave2同样要做
[root@master ~]# systemctl disable --now firewalld
[root@master ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; ve>
Active: inactive (dead)
Docs: man:firewalld(1)
[root@master ~]# vi /etc/selinux/config
SELINUX=disabled
切换hadoop用户,启动zookeeper
[root@master ~]# su - hadoop
[root@slave1 ~]# su - hadoop
[root@slave2 ~]# su - hadoop
#启动zookeeper
[hadoop@master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[hadoop@slave1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[hadoop@slave2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
查看集群
[hadoop@master ~]$ jps
1522 QuorumPeerMain
1579 Jps
[hadoop@slave1 ~]$ jps
1368 Jps
1309 QuorumPeerMain
[hadoop@slave2 ~]$ jps
1330 QuorumPeerMain
1387 Jps
Hadoop HA集群部署
注意:ssh免密登录在第4章已经配过,这里直接配HA
配置密钥加几条:
-
将masterr创建的公钥发给slave1
[hadoop@master ~]$ scp ~/.ssh/authorized_keys root@slave1:~/.ssh/ root@slave1's password: authorized_keys 100% 567 672.2KB/s 00:00 -
将slave1的私钥加到公钥里
[hadoop@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
将公钥发给slave2,master
[hadoop@slave1 ~]$ ssh-copy-id slave2 [hadoop@slave1 ~]$ ssh-copy-id master
删除第4章安装的hadoop
#删除环境变量,三个节点都要做
[root@master ~]# rm -rf /etc/profile.d/hadoop.sh
[root@slave1 ~]# rm -rf /etc/profile.d/hadoop.sh
[root@slave2 ~]# rm -rf /etc/profile.d/hadoop.sh
#删除hadoop
[root@master ~]# rm -rf /usr/local/src/hadoop/
[root@slave1 ~]# rm -rf /usr/local/src/hadoop/
[root@slave2 ~]# rm -rf /usr/local/src/hadoop/
配置hadoop环境变量
[root@master ~]# vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/src/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS="Djava.library.path=$HADOOP_INSTALL/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/local/src/jdk
export PATH=$PATH:$JAVA_HOME/bin
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin
配置 hadoop-env.sh 配置文件
[root@master ~]# tar -xf hadoop-2.7.1.tar.gz -C /usr/local/src/
[root@master ~]# mv /usr/local/src/hadoop-2.7.1/ /usr/local/src/hadoop
[root@master ~]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# vi hadoop-env.sh
#在最下面添加如下配置:
export JAVA_HOME=/usr/local/src/jdk
配置 core-site.xml 配置文件
[root@master hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
<description>ms</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
配置 hdfs-site.xml 配置文件
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master,slave1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.master</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.slave1</name>
<value>slave1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.master</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.slave1</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/src/hadoop/tmp/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/src/hadoop/tmp/hdfs/dn</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/src/hadoop/tmp/hdfs/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
配置mapred-site.xml配置文件
[root@master ~]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置yarn-site.xml配置文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
配置slaves配置文件
[root@master hadoop]# vi slaves
#删除localhost添加以下
master
slave1
slave2
创建数据存放目录
#namenode、datanode、journalnode 等存放数据的公共目录为/usr/local/src/hadoop/tmp
[root@master hadoop]# mkdir -p /usr/local/src/hadoop//tmp/hdfs/{nn,dn,jn}
[root@master hadoop]# mkdir -p /usr/local/src/hadoop/tmp/logs
分发文件到其他节点
#分发环境变量文件
[root@master hadoop]# scp -r /etc/profile.d/hadoop.sh slave1:/etc/profile.d/
hadoop.sh 100% 601 496.6KB/s 00:00
[root@master hadoop]# scp -r /etc/profile.d/hadoop.sh slave2:/etc/profile.d/
hadoop.sh 100% 601 314.7KB/s 00:00
#分发hadoop配置目录
[root@master hadoop]# scp -r /usr/local/src/hadoop/ slave1:/usr/local/src/
[root@master hadoop]# scp -r /usr/local/src/hadoop/ slave2:/usr/local/src/
修改目录所有者和所有者组
[root@master ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
生效环境变量
#在切换hadoop用户时会自动导入,为了以防万一,还是手动source一下
[root@master ~]# source /etc/profile.d/hadoop.sh
[root@slave1 ~]# source /etc/profile.d/hadoop.sh
[root@slave2 ~]# source /etc/profile.d/hadoop.sh
HA高可用集群启动
HA的启动
启动journalnode守护进程
#切换hadoop用户
[hadoop@master ~]$ hadoop-daemons.sh start journalnode
master: starting journalnode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-journalnode-master.out
slave1: starting journalnode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-journalnode-slave1.out
slave2: starting journalnode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-journalnode-slave2.out
初始化namenode
[hadoop@master ~]$ hdfs namenode -format
............
23/05/28 13:58:27 INFO namenode.FSImage: Allocated new BlockPoolId: BP-793703415-192.168.88.10-1685253507647
23/05/28 13:58:27 INFO common.Storage: Storage directory /usr/local/src/hadoop/tmp/hdfs/nn has been successfully formatted.
23/05/28 13:58:28 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
23/05/28 13:58:28 INFO util.ExitUtil: Exiting with status 0
23/05/28 13:58:28 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.88.10
************************************************************/
注册ZNode
#要先启动zookeeper不然会报错
[hadoop@master ~]$ zkServer.sh start
[hadoop@slave1 ~]$ zkServer.sh start
[hadoop@slave2 ~]$ zkServer.sh start
[hadoop@master ~]$ hdfs zkfc -formatZK
......
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: Opening socket connection to server slave2/192.168.88.30:2181. Will not attempt to authenticate using SASL (unknown error)
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: Socket connection established to slave2/192.168.88.30:2181, initiating session
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: Session establishment complete on server slave2/192.168.88.30:2181, sessionid = 0x38860f220b90000, negotiated timeout = 30000
23/05/28 14:01:08 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
23/05/28 14:01:08 INFO ha.ActiveStandbyElector: Session connected.
23/05/28 14:01:08 INFO zookeeper.ZooKeeper: Session: 0x38860f220b90000 closed
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: EventThread shut down
启动hdfs
[hadoop@master ~]$ start-all.sh
同步master数据
#复制 namenode 元数据到其它节点(在 master 节点执行)
[hadoop@master ~]$ scp -r /usr/local/src/hadoop/tmp/hdfs/nn/* slave1:/usr/local/src/hadoop/tmp/hdfs/nn/
VERSION 100% 204 189.8KB/s 00:00
seen_txid 100% 2 1.3KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 38.1KB/s 00:00
fsimage_0000000000000000000 100% 353 378.0KB/s 00:00
edits_inprogress_0000000000000000001 100% 1024KB 5.0MB/s 00:00
in_use.lock 100% 11
6.4KB/s 00:00
[hadoop@master ~]$ scp -r /usr/local/src/hadoop/tmp/hdfs/nn/* slave2:/usr/local/src/hadoop/tmp/hdfs/nn/
VERSION 100% 204 294.1KB/s 00:00
seen_txid 100% 2 2.2KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 65.8KB/s 00:00
fsimage_0000000000000000000 100% 353 554.6KB/s 00:00
edits_inprogress_0000000000000000001 100% 1024KB 6.7MB/s 00:00
in_use.lock 100% 11 8.9KB/s 00:00
在slave1上启动resourcemanager和namenode进程
[hadoop@slave1 ~]$ yarn-daemons.sh start resourcemanager
[hadoop@slave1 ~]$ hadoop-daemon.sh start namenode
[hadoop@slave1 ~]$ jps
1489 JournalNode
1841 DFSZKFailoverController
1922 NodeManager
2658 NameNode
2738 Jps
1702 DataNode
2441 ResourceManager
1551 QuorumPeerMain
启动MapReduce任务历史服务器
[hadoop@master ~]$ yarn-daemon.sh start proxyserver
starting proxyserver, logging to /usr/local/src/hadoop/logs/yarn-hadoop-proxyserver-master.out
[hadoop@master ~]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/src/hadoop/logs/mapred-hadoop-historyserver-master.out
查看端口和进程
[hadoop@master ~]$ jps
3297 JobHistoryServer
2260 DataNode
2564 DFSZKFailoverController
2788 NodeManager
2678 ResourceManager
2122 NameNode
3371 Jps
1727 JournalNode
1919 QuorumPeerMain
[hadoop@slave1 ~]$ jps
1489 JournalNode
1841 DFSZKFailoverController
1922 NodeManager
2658 NameNode
2738 Jps
1702 DataNode
2441 ResourceManager
1551 QuorumPeerMain
[hadoop@slave2 ~]$ jps
1792 NodeManager
1577 QuorumPeerMain
2282 Jps
1515 JournalNode
1647 DataNode
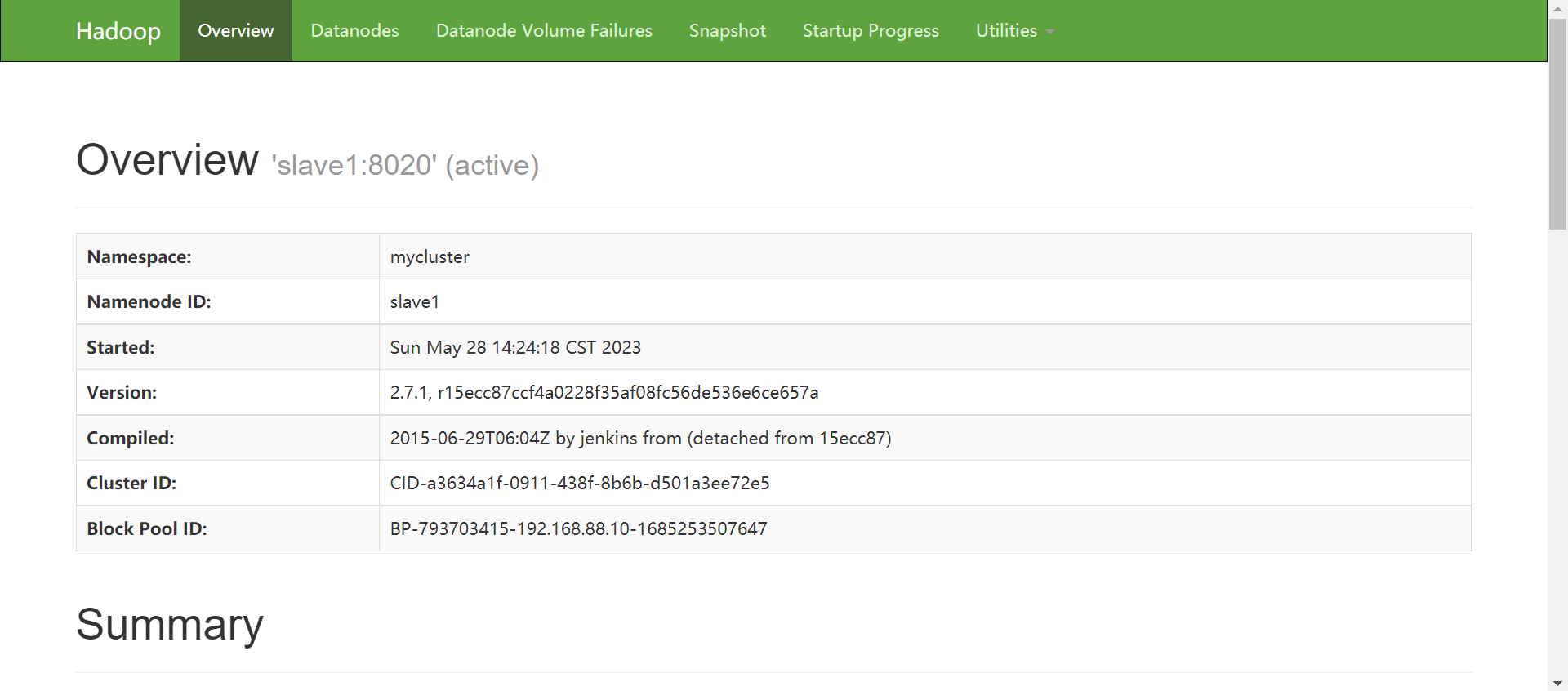
查看网页显示
-
master:50070
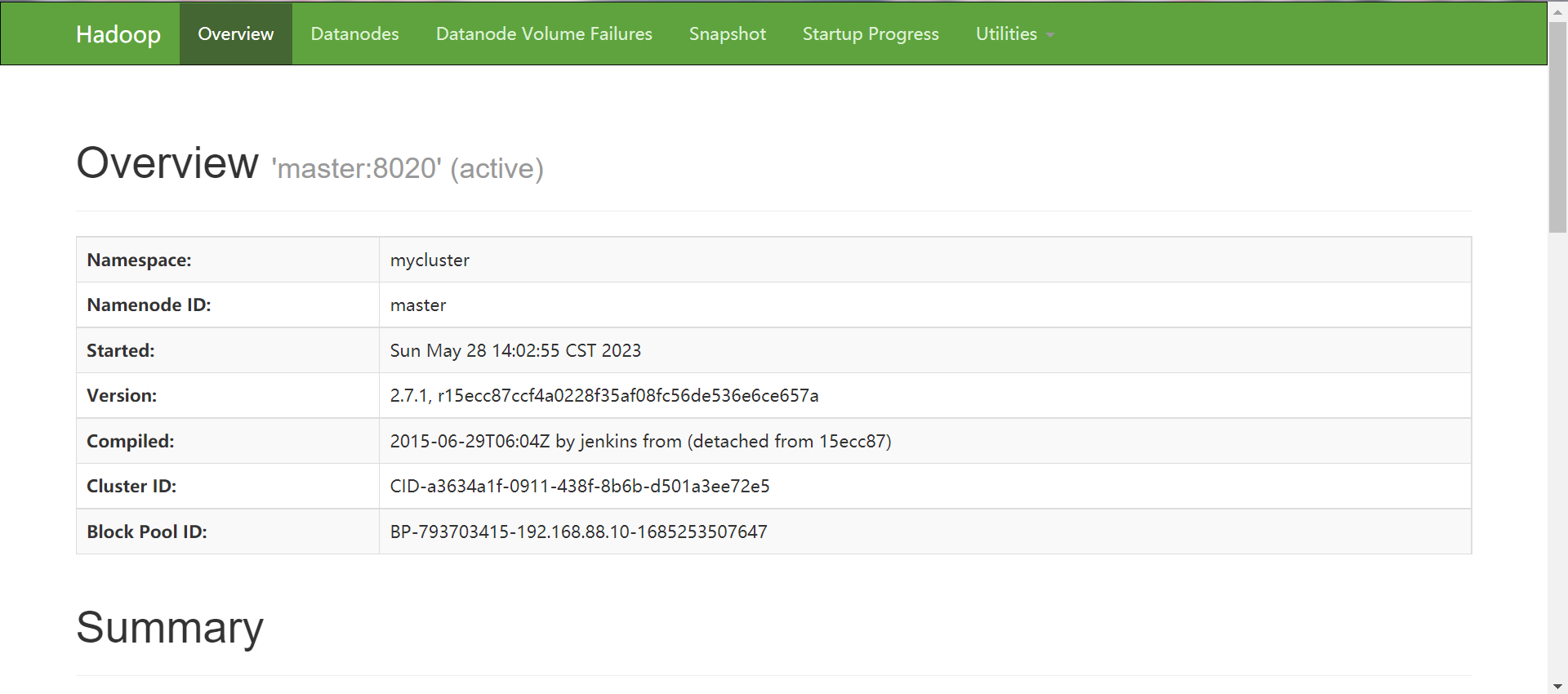
-
slave1:50070
-
master:8088
HA的测试
创建一个测试文件
[hadoop@master ~]$ vi rainmom.txt
Hello World
Hello Hadoop
在hdfs创建文件夹
[hadoop@master ~]$ hadoop fs -mkdir /input
将rainmom.txt传输到input上
[hadoop@master ~]$ hadoop fs -put ~/rainmom.txt /input
进入到jar包测试文件目录下,测试mapreduce
[hadoop@master ~]$ cd /usr/local/src/hadoop/share/hadoop/mapreduce/
[hadoop@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input/rainmom.txt /output
.....
23/05/28 14:35:37 INFO mapreduce.Job: Running job: job_1685253795384_0001
23/05/28 14:35:48 INFO mapreduce.Job: Job job_1685253795384_0001 running in uber mode : false
23/05/28 14:35:48 INFO mapreduce.Job: map 0% reduce 0%
23/05/28 14:35:57 INFO mapreduce.Job: map 100% reduce 0%
23/05/28 14:36:09 INFO mapreduce.Job: map 100% reduce 100%
23/05/28 14:36:10 INFO mapreduce.Job: Job job_1685253795384_0001 completed successfully
....
查看hdfs下的传输结果
[hadoop@master ~]$ hadoop fs -ls -R /output
-rw-r--r-- 2 hadoop supergroup 0 2023-05-28 14:36 /output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 25 2023-05-28 14:36 /output/part-r-00000
查看文件测试的结果
[hadoop@master ~]$ hadoop fs -cat /output/part-r-00000
Hadoop 1
Hello 2
World 1
高可用性验证
自动切换服务状态
#格式:hdfs haadmin -failover --forcefence --forceactive 主 备
[hadoop@master ~]$ hdfs haadmin -failover --forcefence --forceactive slave1 master
#这里注意一点,执行这条命令,会出现:forcefence and forceactive flags
not supported with auto-failover enabled.的提示,这句话表示,配置了自动切换之后,就不能进行手动切换了,
故此次切换失败, 该意思是在配置故障自动切换(dfs.ha.automatic-failover.enabled=true)之后,
无法手动进行,可将该参数更改为false(不需要重启进程)后,重新执行该命令即可。
# dfs.ha.automatic-failover.enabled参数需要在hdfs-site.xml或者core-site.xml中修改
[hadoop@master ~]$ vi /usr/local/src/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
#查看状态
[hadoop@master ~]$ hdfs haadmin -getServiceState slave1
standby
[hadoop@master ~]$ hdfs haadmin -getServiceState master
active
手动切换服务状态
#在 maste 停止并启动 namenode
[hadoop@master ~]$ hadoop-daemon.sh stop namenode
stopping namenode
#查看状态
[hadoop@master ~]$ hdfs haadmin -getServiceState master
23/05/28 14:53:55 INFO ipc.Client: Retrying connect to server: master/192.168.88.10:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From master/192.168.88.10 to master:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
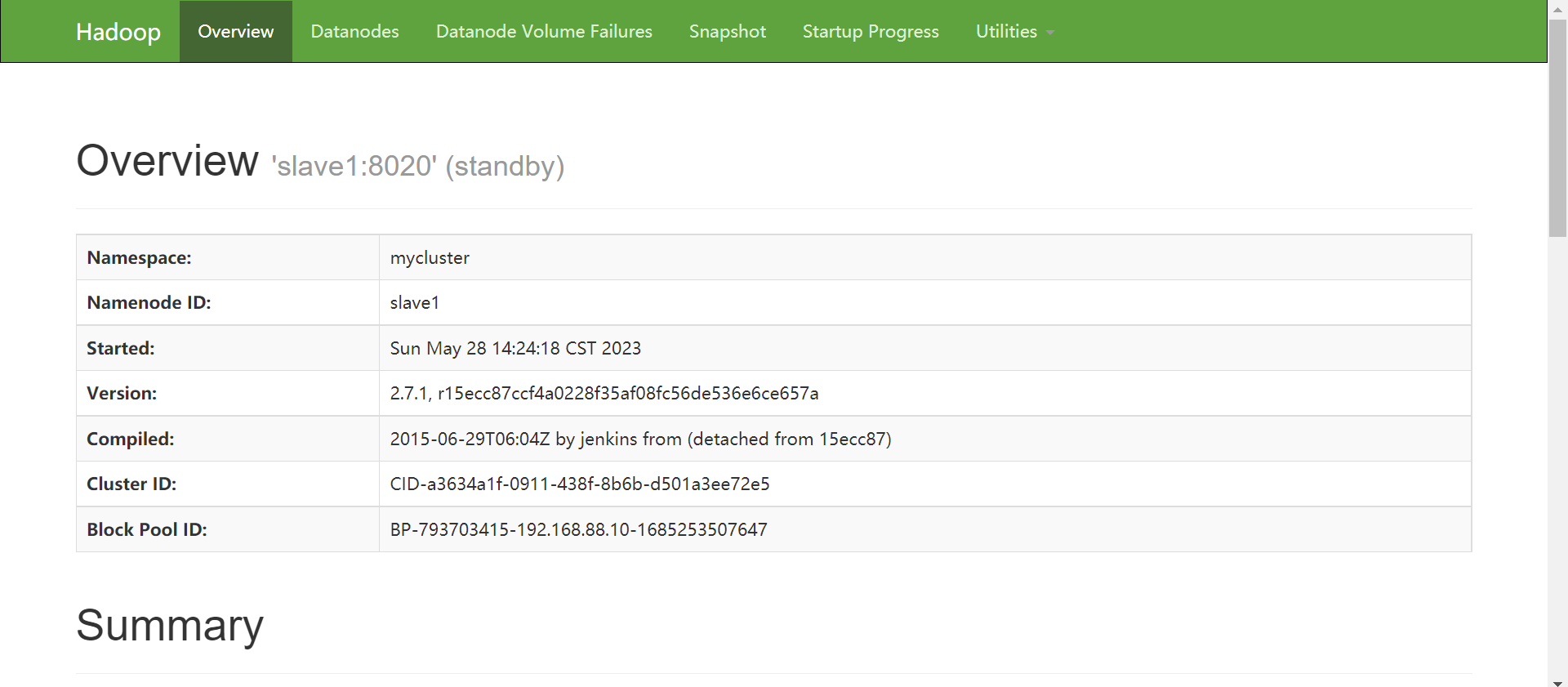
[hadoop@master ~]$ hdfs haadmin -getServiceState slave1
active
#重新启动
[hadoop@master ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.out
#再次查看状态
[hadoop@master ~]$ hdfs haadmin -getServiceState slave1
active
[hadoop@master ~]$ hdfs haadmin -getServiceState master
standby
查看web服务端
-
master:50070
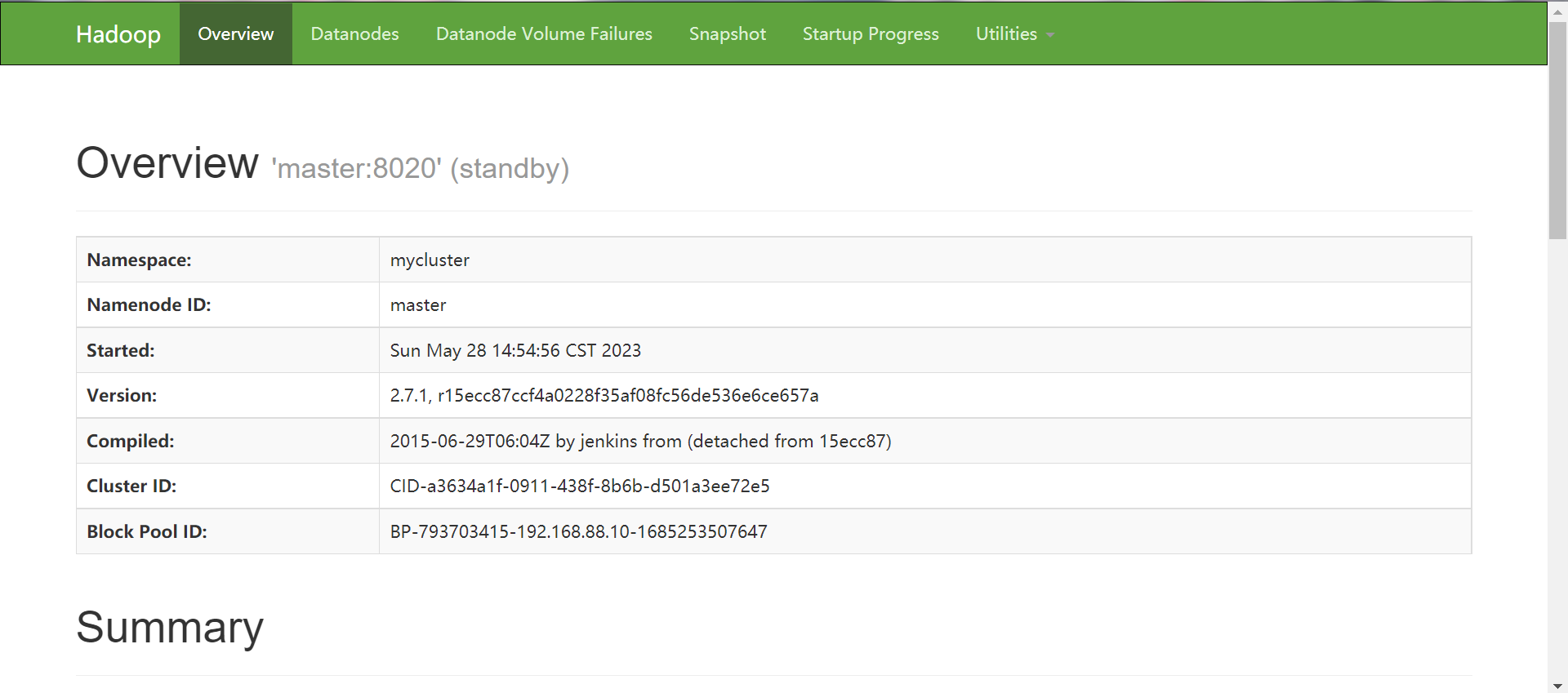
-
slave1:50070