
【LeetCode双向链表】LRU详解,双向链表实战
LRU缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
- LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
思路
LRU 的全称是 Least Recently Used,也就是“最近使用过的”,就是字面意思,这里指的是缓存中最近被使用过的数据。
我们都知道缓存的大小是有限的,因此需要使用有效的方法去管理缓存
LRU的思路很直接,就是以“最近是否被使用”为标准将缓存中每个数据进行排序,被使用越频繁的数据排序越靠前,相对的,不经常使用的数据会随着时间推移,排序逐渐靠后,直到被丢弃(当有新数据要进缓存而此时缓存空间又不够时,就会丢弃最不常使用的数据)
假设当前缓存中只能存3个值,那么根据LRU的规则会有以下情况:
好了,LRU算法的原理大概是这样了,那么本题应该怎么解?
参考labuladong的题解,问题可以描述如下:
首先要接收一个 capacity 参数作为缓存的最大容量,然后实现两个 API,一个是 put(key, val) 方法存入键值对,另一个是 get(key) 方法获取 key 对应的 val,如果 key 不存在则返回 -1。
/* 缓存容量为 2 */
LRUCache cache = new LRUCache(2);
// 你可以把 cache 理解成一个队列
// 假设左边是队头,右边是队尾
// 最近使用的排在队头,久未使用的排在队尾
// 圆括号表示键值对 (key, val)
cache.put(1, 1);
// cache = [(1, 1)]
cache.put(2, 2);
// cache = [(2, 2), (1, 1)]
cache.get(1); // 返回 1
// cache = [(1, 1), (2, 2)]
// 解释:因为最近访问了键 1,所以提前至队头
// 返回键 1 对应的值 1
cache.put(3, 3);
// cache = [(3, 3), (1, 1)]
// 解释:缓存容量已满,需要删除内容空出位置
// 优先删除久未使用的数据,也就是队尾的数据
// 然后把新的数据插入队头
cache.get(2); // 返回 -1 (未找到)
// cache = [(3, 3), (1, 1)]
// 解释:cache 中不存在键为 2 的数据
cache.put(1, 4);
// cache = [(1, 4), (3, 3)]
// 解释:键 1 已存在,把原始值 1 覆盖为 4
// 不要忘了也要将键值对提前到队头
通过上面的分析可知,我们需要实现一种数据结构cache,该数据结构具有以下特点:
1、cache中的元素需要是有序的,用以区分最近使用的数据
? 从LRU算法的解释也不难理解这一点,在该数据结构中,元素是以"是否被使用"作为排序规则的,我们可以将其转换为"被访问的次数",分别进行排序
2、支持通过key快速在cache中找到对应的val
? 有key又有val很难不联系到map(哈希表)
3、每次访问完cache中的某个key,要将对应元素变为最近使用
? 也就是要支持在任意位置插入和删除元素
满足上述描述的设计方案一般有两种:双向链表+哈希表 以及 队列+哈希表
先说第一种吧(因为最经典,有可能被要求手撕)
双向链表+哈希表
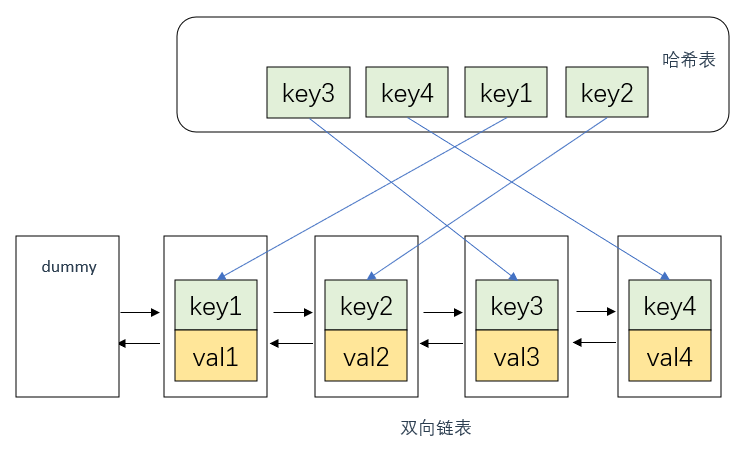
首先说明,这里双向链表的节点中应该存放两个数据,即key, val
如果不自己手写双向链表的话,那么调用std::list时,存放的数据应该是一个
pair<int, int>,即pair<key, val>
来对一对之前提到的三个要求
首先是有序。
如果我们始终按照某一顺序往双向链表添加节点,那么最后该链表就是有序的
例如,每次默认从链表尾部添加元素,那么显然越靠尾部的元素就是最近使用的,越靠头部的元素就是最久未使用的。
其次是通过key快速查找val。
引入了哈希表显然这是可以做到的,从哈希表中拿到key之后,通过修改链表指针就可以快速移动到对应节点处并取出val
最后是插入和删除任意值。
这点的实现方式和查找val一样,如果只是用链表的话,查找某一个节点最坏情况下我们需要遍历整个链表
哈希表提供的快速定位的可能
ok开始动手做,从手写双向链表开始
双向链表
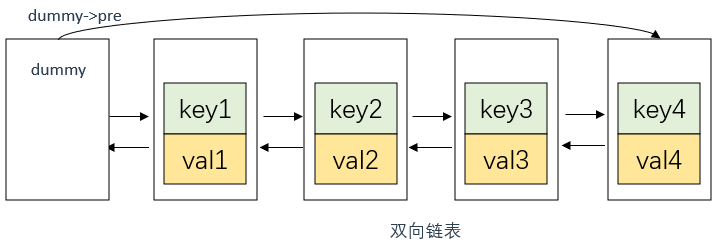
定义一个双向链表并对成员变量进行初始化(使用参数列表)
class LRUCache {
struct ListNode{//定义节点结构体
int key;
int val;
ListNode* next;
ListNode* pre;
};
ListNode* dummy;
int maxSize;//最大缓存数量
int nodeNums;//当前缓存中的节点数量
//定义哈希表,key是int,val是节点
unordered_map<int, ListNode*> hash;
public:
LRUCache(int capacity): maxSize(capacity), dummy(new ListNode){//不用参数列表也行
nodeNums = 0;
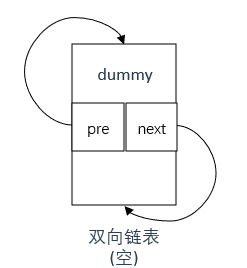
//dummy的 next 和 prev 指针都指向自身,这样当缓存为空时,dummy既是头节点也是尾节点
dummy->next = dummy;
dummy->pre = dummy;
}
int get(int key) {
}
void put(int key, int value) {
}
};
其实也不难写,就是多一个指针
除了定义双向链表的节点外,顺便声明一下dummy节点、最大缓存值maxSize以及当前缓存中的节点数量nodeNums,和hashmap
然后在LRUCache类的初始化函数中对成员变量进行初始化与赋值,完成对双向链表的初始化
注意dummy在双向链表初始化中的初始化方式,如下图所示
现在我们有了一个"哈希链表",接下来开始实现取值函数get
get方法
在get方法中,首先在哈希表中查找是否存在指定的key。
如果存在,则将该节点从链表中原位置取出,然后将其插入到链表头的后一个位置,以表示最近被访问过,最终返回该节点对应的value值。
如果不存在,则直接返回-1。
class LRUCache {
struct ListNode{//定义节点结构体
...
};
ListNode* dummy;
int maxSize;//最大缓存数量
int nodeNums;//当前缓存中的节点数量
//定义哈希表,key是int,val是节点
unordered_map<int, ListNode*> hash;
public:
LRUCache(int capacity): maxSize(capacity), dummy(new ListNode){//不用参数列表也行
nodeNums = 0;
//dummy的 next 和 prev 指针都指向自身,这样当缓存为空时,dummy既是头节点也是尾节点
dummy->next = dummy;
dummy->pre = dummy;
}
int get(int key) {// 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
if(hash.find(key) != hash.end()){
//找到对应节点,取出
ListNode* node = hash[key];
//将node从当前位置移除
node->pre->next = node->next;
node->next->pre = node->pre;
//把node插到dummy的后面,也就是链表头部
node->next = dummy->next;
node->pre = dummy;
dummy->next->pre = node;//令dummy后面节点的前面节点为node
dummy->next = node;//令dummy的后面节点为node
return node->val;
}
return -1;//没找到对应节点返回-1
}
void put(int key, int value) {
}
};
这里涉及双向链表的节点CRUD,过程图示如下:
删除节点node
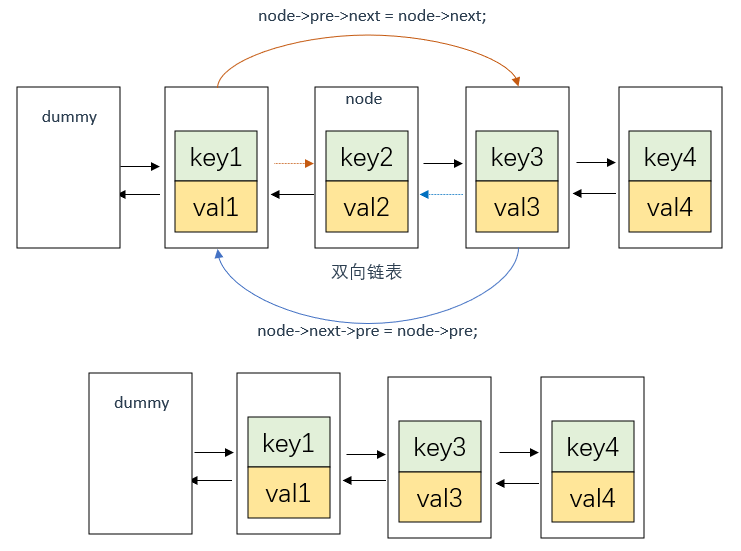
删除节点很好理解,和单向链表差不多,就不多说了
插入节点node
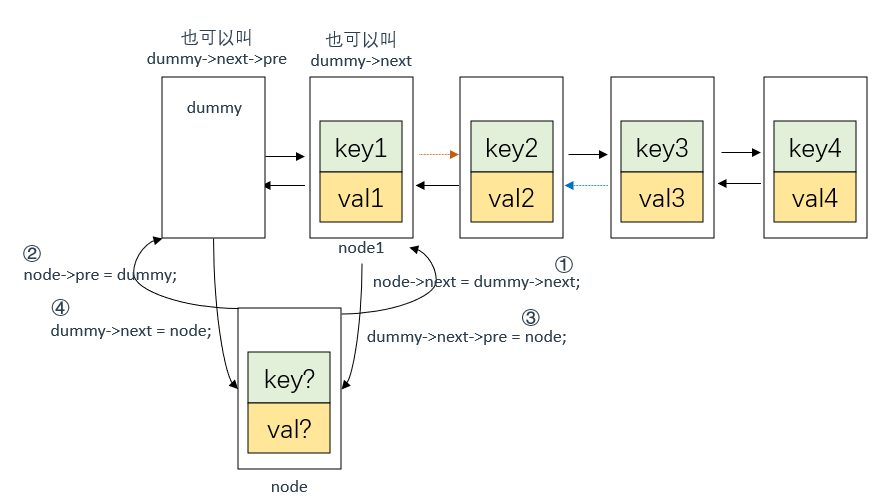
这里需要注意,要先将dummy的下一个节点(dummy->next)的前指针指向node,再将dummy的后指针指向node
在LRU缓存淘汰算法中,最近使用的节点应该放在链表的尾部,最久未使用的节点应该放在链表的头部。因此,在get函数中,我们需要将访问过的节点移动到链表的头部,也就是dummy节点和第一个节点之间。因为dummy节点并不存储任何的key和val值,所以dummy节点不能算作是节点的前驱节点或后继节点。正确的做法是让原本的第一个节点作为新节点的前驱节点,而不是dummy节点,即当前双向链表理论上的第一个节点是node
好了,get函数写完了
put方法
在put方法中,首先检查哈希表中是否已经存在指定的key。
如果已经存在,则更新该节点的value值,并将其移动到链表头的后一个位置来表示最近被访问过。
如果不存在,则需要根据缓存容量是否已满来进行不同的处理。
如果缓存未满,则创建一个新的节点,并将其插入到链表头的后一个位置,同时在哈希表中记录该key对应的节点。
如果缓存已满,则需要替换最老的节点,这里选择删除链表尾部的节点,并在哈希表中删除该key对应的节点,然后再创建一个新的节点来保存新的key和value,并将其插入到链表头的后一个位置,同样需要在哈希表中记录该key对应的节点。
class LRUCache {
struct ListNode{//定义节点结构体
int key;
int val;
ListNode* next;
ListNode* pre;
};
ListNode* dummy;
int maxSize;//最大缓存数量
int nodeNums;//当前缓存中的节点数量
//定义哈希表,key是int,val是节点
unordered_map<int, ListNode*> hash;
public:
LRUCache(int capacity): maxSize(capacity), dummy(new ListNode){//不用参数列表也行
nodeNums = 0;
//dummy的 next 和 prev 指针都指向自身,这样当缓存为空时,dummy既是头节点也是尾节点
dummy->next = dummy;
dummy->pre = dummy;
}
int get(int key) {// 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
if(hash.find(key) != hash.end()){
//找到对应节点,取出
ListNode* node = hash[key];
//将node从当前位置移除
node->pre->next = node->next;
node->next->pre = node->pre;
//把node插到dummy的后面,也就是链表头部
node->next = dummy->next;
node->pre = dummy;
dummy->next->pre = node;//令dummy后面节点的前面节点为node
dummy->next = node;//令dummy的后面节点为node
return node->val;
}
return -1;//没找到对应节点返回-1
}
//如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value
void put(int key, int value) {
//检查是否存在对应键值
if(hash.find(key) != hash.end()){//存在
hash[key]->val = value;//键已经存在于哈希表中,那么需要更新这个键对应的节点的值
get(key);//调用 get(key) 函数,将这个节点移动到链表头部,表示最近访问过它
}else{//不存在,添加进链表
if(nodeNums < maxSize){//缓存没满
nodeNums++;//缓存中当前节点数增加
//创建新节点
ListNode* node = new ListNode;
node->key = key;
node->val = value;
//哈希表对应位置进行记录
hash[key] = node;
//将新节点插到dummy后面,也就是链表头部
node->next = dummy->next;
node->pre = dummy;
dummy->next->pre = node;
dummy->next = node;
}else{//缓存满了,删除此时链表末尾的节点
//取链表最后一个节点,即dummy的pre指针指向的节点
ListNode* node = dummy->pre;
hash.erase(node->key);//在哈希表中删除对应节点
hash[key] = node;//在哈希表中添加新的键值对,其中 key 是缓存节点的键,node 则是新的节点。
node->key=key;//更新 node 节点的键值为新的 key。
node->val=value;
get(key);
}
}
}
};
put函数中对节点的插入删除操作与get方法中一致,就不重复说明了
有一点需要额外说明的是关于dummy的
dummy是一个虚拟头节点,用于简化链表操作。因为对于任意一个节点node,它的前一个节点可以通过node->prev访问到,但是对于头节点,我们无法访问它的前一个节点,因此引入了dummy作为虚拟头节点。
dummy的next指针指向链表逻辑上的第一个节点,dummy的prev指针指向链表逻辑上的最后一个节点。
代码
双向链表+哈希表
class LRUCache {
struct ListNode{//定义节点结构体
...
};
ListNode* dummy;
int maxSize;//最大缓存数量
int nodeNums;//当前缓存中的节点数量
//定义哈希表,key是int,val是节点
unordered_map<int, ListNode*> hash;
public:
LRUCache(int capacity): maxSize(capacity), dummy(new ListNode){//不用参数列表也行
nodeNums = 0;
//dummy的 next 和 prev 指针都指向自身,这样当缓存为空时,dummy既是头节点也是尾节点
dummy->next = dummy;
dummy->pre = dummy;
}
int get(int key) {
...
}
//如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value
void put(int key, int value) {
//检查是否存在对应键值
if(hash.find(key) != hash.end()){//存在
hash[key]->val = value;//键已经存在于哈希表中,那么需要更新这个键对应的节点的值
get(key);//调用 get(key) 函数,将这个节点移动到链表头部,表示最近访问过它
}else{//不存在,添加进链表
if(nodeNums < maxSize){//缓存没满
nodeNums++;//缓存中当前节点数增加
//创建新节点
ListNode* node = new node;
node->key = key;
node->val = val;
//哈希表对应位置进行记录
hash[key] = node;
//将新节点插到dummy后面,也就是链表头部
node->next = dummy->next;
node->pre = dummy;
dummy->next->pre = node;
dummy->next = node;
}else{//缓存满了,删除此时链表末尾的节点
//取链表最后一个节点,即dummy的pre指针指向的节点
ListNode* node = dummy->pre;
hash.erase(node->key);//在哈希表中删除对应节点
hash[key] = node;//在哈希表中添加新的键值对,其中 key 是缓存节点的键,node 则是新的节点。
node->key=key;//更新 node 节点的键值为新的 key。
node->val=value;
get(key);
}
}
}
};
队列+哈希表
TBD