
自然语言处理(NLP) - 前预训练时代的自监督学习
前预训练时代的自监督学习自回归、自编码预训练的前世

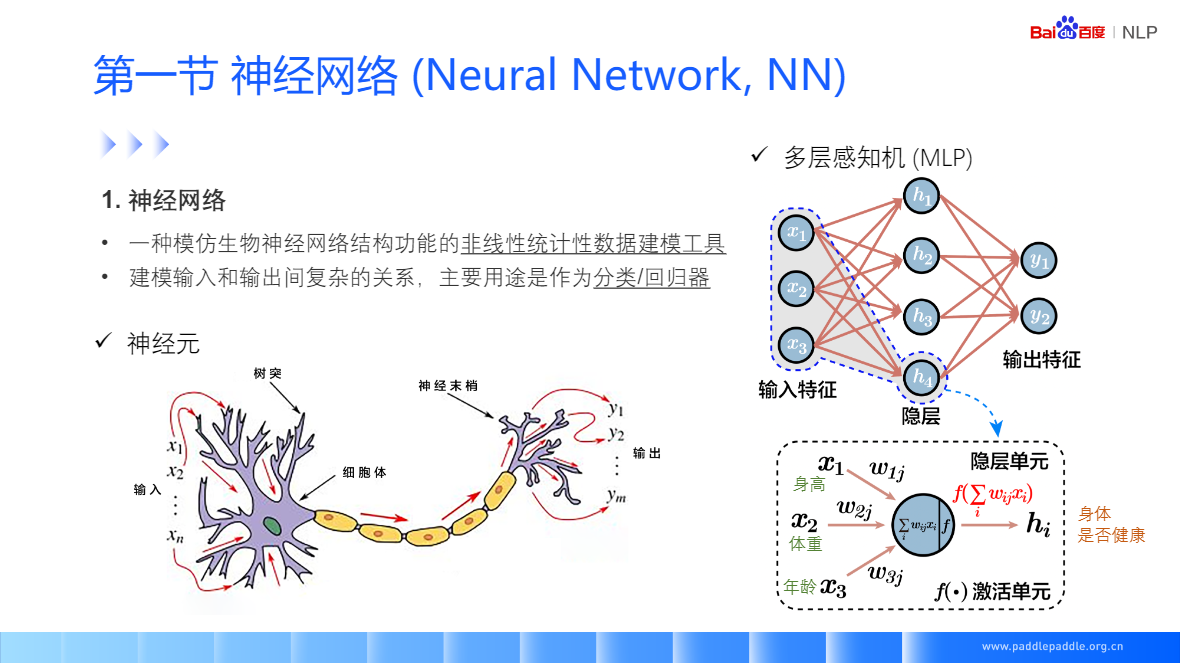
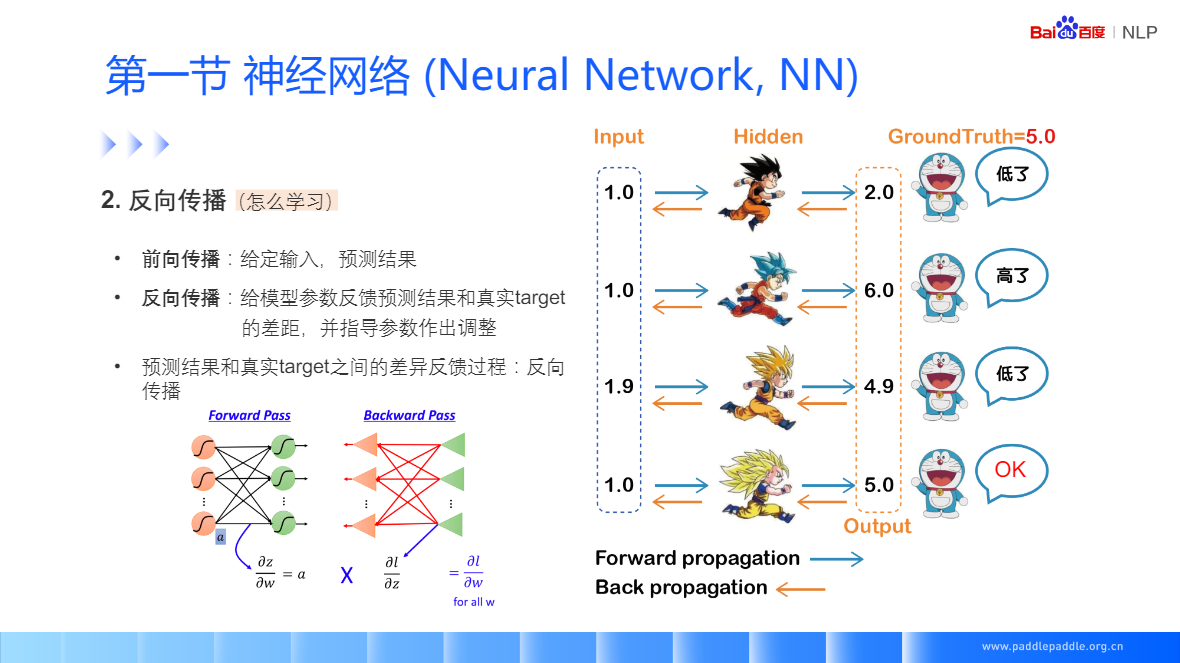
神经网络(Neural Network, NN)
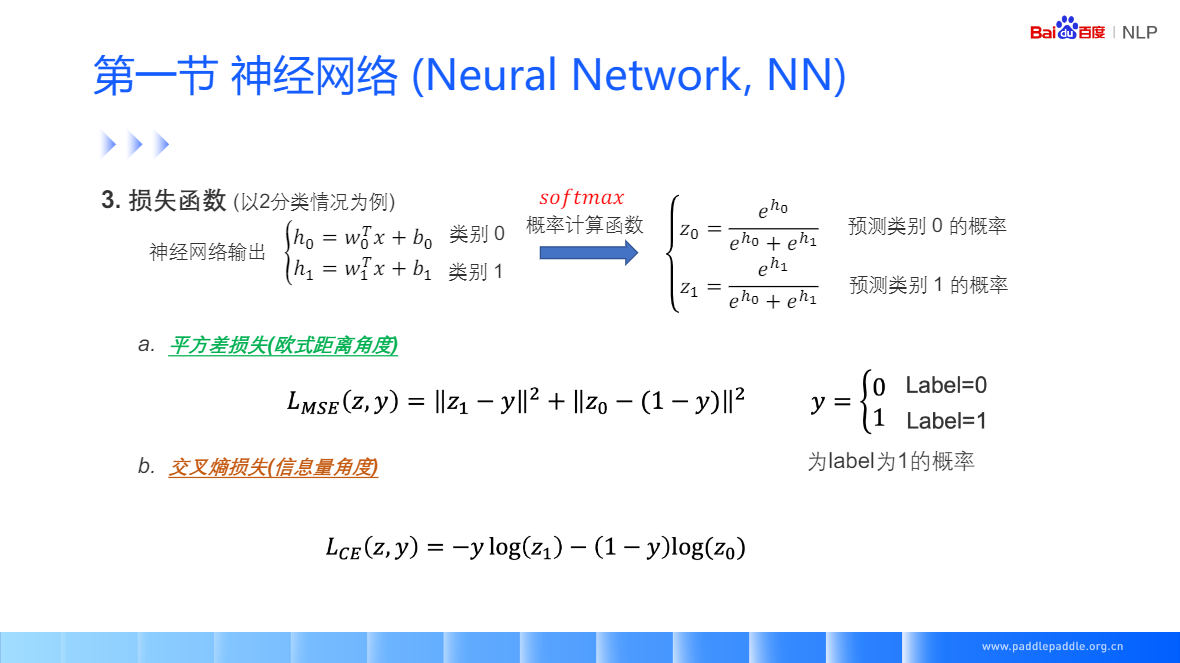
损失函数,度量神经网络的预测结果和真实结果相差多少
- 平方差损失(欧式距离角度)预测概率分部和实际标签概率的欧式距离
- 交叉熵损失(信息量角度)预测概率分部和真实概率分部的差异,指导神经网络学习时,更加稳定
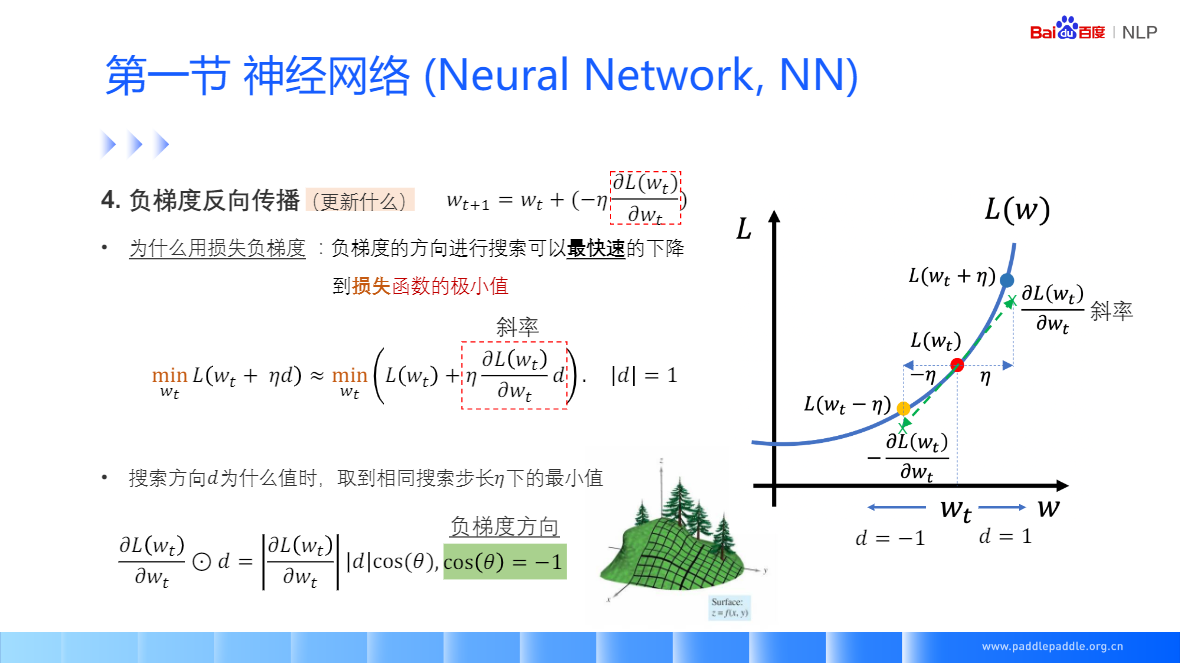
对参数W更新损失的负梯度
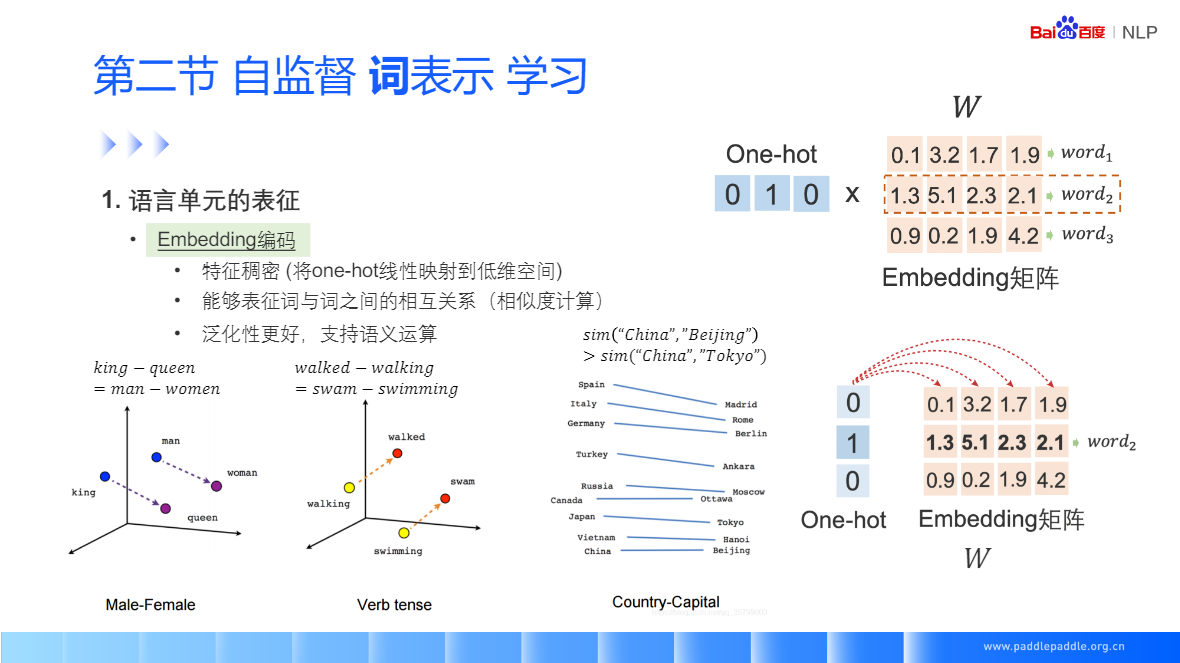
One-hot 人为规定,不需要学习,在推荐里有非常多的用处,(可以理解成完全命中)

词向量需要学习,可以很好的泛化结果,泛化性能比 one-hot 更好(可以理解成泛化关系的建模)
评估模型的好坏:有全体指标,以及一些公开的数据集,去评估词向量的相关性

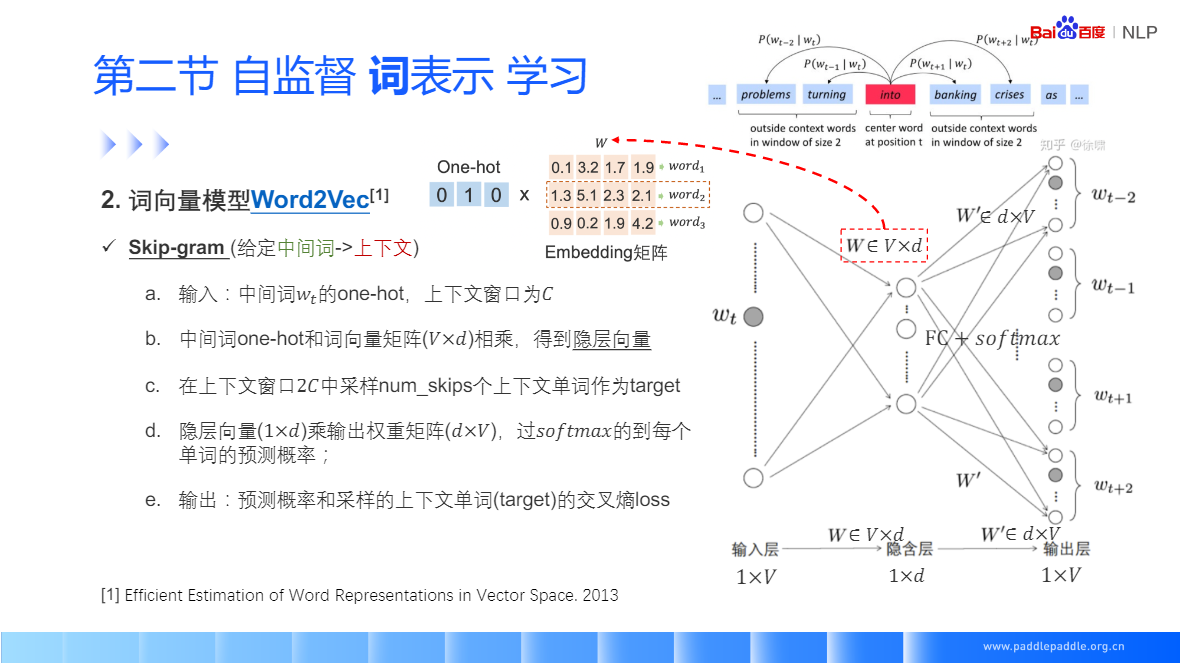
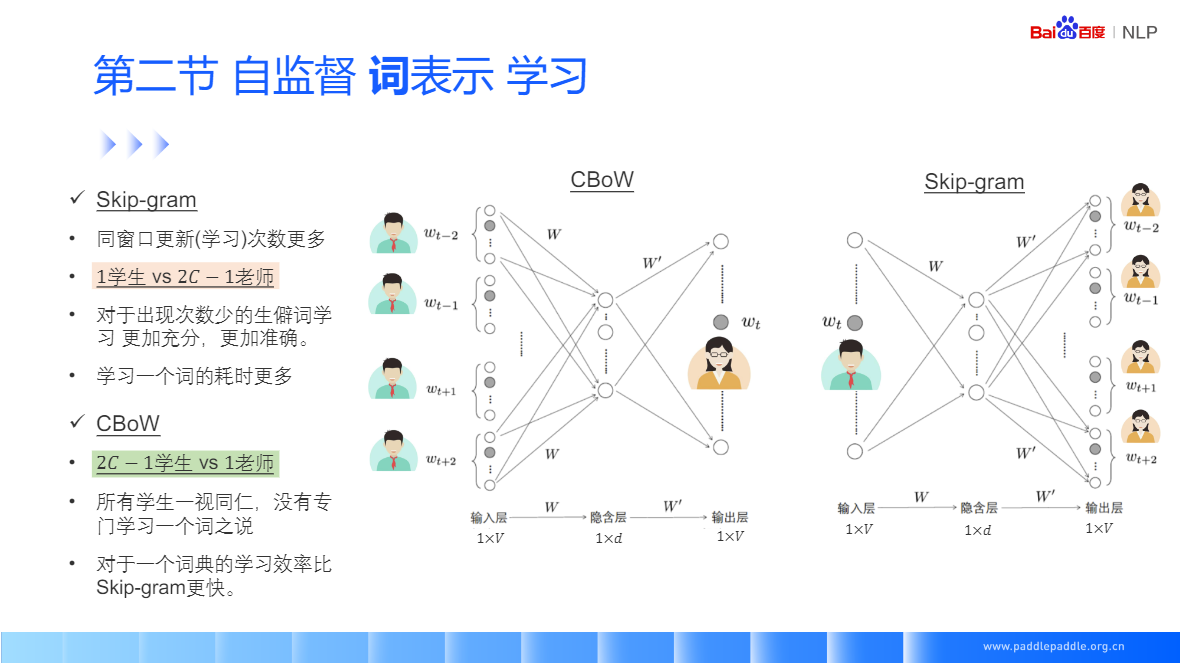
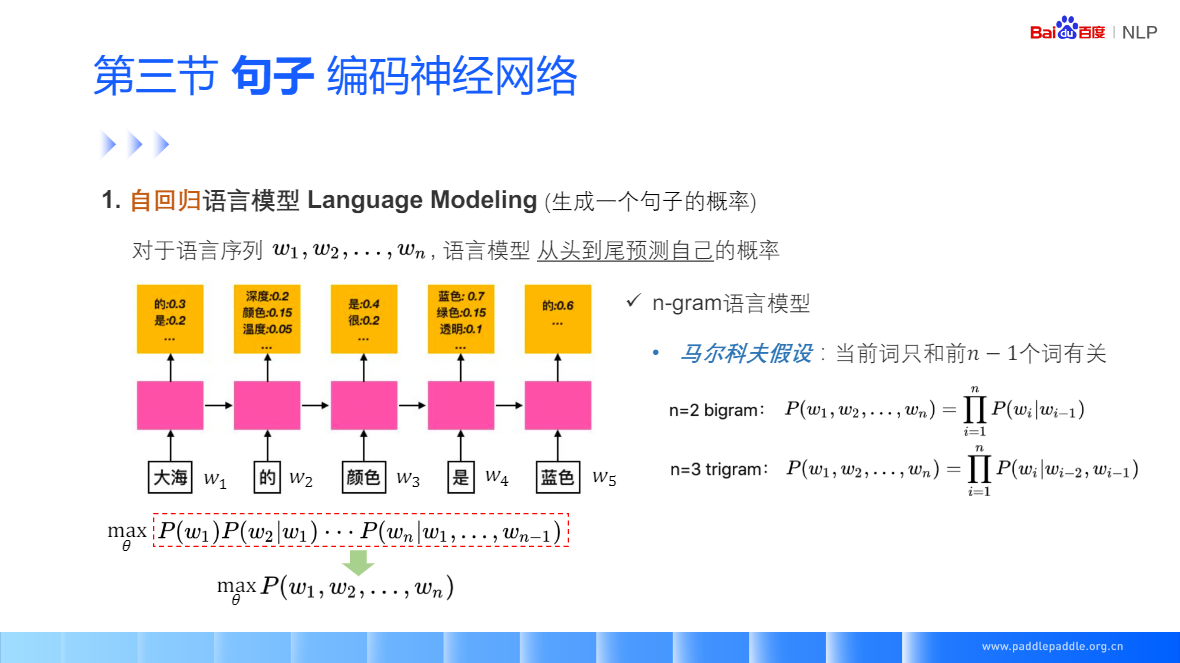
Skip-gram: 给定一个中间值,预测上下文窗口中的一个词

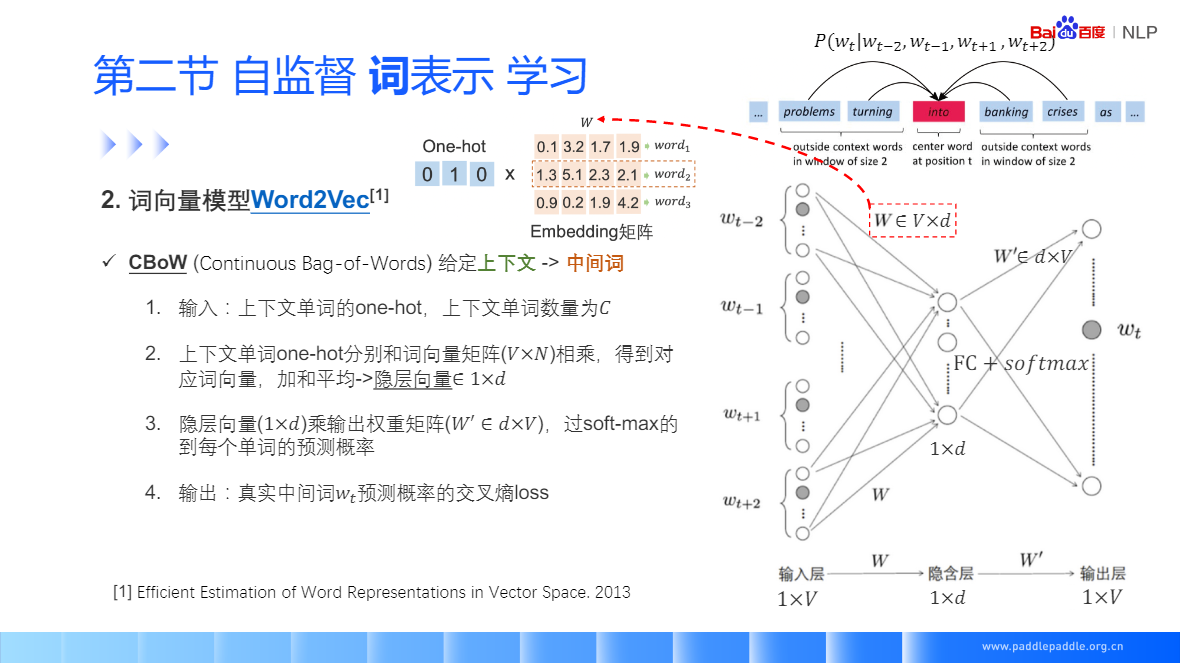
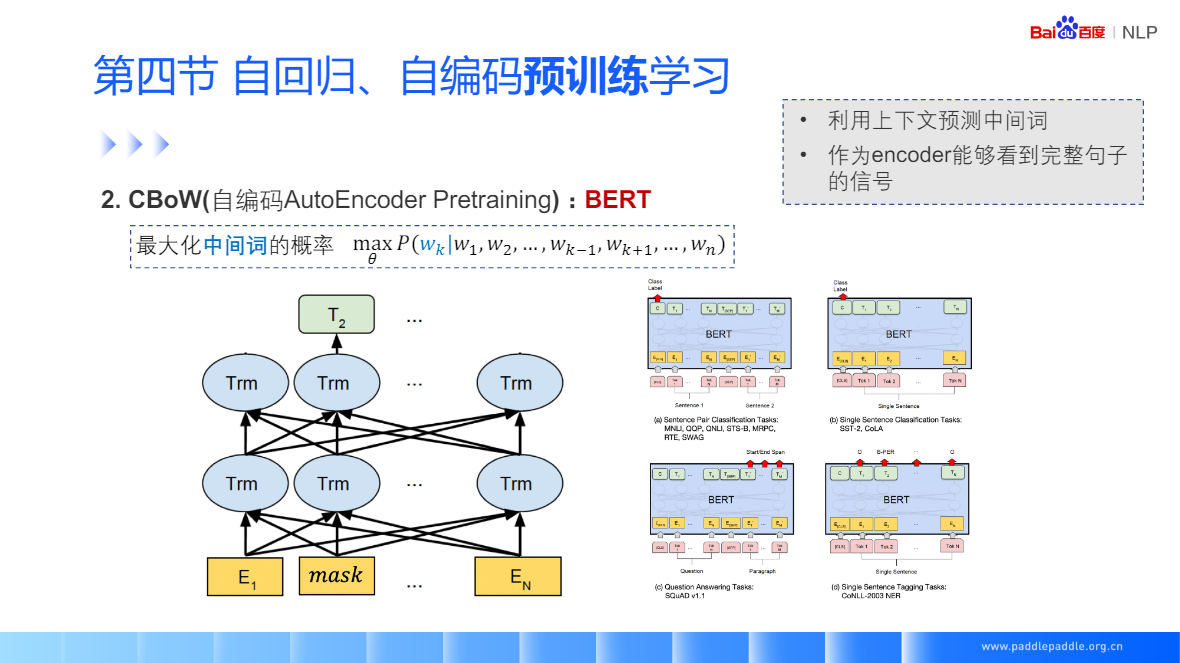
CBoW:给定一个上下文词,预测中间值
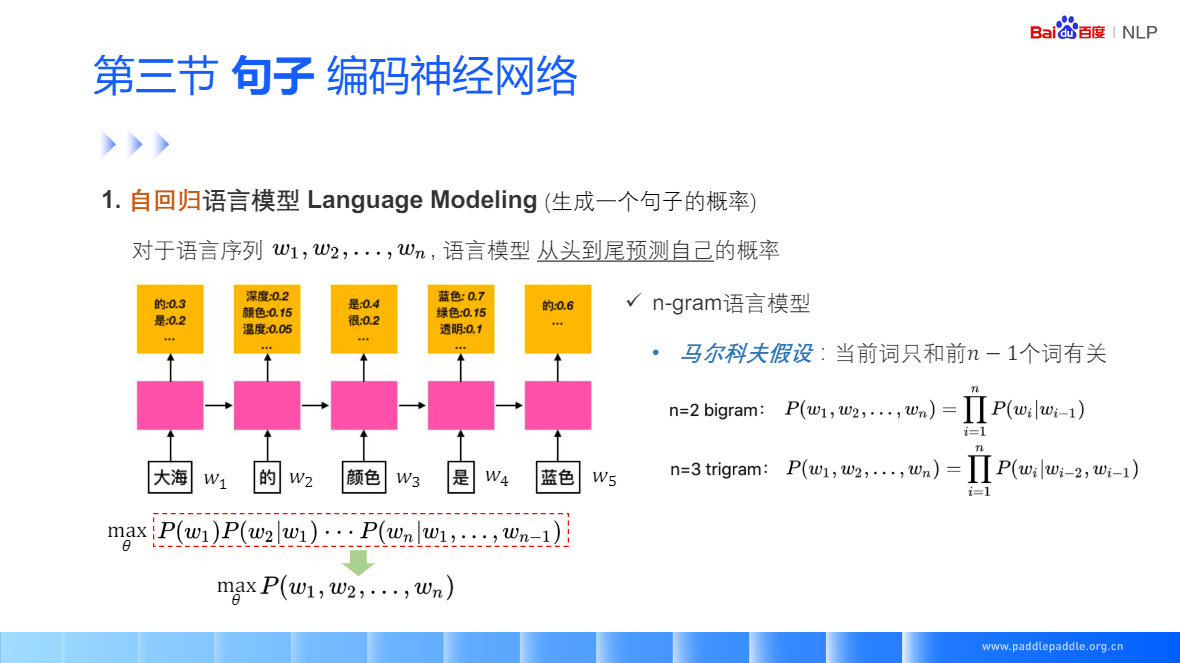
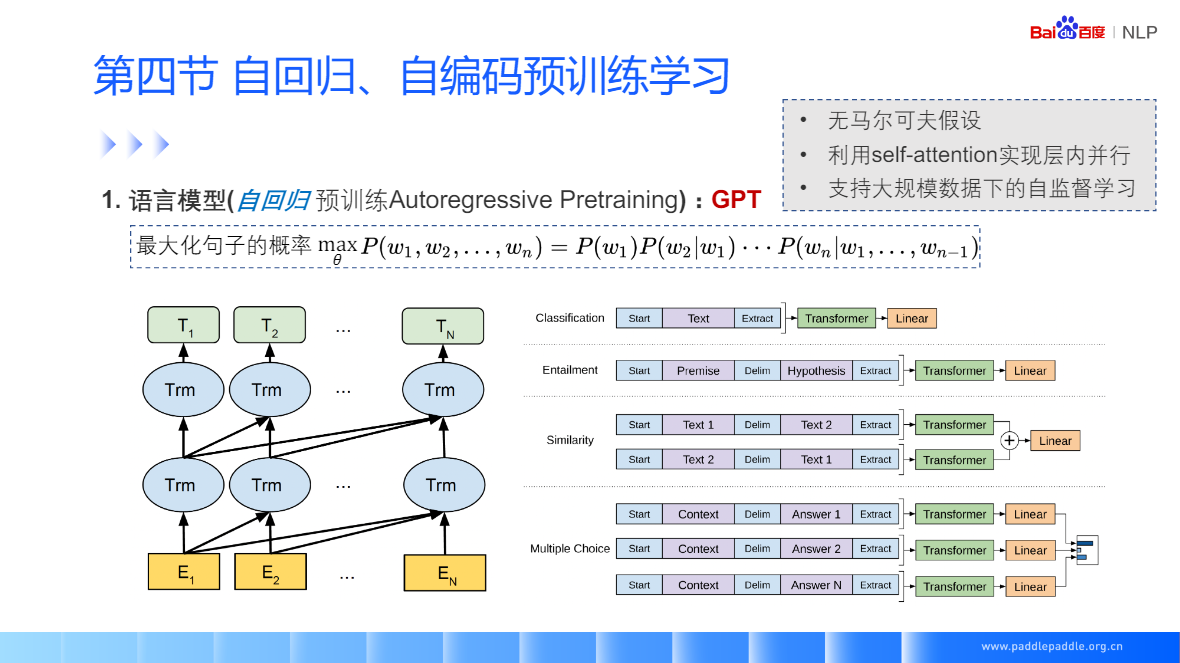
RNN 抛开马尔科夫假设,
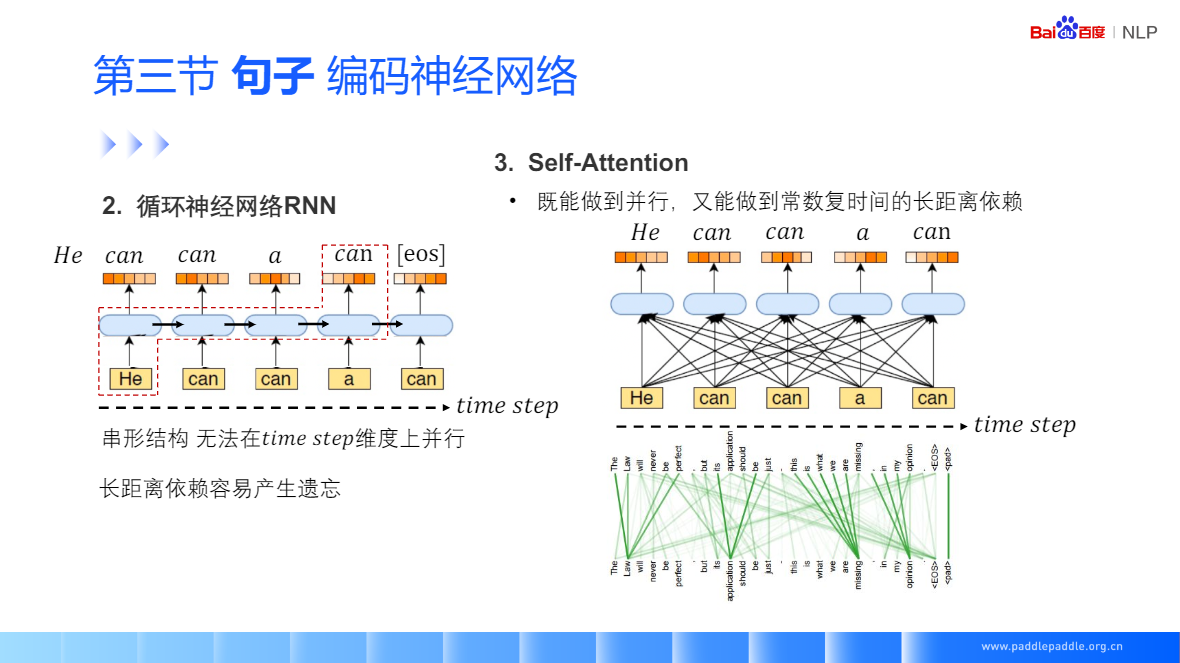
Self-Attention:每个单词和整句所有话进行匹配,来获取当前单词对每个单词的重视程度,利用这个重视程序,对整句话的每个单词进行加权,加权的结果用于表示当前这个单词
Self-Attention:也是非常流行的 Transformer 的核心模块,
Seft-Attention 没有考虑单词的顺序,所以为了更精装的表示位置信息,需要对句子的输入加个位置的序号 Positional Embedding
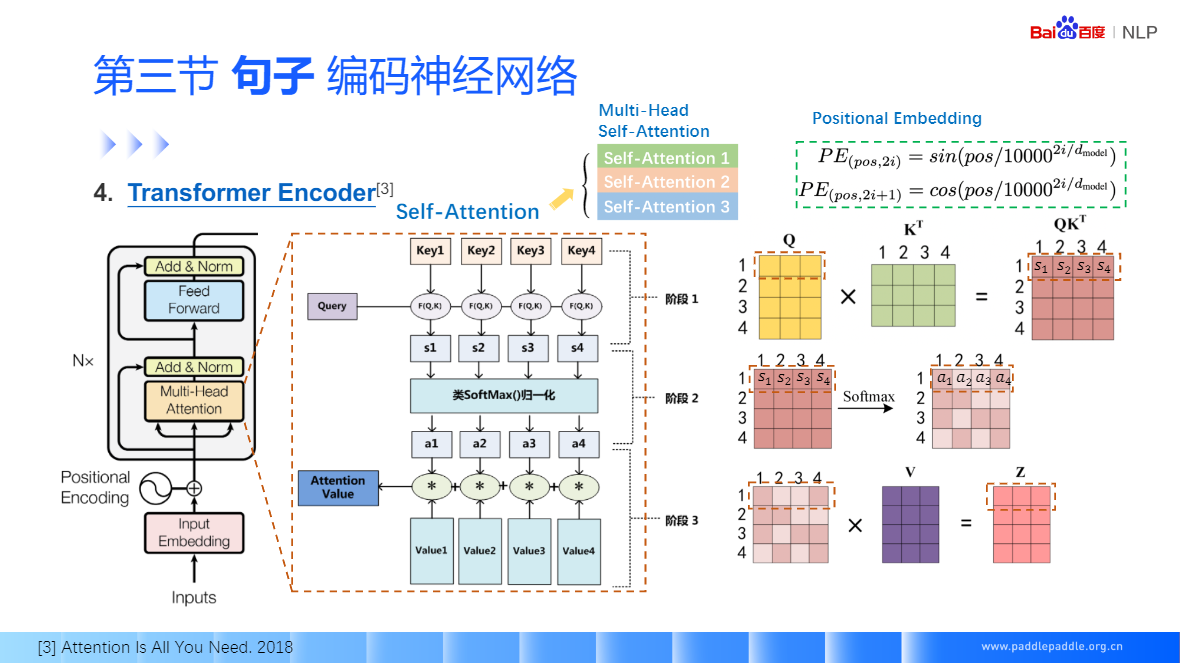
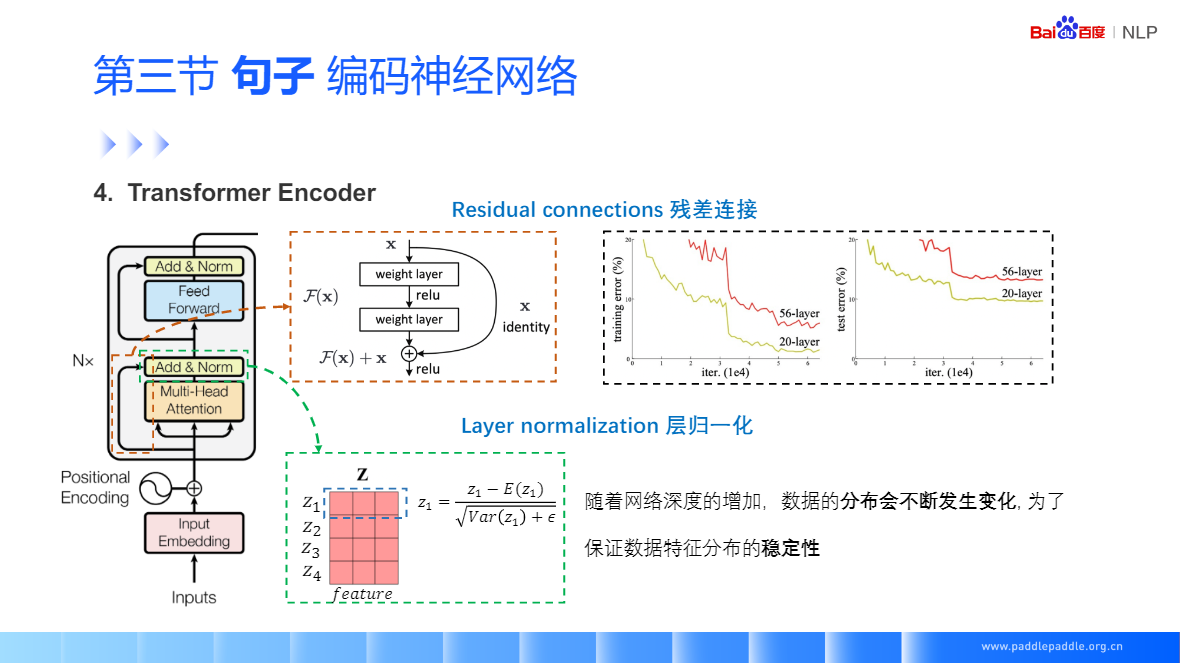
残差连接,很好的缓解梯度消失的问题,包括映射和直连接部分
https://aistudio.baidu.com/aistudio/education/lessonvideo/1451160