
Helm实战案例一:在Kubernetes上使用Helm搭建Prometheus Operator监控
一.系统环境
本文主要基于Kubernetes1.21.9和Linux操作系统CentOS7.4。
| 服务器版本 | Prometheus Operator版本 | docker软件版本 | Kubernetes(k8s)集群版本 | CPU架构 |
|---|---|---|---|---|
| CentOS Linux release 7.4.1708 (Core) | 0.35.0 | Docker version 20.10.12 | v1.21.9 | x86_64 |
Kubernetes集群架构:k8scloude1作为master节点,k8scloude2,k8scloude3作为worker节点。
| 服务器 | 操作系统版本 | CPU架构 | 进程 | 功能描述 |
|---|---|---|---|---|
| k8scloude1/192.168.110.130 | CentOS Linux release 7.4.1708 (Core) | x86_64 | docker,kube-apiserver,etcd,kube-scheduler,kube-controller-manager,kubelet,kube-proxy,coredns,calico | k8s master节点 |
| k8scloude2/192.168.110.129 | CentOS Linux release 7.4.1708 (Core) | x86_64 | docker,kubelet,kube-proxy,calico | k8s worker节点 |
| k8scloude3/192.168.110.128 | CentOS Linux release 7.4.1708 (Core) | x86_64 | docker,kubelet,kube-proxy,calico | k8s worker节点 |
二.前言
随着云原生应用的普及,Kubernetes已成为了事实上的容器编排标准。而作为一个高可用、弹性伸缩的容器编排平台,Kubernetes的稳定性和可靠性是非常重要的。因此,在Kubernetes集群中加入监控系统,可以帮助我们发现和解决问题,确保集群的稳定性和可靠性。
在众多的监控系统中,Prometheus因其卓越的性能和可扩展性而备受关注。而Prometheus Operator是一种用于在Kubernetes上运行和管理Prometheus的解决方案,它可以自动创建、配置和管理Prometheus实例。相比于传统方式手动部署Prometheus,Prometheus Operator可以大幅简化我们的工作量。
在Kubernetes上使用Helm搭建Prometheus Operator监控的前提是已经有一套可以正常运行的Kubernetes集群,关于Kubernetes(k8s)集群的安装部署,可以查看博客《Centos7 安装部署Kubernetes(k8s)集群》https://www.cnblogs.com/renshengdezheli/p/16686769.html。
三.Prometheus Operator简介
Prometheus Operator是CoreOS开源的项目,它提供了一种Kubernetes-native的方式来运行和管理Prometheus。Prometheus Operator可以自动创建、配置和管理Prometheus实例,并将其与Kubernetes中的服务发现机制集成在一起,从而实现对Kubernetes集群的自动监控。
Prometheus和Prometheus Operator的区别如下:
Prometheus是一种开源的监控系统,用于记录各种指标,并提供查询接口和告警机制。而Prometheus Operator则是一种用于在Kubernetes上运行和管理Prometheus的解决方案。相比于传统方式手动部署Prometheus,Prometheus Operator可以自动创建、配置和管理Prometheus实例,并将其与Kubernetes中的服务发现机制集成在一起,大幅简化了我们的工作量。
以下是Prometheus生态架构图:
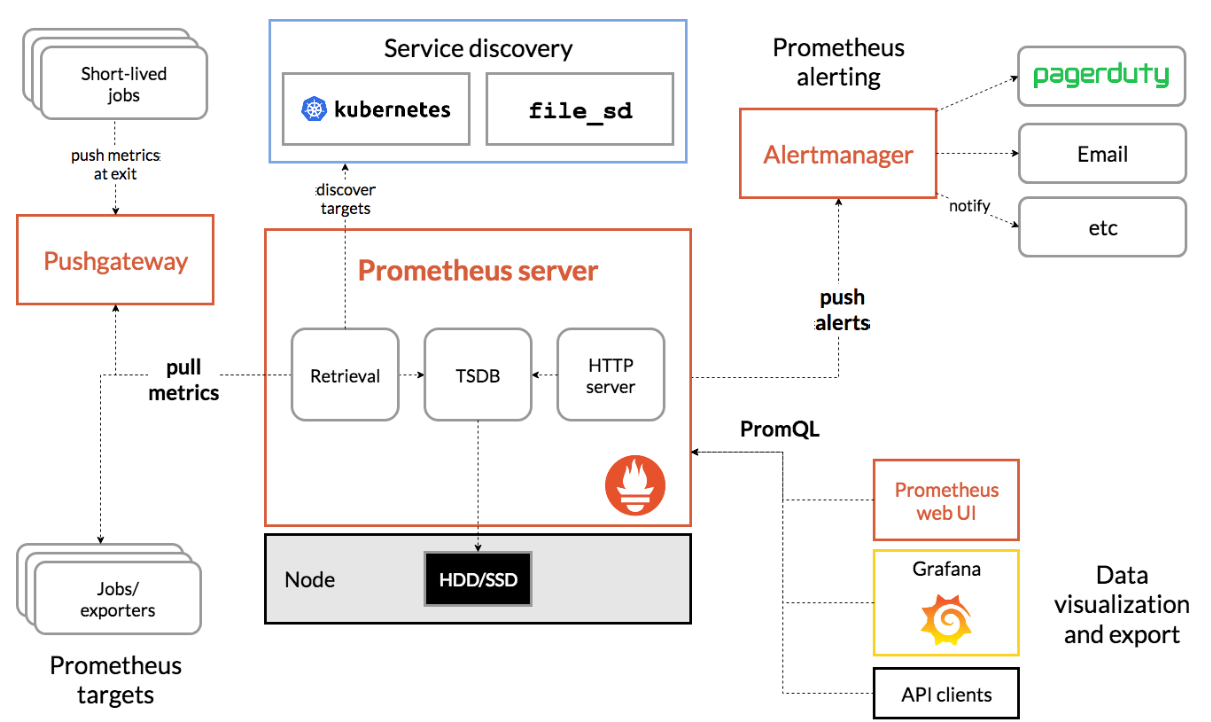
- Prometheus Server:用于持久化存储和查询时间序列数据的核心组件。
- Exporter:用于将各种服务和系统的指标暴露为Prometheus可抓取的格式。
- Alertmanager:用于处理由Prometheus Server生成的告警信息,并对其进行路由、静音、聚合等操作。
- Pushgateway:允许临时性的、批量的指标推送到Prometheus Server中。
- Grafana:一个开源的指标可视化和分析工具,可以与Prometheus进行无缝集成。
以下是Prometheus Operator生态架构图:
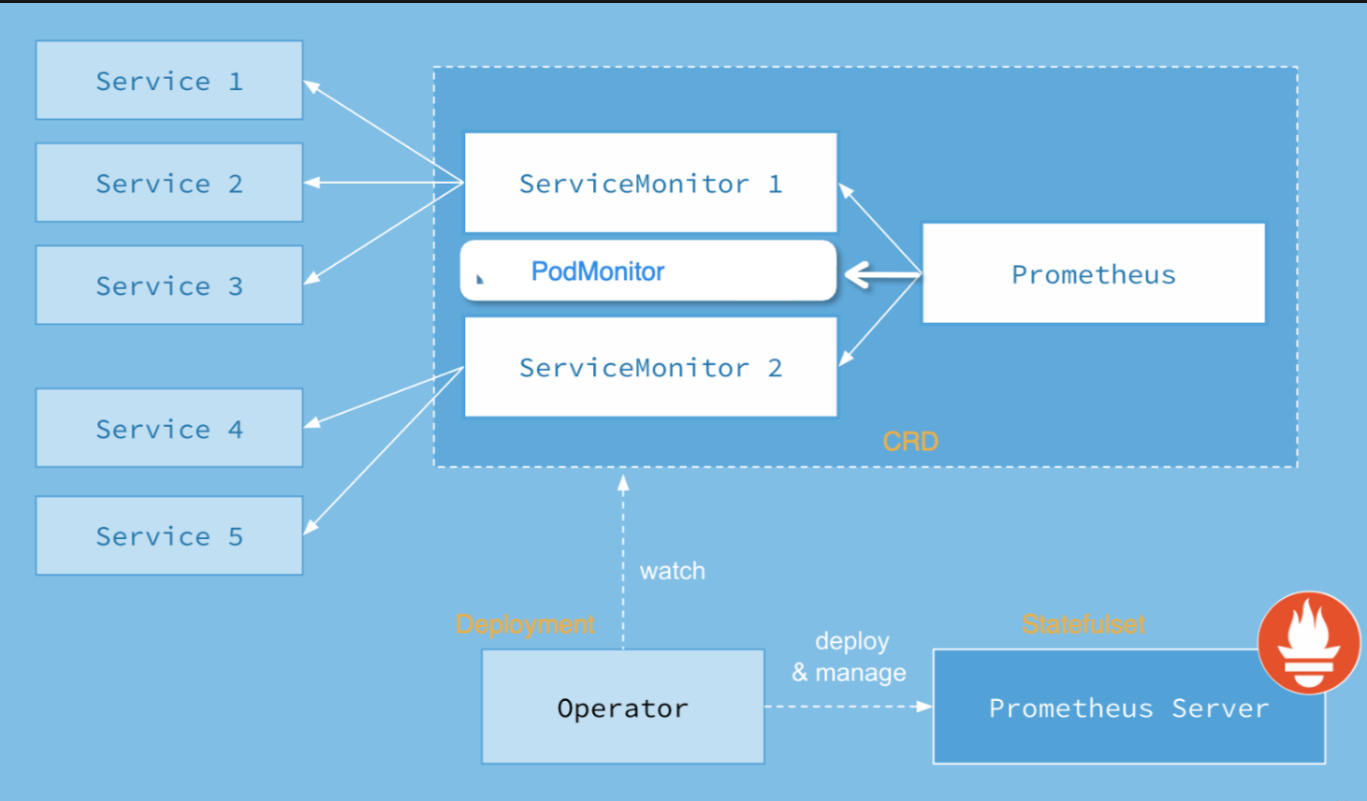
- Prometheus:用于持久化存储和查询时间序列数据的核心组件,由Prometheus Operator自动创建和管理。
- Alertmanager:用于处理由Prometheus生成的告警信息,并对其进行路由、静音、聚合等操作,由Prometheus Operator自动创建和管理。
- Grafana:一个开源的指标可视化和分析工具,可以与Prometheus进行无缝集成,由用户自行安装或使用Helm部署。
- Thanos Sidecar:一种用于在Kubernetes中运行Thanos的解决方案,可以扩展Prometheus的存储能力,由用户自行安装或使用Helm部署。
- ServiceMonitor:用于定义监控的对象和采集规则,由Prometheus Operator自动创建和管理。
- PrometheusRule:用于定义告警规则和记录规则,由Prometheus Operator自动创建和管理。
- Custom Resource Definitions (CRDs):用于定义Prometheus、Alertmanager、ServiceMonitor和PrometheusRule等资源的规范和行为,由Prometheus Operator自动创建和管理。
四.helm安装prometheus-operator
本文介绍如何使用Helm将Prometheus Operator部署到Kubernetes集群中,从而实现对集群的监控。关于helm的详细用法可以查看博客《Kubernetes(k8s)包管理工具Helm:Helm包管理》。
添加微软和阿里的源。
[root@k8scloude1 helm]# helm repo add azure http://mirror.azure.cn/kubernetes/charts/
"azure" has been added to your repositories
[root@k8scloude1 helm]# helm repo add ali https://apphub.aliyuncs.com
"ali" has been added to your repositories
查看helm现在的仓库源。
[root@k8scloude1 helm]# helm repo list
NAME URL
azure http://mirror.azure.cn/kubernetes/charts/
ali https://apphub.aliyuncs.com
搜索prometheus-operator。
[root@k8scloude1 ~]# helm search repo prometheus-operator
NAME CHART VERSION APP VERSION DESCRIPTION
ali/prometheus-operator 8.7.0 0.35.0 Provides easy monitoring definitions for Kubern...
azure/prometheus-operator 9.3.2 0.38.1 DEPRECATED Provides easy monitoring definitions...
安装prometheus-operator。
[root@k8scloude1 ~]# helm install prometheus ali/prometheus-operator
W0219 21:11:11.684133 125088 warnings.go:70] apiextensions.k8s.io/v1beta1 CustomResourceDefinition is deprecated in v1.16+, unavailable in v1.22+; use apiextensions.k8s.io/v1 CustomResourceDefinition
W0219 21:11:11.707883 125088 warnings.go:70] apiextensions.k8s.io/v1beta1 CustomResourceDefinition is deprecated in v1.16+, unavailable in v1.22+; use apiextensions.k8s.io/v1 CustomResourceDefinition
......
W0219 21:11:46.261737 125088 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0219 21:11:47.064316 125088 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0219 21:11:55.302140 125088 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: prometheus
LAST DEPLOYED: Sat Feb 19 21:11:14 2022
NAMESPACE: helm
STATUS: deployed
REVISION: 1
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl --namespace helm get pods -l "release=prometheus"
Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
查看安装的应用。
[root@k8scloude1 ~]# helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
prometheus helm 1 2022-02-19 21:11:14.316586608 +0800 CST deployed prometheus-operator-8.7.0 0.35.0
查看pod,发现一个pod拉取镜像失败ImagePullBackOff。
[root@k8scloude1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-prometheus-prometheus-oper-alertmanager-0 1/2 ImagePullBackOff 0 5m14s 10.244.112.152 k8scloude2 <none> <none>
prometheus-grafana-74578c7898-xb7h6 2/2 Running 0 5m36s 10.244.112.143 k8scloude2 <none> <none>
prometheus-kube-state-metrics-6b4d9598d9-c9xv9 1/1 Running 0 5m36s 10.244.251.218 k8scloude3 <none> <none>
prometheus-prometheus-node-exporter-nwgck 1/1 Running 0 5m36s 192.168.110.129 k8scloude2 <none> <none>
prometheus-prometheus-node-exporter-rq96m 1/1 Running 0 5m36s 192.168.110.130 k8scloude1 <none> <none>
prometheus-prometheus-node-exporter-w4bhq 1/1 Running 0 5m36s 192.168.110.128 k8scloude3 <none> <none>
prometheus-prometheus-oper-operator-5b57575c97-6x4th 2/2 Running 0 5m36s 10.244.251.221 k8scloude3 <none> <none>
prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 1 5m4s 10.244.112.147 k8scloude2 <none> <none>
查看pod的日志。
[root@k8scloude1 ~]# kubectl logs alertmanager-prometheus-prometheus-oper-alertmanager-0
error: a container name must be specified for pod alertmanager-prometheus-prometheus-oper-alertmanager-0, choose one of: [alertmanager config-reloader]
因为alertmanager-prometheus-prometheus-oper-alertmanager-0这个pod里有2个容器,查看日志需要指明看哪个容器的日志,使用-c指定容器名,查看alertmanager-prometheus-prometheus-oper-alertmanager-0这个pod里alertmanager容器的日志,报错了,但是只是说镜像拉取失败,没说具体是哪个镜像拉取失败。
[root@k8scloude1 ~]# kubectl logs alertmanager-prometheus-prometheus-oper-alertmanager-0 -c alertmanager
Error from server (BadRequest): container "alertmanager" in pod "alertmanager-prometheus-prometheus-oper-alertmanager-0" is waiting to start: trying and failing to pull image
查看alertmanager-prometheus-prometheus-oper-alertmanager-0这个pod里config-reloader容器的日志,没报错。
[root@k8scloude1 ~]# kubectl logs alertmanager-prometheus-prometheus-oper-alertmanager-0 -c config-reloader
kubectl describe查看pod的描述信息,可以看到报错:Back-off pulling image "registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0",由此判定是registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0镜像下载失败。
[root@k8scloude1 ~]# kubectl describe pod alertmanager-prometheus-prometheus-oper-alertmanager-0
Name: alertmanager-prometheus-prometheus-oper-alertmanager-0
Namespace: helm
Priority: 0
Node: k8scloude2/192.168.110.129
......
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7m39s default-scheduler Successfully assigned helm/alertmanager-prometheus-prometheus-oper-alertmanager-0 to k8scloude2
Normal Pulling 6m13s kubelet Pulling image "registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-configmap-reload:v0.0.1"
Normal Started 5m25s kubelet Started container config-reloader
Normal Pulled 5m25s kubelet Successfully pulled image "registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-configmap-reload:v0.0.1" in 48.034472085s
Normal Created 5m25s kubelet Created container config-reloader
Normal BackOff 111s (x5 over 4m10s) kubelet Back-off pulling image "registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0"
Warning Failed 111s (x5 over 4m10s) kubelet Error: ImagePullBackOff
Normal Pulling 97s (x4 over 7m38s) kubelet Pulling image "registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0"
Warning Failed 26s (x4 over 6m13s) kubelet Failed to pull image "registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0": rpc error: code = Unknown desc = context canceled
Warning Failed 26s (x4 over 6m13s) kubelet Error: ErrImagePull
我们去kubernetes集群的worker节点手动下载registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0镜像,k8scloude3节点下载镜像。
[root@k8scloude3 ~]# docker pull registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0
v0.20.0: Pulling from kubeapps/quay-alertmanager
0f8c40e1270f: Already exists
626a2a3fee8c: Already exists
05ec5ff61d82: Pull complete
3e4eb9050294: Pull complete
c920019f84ec: Pull complete
59ee938b06a9: Pull complete
Digest: sha256:b9323917a2eda265bec69e59a457f001c529facbbc8166df277f4850cdac61a0
Status: Downloaded newer image for registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0
registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0
[root@k8scloude3 ~]# docker images | grep quay-alertmanager
registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager v0.20.0 0881eb8f169f 2 years ago 52.1MB
因为k8scloude2节点镜像下载不下来,所以把k8scloude3节点的镜像导出为tar包,然后k8scloude2节点导入tar包加载镜像,关于docker更多操作,请查看博客《一文搞懂docker容器基础:docker镜像管理,docker容器管理》。
[root@k8scloude3 ~]# docker save registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0 >quay-alertmanager0.20.tar
[root@k8scloude3 ~]# ls
quay-alertmanager0.20.tar
把quay-alertmanager0.20.tar包传到k8scloude2节点。
[root@k8scloude3 ~]# scp quay-alertmanager0.20.tar k8scloude2:~/
k8scloude2加载镜像包,此时两个worker节点都已经存在了registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager镜像。
[root@k8scloude2 ~]# docker load -i quay-alertmanager0.20.tar
fd718f46814b: Loading layer [==================================================>] 3.584kB/3.584kB
Loaded image: registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager:v0.20.0
[root@k8scloude2 ~]# docker images | grep quay-alertmanager
registry.cn-hangzhou.aliyuncs.com/kubeapps/quay-alertmanager v0.20.0 0881eb8f169f 2 years ago 52.1MB
查看pod,此时alertmanager-prometheus-prometheus-oper-alertmanager-0也变为Running状态。
[root@k8scloude1 helm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 15m 10.244.112.152 k8scloude2 <none> <none>
prometheus-grafana-74578c7898-xb7h6 2/2 Running 0 15m 10.244.112.143 k8scloude2 <none> <none>
prometheus-kube-state-metrics-6b4d9598d9-c9xv9 1/1 Running 0 15m 10.244.251.218 k8scloude3 <none> <none>
prometheus-prometheus-node-exporter-nwgck 1/1 Running 0 15m 192.168.110.129 k8scloude2 <none> <none>
prometheus-prometheus-node-exporter-rq96m 1/1 Running 0 15m 192.168.110.130 k8scloude1 <none> <none>
prometheus-prometheus-node-exporter-w4bhq 1/1 Running 0 15m 192.168.110.128 k8scloude3 <none> <none>
prometheus-prometheus-oper-operator-5b57575c97-6x4th 2/2 Running 0 15m 10.244.251.221 k8scloude3 <none> <none>
prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 1 15m 10.244.112.147 k8scloude2 <none> <none>
此时prometheus-operator就安装完毕了。
五.配置prometheus-operator
5.1 修改grafana的svc类型
查看svc,grafana是可视化界面,此时prometheus-grafana的svc类型为ClusterIP,外界访问不了,我们修改grafana的svc发布类型,使其外界能够访问grafana web界面。关于svc的发布类型,详情请查看博客《Kubernetes(k8s)服务service:service的发现和service的发布》。
[root@k8scloude1 helm]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 16m app=alertmanager
prometheus-grafana ClusterIP 10.108.86.134 <none> 80/TCP 16m app=grafana,release=prometheus
prometheus-kube-state-metrics ClusterIP 10.105.107.5 <none> 8080/TCP 16m app.kubernetes.io/instance=prometheus,app.kubernetes.io/name=kube-state-metrics
prometheus-operated ClusterIP None <none> 9090/TCP 15m app=prometheus
prometheus-prometheus-node-exporter ClusterIP 10.109.42.88 <none> 9100/TCP 16m app=prometheus-node-exporter,release=prometheus
prometheus-prometheus-oper-alertmanager ClusterIP 10.104.36.37 <none> 9093/TCP 16m alertmanager=prometheus-prometheus-oper-alertmanager,app=alertmanager
prometheus-prometheus-oper-operator ClusterIP 10.107.93.11 <none> 8080/TCP,443/TCP 16m app=prometheus-operator-operator,release=prometheus
prometheus-prometheus-oper-prometheus ClusterIP 10.102.189.146 <none> 9090/TCP 16m app=prometheus,prometheus=prometheus-prometheus-oper-prometheus
kubectl edit编辑svc,把svc的类型从ClusterIP改为NodePort。
[root@k8scloude1 helm]# kubectl edit svc prometheus-grafana
service/prometheus-grafana edited
查看svc,此时prometheus-grafana的类型变为了NodePort,外界访问节点IP:30355,即可访问grafana界面。
[root@k8scloude1 helm]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 17m app=alertmanager
prometheus-grafana NodePort 10.108.86.134 <none> 80:30355/TCP 17m app=grafana,release=prometheus
prometheus-kube-state-metrics ClusterIP 10.105.107.5 <none> 8080/TCP 17m app.kubernetes.io/instance=prometheus,app.kubernetes.io/name=kube-state-metrics
prometheus-operated ClusterIP None <none> 9090/TCP 16m app=prometheus
prometheus-prometheus-node-exporter ClusterIP 10.109.42.88 <none> 9100/TCP 17m app=prometheus-node-exporter,release=prometheus
prometheus-prometheus-oper-alertmanager ClusterIP 10.104.36.37 <none> 9093/TCP 17m alertmanager=prometheus-prometheus-oper-alertmanager,app=alertmanager
prometheus-prometheus-oper-operator ClusterIP 10.107.93.11 <none> 8080/TCP,443/TCP 17m app=prometheus-operator-operator,release=prometheus
prometheus-prometheus-oper-prometheus ClusterIP 10.102.189.146 <none> 9090/TCP 17m app=prometheus,prometheus=prometheus-prometheus-oper-prometheus
5.2 查询grafana的账号密码
打开浏览器访问:物理机IP:30355,即可访问grafana,我们访问http://192.168.110.130:30355/login,grafana需要输入账号密码才可以登录。

现在需要查询grafana的账号密码,grafana的账号密码都是放在secret里保存的。
查看secret,grafana的账号密码保存在prometheus-grafana里。
[root@k8scloude1 helm]# kubectl get secret -o wide
NAME TYPE DATA AGE
alertmanager-prometheus-prometheus-oper-alertmanager Opaque 1 21m
default-token-ztjjd kubernetes.io/service-account-token 3 5h49m
prometheus-grafana Opaque 3 21m
prometheus-grafana-test-token-hvdpz kubernetes.io/service-account-token 3 21m
prometheus-grafana-token-4hvvc kubernetes.io/service-account-token 3 21m
。。。。。。
以yaml文件的方式查看prometheus-grafana的信息,可以看到账号密码如下:
- 账号admin-user: YWRtaW4=
- 密码admin-password: cHJvbS1vcGVyYXRvcg==
不过账号密码被加密了,需要进行解密。
[root@k8scloude1 helm]# kubectl get secrets prometheus-grafana -o yaml
apiVersion: v1
data:
admin-password: cHJvbS1vcGVyYXRvcg==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: helm
creationTimestamp: "2022-02-19T13:11:43Z"
labels:
app: grafana
app.kubernetes.io/managed-by: Helm
chart: grafana-4.3.0
heritage: Helm
release: prometheus
name: prometheus-grafana
namespace: helm
resourceVersion: "2359089"
selfLink: /api/v1/namespaces/helm/secrets/prometheus-grafana
uid: 1e081320-13cf-422e-b7b9-bc08b6ea8d23
type: Opaque
解密账号。
[root@k8scloude1 helm]# kubectl get secrets prometheus-grafana -o jsonpath='{.data.admin-user}' | base64 -d
admin
解密密码。
[root@k8scloude1 helm]# kubectl get secrets prometheus-grafana -o jsonpath='{.data.admin-password}' | base64 -d
prom-operator
5.3 访问grafana web界面
得到账号密码之后,登录http://192.168.110.130:30355/login就可以进入grafana了,grafana首页如下所示:
接下来添加数据源,configuration-->data source-->Add data source添加数据源。
默认已经存在了prometheus这个数据源,选择prometheus。
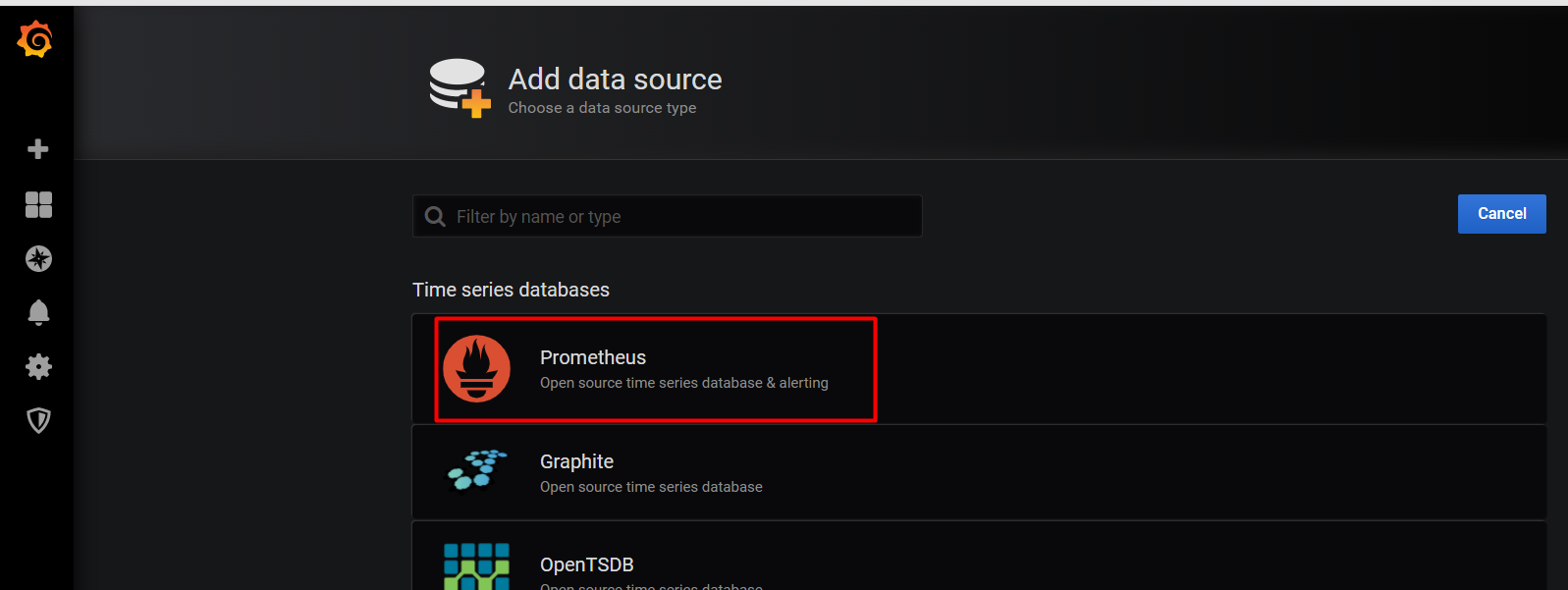
此时查看节点的资源使用情况,选择nodes节点。
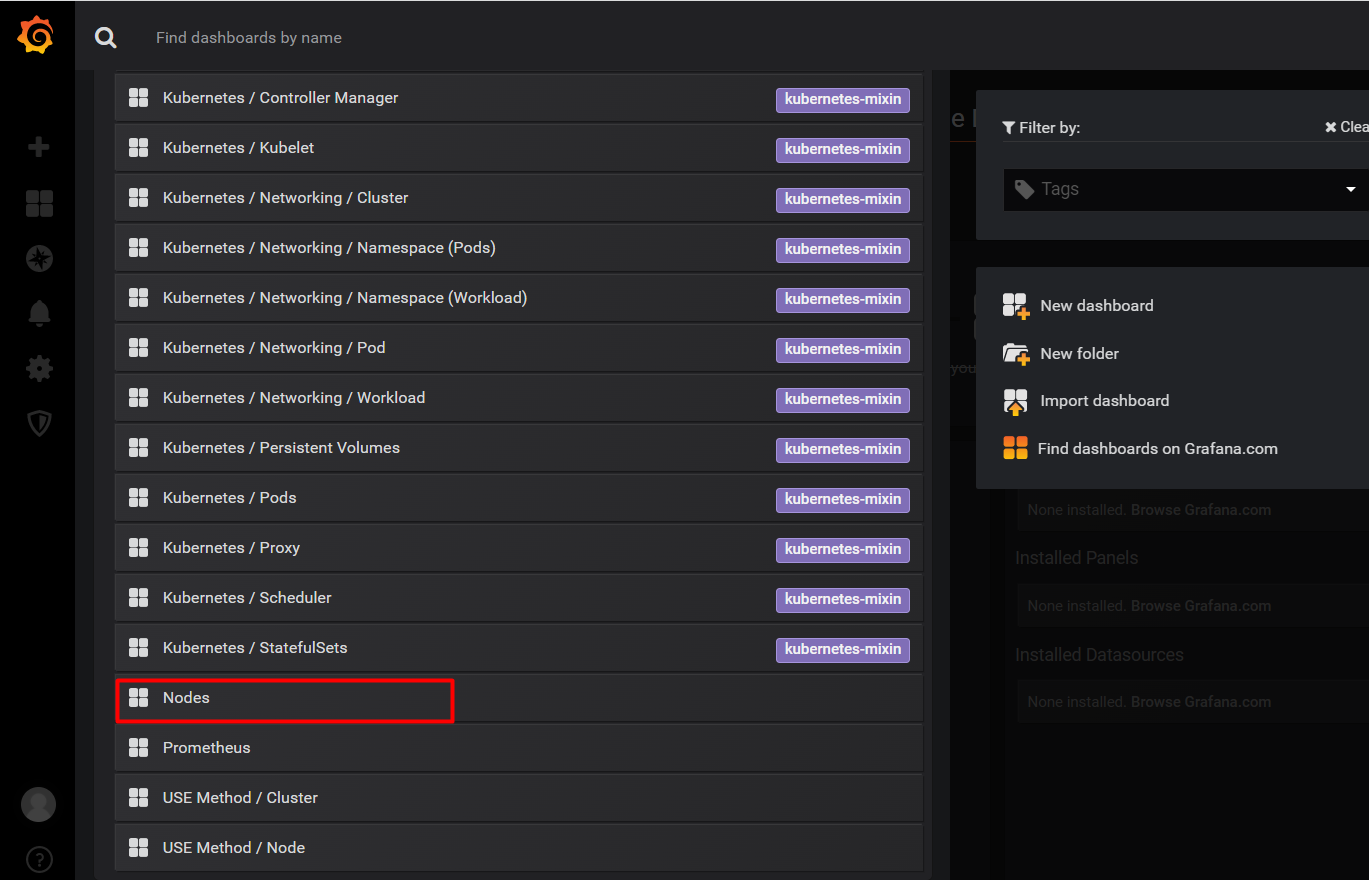
现在展示的就是kubernetes集群的节点资源使用情况了。
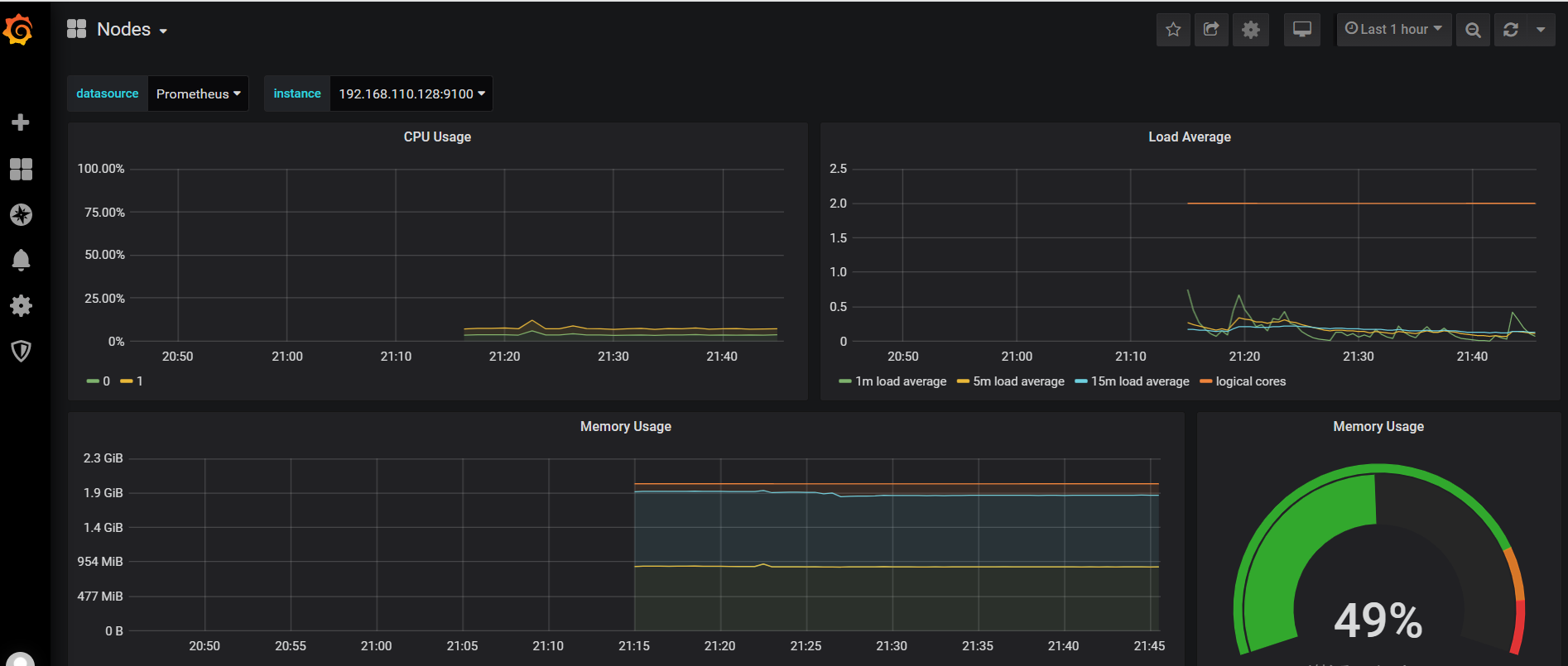
如果觉得默认的dashboard不好看,可以去grafana官网找其他模板,访问grafana官网:https://grafana.com/grafana/dashboards/。
在grafana官网觉得9873这个模板好看,点击copy ID to Clipboard,复制ID。
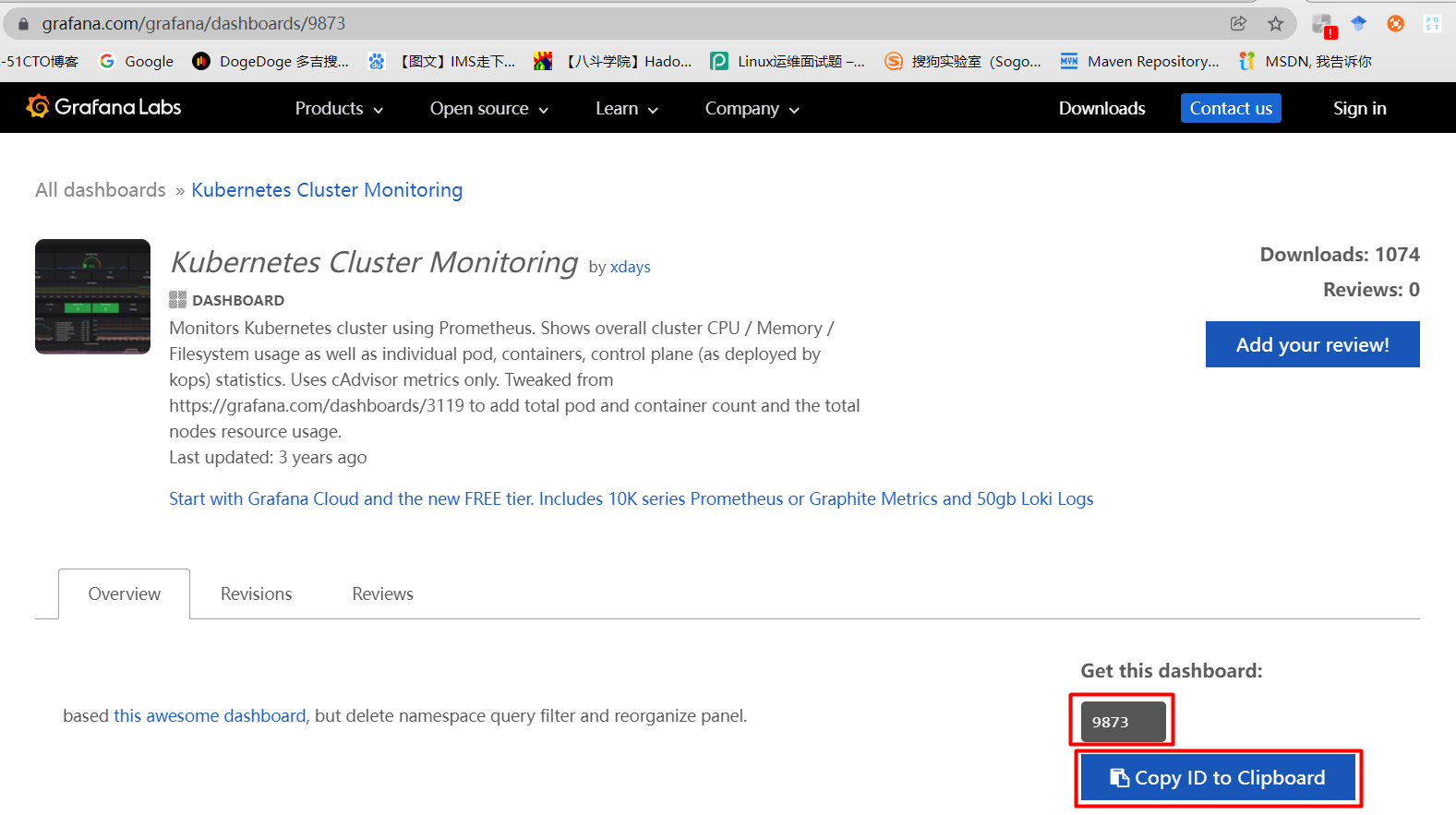
在Import,输入模板ID 9873 进行导入。
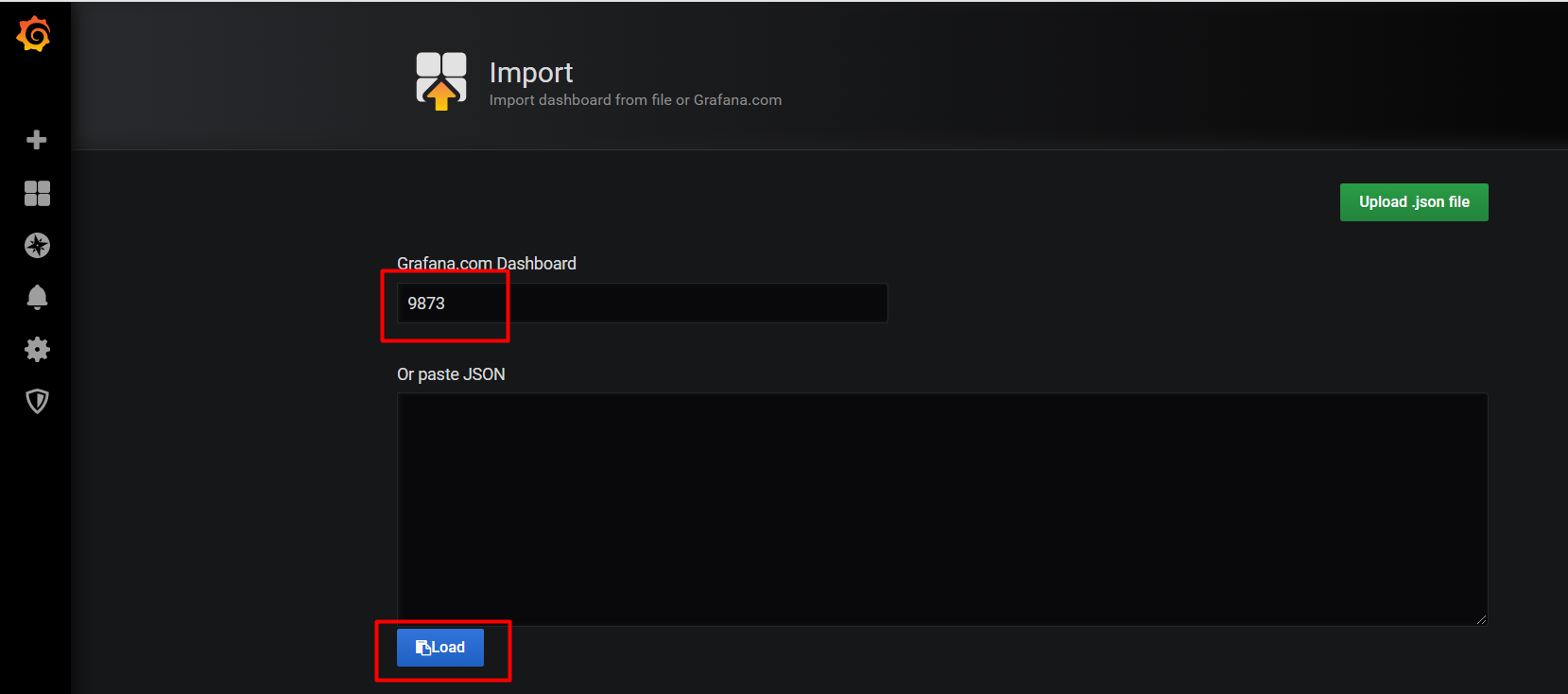
选择prometheus进行导入。
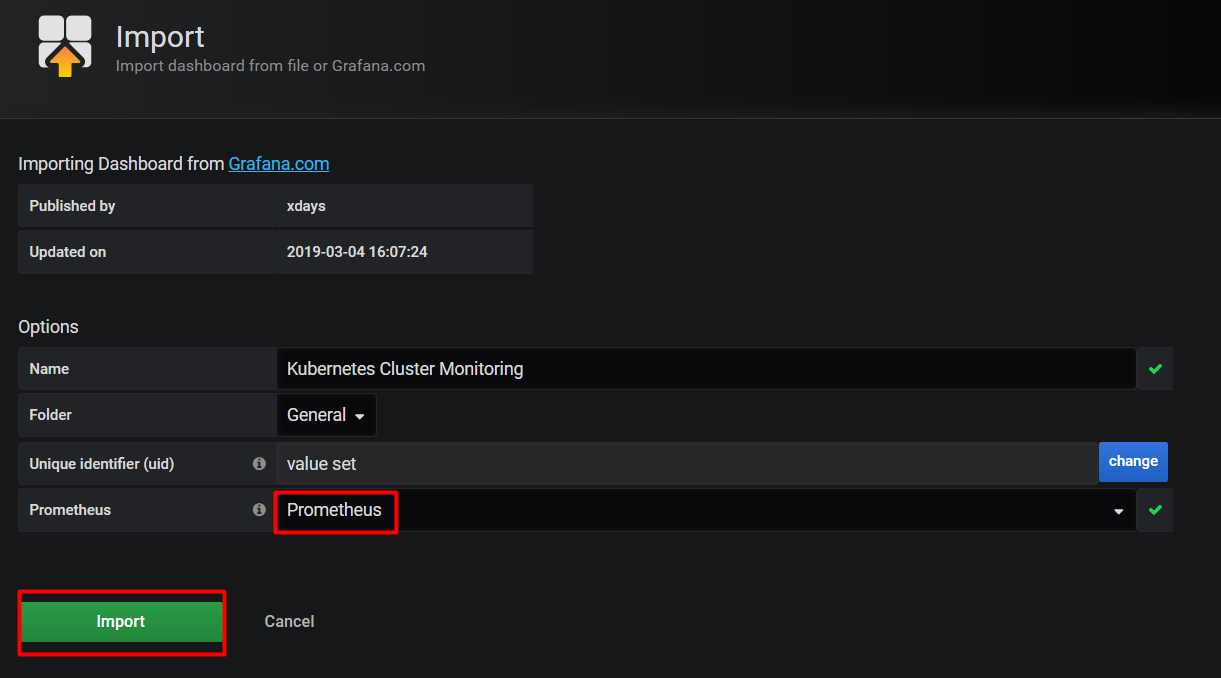
这样就成功导入了新的模板。
六.删除prometheus operator
查看已经安装的应用。
[root@k8scloude1 helm]# helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
prometheus helm 1 2022-02-19 21:11:14.316586608 +0800 CST deployed prometheus-operator-8.7.0 0.35.0
删除prometheus。
[root@k8scloude1 helm]# helm delete prometheus
W0219 22:12:41.986757 52171 warnings.go:70] rbac.authorization.k8s.io/v1beta1 RoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 RoleBinding
W0219 22:12:42.000754 52171 warnings.go:70] rbac.authorization.k8s.io/v1beta1 Role is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 Role
W0219 22:12:42.026096 52171 warnings.go:70] rbac.authorization.k8s.io/v1beta1 ClusterRoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRoleBinding
......
W0219 22:12:42.599013 52171 warnings.go:70] admissionregistration.k8s.io/v1beta1 ValidatingWebhookConfiguration is deprecated in v1.16+, unavailable in v1.22+; use admissionregistration.k8s.io/v1 ValidatingWebhookConfiguration
release "prometheus" uninstalled
[root@k8scloude1 helm]# helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
删除prometheus-operator之后,对应的pod和svc都被删除了。
[root@k8scloude1 helm]# kubectl get pod -o wide
No resources found in helm namespace.
[root@k8scloude1 helm]# kubectl get svc -o wide
No resources found in helm namespace.
七.总结
在本文中,我们介绍了如何使用Helm将Prometheus Operator部署到Kubernetes集群中,并添加了自定义配置以满足我们的需求。通过这种方式,我们可以更加方便地管理和部署Prometheus Operator,同时也可以提高我们对Kubernetes集群的监控能力。
除了使用Helm部署Prometheus Operator之外,我们还可以使用其他工具来进行部署和管理。例如,kube-prometheus是一种用于在Kubernetes上运行和管理Prometheus的解决方案,它也可以自动创建、配置和管理Prometheus实例。如果您需要更高级的功能,可以尝试使用kube-prometheus进行部署和管理。